
日常中工作中我並沒有對kafka接觸很多,但瞭解到很多的框架都和kafka有著緊密的關係。比如rockmetmq是參考了kafka的設計,neflix的緩存組件ehcache是用kafka做數據的同步。同時kafka在大數據方面通常和spark,hadoop,storm一起使用,所以我對kafka也 ...
日常中工作中我並沒有對kafka接觸很多,但瞭解到很多的框架都和kafka有著緊密的關係。比如rockmetmq是參考了kafka的設計,neflix的緩存組件ehcache是用kafka做數據的同步。同時kafka在大數據方面通常和spark,hadoop,storm一起使用,所以我對kafka也產生了一些興趣,抽了些時間去研究了一下這個框架。因為還沒有深入的研究和使用,所以只能算是初探~。
kafka架構
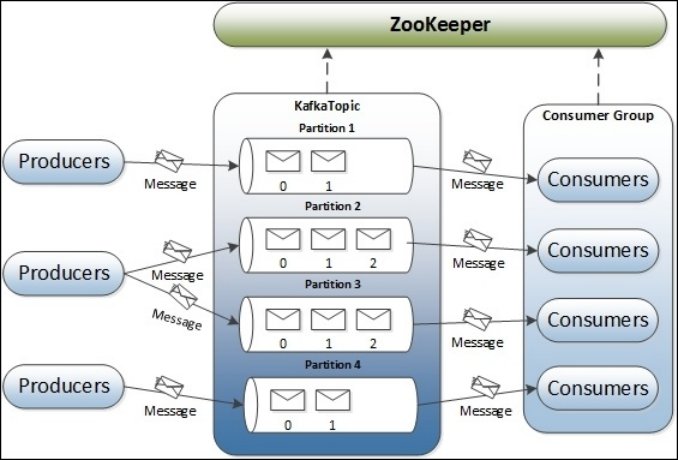

左邊是kafka,右邊是rocketmq。kafka的架構如上所示,與rocketmq很相似。不同的是rocketmq用的是namesrv,而kafka用的是zookeeper。zookeeper在kafka的作用是起到一個動態註冊發現與負載均衡的作用。
zookeeper與kafka
1、broker註冊
kafka使用了全局唯一的數字來指代每個Broker伺服器,不同的Broker必須使用不同的Broker ID進行註冊,創建完節點後,每個Broker就會將自己的IP地址和埠信息記錄到該節點中去。其中,Broker創建的節點類型是臨時節點,一旦Broker宕機,則對應的臨時節點也會被自動刪除。比如我本地起了三個Broker,查看zookeepr /brokers/ids的目錄就看到以下內容
ls /brokers/ids [0, 1, 2] get /brokers/ids/1 {"listener_security_protocol_map":{"PLAINTEXT":"PLAINTEXT"},"endpoints":["PLAINTEXT://10.66.51.58:9093"],"jmx_port":-1,"host":"10.66.51.58","timestamp":"1532936089303","port":9093,"version":4} cZxid = 0x14b ctime = Mon Jul 30 15:34:49 CST 2018 mZxid = 0x14b mtime = Mon Jul 30 15:34:49 CST 2018 pZxid = 0x14b cversion = 0 dataVersion = 0 aclVersion = 0 ephemeralOwner = 0x164ea1258570003 dataLength = 192 numChildren = 0
2、topic註冊
在kafka中,同一個Topic的消息會被分成多個分區並將其分佈在多個Broker上,這些分區信息及與Broker的對應關係也都是由Zookeeper在維護,由專門的節點/broker/topics來記錄。Broker伺服器啟動後,會到對應Topic節點(/brokers/topics)上註冊自己的Broker ID並寫入針對該Topic的分區信息。比如Topic "test3"創建時指定了三個分區。查看zookeeper內容則知道"2"分區放在Broker-0,"1"分區放在Broker-2,"0"分區放在Broker-1
