互聯網那些事 | MQ數據丟失 本系列故事的所有案例和解決方案只是筆者以前在互聯網工作期間的一些事例,僅供大家參考,實際操作應該根據業務和項目情況設計,歡迎大家留言提出寶貴的意見 背景 小王和小明分別維護分散式系統中A、b兩個服務,有一個場景是 A服務會向B服務通過MQ發送事件並且推送用戶信息,然後 ...
互聯網那些事 | MQ數據丟失
本系列故事的所有案例和解決方案只是筆者以前在互聯網工作期間的一些事例,僅供大家參考,實際操作應該根據業務和項目情況設計,歡迎大家留言提出寶貴的意見
背景
小王和小明分別維護分散式系統中A、b兩個服務,有一個場景是 A服務會向B服務通過MQ發送事件並且推送用戶信息,然後B服務保存用戶信息。
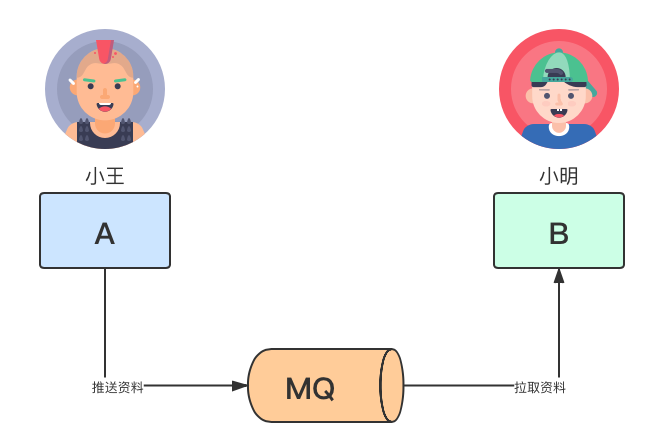
有一天,小王和小明因為一件事討論得熱火朝天、互不相讓,事情由來如下:
- 風控部的童鞋找小明說在B服務的資料庫找不到一些用戶資料
- 小明經過排查,B服務表裡確實沒有這批用戶的數據,在日誌里偶爾看到了一些Redis連接超時異常,小明想小王手動幫忙重推試試
- 小王經過排查,確保自己已經成功推送了那幾個用戶的數據,並且推送的時候A服務並沒有發現MQ異常,覺得自己沒有義務去幫忙重推,應該小明自己解決
這時候,在一旁掃地的清潔工老梁過來調解,並幫忙排查分析,導致這個問題的主要原因如下:
- B服務在接受MQ的處理類捕獲了異常,因為異常並沒有拋出,所以框架預設自動回覆了ACK,MQ認為已經消費者處理成功,就不再重覆投放到隊列,但此時方法體內因為工具包出現Redis連接超時,拋出異常,導致消息並沒有被正常處理
