
模型評價是指對於已經建立的一個或多個模型,根據其模型的類別,使用不同的指標評價其性能優劣的過程。常用的聚類模型評價指標有ARI評價法(蘭德繫數)、AMI評價法(互信息)、V-measure評分、FMI評價法和輪廓繫數等。常用的分類模型評價指標有準確率(Accuracy)、精確率(Precision) ...
模型評價是指對於已經建立的一個或多個模型,根據其模型的類別,使用不同的指標評價其性能優劣的過程。常用的聚類模型評價指標有ARI評價法(蘭德繫數)、AMI評價法(互信息)、V-measure評分、FMI評價法和輪廓繫數等。常用的分類模型評價指標有準確率(Accuracy)、精確率(Precision)、召回率(Recall)、F1值(F1 Value)、ROC和AUC等。常用的回歸模型評價指標有平均絕對誤差、均方根誤差、中值絕對誤差和可解釋方差值等。
線性回歸解決的是連續型數值的預測問題,例如預測房價,產品銷量等。
邏輯回歸解決的是分類問題,從分類數量上看,有二項分類和多項分類。
sklearn庫的metrics模塊提供各種評估方法,包括分類評估、回歸評估、聚類評估和交叉驗證等,評估分類是判斷預測值時否很好的與實際標記值相匹配。正確的鑒別出正樣本(True Positives)或者負樣本(True Negatives)都是True。同理,錯誤的判斷正樣本(False Positive,即一類錯誤)或者負樣本(False Negative,即二類錯誤)。
註意:True和False是對於評價預測結果而言,也就是評價預測結果是正確的(True)還是錯誤的(False)。而Positive和Negative則是樣本分類的標記。
metrics模塊分類度量有6種方法,如下表所示:
|
指標 |
描述 |
metrics方法 |
|
Accuracy |
準確度 |
from sklearn.metrics import accuracy_score |
|
Precision |
查準率 |
from sklearn.metrics import precision_score |
|
Recall |
查全率 |
from sklearn.metrics import recall_score |
|
F1 |
F1值 |
from sklearn.metrics import f1_score |
|
Classification Report |
分類報告 |
from sklearn.metrics import classification_report |
|
Confusion Matrix |
混淆矩陣 |
from sklearn.metrics import confusion_matrix |
|
ROC |
ROC曲線 |
from sklearn.metrics import roc_curve |
|
AUC |
ROC曲線下的面積 |
from sklearn.metrics import auc |
1 ''' 2 from sklearn.metrics import accuracy_score, precision_score, 3 recall_score, f1_score, classification_report, confusion_matrix 4 accuracy_score(y_test, y_pred) 5 precision_score(y_test, y_pred) 6 recall_score(y_test, y_pred) 7 f1_score(y_test,y_pred) 8 classification_report(y_test,y_pred) 9 confusion_matrix(y_test, y_pred) 10 '''
準確度(accuracy)
準確度是預測正確的數(包括正樣本和負樣本)占所有數的比例。利用accuracy_score函數對預測數據進行模型評估,其中第一個參數是測試標記,第二個參數是預測標記值
ACC = (TP+TN)/(TP+TN+FP+FN)
查準率/精確度(Precision)和查全率/召回率(Recall)
sklearn的metrics模塊分別提供了precision_score和recall_score函數用來評估分類模型的查全率和查準率。
精確度:precision,正確預測為正的,占全部預測為正的比例,TP / (TP+FP)
召回率:recall,正確預測為正的,占全部實際為正的比例,TP / (TP+FN)
假設有一個大小為1000的帶布爾標簽數據集,裡面的“真”樣本只有100不到,剩下都是假樣本。假設訓練一個模型,不管輸入什麼數據,它只給出“假”的預測,那麼正確率依舊是90%以上,很明顯,這個時候準確率accuracy就失去它的作用。因此,查全率和查準率一般用在傾斜數據集的時候。
F1值(F1-Measure)
Precision和Recall指標有的時候是矛盾的,F-Measure綜合這二者指標的評估指標,用於綜合反映整體的指標。F-Measure是Precision和Recall加權調和平均, a為權重因數,當a = 1時,F值變為最常見的F1了,代表精確率和召回率的權重一樣(fl_score)
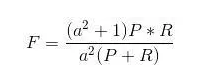
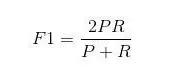
分類報告(Classification Report)
metrics模塊的classification_report方法,綜合提供了查準率(precision)、查全率(recall)和f1值三種評估指標。
混淆矩陣(Confusion Matrix)
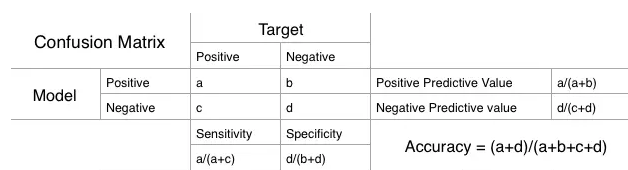
混淆矩陣是一個N X N矩陣,N為分類的個數。假如我們面對的是一個二分類問題,也就是N=2,我們就得到一個2 X 2矩陣。在學習這個矩陣之前,我們需要知道一些簡單的定義。
Accuracy(準確度):預測正確的數占所有數的比例。
Positive Predictive Value(陽性預測值)
or Precision(查準率):陽性預測值被預測正確的比例。
Negative Predictive Value(陰性預測值):陰性預測值被預測正確的比例。
Sensity(靈敏度) or Recall(查全率):在陽性值中實際被預測正確所占的比例。
Specificity(特異度):在陰性值中實現被預測正確所占的比例。
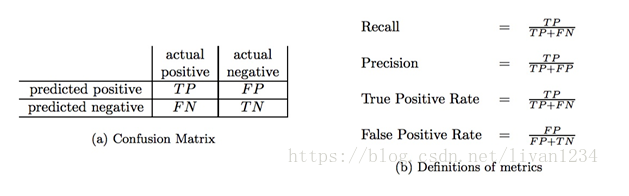
ROC(receiver operating characteristic curve)
曲線指受試者工作特征曲線或者是接收器操作特性曲線, 慮一個二分問題,即將實例分成正類(positive)或負類(negative)。對一個二分問題來說,會出現四種情況。如果一個實例是正類並且也被預測成正類,即為真正類(True positive),如果實例是負類被預測成正類,稱之為假正類(False positive)。相應地,如果實例是負類被預測成負類,稱之為真負類(True negative),正類被預測成負類則為假負類(false negative)。
TP:正確肯定的數目;
FN:漏報,沒有正確找到的匹配的數目;
FP:誤報,給出的匹配是不正確的;
TN:正確拒絕的非匹配對數;
從列聯表引入兩個新名詞。其一是真正類率(true positive rate ,TPR), 計算公式為TPR=TP/ (TP+ FN),刻畫的是分類器所識別出的正實例占所有正實例的比例。另外一個是假正類率(false positive rate, FPR),計算公式為FPR= FP / (FP + TN),計算的是分類器錯認為正類的負實例占所有負實例的比例。還有一個真負類率(True Negative Rate,TNR),也稱為specificity,計算公式為TNR=TN/ (FP+ TN) = 1-FPR。
FPR = FP/(FP +
TN)負樣本中


