
1.現實中的問題 我們知道資料庫的數據,基本80%的業務是查詢,20%的業務涵蓋了增刪改,經過長期的業務變更和積累資料庫的數據到達了一定的數量之後,直接影響的是用戶與系統的交互,查詢時的速度,插入數據時的流暢度,系統的可用性,這些指標對用戶體驗都是會有影響的,不說用戶,你自己用是什麼感覺?我經歷過且 ...
1.現實中的問題
我們知道資料庫的數據,基本80%的業務是查詢,20%的業務涵蓋了增刪改,經過長期的業務變更和積累資料庫的數據到達了一定的數量之後,直接影響的是用戶與系統的交互,查詢時的速度,插入數據時的流暢度,系統的可用性,這些指標對用戶體驗都是會有影響的,不說用戶,你自己用是什麼感覺?我經歷過且常見的無非以下幾個解決方案,從用戶,代碼,資料庫,不知道有沒有人跟我有相似的經歷
1.最簡單粗暴的就是從用戶下手,也就是通過業務的手段來約束,限定查詢時間,限定查詢條件,大批量需要申請後臺工程師導出,不是說對這些方法嗤之以鼻,在某些場景下這樣也是不錯的方法.
2.檢查代碼,查詢語句什麼的能優化的做下優化,這一點確實也是比較關鍵的,再好的架構和伺服器,也頂不住遞歸死迴圈查詢這些.
3.結合一些資料庫監控工具或者對常用查詢的表,做一些資料庫基本的屬性設定,例如資料庫加索引,分分區.
雖然確實可以使用這些技術手段來提升本身的查詢速度,但是達到一定量級,這些手段得到的改善也不是很大,因為數據的量是實實在在的存在,假設此時加上併發量的增大,資料庫引擎在查詢或者計算時,使用的是伺服器的CPU和記憶體,當資源消耗過高時,直接降低系統可用性,往往這個時候就需要通過整體業務上的變通或者技術架構的轉換上來著手解決問題了。
然而現實中業務上的改變,可能在落實上會存在很大的問題,但是可以從技術架構上來嘗試解決,主要在代碼整體架構或者資料庫存儲架構解決了,我們主要介紹數據架構層面的方案。
1.分庫
-
在水平分庫中,就是將資料庫中的表,存到不同的資料庫,但是不同庫的表數量和結構是一樣的,只是每個庫的數據都不一樣,沒有交集,庫的並集是全量數據
-
在垂直分庫中,以表為依據,按照業務歸屬不同,將不同的表拆分到不同的庫中,不同的庫存儲的可能是不同的表,庫的並集是全量數據
2.分表
-
水平分表就是將一張表分為多張表,表的結構都一樣,每個表的數據都不一樣,沒有交集,所有表的並集是全量數據;
-
垂直分表將一張表欄位拆分為不同的表,合併起來就是整個全量數據,但是這種可以歸屬於設計之初的設計缺陷
雖然使用分庫分表可以一定程度解決上面所說的問題,但是分了之後也有可能再變大,總不能一直無腦拆分下去把,此時應該使用讀寫分離,也就是說讀寫分離應該是在分庫分表的基礎之上來實施的。
2.什麼是ShardingSphere-Proxy?
在ShardingSphere中一共有3個核心組件 ShardingSphere-JDBC 定位是一個Java的框架 、ShardingSphere-Proxy、ShardingSphere-Sidecar 還在開發中,我們主要介紹ShardingSphere-Proxy和ShardingSphere-Proxy的實際應用。
ShardingSphere-Proxy定位為透明化的資料庫代理端,提供封裝了資料庫二進位協議的服務端版本,用於完成對異構語言的支持,主要目的對資料庫實現分庫分表和讀寫分離,應用場景不管是傳統的單體項目,或者現有流行的微服務項目中都可以使用,但是目前只支持 MySQL 和 PostgreSQL , 它在整個系統架構中定位是一個資料庫中間件。
在這裡我們選擇使用ShardingSphere-Proxy中間件,來作為我們實現分庫分表的工具,寫這個的目的主要是記錄ShardingSphere-Proxy的使用和一些基本的概念,至於說具體分成什麼樣,如果您只想知道到底是分表,還是分庫,又或者是分庫分表,我可能幫不了什麼,但是您可以按照現在所困擾的問題展開分析,然後使用ShardingSphere-Proxy落地。
3.分庫分表方案
實現分庫分表的方案根據不同的需求可能會延伸出很多,但是我們在邏輯上抽象出2種,一種是進程內和業務系統集成,一種是拆分出分庫分表作為獨立進程,
1.進程內方案
進程內的方案通常是將分庫分表實現業務放到系統內部,通常存在以下缺陷
-
1.系統和分庫分表會存在資源競爭
-
2.一個異常的話,另外一個也會異常,依賴性太強。
-
3.無法適應異構,對其他語言的支持
2.進程外方案
進程外方案將分庫分表邏輯拆分,使用單獨的工具實現客戶端將請求發送到系統, 系統通過資料庫中間件在內部進行分庫分表邏輯,然後存儲資料庫,通常存在以下缺陷
-
1.維護量上升
-
2.相對進程內,性能會差一點,但是如果內網部署基本可以接受
4.ShardingSphere-Proxy基本概念
使用ShardingSphere-Proxy在進行實現分庫分表或者查詢時,主要有6個階段,這整個階段中的核心步驟是由中間件來實現的。
-
1.選擇具體資料庫
-
2.sql解析將中間件連接成為真實資料庫連接
-
3.sql路由,選擇一個真實資料庫執行
-
4.sql重寫優化
-
5.sql執行真實資料庫獲取結果
-
6.結果合併從多個表或者庫中獲取結果
用戶主要是針對路由規則的配置,實現將數據分片到不同表以及不同的庫,那我們應該思考如何對數據進行分片呢,需要哪些條件?
-
1.分片鍵:數據表中的欄位,選擇以哪個欄位作為分片的條件。
-
2.分片演算法:它的作用就是根據分片數據欄位如何去實現數據的分片。
5.項目環境及搭建
ShardingSphere-Proxy是由java開發,所以首先我們需要準備java的基本環境。
1.環境準備
- 1.下載Mysql
- 2.下載jdk1.8 提取碼:wgl2
- 3.下載mysql-connector-java-5.1.47.jar
- 4.下載ShardingSphere-Proxy
- 4.1 使用tar命令解壓 tar zxvf apache-shardingsphere-5.0.0-shardingsphere-proxy-bin.tar.gz
- 4.2 將下載的mysql-connector-java-5.1.47.jar 拷貝到lib目錄下
6.分庫分表配置
1.ShardingSphere-Proxy 分表
1.以數據採集資料庫的電源信息數據表為例,如果沒有資料庫就創建資料庫
2.在ShardingSphere-Proxy中的conf下找到config-sharding.yaml配置文件進行配置
3.在config-sharding.yaml中配置資料庫連接
dataSources:
dataacquisitionsources_0:
url: jdbc:mysql://localhost:3306/dataacquisition?serverTimezone=UTC&useSSL=false
username: root
password: 123456
connectionTimeoutMilliseconds: 30000
idleTimeoutMilliseconds: 60000
maxLifetimeMilliseconds: 1800000
maxPoolSize: 50
minPoolSize: 1
4.配置表和數據的分片規則
-
- actualDataNodes節點用來配置分成幾張表{0..1}就是2張,如果配置10張那就{0..9}
-
- 如果多張表分表就使用多個邏輯表名和節點,註意一定要註意配置格式
rules:
- !SHARDING
tables:
powerinformation:# 邏輯表名
actualDataNodes: dataacquisitionsources_0.powerinformation_${0..1} #分表
tableStrategy: #數據分表策略
standard:
shardingColumn: id #分表欄位
shardingAlgorithmName: powerinformation_MOD
shardingAlgorithms:
powerinformation_MOD:
type: MOD
props:
sharding-count: 2
5.配置客戶端連接虛擬資料庫,一般和真實庫名對應
schemaName: dataacquisition
6.打開配置目錄的server.yaml配置文件,來設置用戶和密碼
rules:
- !AUTHORITY
users:
- root@%:root
- sharding@:sharding
provider:
type: ALL_PRIVILEGES_PERMITTED
7.啟動bin目錄下的start.bat,如果出現以下畫面,那麼恭喜你中間件被成功配置

8.使用客戶端連接虛擬伺服器3307埠

9.執行腳本在虛擬伺服器上創建表結構,那麼中間件會預設按照預定的規則分表
create table powerinformation
(
id int not null AUTO_INCREMENT PRIMARY key,
Station Text,
voltage DECIMAL,
resistance DECIMAL,
electricity DECIMAL,
createDate DATETIME
)
COLLATE='utf8_general_ci'
ENGINE=InnoDB
AUTO_INCREMENT=2
;
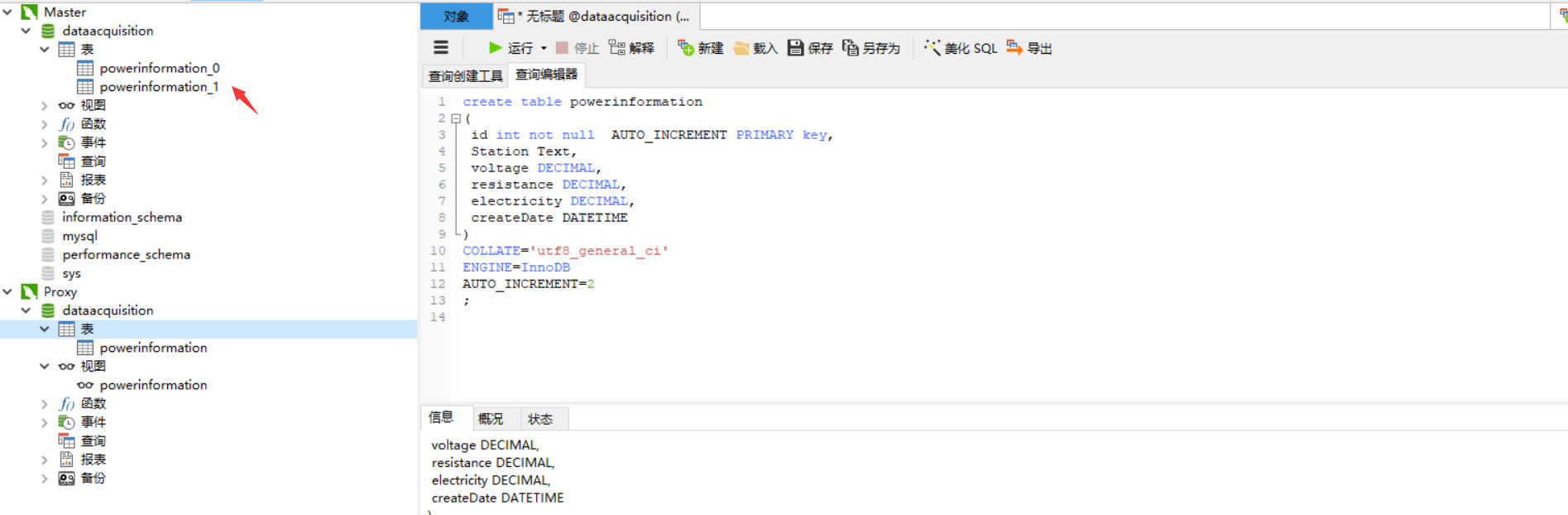
10.打開客戶端查看真實庫已經分表成功
2.ShardingSphere-Proxy 分庫
1.創建2個資料庫分別取名為dataacquisition_0和dataacquisition_1

2.打開配置文件,對代理配置不同資料庫連接
dataSources:
dataacquisitionsources_0:
url: jdbc:mysql://127.0.0.1:3306/dataacquisition_0?serverTimezone=UTC&useSSL=false #連接庫0
username: root
password: sa@123456
connectionTimeoutMilliseconds: 30000
idleTimeoutMilliseconds: 60000
maxLifetimeMilliseconds: 1800000
maxPoolSize: 50
minPoolSize: 1
dataacquisitionsources_1:
url: jdbc:mysql://127.0.0.1:3306/dataacquisition_1?serverTimezone=UTC&useSSL=false #連接庫1
username: root
password: sa@123456
connectionTimeoutMilliseconds: 30000
idleTimeoutMilliseconds: 60000
maxLifetimeMilliseconds: 1800000
maxPoolSize: 50
minPoolSize: 1
3.配置分庫規則,由於現在是2個不同的庫,所以不需要配置數據分到表的規則
rules:
- !SHARDING
tables:
powerinformation:
actualDataNodes: dataacquisitionsources_${0..1}.powerinformation #庫名錶達式
databaseStrategy: #數據分庫策略
standard:
shardingColumn: id
shardingAlgorithmName: powerinformation_MOD
shardingAlgorithms:
powerinformation_MOD:
type: MOD
props:
sharding-count: 2
4.在虛擬庫中添加表和數據將會分配到2個不同的庫

3.ShardingSphere-Proxy 分庫分表
1.按照分庫的操作執行,分庫配置不變
2.配置文件配置分庫分表的規則
rules:
- !SHARDING
tables:
powerinformation:
actualDataNodes: dataacquisitionsources_${0..1}.powerinformation_${0..1}
tableStrategy:
standard:
shardingColumn: id
shardingAlgorithmName: powerinformation_MOD
databaseStrategy:
standard:
shardingColumn: id
shardingAlgorithmName: powerinformation_MOD
shardingAlgorithms:
powerinformation_MOD:
type: MOD
props:
sharding-count: 2
7.搭建常見問題
1.由於是yaml文件,一定要註意對應節點的格式對齊
2.建議使用大於等於5.0.0+版本 折騰4.0.0版本被噁心吐了
3.如果出現 near 0這種錯誤就是在配置中使用了特殊符號 建議使用 下劃線的"_"