偽代碼如下:
@RabbitHandler
public void handle(byte[] message) {
try {
t = parseBody(messageStr);
} catch (Exception e) {
log.error("消費消息失敗", e.getCause());
}
}
private void handleMessage(T t) throws MQHandleException {
//唯一標識
String key = t.getLockedId();
//獲取鎖
DistributedLock lock = DistributedLockFactory.getLock(key);
try {
// 解決分散式服務提交相同資料併發問題
lock.lock(CacheConstants.LOCK_WAIT_TIME, CacheConstants.LOCK_LEASE_TIME, CacheConstants.DEFAULT_CACHE_UNIT);
// 處理業務邏輯
handleBusinessLogic(t);
} catch (LockException e) {
throw new MQHandleException(e);
} finally {
// 釋放鎖
lock.unLock();
}
}
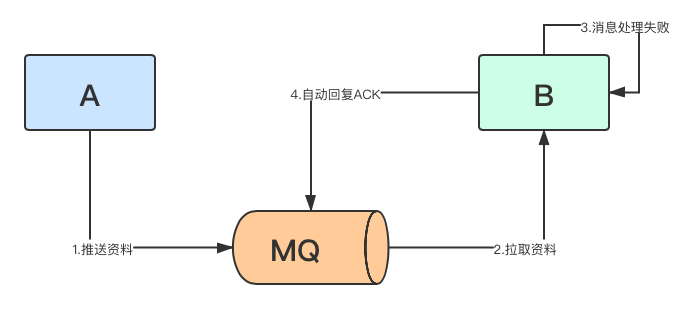
-
頻繁Redis超時是因為A、B服務共用一個Redis,A服務Key太多把Redis記憶體資源占滿了(也可能連接占滿),導致了B服務經常出現連接超時(該故障不是本章主要關註目標)
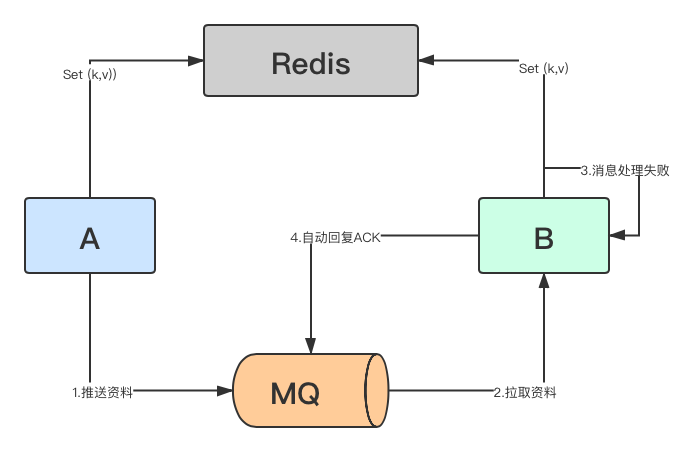
-
B服務在已經成功接受到消息後,沒有把消息先保存起來,所以也導致了自身並沒有能力重跑
清潔工老梁跟小王和小明進行一番詳談後,瞭解到他們主要需求有兩個:
- B服務儘可能自己重新消費信息,而不是一昧依賴A服務手動重推
- B服務對已接收到的消息,能自己重新消費,當然,這裡指的是有意義的消息,如果一些本身A服務推送過來的消息就是有問題的,例如格式錯誤之類的,這些B服務可以要求A重推
解決思路
經過上面的分析,老梁的解題思路主要分為兩個方向:
- B服務建立自己的本地異常消息事件表。
- B服務做異常分類,只對可以重跑的消息事件進行重跑
本地異常消息事件表
一般來說,常見的微服務架構實現最終一致性有三種模式:可靠事件模式、業務補償模式、TCC模式。這裡AB服務是通過業務補償模式實現最終一致性,但這裡又跟我們一般的分散式架構的事務問題不同,這裡我們只需要保證B服務能最終把正常消息事件消費成功即可。
實現思路:
- 建立一張本地異常消息事件表,為了避免太多資料庫IO操作,這裡只會記錄異常事件
- 提取一個通用消息處理層,統一保存異常消息事件,併進行狀態更新
- 提取一個事件恢復模塊,統一對失敗事件進行追蹤