ls /brokers/topics [connect-test, test3, test, my-replicated-topic, __consumer_offsets] get /brokers/topics/test3 {"version":1,"partitions":{"2":[0],"1":[2],"0":[1]}} cZxid = 0x154 ctime = Mon Jul 30 16:11:30 CST 2018 mZxid = 0x154 mtime = Mon Jul 30 16:11:30 CST 2018 pZxid = 0x158 cversion = 1 dataVersion = 0 aclVersion = 0 ephemeralOwner = 0x0 dataLength = 52 numChildren = 1
3、生產者負載均衡
由於同一個Topic消息會被分區並將其分佈在多個Broker上,因此,生產者需要將消息合理地發送到這些分散式的Broker上,那麼如何實現生產者的負載均衡,Kafka支持傳統的四層負載均衡,也支持Zookeeper方式實現負載均衡。
(1) 四層負載均衡,根據生產者的IP地址和埠來為其確定一個相關聯的Broker。通常,一個生產者只會對應單個Broker,然後該生產者產生的消息都發往該Broker。這種方式邏輯簡單,每個生產者不需要同其他系統建立額外的TCP連接,只需要和Broker維護單個TCP連接即可。但是,其無法做到真正的負載均衡,因為實際系統中的每個生產者產生的消息量及每個Broker的消息存儲量都是不一樣的,如果有些生產者產生的消息遠多於其他生產者的話,那麼會導致不同的Broker接收到的消息總數差異巨大,同時,生產者也無法實時感知到Broker的新增和刪除。
(2) 使用Zookeeper進行負載均衡,由於每個Broker啟動時,都會完成Broker註冊過程,生產者會通過該節點的變化來動態地感知到Broker伺服器列表的變更,這樣就可以實現動態的負載均衡機制。
4、消費者負載均衡
與生產者類似,Kafka中的消費者同樣需要進行負載均衡來實現多個消費者合理地從對應的Broker伺服器上接收消息,每個消費者分組包含若幹消費者,每條消息都只會發送給分組中的一個消費者,不同的消費者分組消費自己特定的Topic下麵的消息,互不幹擾。
5、消費者offset的存儲
消費者的offset我之前瞭解到是存在zookeeper上面,但下載最新版的沒在上面找到,後面瞭解到是存到了broker上面~。
消息的持久化
Kafka 對消息的存儲和緩存嚴重依賴於文件系統,但kafka的性能卻遠超出了人們對磁碟IO的性能預估。主要原因有:
1、順序磁碟IO
關於磁碟性能的關鍵事實是,磁碟的吞吐量和過去十年裡磁碟的定址延遲不同。因此,使用6個7200rpm、SATA介面、RAID-5的磁碟陣列在JBOD配置下的順序寫 入的性能約為600MB/秒,但隨機寫入的性能僅約為100k/秒,相差6000倍以上。因為線性的讀取和寫入是磁碟使用模式中最有規律的,並且由操作系統進行了大量的優化。現代操作系統提供了 read-ahead 和 write-behind 技術,read-ahead 是以大的 data block 為單位預先讀取數據,而 write-behind 是將多個小型的邏輯寫 合併成一次大型的物理磁碟寫入。關於該問題的進一步討論可以參考 ACM Queue article,他們發現實際上順序磁碟訪問在某些情況下比隨機記憶體訪問還要快!
