最近購買了極客時間推出的李運華的課程——《從0開始學架構》,本人通過聽音頻和文字閱讀,整理出相關筆記,目的是方便今後再次閱讀。再次感謝李運華的講解,購買鏈接:從0開始學架構 資深技術專家的實戰架構心法 開篇詞 | 照著做,你也能成為架構師 想成為架構師,夢想是美好的,但道路是曲折的,這應該不是個人天 ...
最近購買了極客時間推出的李運華的課程——《從0開始學架構》,本人通過聽音頻和文字閱讀,整理出相關筆記,目的是方便今後再次閱讀。再次感謝李運華的講解,購買鏈接:從0開始學架構 資深技術專家的實戰架構心法
開篇詞 | 照著做,你也能成為架構師
想成為架構師,夢想是美好的,但道路是曲折的,這應該不是個人天資的問題,而是架構設計本身的一些特性所致。
- 架構設計的關鍵思維是判斷和取捨,程式設計的關鍵思維是邏輯和實現。
- 架構設計沒有體系化的培訓和訓練機制
- 程式員對架構設計的理解存在很多舞曲(比如,架構一定具備高可用、高性能等)
這個專欄涵蓋:
- 架構基礎
- 高性能架構模式
- 高可用架構模式
- 可擴展架構模式
- 架構實戰
通過本專欄的學習,你會收穫:
- 清楚地理解架構的相關的概念、本質、目的
- 掌握通用的架構設計原則
- 掌握架構標準的設計流程
- 深入理解已有的架構模式
- 掌握架構演進和開源系統使用的一些技巧
只要你努力,技術的夢想一定會實現。
精彩留言:

一、架構基礎
01 | 架構到底是指什麼?
梳理幾個有關係而又相似的概念:
A. 系統與子系統
系統泛指由一群有關聯的個體組成,根據某種規則運作,能完成個別元件不能單獨完成的工作的群體。它的意思是“總體”“整體”或“聯盟”。(維基百科)
(註意:這裡的“能”指的是“能力”,系統能力與個體能力又本質差別,系統能力不是個體同理之和,而是生產了新的能力。比如,汽車能夠載重前行,發動機不能。)
B. 模塊與組件
軟體模塊(Module)是一套一致而互相有緊密關連的軟體組織。它分別包含了程式和數據結構兩部分。現代軟體開發往往利用模塊作為合成的單位。模塊的介面表達了由該模塊提供的功能和調用它時所需的元素。模塊是可能分開被編寫的單位。這使它們可再用和允許人員同時協作、編寫及研究不同的模塊。軟體組件定義為自包含的、可編程的、可重用的、與語言無關的軟體單元,軟體組件可以很容易被用於組裝應用程式中。(維基百科)
總結:模塊和組件都是系統的組成部分,只是從不同的角度拆分系統而已。
C. 框架與架構
軟體框架(Software framework)通常指的是為了實現某個業界標準或完成特定基本任務的軟體組件規範,也指為了實現某個軟體組件規範時,提供規範所要求之基礎功能的軟體產品。
提煉一下其中關鍵部分:
- 框架是組件規範:例如,MVC 就是一種最常見的開發規範,類似的還有 MVP、MVVM、J2EE 等框架。
- 框架提供基礎功能的產品:例如,Spring MVC 是 MVC 的開發框架,除了滿足 MVC 的規範,Spring 提供了很多基礎功能來幫助我們實現功能,包括註解(@Controller 等)、Spring Security、Spring JPA 等很多基礎功能。