- 對於重跑仍失敗消息事件,設置一個重跑次數上限,進行自動重跑,可以通過調度任務去做(事件恢復模塊),當重跑多次仍然失敗(像網路異常和資料庫異常之類,短時間不會被修複),則後期進行人工重跑
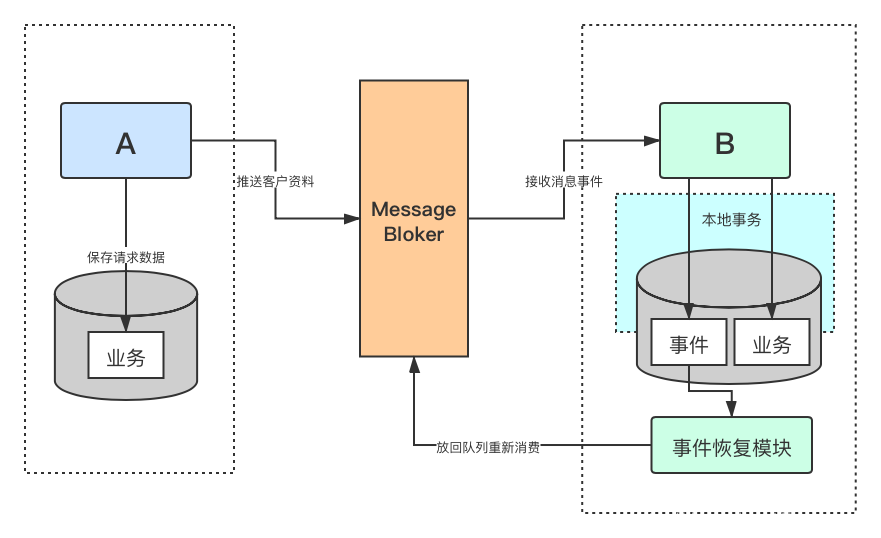
表設計

針對於B服務,對於收到的MQ信息沒有進行有效的記錄,而且MQ信息處理之後,存在修改錯誤,沒法進行對應信息補充修複的功能,增加通用消息處理層,進行消息體的記錄和回溯。 在獲取消息之後進行一次記錄,進行冪等操作和對應的狀態更新, 消息狀態在業務相關操作完成後,標記為處理完成,認為對應消息狀態結束。
這裡hash_value是對請求體進行hash計算得出來的一個值,例如:MD5、SHA-2,保證每個不同請求的hash碼不一樣,相同的請求hash碼相同,可以用於冪等控制。
表大致操作流程:
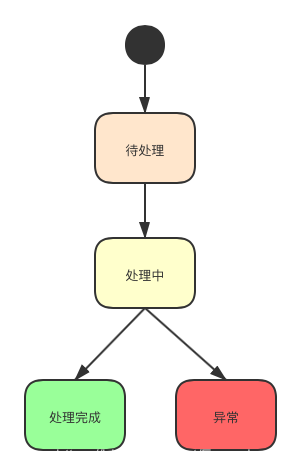
異常消息狀態設計
異常消息有4個狀態
- 待處理 當系統消費失敗時,會對特定的異常插入異常事件表,初始狀態為
待處理 - 處理中 當失敗恢復模塊開始執行任務時會把當前異常事件狀態設置為
處理中 - 處理完成 當失敗事件重跑成功後,會把當前異常事件狀態設置為
處理完成 - 異常 當失敗事件重跑超過上限次數後,會把當前異常事件狀態設置為
異常,等待後期人工重跑
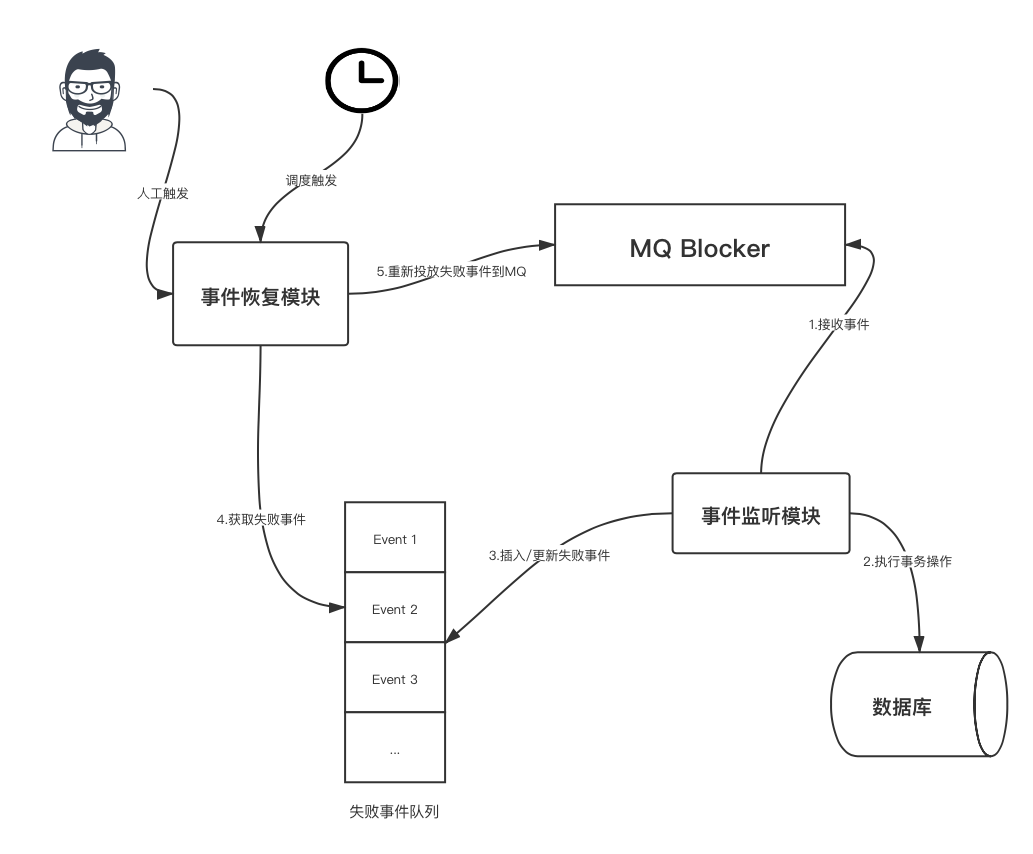
事件恢復模塊
失敗事件隊列在這裡是採用資料庫表代替
異常分類
因為並非所有的異常都能重跑就能解決問題,我們只能針對可以修複的異常進行重試,這裡把異常分為兩大類:
- 可修複異常:可修複異常指的是可以通過重跑解決的異常,如:資料庫超時、資料庫缺少欄位、Redis獲取鎖失敗、處理邏輯有問題導致信息缺失、系統升級導致消費失敗、網路問題、伺服器不穩定等引起。
- 可立即修複異常:指一些可以通過立即重試就能恢復的異常。例如短暫的網路中斷引起的異常,一般可以在功能代碼級進行立即重試,可以使用spring-retry等組件
- 延遲修複異常:指一些短時間內不能立即恢復的異常,需要延遲執行,等待故障修複。例如依賴的下游系統正在升級,導致一段時間服務介面中斷不可以用,需要等待服務啟動才能使用,一般通過定時任務設定一定時間間隔或者重跑次數去解決
- 人工修複異常:指系統沒辦法直接修複,出現了一些未知異常或者短時間內不可解決的異常,例如Redis宕掉無法預知修複時間、上線時腳本遺漏導致表裡缺少欄位等,需要人工干預進行重跑,一般通過後臺管理頁面操作
- 不可修複異常:不可修複異常指不能通過重跑就能解決的異常。如:上游系統傳輸格式有問題、消息事件內容本身有誤等引起的異常,這些即使重跑也解決不了問題,應該要從上游系統或者根源去解決。
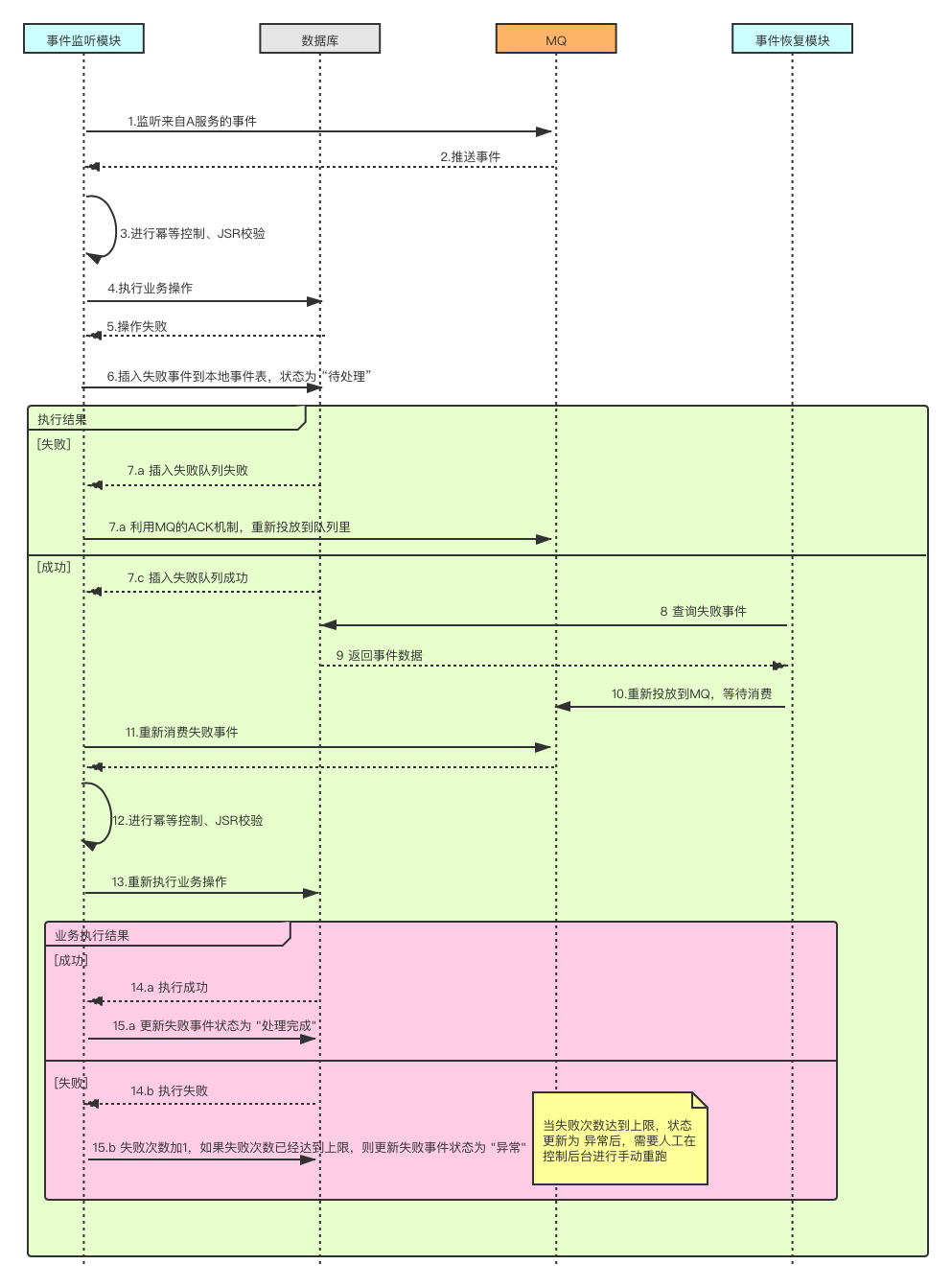
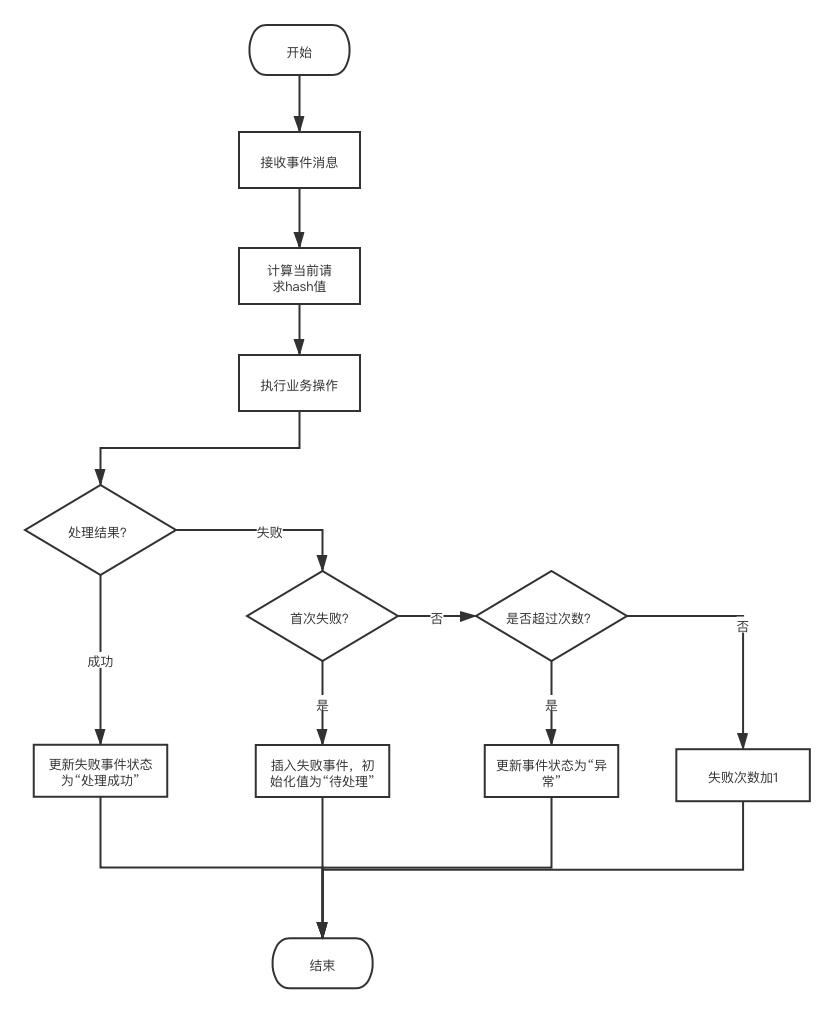
B服務異常處理流程
最後小明負責的B服務按照老梁的思路,重新調整了代碼,異常處理流程如下: