
前言 前面說了很多Kafka的性能優點,有些童鞋要說了,這Kafka在企業開發或者企業級應用中要怎麼用呢?今天咱們就來簡單探究一下。 1、 使用 Kafka 進行消息的非同步處理 Kafka 提供了一個可靠的消息傳遞機制,使得企業能夠將不同組件之間的通信解耦,實現高效的非同步處理。在企業級應用中,可以通 ...
1 從零擴展到百萬用戶
設計支持數百萬用戶的系統是一項挑戰,是需要不斷完善和無止境改進的過程。在本章中,我們將構建一個支持單個用戶的系統,並逐步將其擴展到為數百萬用戶提供服務。
1.1 單伺服器設置
下圖展示了單伺服器設置的示意圖,其中所有內容都運行在一臺伺服器上:網路應用程式、資料庫、緩存等。
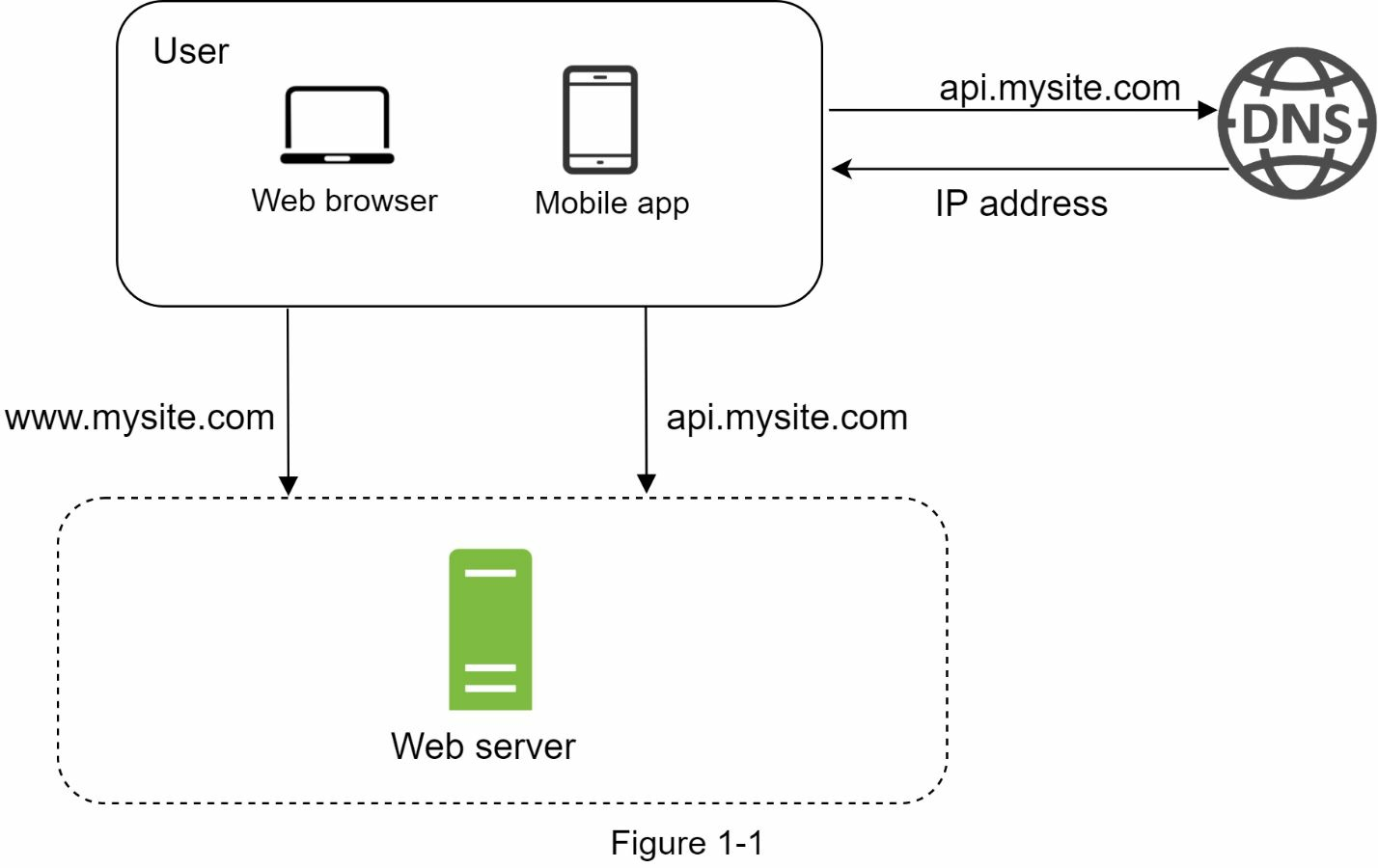
請求流:
-
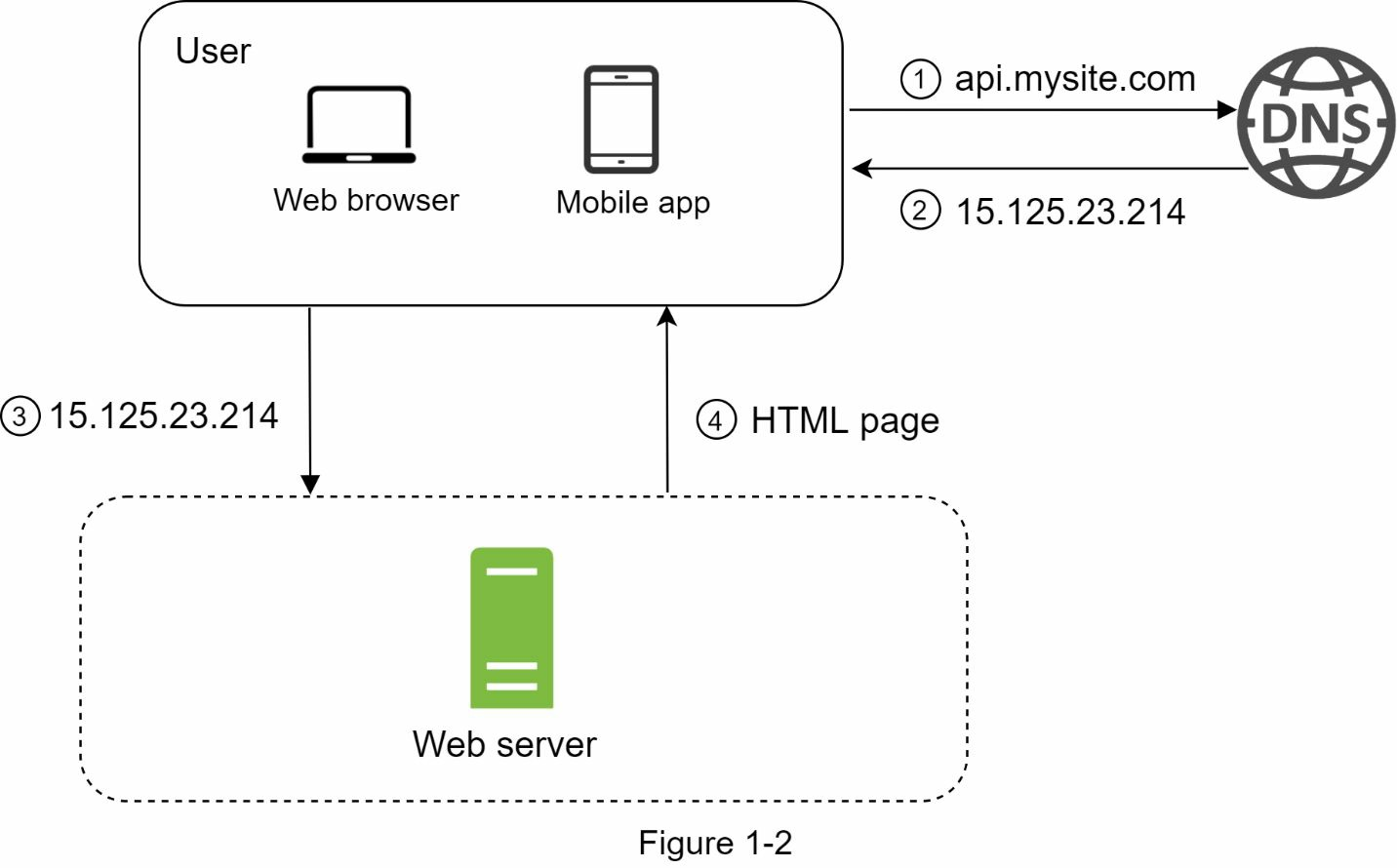
用戶通過功能變數名稱訪問網站,如 api.mysite.com。通常,功能變數名稱系統(DNS)是由第三方提供的付費服務,並非由我們的伺服器托管。
-
互聯網協議 (IP)地址會返回給瀏覽器或移動應用程式。在本例中,將返回IP地址15.125.23.214。
-
獲得IP地址後,超文本傳輸協議(HTTP)請求將直接發送到您的網路伺服器。
-
網路伺服器返回HTML頁面或JSON響應,以供呈現。
網路伺服器的流量來自兩個方面:Web應用程式和移動應用程式。
-
Web應用:使用伺服器端語言(Python、Go、Java、PHP、Perl、Node.js等)處理業務邏輯和存儲等,並使用客戶端語言(HTML和JavaScript)進行呈現。
-
移動應用程式: HTTP協議是移動應用程式與網路伺服器之間的通信協議。JavaScript Object Notation(JSON)是常用的API響應格式,因其簡單易用,可用於傳輸數據。
1.2 資料庫
隨著用戶群的增長,一臺伺服器是不夠的,我們需要多台伺服器:一臺用於Web/移動流量,另一臺用於資料庫。將網路/移動流量(網路層)和資料庫(數據層)伺服器分開,可以使它們獨立擴展。
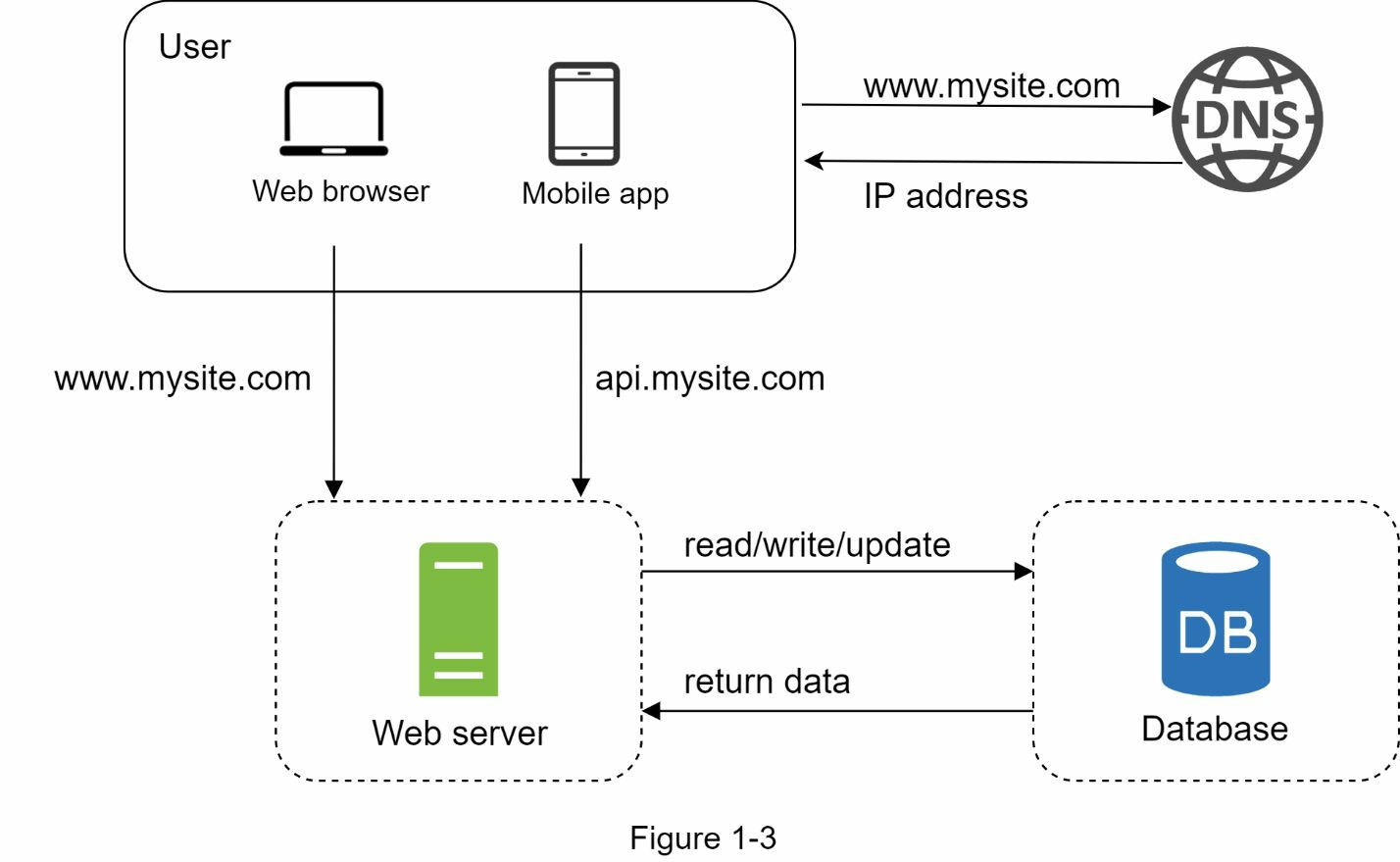
您可以選擇傳統的關係資料庫或非關係資料庫。讓我們來看看它們的區別。
關係資料庫也稱為關係資料庫管理系統(RDBMS)或 SQL 資料庫。最流行的資料庫有PostgreSQL、MySQL、Oracle等。關係資料庫以表格和行來表示和存儲數據。您可以使用SQL跨不同的資料庫表執行連接操作。
1.2.1 選擇資料庫
非關係型資料庫也稱為NoSQL資料庫。常用的資料庫有MongoDB、CouchDB、Neo4j、Cassandra、HBase、Amazon DynamoDB 等。 這些資料庫分為四類:鍵值存儲、圖存儲、列存儲和文檔存儲。
對於大多數開發人員來說,關係資料庫是最好的選擇,因為關係資料庫已經存在了 40 多年,歷史上一直運行良好。但是,如果關係資料庫不適合您的特定用例,就必須探索關係資料庫以外的其他資料庫。在以下情況下,非關係型資料庫可能是正確的選擇:
- 要超低延遲。
- 數據是非結構化的,或者您沒有任何關係型數據。
- 只需要序列化和反序列化數據(JSON、XML、YAML 等)。
- 存儲大量數據。
1.3 垂直擴展與水平擴展
垂直擴展在伺服器上增加更多功率(CPU、記憶體等)的過程。水平擴展被稱為 "向外擴展",通過在資源池中添加更多伺服器來實現擴展。
當流量較低時,垂直擴展是不錯的選擇,垂直擴展的簡單性是其主要優勢。遺憾的是,它也有嚴重的局限性。
- 垂直擴展有硬限制。不可能在一臺伺服器上無限增加CPU和記憶體。
- 垂直擴展不具備故障切換和冗餘功能。如果一臺伺服器宕機,網站/應用程式也會隨之完全宕機。
由於垂直擴展的局限性,對於大型應用程式來說,水平擴展更為理想。
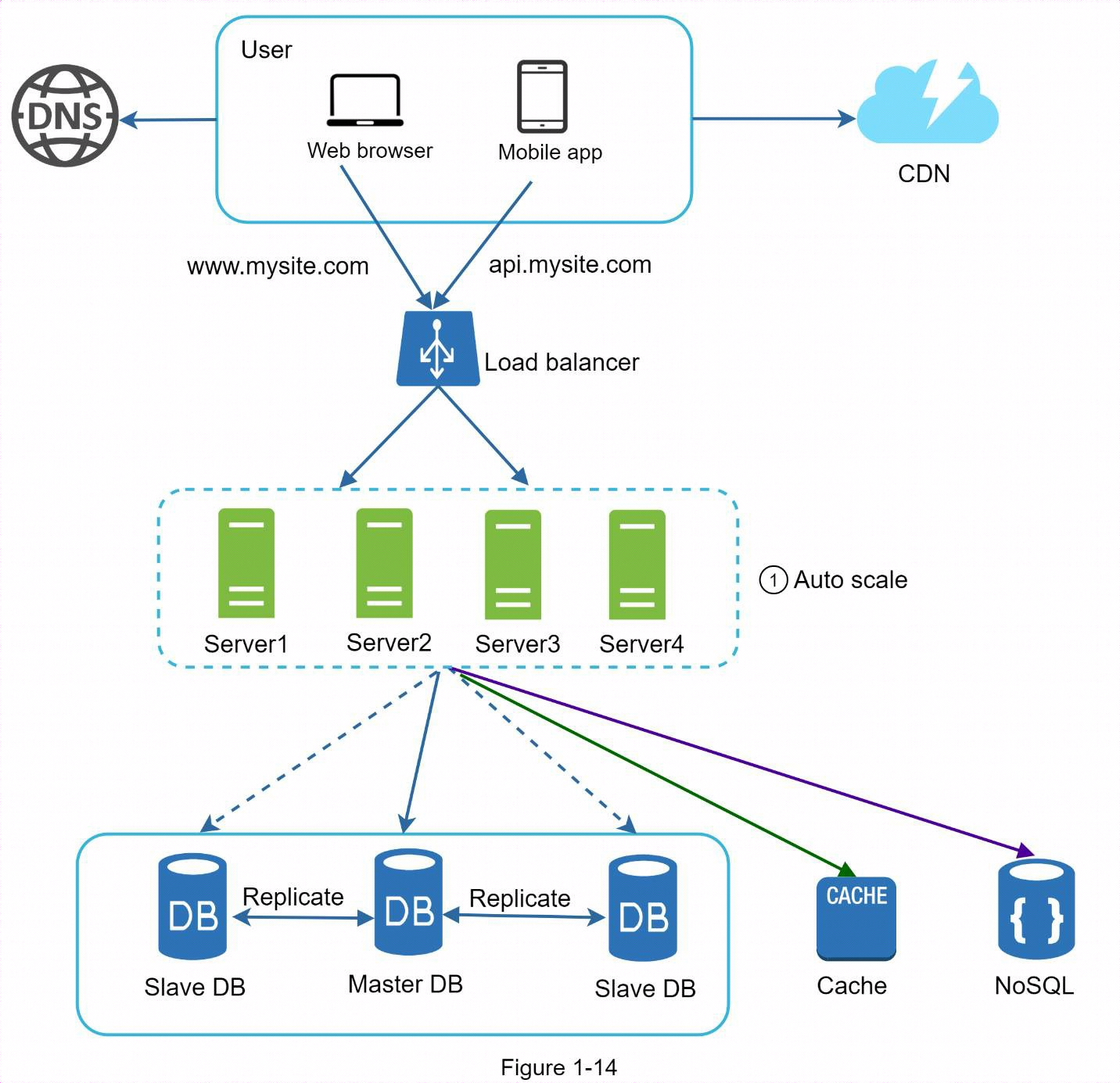
在前面的設計中,用戶直接連接到網路伺服器。如果網路伺服器離線,用戶將無法訪問網站。在另一種情況下,如果許多用戶同時訪問網路伺服器,並達到網路伺服器的負載極限,用戶一般會體驗到較慢的響應或無法連接到伺服器。負載平衡器是解決這些問題的最佳技術。
1.4 負載均衡
負載均衡在負載平衡集定義的網路伺服器之間平均分配傳入流量。
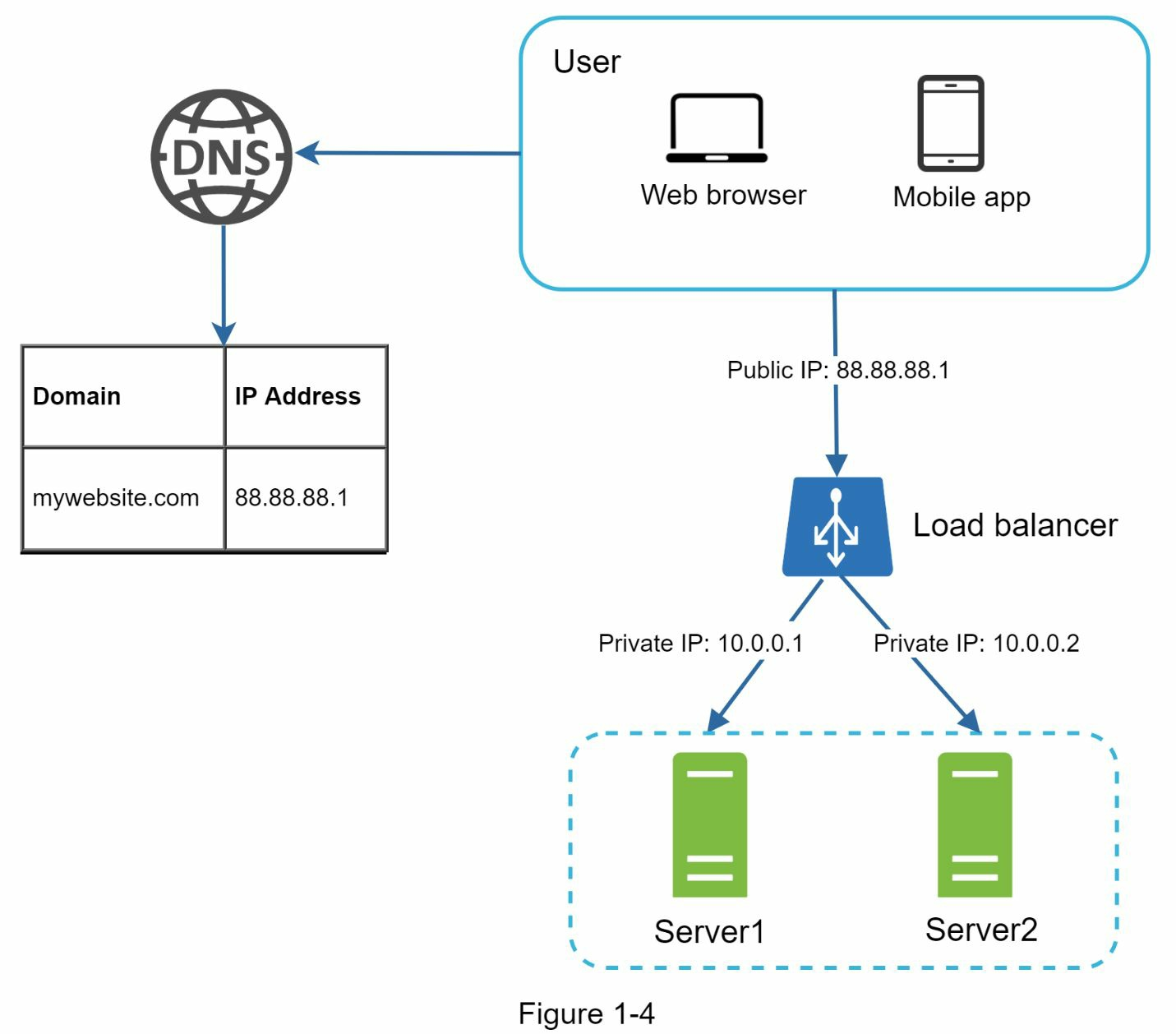
用戶直接連接到負載均衡。在這種設置下,客戶端再也無法直接訪問網路伺服器。為了提高安全性,伺服器之間的通信使用專網。
- 如果伺服器1離線,所有流量將被路由到伺服器2。這可以防止網站離線。
- 如果流量迅速增長,兩台伺服器不足以處理流。只需添加更多伺服器,負載平衡器就會自動開始向它們發送請求。
1.5 資料庫複製
資料庫複製可用於許多資料庫管理系統,通常在原始資料庫(主資料庫)和副本(從資料庫)之間存在主從關係。
主資料庫通常只支持寫操作。從資料庫從主資料庫獲取數據副本,只支持讀操作。所有修改數據的命令(如插入、刪除或更新)都必鬚髮送到主資料庫。大多數應用程式要求的讀取和寫入比例要高得多;因此,系統中從資料庫的數量通常大於主資料庫的數量。
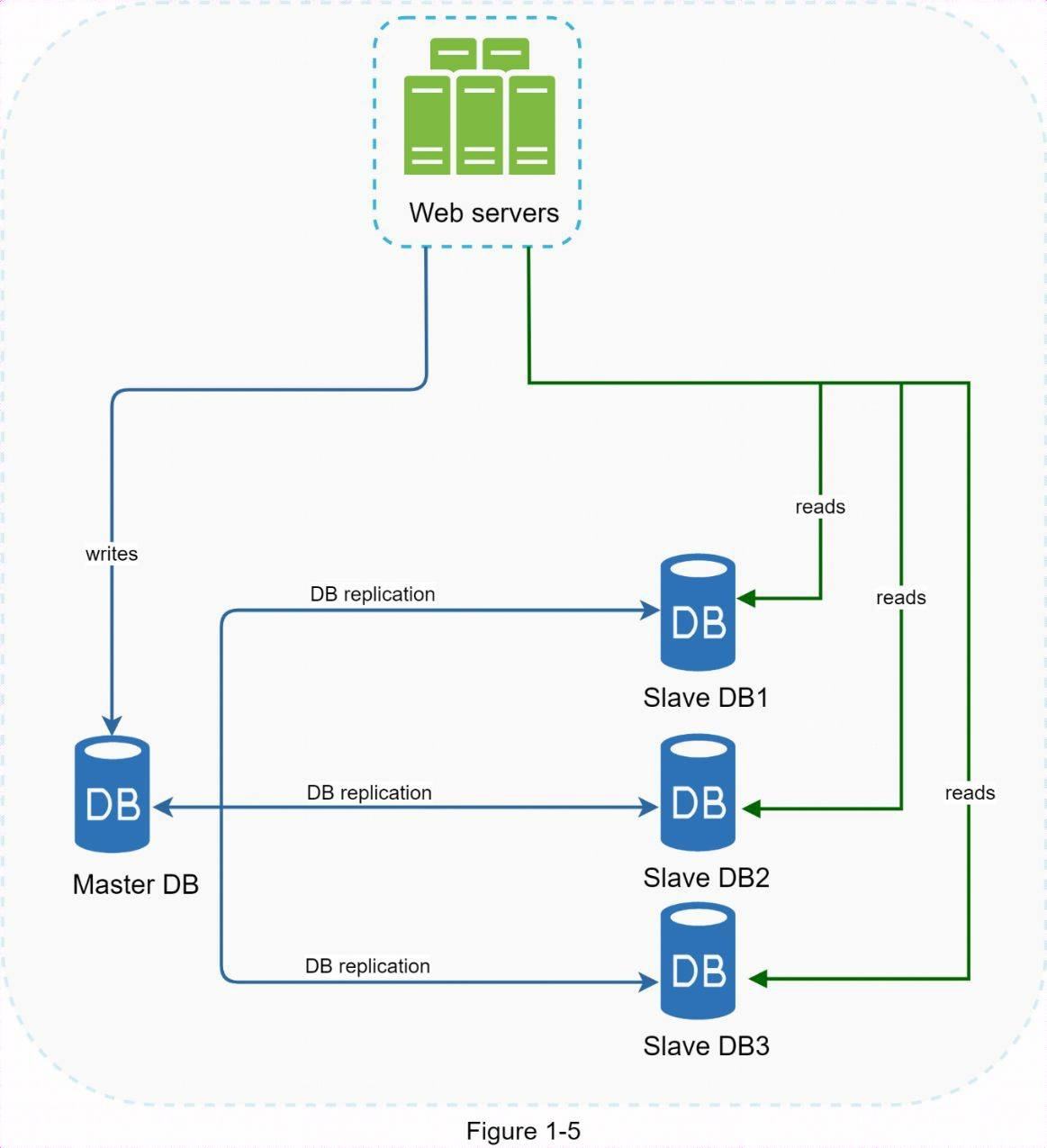
資料庫複製的優勢:
-更好的性能: 在主從模式中,所有寫入和更新操作都在主節點上進行;而讀取操作則分佈在從節點上進行。這種模式可以並行處理更多查詢,因此可以提高性能。
-可靠性: 如果您的一臺資料庫伺服器因颱風或地震等自然災害而毀壞,數據仍會保留。您不必擔心數據丟失,因為數據是在多個地點複製的。
-高可用性: 通過在不同地點複製數據,即使資料庫離線,您的網站也能繼續運行,因為您可以訪問存儲在另一個資料庫伺服器中的數據。
如果其中一個資料庫離線了怎麼辦?
-
如果只有一個從資料庫可用,但該資料庫離線,讀取操作將暫時定向到主資料庫。一旦發現問題,新的從資料庫將取代舊的從資料庫。如果有多個從資料庫可用,讀取操作將重定向到其他健康的從資料庫。新的資料庫伺服器將取代舊的資料庫伺服器。
-
如果主資料庫離線,從資料庫將被提升為新的主資料庫。所有資料庫操作都將在新的主資料庫上臨時執行。新的從資料庫將立即取代舊的從資料庫進行數據複製。在生產系統中,推廣新的主資料庫更為複雜,因為從資料庫中的數據可能不是最新的。需要通過運行數據恢復腳本來更新缺失的數據。雖然其他一些複製方法,如多主複製和迴圈複製也有幫助,但這些設置更為複雜,而且其討論超出了本書的範圍。
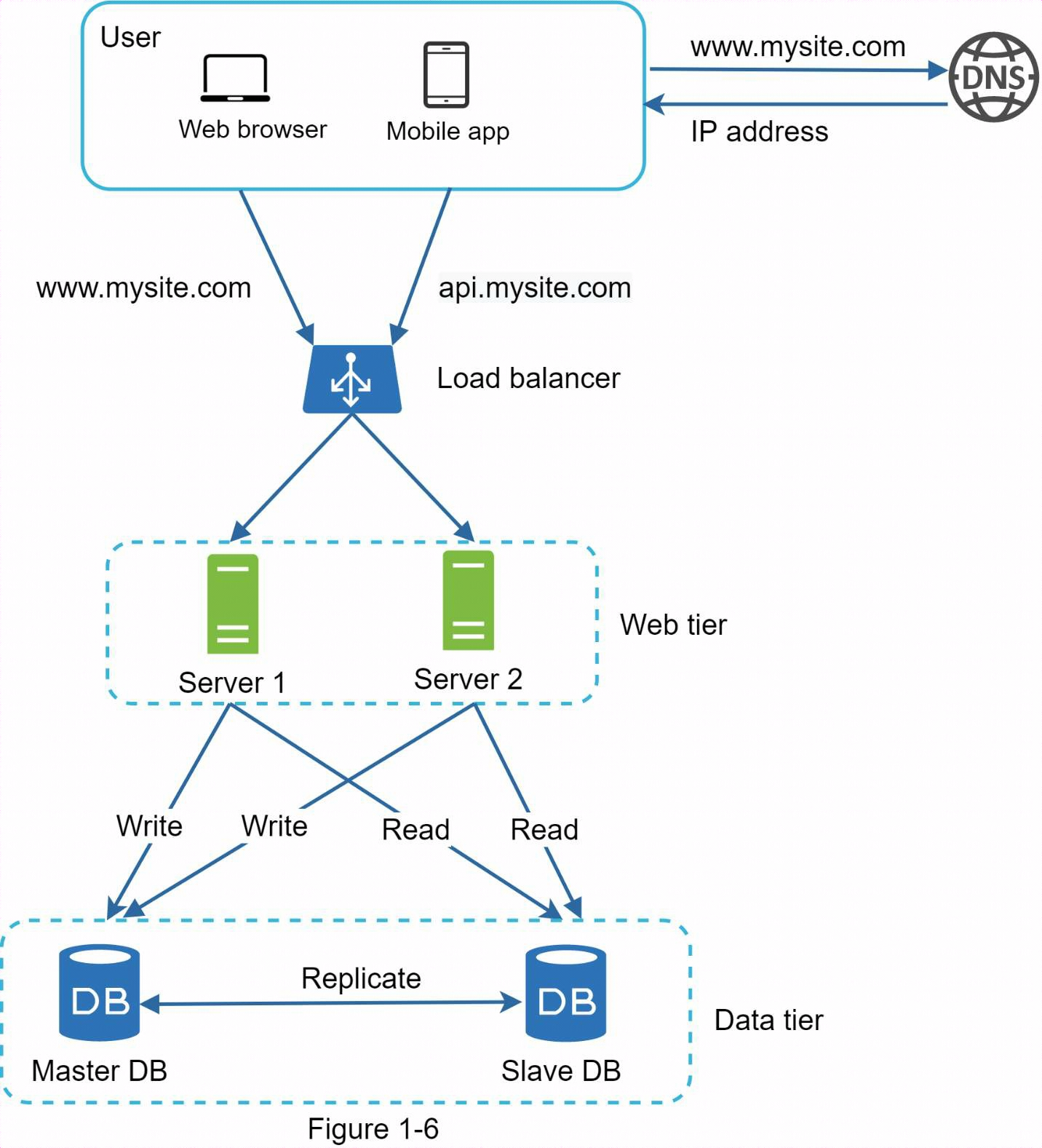
-
用戶從DNS獲取負載均衡器的IP
-
用戶使用該IP連接負載均衡器
-
HTTP請求被路由到伺服器1或伺服器2。
-
Web伺服器從從資料庫中讀取用戶數據。
-
Web伺服器將任何數據修改操作路由至主資料庫。這包括寫入、更新和刪除操作。
1.6 緩存
緩存是一個臨時存儲區域,用於將昂貴的響應結果或頻繁訪問的數據存儲在記憶體中,以便更快地處理後續請求。每次載入新網頁時,都會執行一次或多次資料庫調用來獲取數據。重覆調用資料庫會極大地影響應用程式的性能。緩存可以緩解這一問題。

緩存是臨時數據存儲層,速度比資料庫快得多。擁有獨立緩存層的好處包括:更好的系統性能、減少資料庫工作負載的能力以及獨立擴展緩存層的能力。上圖顯示了緩存伺服器的可能設置:
網路伺服器收到請求後,首先會檢查緩存中是否有可用的響應。如果有,則將數據發送回客戶端。如果沒有,它就會查詢資料庫,將響應存儲在緩存中,然後發送回客戶端。這種緩存策略稱為直讀緩存。根據數據類型、大小和訪問模式的不同,還有其他緩存策略可供選擇。
與緩存伺服器交互非常簡單,因為大多數緩存伺服器都提供了適用於常見編程語言的API。下麵的代碼片段展示了典型的 Memcached API:

1.6.1 使用緩存的註意事項
以下是使用緩存系統的一些註意事項:
-
決定何時使用緩存。當數據讀取頻繁但修改不頻繁時,考慮使用緩存。由於緩存數據存儲在易失性記憶體中,因此緩存伺服器不是持久化數據的理想選擇。例如,如果緩存伺服器重新啟動,記憶體中的所有數據都會丟失。因此,重要數據應保存在持久化數據存儲中。
-
過期策略。實施過期策略是一種很好的做法。緩存數據一旦過期,就會從緩存中刪除。如果沒有過期策略,緩存數據將永久保存在記憶體中。過期日期最好不要太短,因為這會導致系統過於頻繁地從資料庫中重新載入數據。同時,過期日期也不宜過長,否則數據會變得陳舊。
-
一致性: 這包括保持數據存儲和緩存同步。由於數據存儲和緩存上的數據修改操作不是在單個事務中進行的,因此可能會出現不一致。在跨多個區域擴展時,保持數據存儲和高速緩存之間的一致性具有挑戰性。更多詳情,請參閱 Facebook 發佈的題為 "Scaling Memcache at Facebook "的論文。
-
緩解故障: 單個緩存伺服器代表一個潛在的單點故障(SPOF single point of failure),維基百科的定義如下: "單點故障(SPOF)是系統中的一個部分,如果它發生故障,整個系統將停止工作"。因此,為避免單點故障,建議在不同的數據中心安裝多個高速緩存伺服器。另一種推薦方法是按一定比例超額配置所需的記憶體。這可以在記憶體使用量增加時提供緩衝。
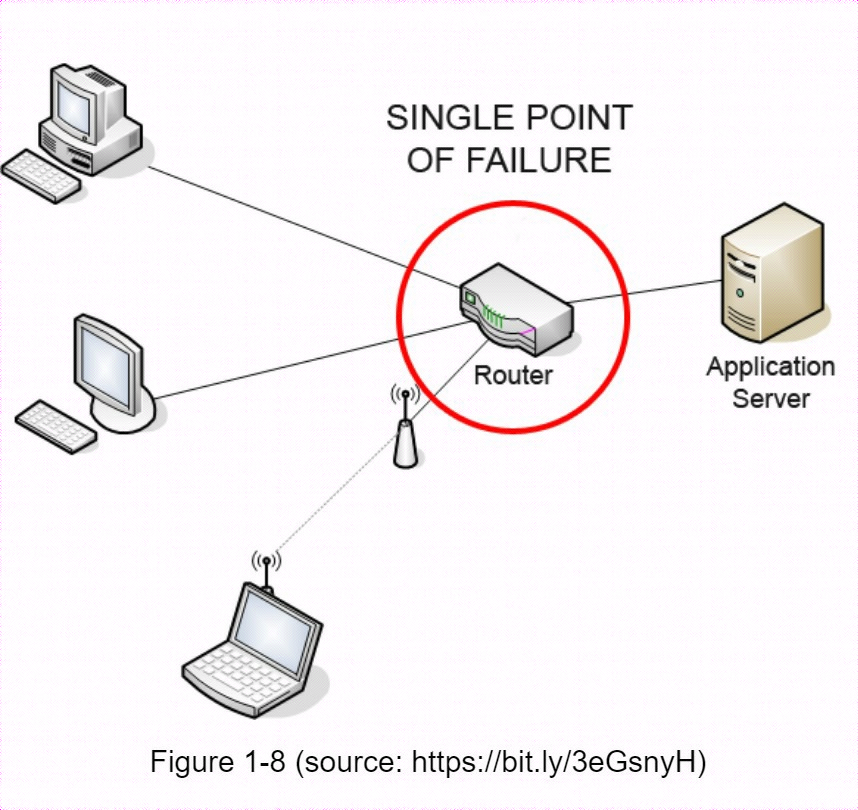
- 禁用策略: 一旦緩存已滿,任何向緩存添加項目的請求都可能導致現有項目被刪除。這就是所謂的緩存驅逐。最近最少使用(LRU Least-recently-used)是最流行的緩存驅逐策略。還可以採用其他驅逐策略,如最不常用(LFU)或先進先出(FIFO First in First Out),以滿足不同的使用情況。
1.7 CDN
CDN是一個由地理位置分散的伺服器組成的網路,用於傳輸靜態內容。CDN 伺服器緩存圖片、視頻、CSS、JavaScript 文件等靜態內容。
動態內容緩存是一個相對較新的概念,超出了本書的討論範圍。它可以根據請求路徑、查詢字元串、cookie 和請求標頭緩存 HTML頁面。
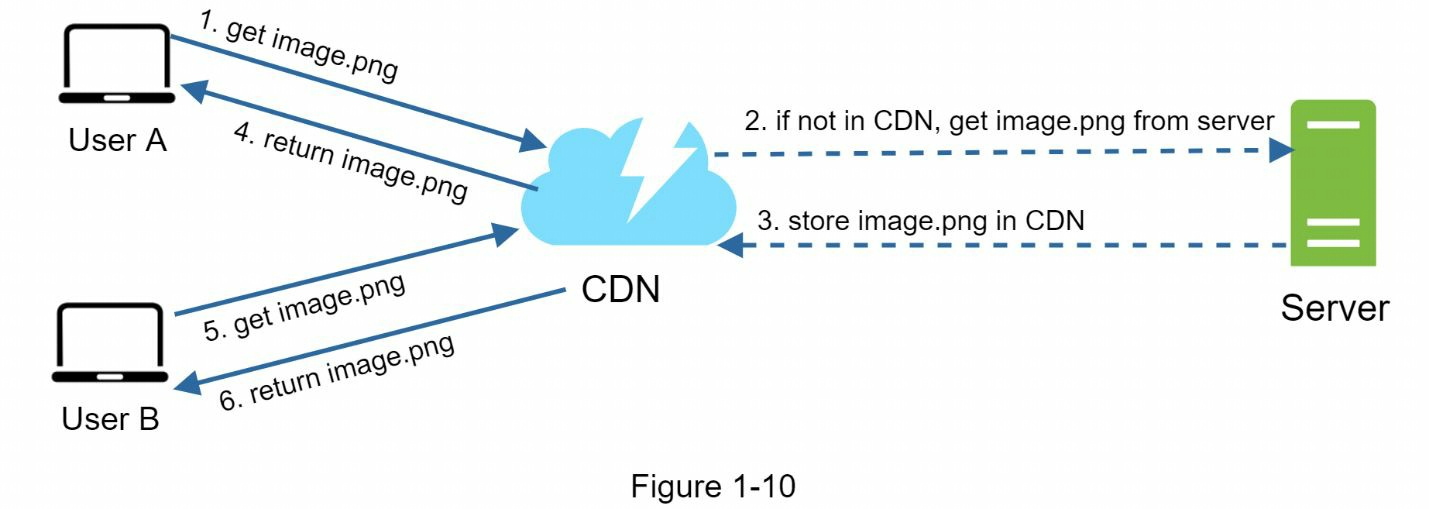
以下是CDN的高級工作原理:當用戶訪問網站時,離用戶最近的CDN伺服器將傳輸靜態內容。直觀地說,用戶離CDN伺服器越遠,網站載入速度就越慢。例如,如果CDN伺服器位於舊金山,那麼洛杉磯的用戶獲取內容的速度就會比歐洲的用戶快。
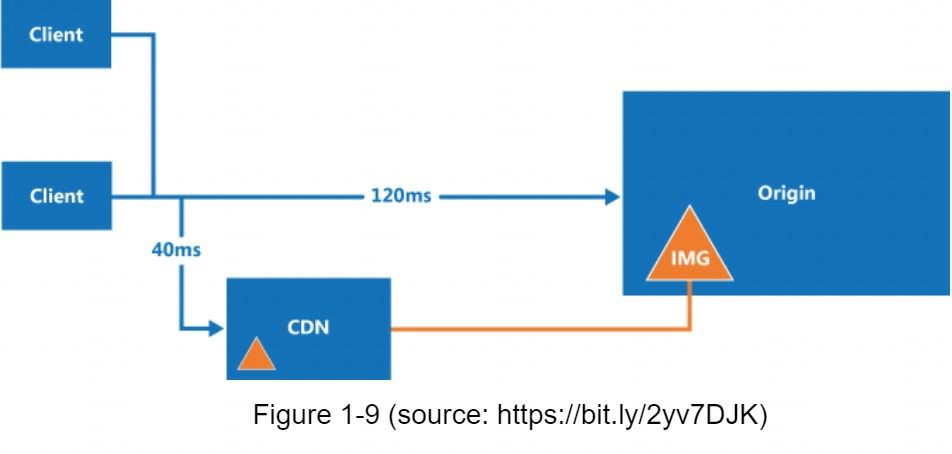
工作流:
-
用戶嘗試使用圖片URL獲取image.png。URL的功能變數名稱由CDN提供商提供。
-
如果CDN伺服器的緩存中沒有image.png,CDN伺服器就會從原點請求文件,原點可以是網路伺服器或線上存儲(如 Amazon S3)。
-
源伺服器將image.png返回給CDN伺服器,其中包括可選的HTTP標頭Time-to-Live (TTL),用於描述圖像的緩存時間。
-
CDN緩存圖像並將其返回給用戶A。
-
用戶B發送請求獲取相同的圖像。
-
只要TTL未過期,圖像就會從緩存中返回。
1.7.1 使用CDN的註意事項
-
成本: CDN由第三方提供商運行,您需要為進出CDN的數據傳輸付費。緩存不經常使用的資產不會帶來明顯的好處,因此應考慮將它們移出CDN。
-
設置適當的緩存到期時間: 對於時間敏感的內容,設置緩存過期時間非常重要。緩存過期時間既不能太長,也不能太短。如果時間過長,內容可能不再新鮮。如果時間太短,則可能導致重覆重新載入從原始伺服器到 CDN 的內容。
-
CDN回退: 應考慮網站/應用程式如何應對CDN故障。如果CDN出現暫時中斷,客戶端應能檢測到問題並從源伺服器請求資源。
-
無效文件: 您可以通過執行以下操作之一,在文件過期前將其從 CDN 中刪除:
- 使用CDN供應商提供的API使CDN對象失效。
- 使用對象版本控制提供不同版本的對象。要對對象進行版本控制,可以在URL中添加一個參數,如版本號。例如,在查詢字元串中添加版本號2:image.png?v=2。
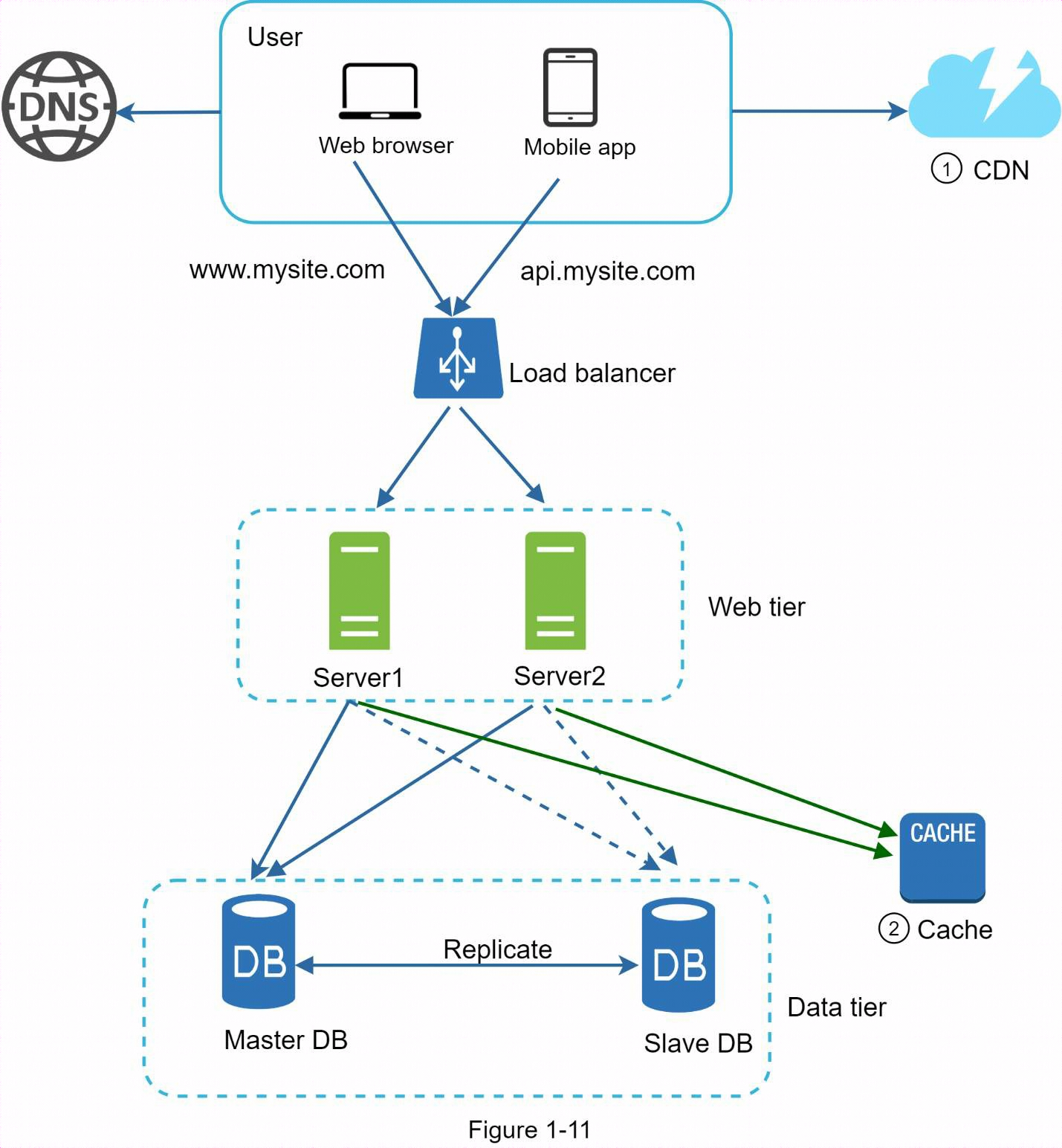
- 靜態資產(JS、CSS、圖片等)不再由Web伺服器提供。它們從CDN抓取,以獲得更好的性能。
- 通過緩存數據減輕資料庫負載。
1.8 無狀態Web層
將會話數據存儲在關係資料庫或NoSQL等持久存儲中。集群中的每個網路伺服器都可以訪問資料庫中的狀態數據。這就是所謂的無狀態Web層。
1.8.1 有狀態架構
有狀態伺服器和無狀態伺服器有一些主要區別。有狀態伺服器從一個請求到下一個請求都會記住客戶端數據(狀態)。無狀態伺服器不保存任何狀態信息。
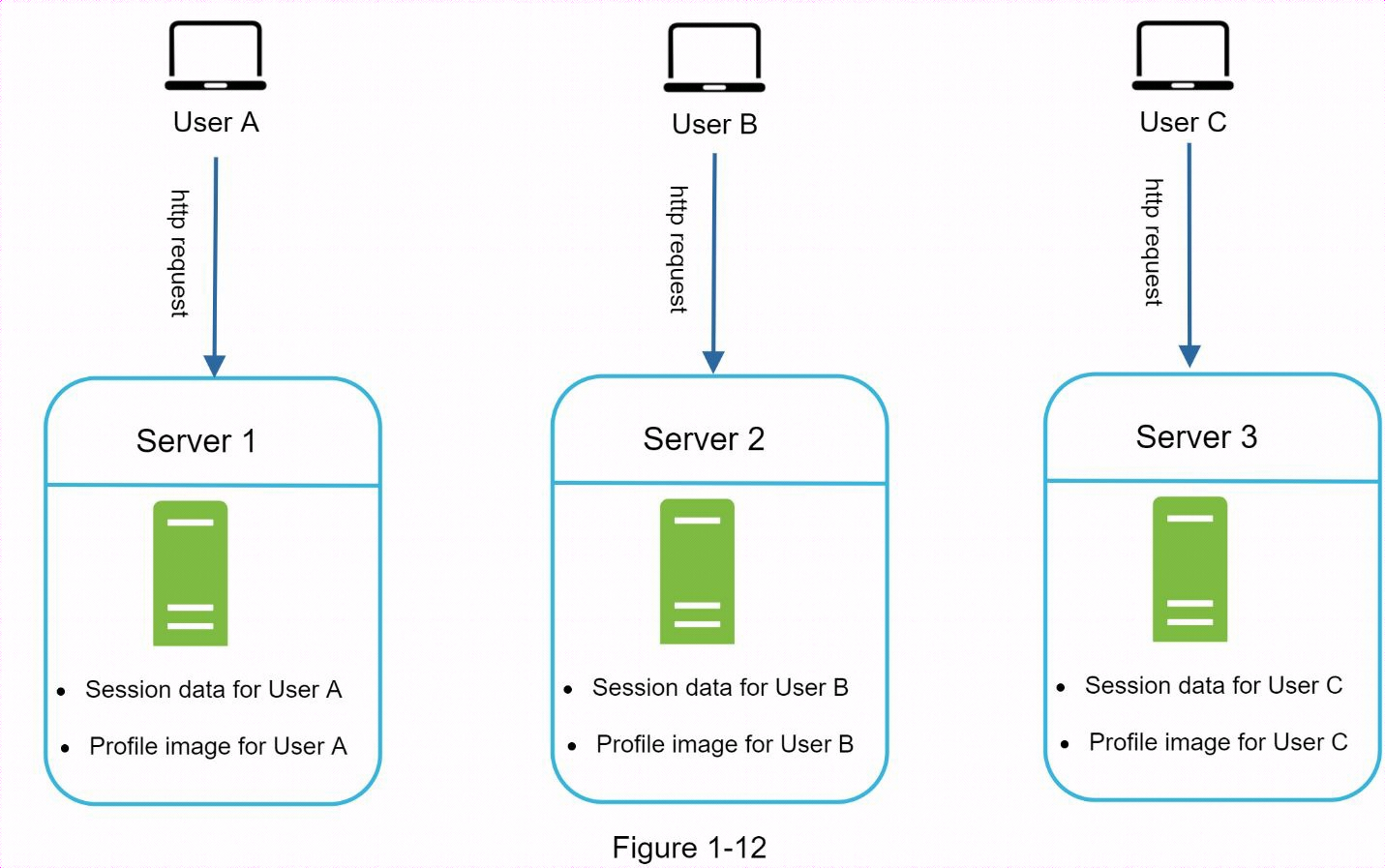
用戶A的會話數據和個人資料圖像存儲在伺服器1中。要對用戶A進行身份驗證,HTTP請求必須路由到伺服器1。如果請求被髮送到其他伺服器(如伺服器2),身份驗證就會失敗,因為伺服器2不包含用戶A的會話數據。同樣,用戶B的所有 HTTP 請求都必鬚髮送到伺服器2;用戶C的所有請求都必鬚髮送到伺服器3。
來自同一個客戶端的每個請求都必須路由到同一個伺服器。這可以通過大多數負載均衡器中的粘性會話來實現,但這會增加開銷。使用這種方法添加或刪除伺服器要困難得多。處理伺服器故障也很有挑戰性。
1.8.2 無狀態架構
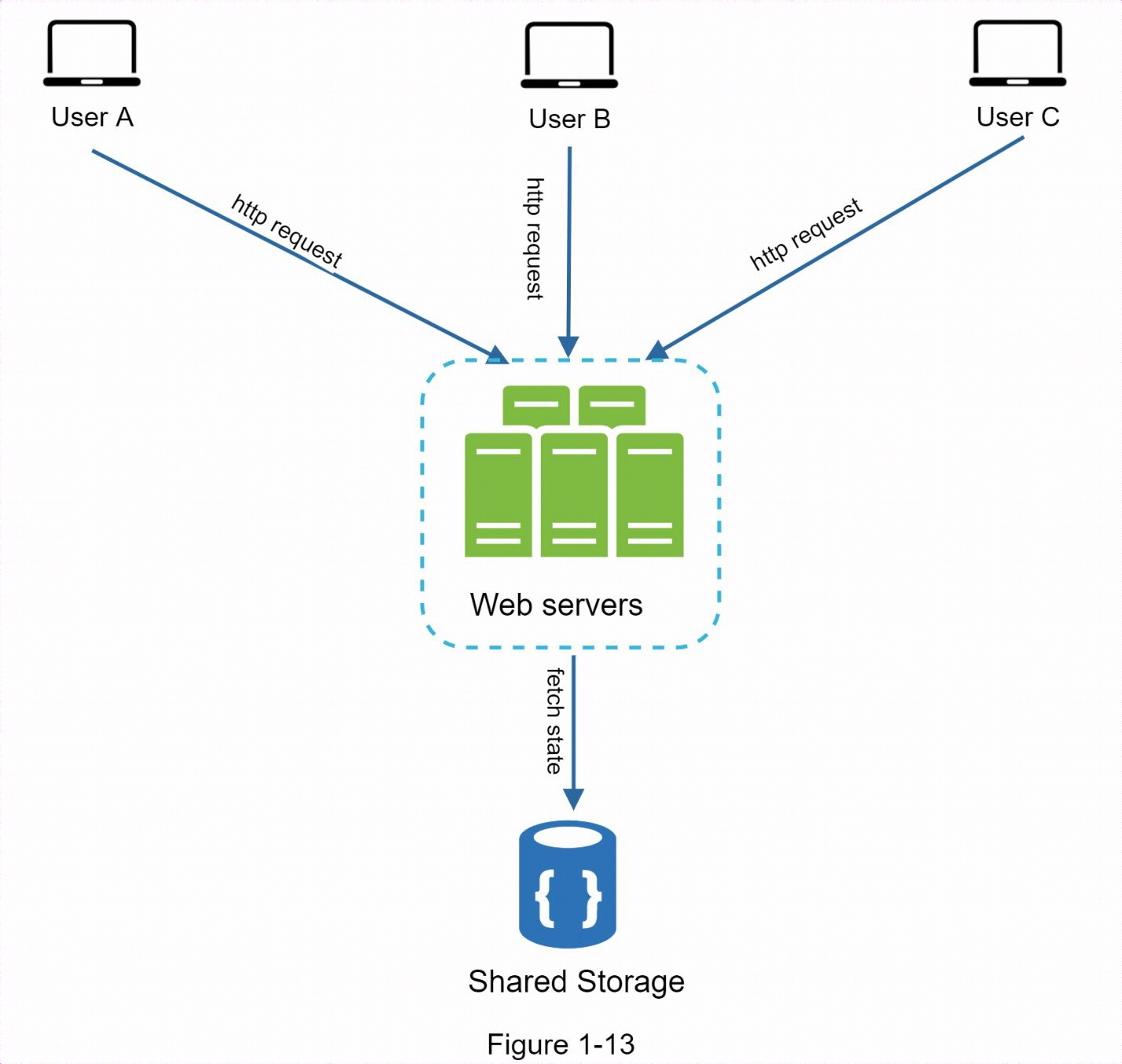
在這種無狀態架構中,用戶的HTTP請求可以發送到任何網路伺服器,由伺服器從共用數據存儲區獲取狀態數據。狀態數據存儲在共用數據存儲區,不與網路伺服器相連。無狀態系統更簡單、更健壯、可擴展。
我們將會話數據移出網路層,並將其存儲在持久化數據存儲區中。共用數據存儲可以是關係資料庫、Memcached/Redis、NoSQL 等。之所以選擇NoSQL數據存儲,是因為它易於擴展。自動擴展是指根據流量負載自動添加或移除網路伺服器。從網路伺服器中移除狀態數據後,根據流量負載添加或移除伺服器,就能輕鬆實現網路層的自動擴展。
參考資料
- 軟體測試精品書籍文檔下載持續更新 https://github.com/china-testing/python-testing-examples 請點贊,謝謝!
- 本文涉及的python測試開發庫 謝謝點贊! https://github.com/china-testing/python_cn_resouce
- python精品書籍下載 https://github.com/china-testing/python_cn_resouce/blob/main/python_good_books.md
- Linux精品書籍下載 https://www.cnblogs.com/testing-/p/17438558.html
- https://www.drawio.com/doc/faq/
- Hypertext Transfer Protocol: https://en.wikipedia.org/wiki/Hypertext_Transfer_Protocol
- Should you go Beyond Relational Databases?:
https://blog.teamtreehouse.com/should-you-go-beyond-relational-databases - Replication: https://en.wikipedia.org/wiki/Replication_(computing)
- Multi-master replication:
https://en.wikipedia.org/wiki/Multi-master_replication - NDB Cluster Replication: Multi-Master and Circular Replication:
https://dev.mysql.com/doc/refman/5.7/en/mysql-cluster-replication-multi-master.html - Caching Strategies and How to Choose the Right One:
https://codeahoy.com/2017/08/11/caching-strategies-and-how-to-choose-the-right-one/ - R. Nishtala, "Facebook, Scaling Memcache at," 10th USENIX Symposium on Networked
Systems Design and Implementation (NSDI ’13). - Single point of failure: https://en.wikipedia.org/wiki/Single_point_of_failure
- Amazon CloudFront Dynamic Content Delivery:
https://aws.amazon.com/cloudfront/dynamic-content/ - Configure Sticky Sessions for Your Classic Load Balancer:
https://docs.aws.amazon.com/elasticloadbalancing/latest/classic/elb-sticky-sessions.html - Active-Active for Multi-Regional Resiliency:
https://netflixtechblog.com/active-active-for-multi-regional-resiliency-c47719f6685b - Amazon EC2 High Memory Instances:
https://aws.amazon.com/ec2/instance-types/high-memory/ - What it takes to run Stack Overflow:
http://nickcraver.com/blog/2013/11/22/what-it-takes-to-run-stack-overflow - What The Heck Are You Actually Using NoSQL For:
http://highscalability.com/blog/2010/12/6/what-the-heck-are-you-actually-using-nosql-
for.html
1.9 數據中心
下圖顯示了兩個數據中心的設置示例。在正常運行時,用戶會被geoDNS-routed(也稱為地理路由到最近的數據中心,其中大明東部的流量占x%,大明西部的流量占(100 - x)%。地理DNS是一種DNS服務,可根據用戶的位置將功能變數名稱解析為IP地址。
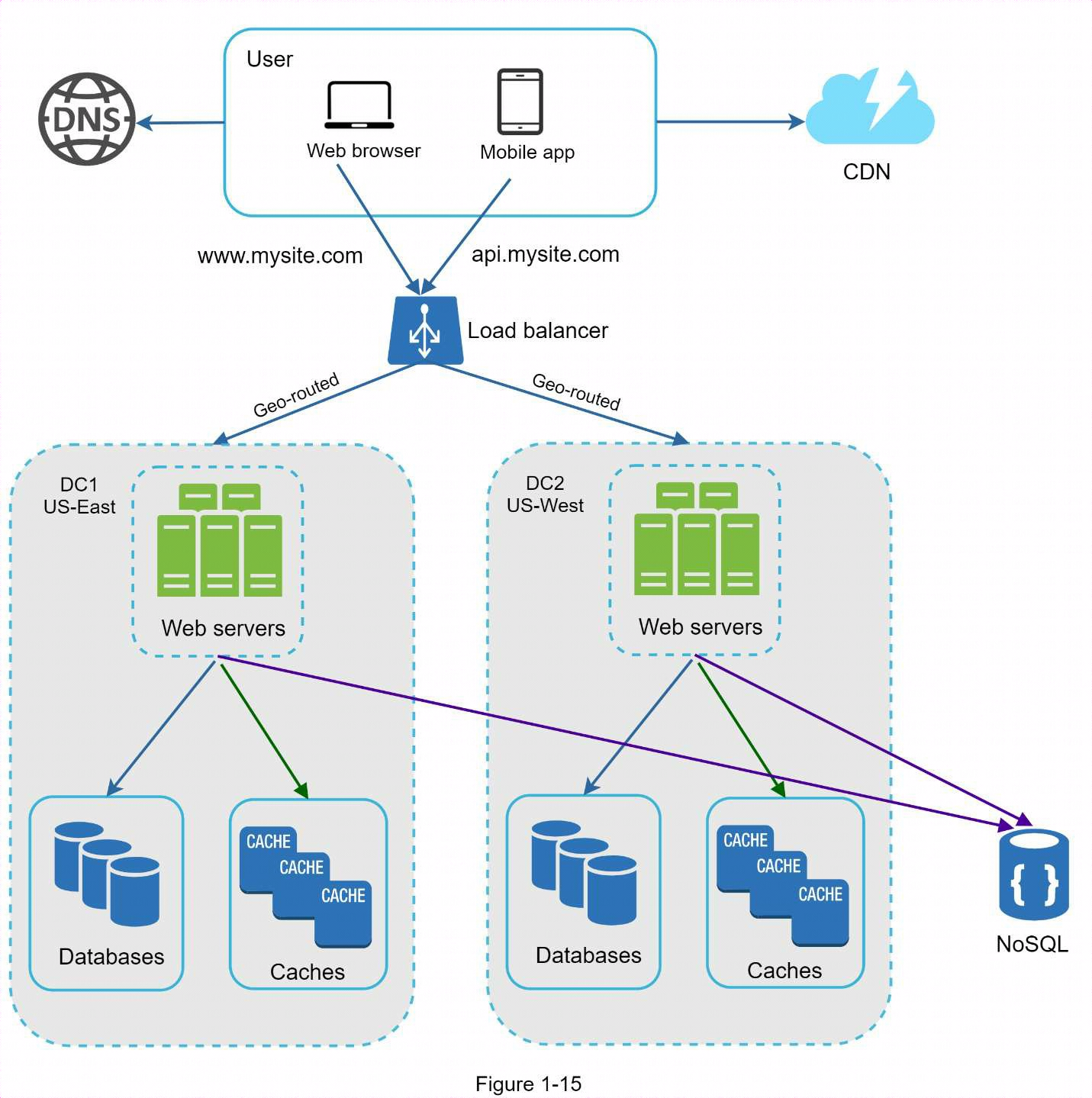
如果數據中心發生重大故障,我們會將所有流量引導到健康的數據中心。
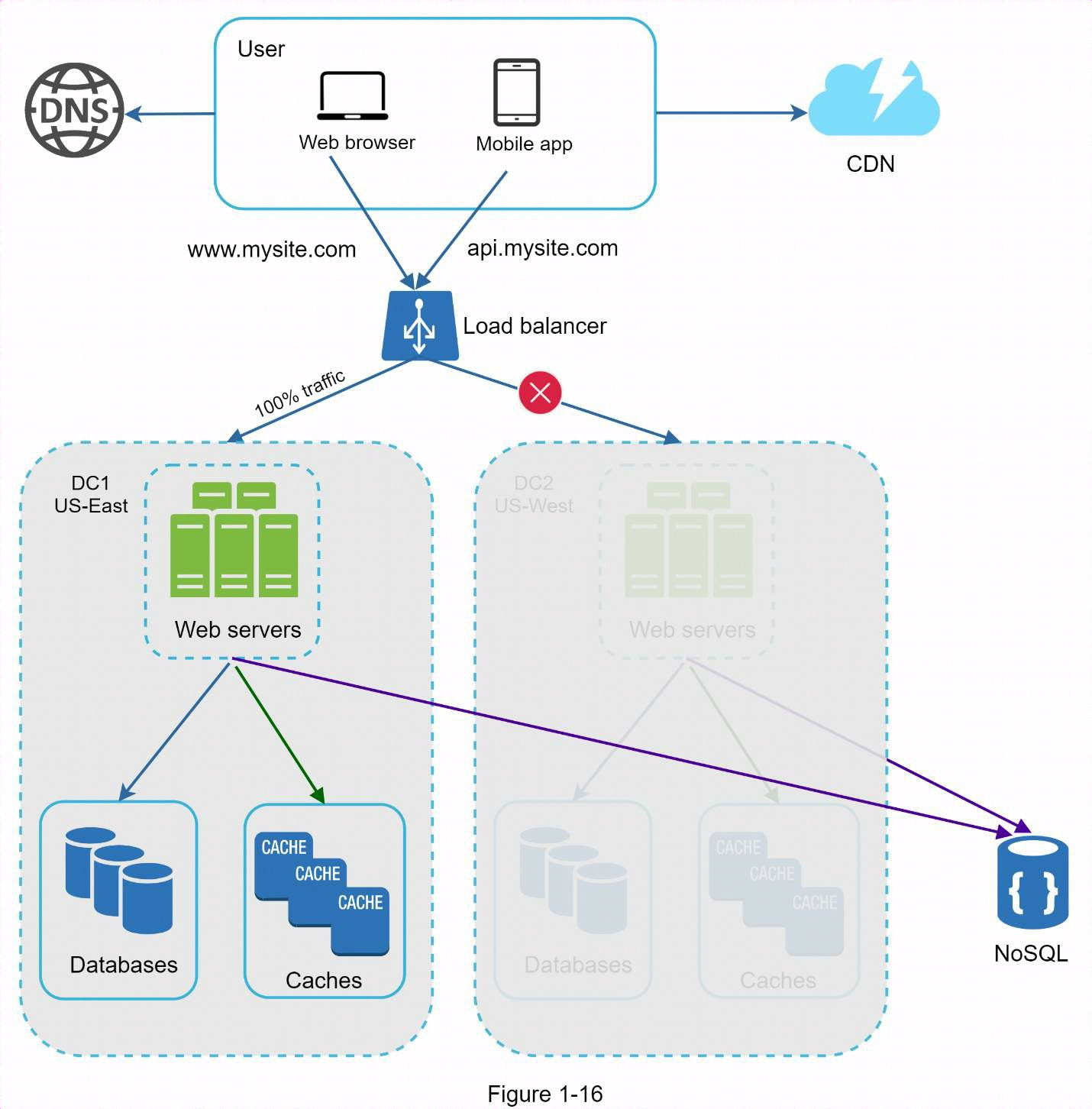
要實現多數據中心設置,必須解決幾個技術難題:
- 流量重定向
需要有效的工具將流量導向正確的數據中心。可使用GeoDNS根據用戶所在位置將流量導向最近的數據中心。
- 數據同步
不同地區的用戶可能使用不同的本地資料庫或緩存。在故障切換情況下,流量可能會被路由到數據不可用的數據中心。一種常見的策略是在多個數據中心之間複製數據。
- 測試和部署
通過多數據中心設置,在不同地點測試網站/應用程式非常重要。自動部署工具對於在所有數據中心保持服務一致性至關重要 。
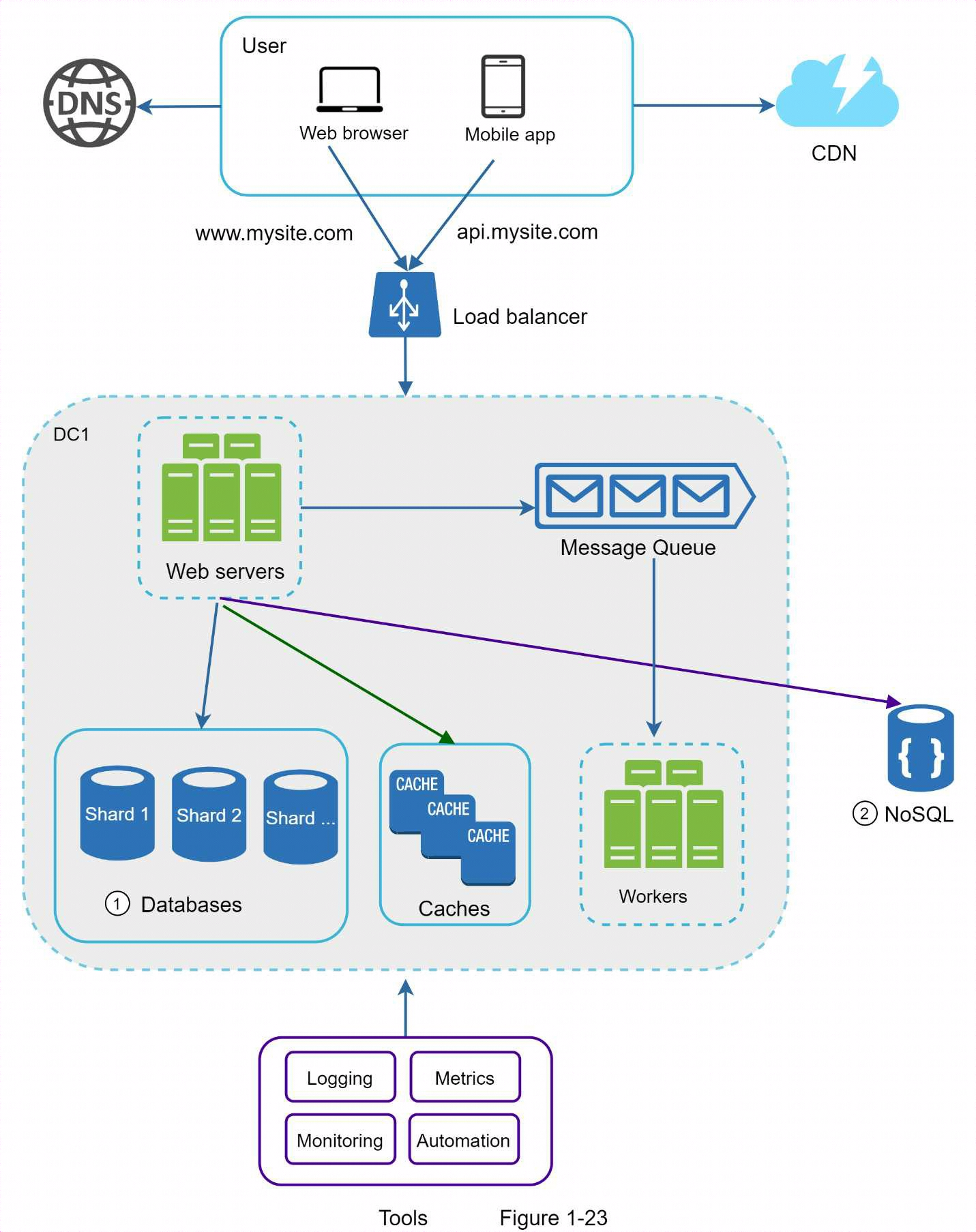
為了進一步擴展我們的系統,我們需要將系統的不同組件解耦,以便它們可以獨立擴展。消息隊列是現實世界中許多分散式系統解決這一問題的關鍵策略。
1.10 消息隊列
消息隊列是一個存儲在記憶體中的持久組件,支持非同步通信。它充當緩衝器並分發非同步請求。消息隊列的基本架構很簡單。被稱為生產者/發佈者的輸入服務創建消息,並將其發佈到消息隊列。其他服務或伺服器(稱為消費者/訂閱者)連接到隊列,並執行消息定義的操作。

解耦使消息隊列成為構建可擴展和可靠應用程式的首選架構。有了消息隊列,當消費者無法處理消息時,生產者可以將消息發佈到隊列中。即使生產者不可用,消費者也能從隊列中讀取消息。
考慮以下用例:您的應用程式支持照片定製,包括裁剪、銳化、模糊等。這些定製任務需要時間來完成。下圖中,網路伺服器將照片處理任務發佈到消息隊列。照片處理工作者從消息隊列中拾取任務,並非同步執行照片定製任務。生產者和消費者可以獨立擴展。當隊列規模變大時,就會增加更多的工人來縮短處理時間。但是,如果隊列大部分時間是空的,則可以減少工人數量。
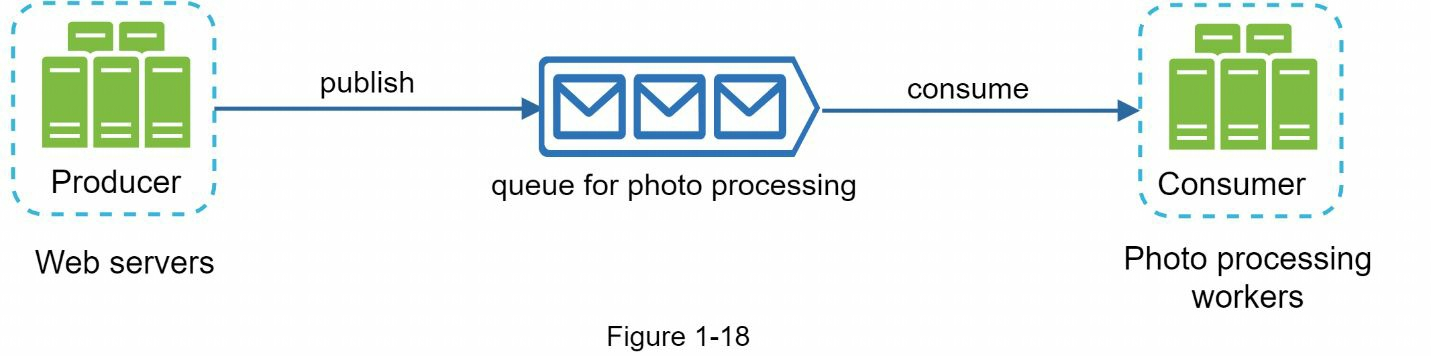
1.11 日誌、指標、自動化
在幾個伺服器上運行小型網站時,日誌記錄、指標和自動化支持是很好的做法,但並非必需。但是,現在您的網站已經發展成為一個大型企業,投資這些工具就顯得非常必要了。
- 日誌記錄
監控錯誤日誌非常重要,因為它有助於識別系統中的錯誤和問題。您可以監控每個伺服器級別的錯誤日誌,也可以使用工具將它們彙總到一個集中服務中,以便於搜索和查看。
-
指標: 收集不同類型的指標有助於我們獲得業務洞察力並瞭解系統的健康狀況。以下一些指標非常有用:
- 主機級指標: CPU、記憶體、磁碟 I/O 等。
- 聚合級指標:例如,整個資料庫層、緩存層等的性能。
- 關鍵業務指標:日活躍用戶、留存率、收入等。
-
自動化
當系統變得龐大而複雜時,我們需要構建或利用自動化工具來提高生產率。持續集成是一種很好的做法,它通過自動化驗證每個代碼的簽入,使團隊能夠及早發現問題。此外,將構建、測試和部署流程等自動化也能顯著提高開發人員的工作效率。
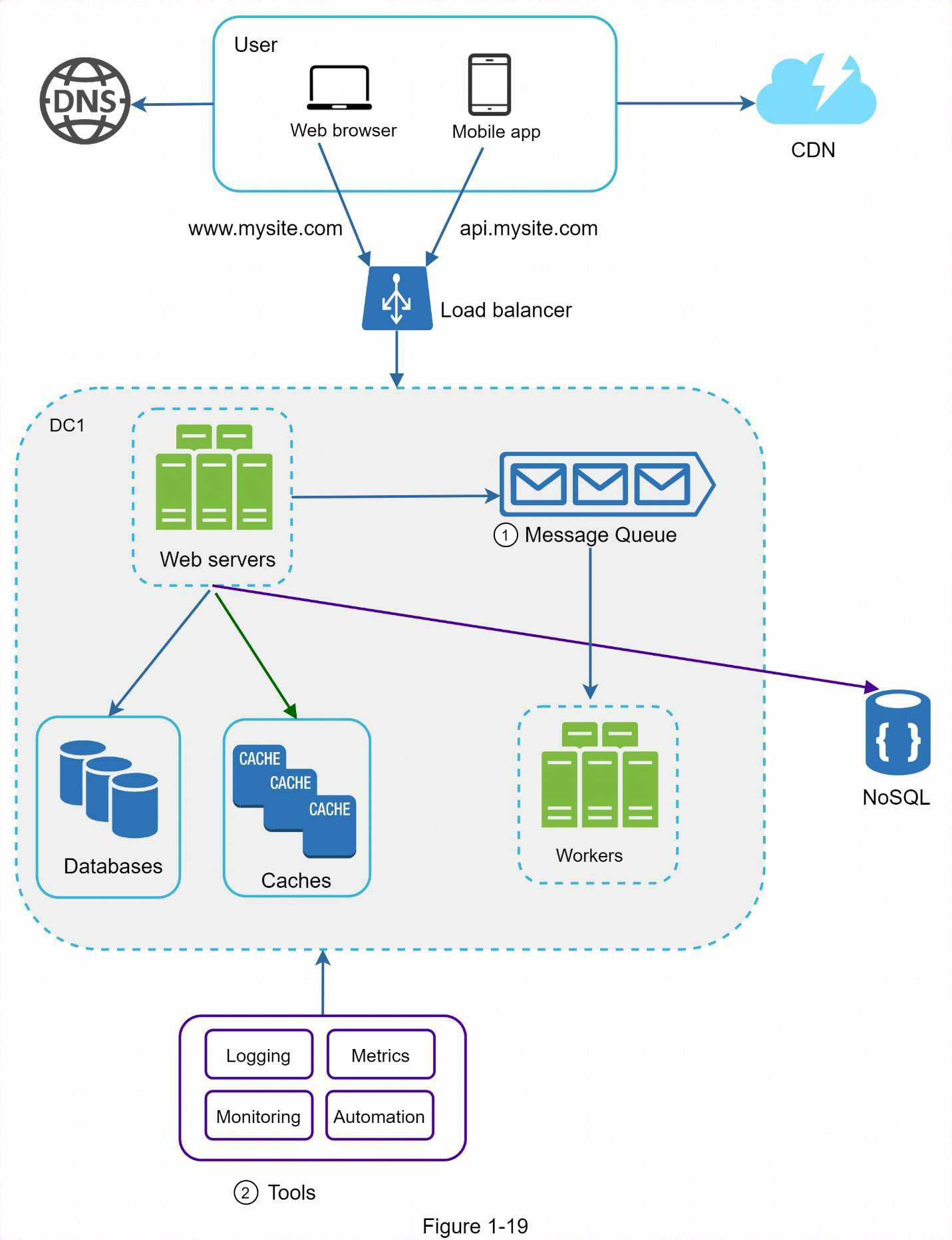
- 該設計包含一個消息隊列,有助於使系統更加鬆散耦合和具有故障彈性。
- 包括日誌、監控、度量和自動化工具。
1.12 資料庫擴展
資料庫擴展有兩大方法:垂直擴展和水平擴展。
1.12.1 垂直擴展
縱向擴展,也稱為向上擴展,是指在現有機器上增加更多功率(CPU、RAM、DISK 等)。有一些功能強大的資料庫伺服器。根據亞馬遜關係資料庫服務(RDS),你可以獲得一個擁有24TB記憶體的資料庫伺服器。這種強大的資料庫伺服器可以存儲和處理大量數據。例如,stackoverflow.com 在2013年的月獨立訪客數超過1000萬,但它只有一個主資料庫。不過,縱向擴展也有一些嚴重的缺點:
- 您可以為資料庫伺服器增加更多的 CPU、記憶體等,但這是有硬體限制的。如果用戶基數大,單個伺服器是不夠的。
- 單點故障風險更大。
- 垂直擴展的總體成本較高。功能強大的伺服器成本更高。
1.12.2 橫向擴展
水平擴展也稱為分片,是增加更多伺服器的做法。
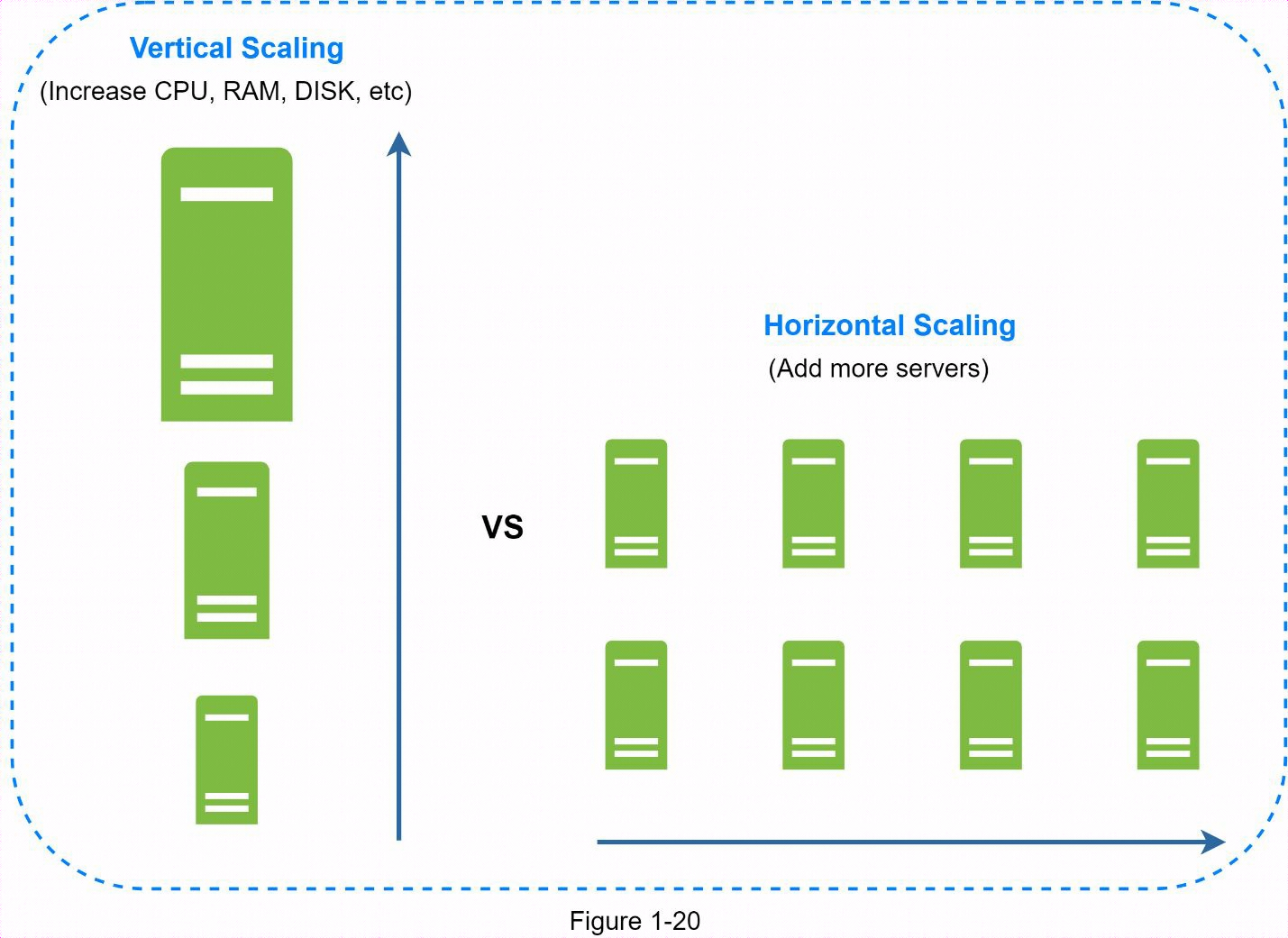
分片將大型資料庫分成更小、更易於管理的部分,稱為分片。每個分片共用相同的模式,但每個分片上的實際數據都是獨一無二的。
下圖顯示了分片資料庫的示例。用戶數據是根據用戶ID分配給資料庫伺服器的。每次訪問數據時,都會使用哈希函數找到相應的分片。在我們的示例中,user_id % 4被用作散列函數。如果結果等於0,則0分區用於存儲和獲取數據。如果結果等於1,則使用分區1。同樣的邏輯也適用於其他分區。
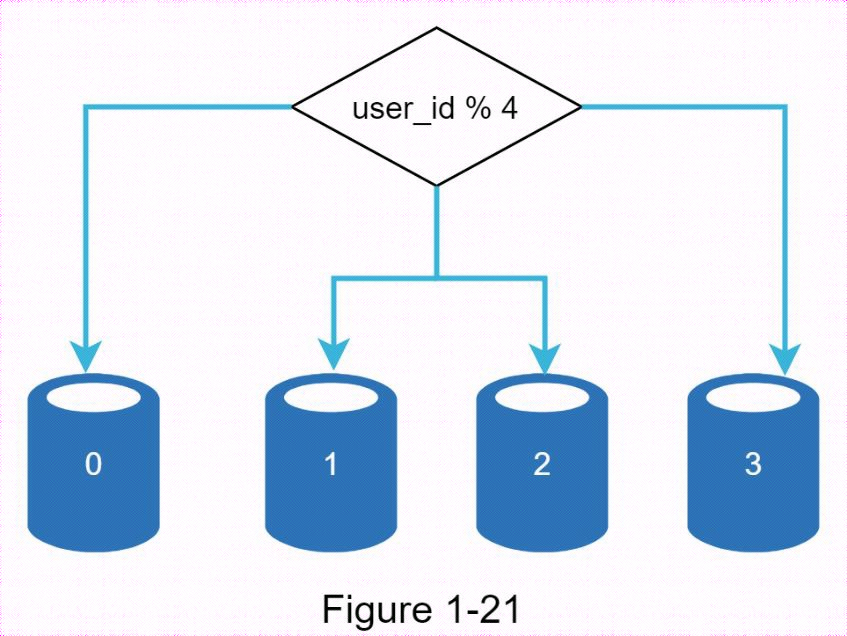
實施分片策略時需要考慮的最重要因素是分片鍵的選擇。分片鍵(稱為分區鍵)由一列或多列組成,決定了數據的分配方式。下圖"user_id "就是分片鍵。通過分片鍵,可以將資料庫查詢路由到正確的資料庫,從而有效地檢索和修改數據。在選擇分片鍵時,最重要的標準之一是選擇一個能均勻分佈數據的鍵。
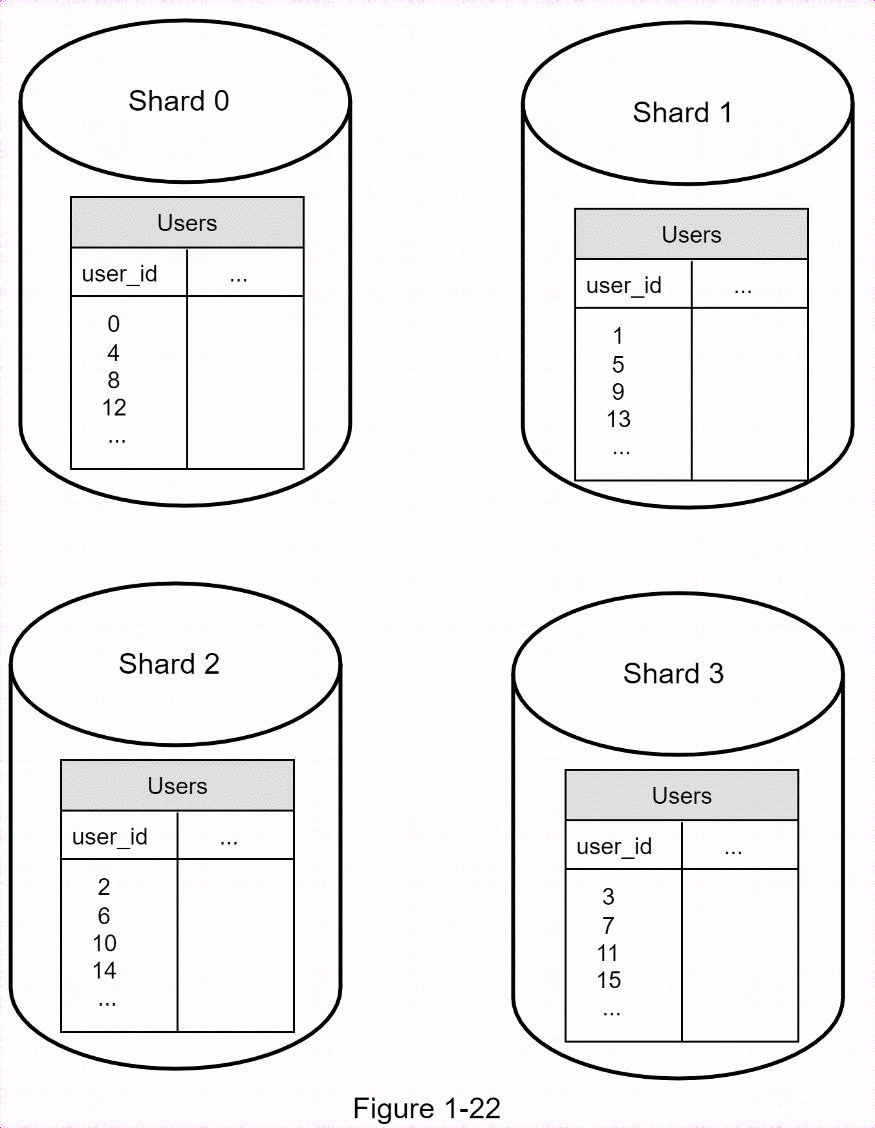
分片是一種擴展資料庫的好技術,但遠非完美的解決方案。它給系統帶來了複雜性和新的挑戰:
-
數據重分片: 當出現以下情況時,需要對數據進行重新分片:1)由於數據增長過快,單個分片無法再容納更多數據。2) 由於數據分佈不均,某些分區可能比其他分區更快出現分區耗盡。當分片耗盡時,需要更新分片功能並移動數據。第5章將討論的一致性散列是解決這一問題的常用技術。
-
名人問題:這也叫熱點密鑰問題。對特定分片的過度訪問會導致伺服器超載。試想一下,凱蒂-佩里、賈斯汀-比伯和 Lady Gaga 的數據都在同一分片上。對於社交應用來說,讀取操作將使該分區不堪重負。為瞭解決這個問題,我們可能需要為每個名人分配一個分區。每個分區甚至可能需要進一步劃分。
-
連接和去規範化: 一旦資料庫被分到多個伺服器上,就很難在資料庫分片之間執行連接操作。常見的解決方法是去規範化資料庫,以便在單個表中執行查詢。
我們對資料庫進行分片,以支持快速增長的數據流量。同時,一些非關係型功能被轉移到NoSQL數據存儲中,以減少資料庫負載。
1.13 更多用戶
擴展系統是一個迭代過程。迭代本章所學的內容可以讓我們走得更遠。要擴展到數百萬用戶以上,還需要更多的微調和新策略。例如,你可能需要優化系統並將系統解耦為更小的服務。本章所學的所有技術應能為應對新挑戰打下良好基礎。在本章的最後,我們總結瞭如何擴展系統以支持數百萬用戶:
- 保持網路層無狀態
- 在每個層建立冗餘
- 儘可能多地緩存數據
- 支持多個數據中心
- 在CDN中托管靜態資產
- 通過分片擴展數據層
- 將層級拆分為單個服務
- 監控系統並使用自動化工具