軟體架構指軟體系統的“基礎結構”,創造這些基礎結構的準則,以及對這些結構的描述。
單純從定義的角度來看,框架和架構的區別還是比較明顯的,框架關註的是“規範”,架構關註的是“結構”。框架的英文是 Framework,架構的英文是 Architecture。Spring MVC 的英文文檔標題就是“Web MVC framework”。
“從業務邏輯的角度分解,“學生管理系統”的機構是:
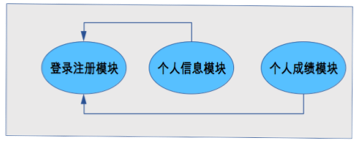
從物理部署的角度分解,“學生管理系統”的架構是:
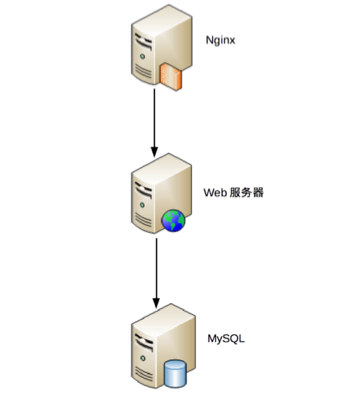
從開發規範的角度分解,“學生管理系統”可以採用標準的 MVC 框架來開發,因此架構又變成了 MVC 架構:

這些“架構”,都是“學生管理系統”正確的架構,只是從不同的角度來分解而已,這也是 IBM 的 RUP 將軟體架構視圖分為著名的“4+1 視圖”的原因。
重新定義架構
“軟體架構指軟體系統的頂層結構”——李運華
首先,“系統是一群關聯個體組成”,這些“個體”可以是“子系統”“模塊”“組件”等;架構需要明確系統包含哪些“個體”。
其次,系統中的個體需要“根據某種規則”運作,架構需要明確個體運作和協作的規則。
第三,維基百科定義的架構用到了“基礎結構”這個說法,我改為“頂層結構”,可以更好地區分系統和子系統,避免將系統架構和子系統架構混淆在一起導致架構層次混亂。
精選留言:




02 | 架構設計的歷史背景
機器語言(1940 年之前)1.機器語言(1940 年之前)
101100000000000000000011 000001010000000000110000 001011010000000000000101彙編語言(20 世紀 40 年代)
2.彙編語言(20 世紀 40 年代)
為瞭解決機器語言編寫、閱讀、修改複雜的問題,彙編語言應運而生。彙編語言又叫“符號語言”,用助記符代替機器指令的操作碼,用地址符號(Symbol)或標號(Label)代替指令或操作數的地址。為瞭解決機器語言編寫、閱讀、修改複雜的問題,彙編語言應運而生。彙編語言又叫“符號語言”,用助記符代替機器指令的操作碼,用地址符號(Symbol)或標號(Label)代替指令或操作數的地址。
機器語言:1000100111011000 彙編語言:mov ax,bx
.section .data a: .int 10 b: .int 20 format: .asciz "%d\n" .section .text .global _start _start: movl a, %edx addl b, %edx pushl %edx pushl $format call printf movl $0, (%esp) call exit除了編寫本身複雜,還有另外一個複雜的地方在於:不同 CPU 的彙編指令和結構是不同的。