2、pageCache而不是in-memory cache
為了提高性能,現代操作系統在越來越註重使用記憶體對磁碟進行 cache。現代操作系統主動將所有空閑記憶體用作 disk caching,代價是在記憶體回收時性能會有所降低。所有對磁碟的讀寫操作都會通過這個統一的 cache。如果不使用直接I/O,該功能不能輕易關閉。因此即使進程維護了 in-process cache,該數據也可能會被覆制到操作系統的 pagecache 中,事實上所有內容都被存儲了兩份。
此外,Kafka 建立在 JVM 之上,瞭解 Java 記憶體使用的人都知道兩點:
- 對象的記憶體開銷非常高,通常是所存儲的數據的兩倍(甚至更多)。
- 隨著堆中數據的增加,Java 的垃圾回收變得越來越複雜和緩慢。
受這些因素影響,相比於維護 in-memory cache 或者其他結構,使用文件系統和 pagecache 顯得更有優勢--我們可以通過自動訪問所有空閑記憶體將可用緩存的容量至少翻倍,並且通過存儲緊湊的位元組結構而不是獨立的對象,有望將緩存容量再翻一番。 這樣使得32GB的機器緩存容量可以達到28-30GB,並且不會產生額外的 GC 負擔。此外,即使服務重新啟動,緩存依舊可用,而 in-process cache 則需要在記憶體中重建(重建一個10GB的緩存可能需要10分鐘),否則進程就要從 cold cache 的狀態開始(這意味著進程最初的性能表現十分糟糕)。 這同時也極大的簡化了代碼,因為所有保持 cache 和文件系統之間一致性的邏輯現在都被放到了 OS 中,這樣做比一次性的進程內緩存更準確、更高效。如果你的磁碟使用更傾向於順序讀取,那麼 read-ahead 可以有效的使用每次從磁碟中讀取到的有用數據預先填充 cache。
所以kafka給出了一個簡單的設計:相比於維護儘可能多的 in-memory cache,並且在空間不足的時候匆忙將數據 flush 到文件系統,我們把這個過程倒過來。所有數據一開始就被寫入到文件系統的持久化日誌中,而不用在 cache 空間不足的時候 flush 到磁碟。實際上,這表明數據被轉移到了內核的 pagecache 中。
3、隊列存儲數據
消息系統使用的持久化數據結構,BTree 是最通用的數據結構,可以在消息系統能夠支持各種事務性和非事務性語義。 雖然 BTree 的操作複雜度是 O(log N),但成本也相當高。通常我們認為 O(log N) 基本等同於常數時間,但這條在磁碟操作中不成立。磁碟定址是每10ms一跳,並且每個磁碟同時只能執行一次定址,因此並行性受到了限制。 因此即使是少量的磁碟定址也會很高的開銷。由於存儲系統將非常快的cache操作和非常慢的物理磁碟操作混合在一起,當數據隨著 fixed cache 增加時,可以看到樹的性能通常是非線性的——比如數據翻倍時性能下降不只兩倍。
所以直觀來看,持久化隊列可以建立在簡單的讀取和向文件後追加兩種操作之上,這和日誌解決方案相同。這種架構的優點在於所有的操作複雜度都是O(1),而且讀操作不會阻塞寫操作,讀操作之間也不會互相影響。這有著明顯的性能優勢,由於性能和數據大小完全分離開來——伺服器現在可以充分利用大量廉價、低轉速的1+TB SATA硬碟。 雖然這些硬碟的定址性能很差,但他們在大規模讀寫方面的性能是可以接受的,而且價格是原來的三分之一、容量是原來的三倍。
在不產生任何性能損失的情況下能夠訪問幾乎無限的硬碟空間,這意味著我們可以提供一些其它消息系統不常見的特性。例如:在 Kafka 中,我們可以讓消息保留相對較長的一段時間(比如一周),而不是試圖在被消費後立即刪除。正如我們後面將要提到的,這給消費者帶來了很大的靈活性。
消息的傳輸
解決了數據持久化的問題,還需要解決數據的發送和消費等相關傳輸問題。
1、批量操作而不是多次小IO
一旦消除了磁碟訪問模式不佳的情況,系統性能低下的主要原因就剩下了兩個:大量的小型 I/O 操作,以及過多的位元組拷貝。小型的 I/O 操作發生在客戶端和服務端之間以及服務端自身的持久化操作中。為了避免這種情況,kafka的通訊協議是建立在一個 “消息塊” 的抽象基礎上,合理將消息分組。 這使得網路請求將多個消息打包成一組,而不是每次發送一條消息,從而使整組消息分擔網路中往返的開銷。Consumer 每次獲取多個大型有序的消息塊,並由服務端 依次將消息塊一次載入到它的日誌中。
這個簡單的優化對速度有著數量級的提升。批處理允許更大的網路數據包,更大的順序讀寫磁碟操作,連續的記憶體塊等等,所有這些都使 KafKa 將隨機流消息順序寫入到磁碟, 再由 consumers 進行消費。
2、sendfile避免過多的位元組拷貝
broker 維護的消息日誌本身就是一個文件目錄,每個文件都由一系列以相同格式寫入到磁碟的消息集合組成,這種寫入格式被 producer 和 consumer 共用。保持這種通用格式可以對一些很重要的操作進行優化: 持久化日誌塊的網路傳輸。 現代的unix 操作系統提供了一個高度優化的編碼方式,用於將數據從 pagecache 轉移到 socket 網路連接中;在 Linux 中系統調用 sendfile 做到這一點。
為了理解 sendfile 的意義,瞭解數據從文件到套接字的常見數據傳輸路徑就非常重要:
- 操作系統從磁碟讀取數據到內核空間的 pagecache
- 應用程式讀取內核空間的數據到用戶空間的緩衝區
- 應用程式將數據(用戶空間的緩衝區)寫回內核空間到套接字緩衝區(內核空間)
- 操作系統將數據從套接字緩衝區(內核空間)複製到通過網路發送的 NIC 緩衝區
這顯然是低效的,有四次 copy 操作和兩次系統調用。使用 sendfile 方法,可以允許操作系統將數據從 pagecache 直接發送到網路,這樣避免重新複製數據。所以這種優化方式,只需要最後一步的copy操作,將數據複製到 NIC 緩衝區。
我們期望一個普遍的應用場景,一個 topic 被多消費者消費。使用上面提交的 zero-copy(零拷貝)優化,數據在使用時只會被覆制到 pagecache 中一次,節省了每次拷貝到用戶空間記憶體中,再從用戶空間進行讀取的消耗。這使得消息能夠以接近網路連接速度的 上限進行消費。
pagecache 和 sendfile 的組合使用意味著,在一個kafka集群中,大多數 consumer 消費時,您將看不到磁碟上的讀取活動,因為數據將完全由緩存提供。
3、壓縮數據
在某些情況下,數據傳輸的瓶頸不是 CPU ,也不是磁碟,而是網路帶寬。對於需要通過廣域網在數據中心之間發送消息的數據管道尤其如此。當然,用戶可以在不需要 Kakfa 支持下一次一個的壓縮消息。但是這樣會造成非常差的壓縮比和消息重覆類型的冗餘,比如 JSON 中的欄位名稱或者是或 Web 日誌中的用戶代理或公共字元串值。高性能的壓縮是一次壓縮多個消息,而不是壓縮單個消息。
Kafka 以高效的批處理格式支持一批消息可以壓縮在一起發送到伺服器。這批消息將以壓縮格式寫入,並且在日誌中保持壓縮,只會在 consumer 消費時解壓縮。
Kafka 支持 GZIP,Snappy 和 LZ4 壓縮協議
消息是推還是拉?
Kafka 在這方面採取了一種較為傳統的設計方式,也是大多數的消息系統所共用的方式:即 producer 把數據 push 到 broker,然後 consumer 從 broker 中 pull 數據。 但也有一些 系統,比如 Scribe 和 Apache Flume,沿著一條完全不同的 push-based 的路徑,將數據 push 到下游節點。這兩種方法都有優缺點。然而,由於 broker 控制著數據傳輸速率, 所以 push-based 系統很難處理不同的 consumer。讓 broker 控制數據傳輸速率主要是為了讓 consumer 能夠以可能的最大速率消費;不幸的是,這導致著在 push-based 的系統中,當消費速率低於生產速率時,consumer 往往會不堪重負(本質上類似於拒絕服務攻擊)。pull-based 系統有一個很好的特性, 那就是當 consumer 速率落後於 producer 時,可以在適當的時間趕上來。還可以通過使用某種 backoff 協議來減少這種現象:即 consumer 可以通過 backoff 表示它已經不堪重負了,然而通過獲得負載情況來充分使用 consumer(但永遠不超載)這一方式實現起來比它看起來更棘手。前面以這種方式構建系統的嘗試,引導著 Kafka 走向了更傳統的 pull 模型。
另一個 pull-based 系統的優點在於:它可以大批量生產要發送給 consumer 的數據。而 push-based 系統必須選擇立即發送請求或者積累更多的數據,然後在不知道下游的 consumer 能否立即處理它的情況下發送這些數據。如果系統調整為低延遲狀態,這就會導致一次只發送一條消息,以至於傳輸的數據不再被緩衝,這種方式是極度浪費的。 而 pull-based 的設計修複了該問題,因為 consumer 總是將所有可用的(或者達到配置的最大長度)消息 pull 到 log 當前位置的後面,從而使得數據能夠得到最佳的處理而不會引入不必要的延遲。
簡單的 pull-based 系統的不足之處在於:如果 broker 中沒有數據,consumer 可能會在一個緊密的迴圈中結束輪詢,實際上 busy-waiting 直到數據到來。為了避免 busy-waiting,我們在 pull 請求中加入參數,使得 consumer 在一個“long pull”中阻塞等待,直到數據到來(還可以選擇等待給定位元組長度的數據來確保傳輸長度)。
消息的offset
大多數消息系統都在 broker 上保存被消費消息的元數據。也就是說,當消息被傳遞給 consumer,broker 要麼立即在本地記錄該事件,要麼等待 consumer 的確認後再記錄。這是一種相當直接的選擇,而且事實上對於單機伺服器來說,也沒與其它地方能夠存儲這些狀態信息。 由於大多數消息系統用於存儲的數據結構規模都很小,所以這也是一個很實用的選擇——因為只要 broker 知道哪些消息被消費了,就可以在本地立即進行刪除,一直保持較小的數據量。
但要讓 broker 和 consumer 就被消費的數據保持一致性也不是一個小問題。如果 broker 在每條消息被髮送到網路的時候,立即將其標記為 consumed,那麼一旦 consumer 無法處理該消息(可能由 consumer 崩潰或者請求超時或者其他原因導致),該消息就會丟失。 為瞭解決消息丟失的問題,許多消息系統增加了確認機制:即當消息被髮送出去的時候,消息僅被標記為sent 而不是 consumed;然後 broker 會等待一個來自 consumer 的特定確認,再將消息標記為consumed。這個策略修複了消息丟失的問題,但也產生了新問題。 首先,如果 consumer 處理了消息但在發送確認之前出錯了,那麼該消息就會被消費兩次。第二個是關於性能的,現在 broker 必須為每條消息保存多個狀態(首先對其加鎖,確保該消息只被髮送一次,然後將其永久的標記為 consumed,以便將其移除)。 還有更棘手的問題要處理,比如如何處理已經發送但一直得不到確認的消息。
Kafka 使用完全不同的方式解決消息丟失問題。Kafka的 topic 被分割成了一組完全有序的 partition,其中每一個 partition 在任意給定的時間內只能被每個訂閱了這個 topic 的 consumer 組中的一個 consumer 消費。這意味著 partition 中 每一個 consumer 的位置僅僅是一個數字,即下一條要消費的消息的offset。這使得被消費的消息的狀態信息相當少,每個 partition 只需要一個數字。這個狀態信息還可以作為周期性的 checkpoint。這以非常低的代價實現了和消息確認機制等同的效果。
這種方式還有一個附加的好處。consumer 可以回退到之前的 offset 來再次消費之前的數據,這個操作違反了隊列的基本原則,但事實證明對大多數 consumer 來說這是一個必不可少的特性。 例如,如果 consumer 的代碼有 bug,並且在 bug 被髮現前已經有一部分數據被消費了, 那麼 consumer 可以在 bug 修複後通過回退到之前的 offset 來再次消費這些數據。
以上就是我整理的一些關於kafka的資料,主要還是集中在概念設計這一塊,不知道大家看了有沒有有所收穫呢。



{kind=link}