除了編寫本身複雜,還有另外一個複雜的地方在於:不同 CPU 的彙編指令和結構是不同的。
高級語言(20 世紀 50 年代)3.高級語言(20 世紀 50 年代)
- Fortran:1955 年,名稱取自”FORmula TRANslator”,即公式翻譯器,由約翰·巴科斯(John Backus)等人發明。
- LISP:1958 年,名稱取自”LISt Processor”,即枚舉處理器,由約翰·麥卡錫(John McCarthy)等人發明。
- Cobol:1959 年,名稱取自”Common Business Oriented Language”,即通用商業導向語言,由葛麗絲·霍普(Grace Hopper)發明。
這些語言讓程式員不需要關註機器底層的低級結構和邏輯,而只要關註具體的問題和業務即可。
4.第一次軟體危機與結構化程式設計(20 世紀 60 年代~20 世紀 70 年代)
20 世紀 60 年代中期開始爆發了第一次軟體危機,典型表現有軟體質量低下、項目無法如期完成、項目嚴重超支等,因為軟體而導致的重大事故時有發生。例如,1963 年美國(http://en.wikipedia.org/wiki/Mariner_1)的水手一號火箭發射失敗事故,就是因為一行 FORTRAN 代碼錯誤導致的。
結構化程式方法成為了 20 世紀 70 年代軟體開發的潮流。
5.第二次軟體危機與面向對象(20 世紀 80 年代)
結構化編程的風靡在一定程度上緩解了軟體危機,然而隨著硬體的快速發展,業務需求越來越複雜,以及編程應用領域越來越廣泛,第二次軟體危機很快就到來了。第二次軟體危機的根本原因還是在於軟體生產力遠遠跟不上硬體和業務的發展。
第一次軟體危機的根源在於軟體的“邏輯”變得非常複雜,而第二次軟體危機主要體現在軟體的“擴展”變得非常複雜。
結構化程式設計雖然能夠解決(也許用“緩解”更合適)軟體邏輯的複雜性,但是對於業務變化帶來的軟體擴展卻無能為力,軟體領域迫切希望找到新的銀彈來解決軟體危機,在這種背景下,面向對象的思想開始流行起來。
軟體架構的歷史背景
雖然早在 20 世紀 60 年代,戴克斯特拉這位上古大神就已經涉及軟體架構這個概念了,但軟體架構真正流行卻是從 20 世紀 90 年代開始的,由於在 Rational 和 Microsoft 內部的相關活動,軟體架構的概念開始越來越流行了。
軟體架構的出現有其歷史必然性。
20 世紀 60 年代第一次軟體危機引出了“結構化編程”,創造了“模塊”概念;
20 世紀 80 年代第二次軟體危機引出了“面向對象編程”,創造了“對象”概念;
20 世紀 90 年代“軟體架構”開始流行,創造了“組件”概念。
我們可以看到,“模塊”“對象”“組件”本質上都是對達到一定規模的軟體進行拆分,差別隻是在於隨著軟體的複雜度不斷增加,拆分的粒度越來越粗,拆分的層次越來越高。《人月神話》中提到的 IBM 360 大型系統,開發時間是 1964 年,那個時候結構化編程都還沒有提出來,更不用說軟體架構了。如果 IBM 360 系統放在 20 世紀 90 年代開發,不管是質量還是效率、成本,都會比 1964 年開始做要好得多,當然,這樣的話我們可能就看不到《人月神話》了。



03 | 架構設計的目的
架構設計的真正目的究竟是什麼?
架構設計的主要目的是為瞭解決軟體系統複雜度帶來的問題。
架構設計並不是要面面俱到,不需要每個架構都具備高性能、高可用、高擴展等特點,而是要識別出複雜點然後有針對性地解決問題。
簡單的複雜度分析案例:
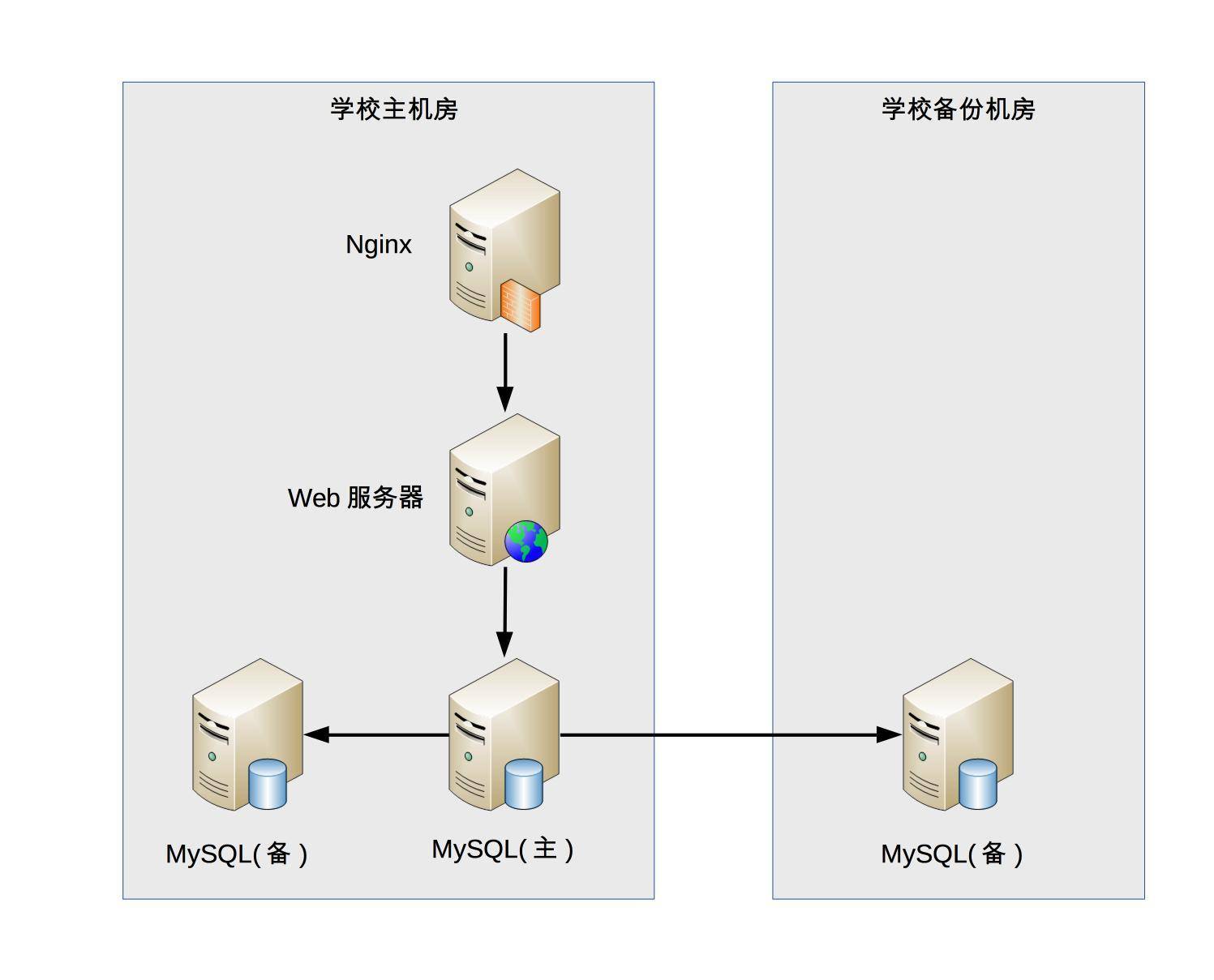
假設我們需要設計一個學生管理系統:
- 性能:一個學校大約1~2萬人,學生管理系統的訪問率並不高,因此性能要求並不高,存儲用MySQL完全能勝任,緩存可以不用,Web伺服器用Nginx綽綽有餘。
- 可擴展性:學生管理系統的功比較穩定,可擴展性不強。
- 高可用:宕機2小時對學生影響可能不大,可以不做負載均衡,不用考慮異地多活這類複雜的方案。學生信息的存儲比較重要,因此需要考慮存儲高可靠。還要考慮:機器故障、機房故障,針對機器故障可設計MySQL同機房主備方案;針對機房故障,可考慮設計MySQL跨機房同步方案。
- 安全性:基本滿足:Nginx提供ACL控制、用戶賬號密碼管理、資料庫訪問許可權控制。
- 成本:伺服器使用數量不多。
精選留言:



04 | 複雜度來源:高性能
軟體系統中高性能帶來的複雜度主要體現在兩個方面:
- 單台電腦內部為了高性能帶來的複雜度
- 多太電腦集群為了高性能帶來的複雜度
單機複雜度
電腦內部複雜度最關鍵的地方就是操作系統。電腦性能的發展本質上是悠硬體發展驅動的,尤其是CPU的性能發展。
操作系統和性能相關的就是進程和線程。
- 最早的電腦沒有操作系統,只有輸入、計算和輸出功能。這樣的處理性能效率很低。
- 為解決手工操作帶來的低效,批處理應運而生,性能就有了很大的提升。(缺點:電腦一次只能執行一個任務,如果某個任務需要從I/O設備(例如磁帶)讀取大量的數據,在I/O操作的過程中,CPU其實是空閑的,浪費了部分資源)
- 為進一步提升性能,人們發明瞭“進程”,用進程來對應一個任務,每個任務都有自己的獨立記憶體空間,進程間互不相關,由操作系統來進行調度。(此時的CPU還沒有多核和多線程的概念,為了達到多進程並行的目的,採取了分時的方式。同時,進程間通信的各種方式被設計出來,包括管道、消息隊列、信號量、共用存儲等。多進程讓多任務能夠並行處理,但本身缺點:單個進程內部只能串列處理,而實際上很多進程內部的子任務並不要求是嚴格按照時間順序來執行的,也需要並行處理。)
- 為解決進程的缺點,人們發明瞭線程。(同時,為保證數據的正確性,又發明瞭互斥鎖機制。有了多線程後,操作系統調度的最小單位就變成了線程,而進程變成了操作系統分配資源的最小單位。多進程多線程雖讓多任務並行處理的性能大大提升,但本質還是分時系統,並不能實現真正意義上的多任務並行)
- 多個CPU能夠同時執行計算任務,實現真正意義上的多任務並行:目前這樣的解決方案有 3 種:SMP(Symmetric Multi-Processor,對稱多處理器結構)、NUMA(Non-Uniform Memory Access,非一致存儲訪問結構)、MPP(Massive Parallel Processing,海量並行處理結構)。
操作系統發展到現在,如果我們要完成一個高性能的軟體系統,需要考慮如多進程、多線程、進程間通信、多線程併發等技術點,而且這些技術並不是最新的就是最好的,也不是非此即彼的選擇。在做架構設計的時候,需要花費很大的精力來結合業務進行分析、判斷、選擇、組合,這個過程同樣很複雜。
雖然,電腦操作系統和硬體的發展已經很快了,但是在進入互聯網時代後,業務的發展速度遠遠更超前了。例如:
- 2016 年“雙 11”支付寶每秒峰值達 12 萬筆支付。
- 2017 年春節微信紅包收發紅包每秒達到 76 萬個
單機的性能無法支撐業務需求的增長,必須採用機器集群的方式來達到高性能。但是,通過大量的機器來提升性能,並不僅僅是增加機器這麼簡單,下麵是針對幾種方式的加單分析:
1.任務分配:
任務分配的意思是指,每台機器都可以處理完整的業務任務,不同的任務分配到不同的機器上執行。
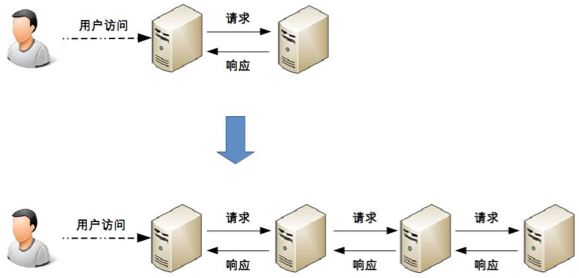
例如:從最簡單的一臺伺服器變兩台伺服器:

此時架構上明顯要複雜多了,主要體現在:
- 需要增加一個任務分配器,這個分配器可能是硬體網路設備(例如,F5、交換機等),可能是軟體網路設備(例如,LVS),也可能是負載均衡軟體(例如,Nginx、HAProxy),還可能是自己開發的系統。選擇合適的任務分配器也是一件複雜的事情,需要綜合考慮性能、成本、可維護性、可用性等各方面的因素。
- 任務分配器和真正的業務伺服器之間有連接和交互(即圖中任務分配器到業務伺服器的連接線),需要選擇合適的連接方式,並且對連接進行管理。例如,連接建立、連接檢測、連接中斷後如何處理等。
- 任務分配器需要增加分配演算法。例如,是採用輪詢演算法,還是按權重分配,又或者按照負載進行分配。如果按照伺服器的負載進行分配,則業務伺服器還要能夠上報自己的狀態給任務分配器。
假設性能要求繼續提高,要求每秒提升到10萬次:

這個架構比 2 台業務伺服器的架構要複雜,主要體現在:
- 任務分配器從 1 台變成了多台(對應圖中的任務分配器 1 到任務分配器 M),這個變化帶來的複雜度就是需要將不同的用戶分配到不同的任務分配器上(即圖中的虛線“用戶分配”部分),常見的方法包括 DNS 輪詢、智能 DNS、CDN(Content Delivery Network,內容分髮網絡)、GSLB 設備(Global Server Load Balance,全局負載均衡)等。
- 任務分配器和業務伺服器的連接從簡單的“1 對多”(1 台任務分配器連接多台業務伺服器)變成了“多對多”(多台任務分配器連接多台業務伺服器)的網狀結構。
- 機器數量從 3 台擴展到 30 台(一般任務分配器數量比業務伺服器要少,這裡我們假設業務伺服器為 25 台,任務分配器為 5 台),狀態管理、故障處理複雜度也大大增加。
上面這兩個例子都是以業務處理為例,實際上“任務”涵蓋的範圍很廣,可以指完整的業務處理,也可以單指某個具體的任務。例如,“存儲”“運算”“緩存”等都可以作為一項任務,因此存儲系統、運算系統、緩存系統都可以按照任務分配的方式來搭建架構。此外,“任務分配器”也並不一定只能是物理上存在的機器或者者一個獨立運行的程式,也可以是嵌入在其他程式中的演算法,例如 Memcache 的集群架構。

2.任務分解
通過任務分配的方式,能夠突破單台機器處理性能的瓶頸,通過增加更多的機器來滿足業務的性能需求,但如果業務本身也越來越複雜,單純只通過任務分配的方式來擴展性能,收益會越來越低。
為了能夠繼續提升性能,我們需要採取第二種方式:任務分解。

那為何通過任務分解就能夠提升性能呢?
1.簡單的系統更加容易做到高性能
系統的功能越簡單,影響性能的點就越少,就更加容易進行有針對性的優化。而系統很複雜的情況下,首先是比較難以找到關鍵性能點,因為需要考慮和驗證的點太多;其次是即使花費很大力氣找到了,修改起來也不容易。
2.可以針對單個任務進行擴展
當各個邏輯任務分解到獨立的子系統後,整個系統的性能瓶頸更加容易發現,而且發現後只需要針對有瓶頸的子系統進行性能優化或者提升,不需要改動整個系統,風險會小很多。
雖然系統拆分可能在某種程度上能提升業務處理性能,但提升性能也是有限的。理論上的性能是有一個上限的,系統拆分能夠讓性能逼近這個極限,但無法突破這個極限。因此,任務分解帶來的性能收益是有一個度的,並不是任務分解越細越好,而對於架構設計來說,如何把握這個粒度就非常關鍵了。
精選留言:


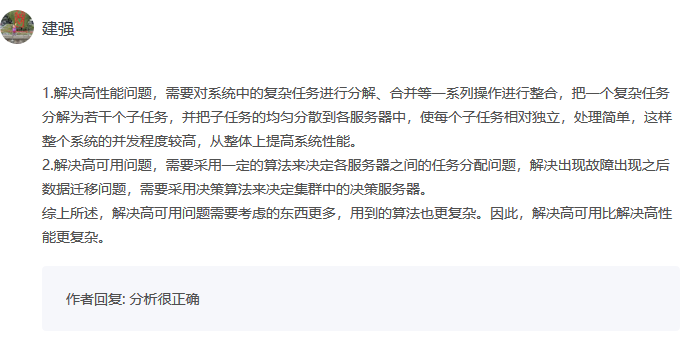
05 | 複雜度來源:高可用
高可用:系統無中斷地執行其功能的能力,代表系統的可用性程度,是進行系統設計時的準則之一。
“無中斷”的干擾因素有很多:硬體出現故障、軟體Bug、外部環境的不可控,不可避免性,地震水災等。所以,系統的高可用方案五花八門,但是本質都是通過“冗餘”來實現高可用。
通俗點來講,就是一臺機器不夠就兩台,兩台不夠就四台;一個機房可能斷電,那就部署兩個機房;一條通道可能故障,那就用兩條,兩條不夠那就用三條(移動、電信、聯通一起上)。
高可用的“冗餘”解決方案,單純從形式上來看,和之前講的高性能是一樣的,都是通過增加更多機器來達到目的,但其實本質上是有根本區別的:高性能增加機器目的在於“擴展”處理性能;高可用增加機器目的在於“冗餘”處理單元。
1.計算高可用
這裡的“計算”指的是業務的邏輯處理。計算有一個特點就是無論在哪台機器上進行計算,同樣的演算法和輸入數據,產出的結果都是一樣的,所以將計算從一臺機器遷移到另外一臺機器,對業務並沒有什麼影響。
單機變雙機的簡單架構示意圖:

這個雙機的架構圖和上期“高性能”講到的雙機架構圖是一樣的,因此複雜度也是類似的,具體表現為:
- 需要增加一個任務分配器,選擇合適的任務分配器也是一件複雜的事情,需要綜合考慮性能、成本、可維護性、可用性等各方面因素。
- 任務分配器和真正的業務伺服器之間有連接和交互,需要選擇合適的連接方式,並且對連接進行管理。例如,連接建立、連接檢測、連接中斷後如何處理等。
- 任務分配器需要增加分配演算法。例如,常見的雙機演算法有主備、主主,主備方案又可以細分為冷備、溫備、熱備。
上面這個示意圖只是簡單的雙機架構,再看一個複雜一點的高可用集群架構:
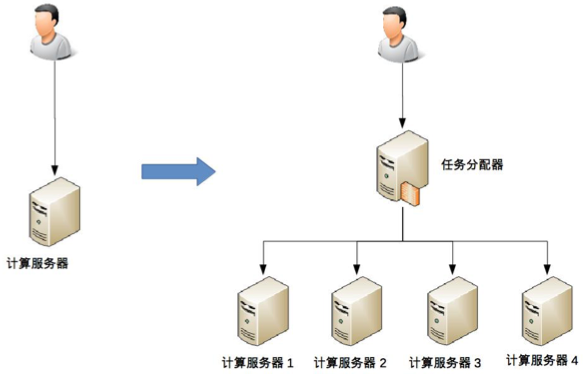
這個高可用集群相比雙機來說,分配演算法更加複雜,可以是 1 主 3 備、2 主 2 備、3 主 1 備、4 主 0 備,具體應該採用哪種方式,需要結合實際業務需求來分析和判斷,並不存在某種演算法就一定優於另外的演算法。例如,ZooKeeper 採用的就是 1 主多備,而 Memcached 採用的就是全主 0 備。
2.存儲高可用
存儲與計算相比,有一個本質上的區別:將數據從一臺機器搬到到另一臺機器,需要經過線路進行傳輸。
- 正常情況下的傳輸延遲:線路傳輸的速度是毫秒級別,同一機房內部能夠做到幾毫秒;分佈在不同地方的機房,傳輸耗時需要幾十甚至上百毫秒。(例如,從廣州機房到北京機房,穩定情況下 ping 延時大約是 50ms,不穩定情況下可能達到 1s 甚至更多。)
- 異常情況下的傳輸中斷:傳輸線路可能中斷、可能擁塞、可能異常(錯包、丟包),並且傳輸線路的故障時間一般都特別長,短的十幾分鐘,長的幾個小時都是可能的。
綜合分析,以上兩點都會導致系統的數據在某個時間點或者時間段是不一致的,而數據的不一致又會導致業務問題;但如果完全不做冗餘,系統的整體高可用又無法保證,所以存儲高可用的難點不在於如何備份數據,而在於如何減少或者規避數據不一致對業務造成的影響。分散式領域裡面有一個著名的 CAP 定理,從理論上論證了存儲高可用的複雜度。也就是說,存儲高可用不可能同時滿足“一致性、可用性、分區容錯性”,最多滿足其中兩個,這就要求我們在做架構設計時結合業務進行取捨。
高可用狀態決策
一個本質的矛盾:通過冗餘來實現的高可用系統,狀態決策本質上就不可能做到完全正確。下麵我基於幾種常見的決策方式進行詳細分析。
1. 獨裁式
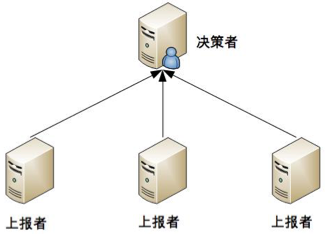
獨裁式的決策方式:
- 優點:不會出現決策混亂的問題,因為只有一個決策者。
- 缺點:當決策者本身故障時,整個系統就無法實現準確的狀態決策。如果決策者本身又做一套狀態決策,那就陷入一個遞歸的死迴圈了。
2. 協商式
協商式決策指的是兩個獨立的個體通過交流信息,然後根據規則進行決策,最常用的協商式決策就是主備決策。
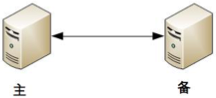
這個架構的基本協商規則可以設計成:
- 2 台伺服器啟動時都是備機。
- 2 台伺服器建立連接。
- 2 台伺服器交換狀態信息。
- 某 1 台伺服器做出決策,成為主機;另一臺伺服器繼續保持備機身份。
協商式決策的架構不複雜,規則也不複雜,其難點在於,如果兩者的信息交換出現問題(比如主備連接中斷),此時狀態決策應該怎麼做。如果備機在連接中斷的情況下認為主機故障,那麼備機需要升級為主機。
下麵分為三種情況:
第一種情況:如果備機在連接中斷的情況下,實際上主機並沒有故障,那麼系統就出現了兩個主機,這與設計初衷(1 主 1 備)是不符合的。

第二種情況:如果備機在連接中斷的情況下不認為主機故障,則此時如果主機真的發生故障,那麼系統就沒有主機了,這同樣與設計初衷(1 主 1 備)是不符合的。
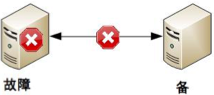
第三種情況:如果為了規避連接中斷對狀態決策帶來的影響,可以增加更多的連接。
例如,雙連接、三連接。這樣雖然能夠降低連接中斷對狀態帶來的影響(註意:只能降低,不能徹底解決),但同時又引入了這幾條連接之間信息取捨的問題,即如果不同連接傳遞的信息不同,應該以哪個連接為準?實際上這也是一個無解的答案,無論以哪個連接為準,在特定場景下都可能存在問題。
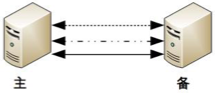
綜合分析,協商式狀態決策在某些場景總是存在一些問題的。
3. 民主式
民主式決策指的是多個獨立的個體通過投票的方式來進行狀態決策。例如,ZooKeeper 集群在選舉 leader 時就是採用這種方式。

民主式決策和協商式決策比較類似,其基礎都是獨立的個體之間交換信息,每個個體做出自己的決策,然後按照“多數取勝”的規則來確定最終的狀態。不同點在於民主式決策比協商式決策要複雜得多,ZooKeeper 的選舉演算法 Paxos,絕大部分人都看得雲里霧裡,更不用說用代碼來實現這套演算法了。
除了演算法複雜,民主式決策還有一個固有的缺陷:腦裂。

從圖中可以看到,正常狀態的時候,節點 5 作為主節點,其他節點作為備節點;當連接發生故障時,節點 1、節點 2、節點 3 形成了一個子集群,節點 4、節點 5 形成了另外一個子集群,這兩個子集群的連接已經中斷,無法進行信息交換。按照民主決策的規則和演算法,兩個子集群分別選出了節點 2 和節點 5 作為主節點,此時整個系統就出現了兩個主節點。這個狀態違背了系統設計的初衷,兩個主節點會各自做出自己的決策,整個系統的狀態就混亂了。
為瞭解決腦裂問題,民主式決策的系統一般都採用“投票節點數必須超過系統總節點數一半”規則來處理。
如圖中那種情況,節點 4 和節點 5 形成的子集群總節點數只有 2 個,沒有達到總節點數 5 個的一半,因此這個子集群不會進行選舉。這種方式雖然解決了腦裂問題,但同時降低了系統整體的可用性,即如果系統不是因為腦裂問題導致投票節點數過少,而真的是因為節點故障(例如,節點 1、節點 2、節點 3 真的發生了故障),此時系統也不會選出主節點,整個系統就相當於宕機了,儘管此時還有節點 4 和節點 5 是正常的。
綜合分析,無論採取什麼樣的方案,狀態決策都不可能做到任何場景下都沒有問題,但完全不做高可用方案又會產生更大的問題,如何選取適合系統的高可用方案,也是一個複雜的分析、判斷和選擇的過程。
精選留言: