
git是什麼 簡單來說,Git,它是一個快速的 分散式版本控制系統 。 同傳統的 集中式版本控制系統 不同,Git的分散式特性使得開發者間的協作變得更加靈活多樣。 這時候我們會想到: 1. 什麼又是版本控制呢? 2. 什麼是分散式什麼是集中式? 我們帶著問題往下走。 版本控制 版本控制是一種記錄一個 ...
git是什麼
簡單來說,Git,它是一個快速的 分散式版本控制系統 (Distributed Version Control System,簡稱 DVCS) 。
同傳統的 集中式版本控制系統 (Centralized Version Control Systems,簡稱CVCS) 不同,Git的分散式特性使得開發者間的協作變得更加靈活多樣。
這時候我們會想到:
- 什麼又是版本控制呢?
- 什麼是分散式什麼是集中式?
我們帶著問題往下走。
版本控制
版本控制是一種記錄一個或若幹文件內容變化,以便將來查閱特定版本修訂情況的系統。
比如:有一位程式員他可能需要保存一個代碼文件的所有的修訂版本,這樣就可以
- 將某個文件回溯到之前的狀態
- 甚至將整個項目都回退到過去某個時間點的狀態
- 比較文件的變化細節,查出最後是誰修改了哪個地方,從而找出導致怪異問題出現的原因
這時候採用版本控制就是一個非常明智的選擇,使用版本控制系統通常還意味著,就算你亂來一氣把整個項目中的文件改的改刪的刪,你也照樣可以輕鬆恢復到原先的樣子。 但額外增加的工作量卻微乎其微。
版本控制的成長
兒童:人們通過複製整個項目的方式來保存不同的版本,或許還會改名加上備份時間以示區別。好處就是簡單,但是特別容易犯錯,一不小心會寫錯文件或者覆蓋意想外的文件。
少年:人們為了上面的問題,很久以前就開發了許多種本地版本控制系統,大多是採用某種簡單的資料庫來記錄文件的歷次更新差異,比如其中比較流行的 RCS 。
青年:人們又遇到一個問題,如何讓在不同系統上的開發者協同工作? 於是,集中化的版本控制系統( CVCS)應運而生。 這類系統,諸如 CVS 、 Subversion ,都有一個單一的集中管理的伺服器,保存所有文件的修訂版本,而協同工作的人們都通過客戶端連到這台伺服器,取出最新的文件或者提交更新。現在,每個人都可以在一定程度上看到項目中的其他人正在做些什麼。 而管理員也可以輕鬆掌控每個開發者的許可權,並且管理一個 CVCS。
事分兩面,有好有壞。 這麼做最顯而易見的缺點是中央伺服器的單方面故障。 如果關機一小時,那麼在這一小時內,誰都無法提交更新,也就無法協同工作。 如果中心資料庫所在的磁碟發生損壞,又沒有做恰當備份,毫無疑問你將丟失所有數據——包括項目的整個變更歷史,只剩下人們在各自機器上保留的單獨快照。
壯年:於是分散式版本控制系統面世了。 在這類系統中,像 Git 、Mercurial 等,客戶端並不只提取最新版本的文件快照,而是把代碼倉庫完整地鏡像下來。 這麼一來,任何一處協同工作用的伺服器發生故障,事後都可以用任何一個鏡像出來的本地倉庫恢復。 因為每一次的克隆操作,實際上都是一次對代碼倉庫的完整備份。
許多這類系統都可以指定和若幹不同的遠端代碼倉庫進行交互。籍此,你就可以在同一個項目中,分別和不同工作小組的人相互協作。 你可以根據需要設定不同的協作流程,比如層次模型式的工作流,而這在以前的集中式系統中是無法實現的。
git誕生史記
很多人都知道, Linus 在1991年創建了開源的 Linux ,從此,Linux 系統不斷發展,已經成為最大的伺服器系統軟體了。
Linus 雖然創建了 Linux,但 Linux 的壯大是靠全世界熱心的志願者參與的,這麼多人在世界各地為 Linux 編寫代碼,那 Linux 的代碼是如何管理的呢?
事實是,在2002年以前,世界各地的志願者把源代碼文件通過 diff 的方式發給 Linus,然後由 Linus 本人通過手工方式合併代碼!
你也許會想,為什麼 Linus 不把 Linux 代碼放到版本控制系統里呢?不是有 CVS、SVN這些免費的版本控制系統嗎?因為 Linus 堅定地反對 CVS 和 SVN,這些集中式的版本控制系統不但速度慢,而且必須聯網才能使用。有一些商用的版本控制系統,雖然比 CVS 、 SVN 好用,但那是付費的,和 Linux 的開源精神不符。
不過,到了2002年,Linux 系統已經發展了十年了,代碼庫之大讓 Linus 很難繼續通過手工方式管理了,社區的弟兄們也對這種方式表達了強烈不滿,於是 Linus 選擇了一個商業的版本控制系統 BitKeeper,BitKeeper 的東家 BitMover 公司出於人道主義精神,授權 Linux 社區免費使用這個版本控制系統。
安定團結的大好局面在2005年就被打破了,原因是 Linux 社區牛人聚集,不免沾染了一些梁山好漢的江湖習氣。開發 Samba 的 Andrew 試圖破解 BitKeeper 的協議(這麼乾的其實也不只他一個),被 BitMover 公司發現了(監控工作做得不錯!),於是 BitMover 公司怒了,要收回 Linux 社區的免費使用權。
Linus 可以向 BitMover 公司道個歉,保證以後嚴格管教弟兄們,嗯,這是不可能的。實際情況是這樣的:
Linus 花了兩周時間自己用 C 寫了一個分散式版本控制系統,這就是 Git!一個月之內,Linux 系統的源碼已經由 Git 管理了!牛是怎麼定義的呢?大家可以體會一下。
Git 迅速成為最流行的分散式版本控制系統,尤其是2008年,GitHub 網站上線了,它為開源項目免費提供 Git 存儲,無數開源項目開始遷移至 GitHub,包括 jQuery,PHP,Ruby等等。
歷史就是這麼偶然,如果不是當年 BitMover 公司威脅 Linux 社區,可能現在我們就沒有免費而超級好用的 Git 了。
git的優點
在集中式系統中,每個開發者就像是連接在集線器上的節點,彼此的工作方式大體相像。 而在 Git 中,每個開發者同時扮演著節點和集線器的角色——也就是說,每個開發者既可以將自己的代碼貢獻到其他的倉庫中,同時也能維護自己的公開倉庫,讓其他人可以在其基礎上工作並貢獻代碼。 由此,Git 的分散式協作可以為你的項目和團隊衍生出種種不同的工作流程。
速度快
簡單的設計,易用
對非線性開發模式的強力支持(允許成千上萬個並行開發的分支)
完全分散式
有能力高效管理類似 Linux 內核一樣的超大規模項目(速度和數據量)
git實現原理
從根本上來講 Git 是一個內容定址 (content-addressable) 文件系統,併在此之上提供了一個版本控制系統的用戶界面,Git 的核心部分是一個簡單的鍵值對資料庫 (key-value data store) 。 你可以向該資料庫插入任意類型的內容,它會返回一個鍵值,通過該鍵值可以在任意時刻再次檢索 (retrieve) 該內容。
初始化的git目錄
當在一個新目錄或已有目錄執行 git init 時,Git 會創建一個 .git 目錄。 這個目錄包含了幾乎所有 Git 存儲和操作的對象。 如若想備份或複製一個版本庫,只需把這個目錄拷貝至另一處即可。
$ ls -F1
HEAD
config*
description
hooks/
info/
objects/
refs/這是一個全新的 git init 版本庫,這將是你看到的預設結構。
description文件僅供GitWeb程式使用,我們無需關心。config文件包含項目特有的配置選項。info目錄包含一個全局性排除(global exclude)文件,用以放置那些不希望被記錄在.gitignore文件中的忽略模式(ignored patterns)。hooks目錄包含客戶端或服務端的鉤子腳本(hook scripts)。objects目錄存儲所有數據內容。refs目錄存儲指向數據(分支)的提交對象的指針HEAD文件指示目前被檢出的分支index文件保存暫存區信息。
git對象模型
所有用來表示項目歷史信息的文件,是通過一個40個字元的 (40-digit) “對象名”來索引的,對象名看起來像這樣:
6ff87c4664981e4397625791c8ea3bbb5f2279a3你會在Git里到處看到這種“40個字元”字元串。每一個“對象名”都是對“對象”內容做 SHA1 哈希計算得來的,( SHA1 是一種密碼學的哈希演算法)。這樣就意味著兩個不同內容的對象不可能有相同的“對象名”。
這樣做會有幾個好處:
Git只要比較對象名,就可以很快的判斷兩個對象是否相同。- 因為在每個倉庫
(repository)的“對象名”的計算方法都完全一樣,如果同樣的內容存在兩個不同的倉庫中,就會存在相同的“對象名”下。 Git還可以通過檢查對象內容的SHA1的哈希值和“對象名”是否相同,來判斷對象內容是否正確。
對象
每個對象 (object) 包括三個部分:類型,大小和內容。大小就是指內容的大小,內容取決於對象的類型,有四種類型的對象:"blob" 、 "tree" 、 "commit" 和 "tag" 。
“blob”用來存儲文件數據,通常是一個文件。“tree”有點像一個目錄,它管理一些“tree”或是 “blob”(就像文件和子目錄)。一個
“commit”只指向一個"tree",它用來標記項目某一個特定時間點的狀態。它包括一些關於時間點的元數據,如時間戳、最近一次提交的作者、指向上次提交(commits)的指針等等。一個
“tag”是來標記某一個提交(commit)的方法。
幾乎所有的 Git 功能都是使用這四個簡單的對象類型來完成的。它就像是在你本機的文件系統之上構建一個小的文件系統。
Blob對象
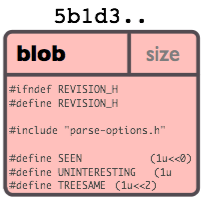
一個 blob 通常用來存儲文件的內容。
Tree 對象

一個 tree 對象可以指向一個包含文件內容的 blob 對象, 也可以是其它包含某個子目錄內容的其它 tree 對象,它一般用來表示內容之間的目錄層次關係。 Tree 對象、blob 對象和其它所有的對象一樣,都用其內容的 SHA1 哈希值來命名的;只有當兩個 tree 對象的內容完全相同(包括其所指向所有子對象)時,它的名字才會一樣,反之亦然。這樣就能讓Git 僅僅通過比較兩個相關的 tree 對象的名字是否相同,來快速的判斷其內容是否不同。
Commit對象
commit 對象指向一個 tree 對象,並且帶有相關的描述信息。

一個提交 commit 由以下的部分組成:
一個
tree對象:tree對象的 `SHA1簽名, 代表著目錄在某一時間點的內容。父對象
(parent(s)): 提交(commit)的SHA1簽名代表著當前提交前一步的項目歷史。合併的提交(merge commits)可能會有不只一個父對象。如果一個提交沒有父對象,那麼我們就叫它“根提交"(root commit),它就代表著項目最初的一個版本(revision)。 每個項目必須有至少有一個“根提交"(root commit)。作者
(author):做了此次修改的人的名字,還有修改日期。- 提交者
(committer):實際創建提交(commit)的人的名字, 同時也帶有提交日期。 註釋:用來描述此次提交。
註意:一個提交(commit)本身並沒有包括任何信息來說明其做了哪些修改; 所有的修改(changes)都是通過與父提交(parents)的內容比較而得出的。 值得一提的是, 儘管git可以檢測到文件內容不變而路徑改變的情況, 但是它不會去顯式(explicitly)的記錄文件的更名操作(可以看一下 git diff )。
一般用 git commit 來創建一個提交 (commit), 這個提交 (commit) 的父對象一般是當前分支 (current HEAD) ,同時把存儲在當前索引 (index) 的內容全部提交。
對象模型:
如果我們把它提交 (commit) 到一個 Git 倉庫中, 在 Git 中它們也許看起來就如下圖:
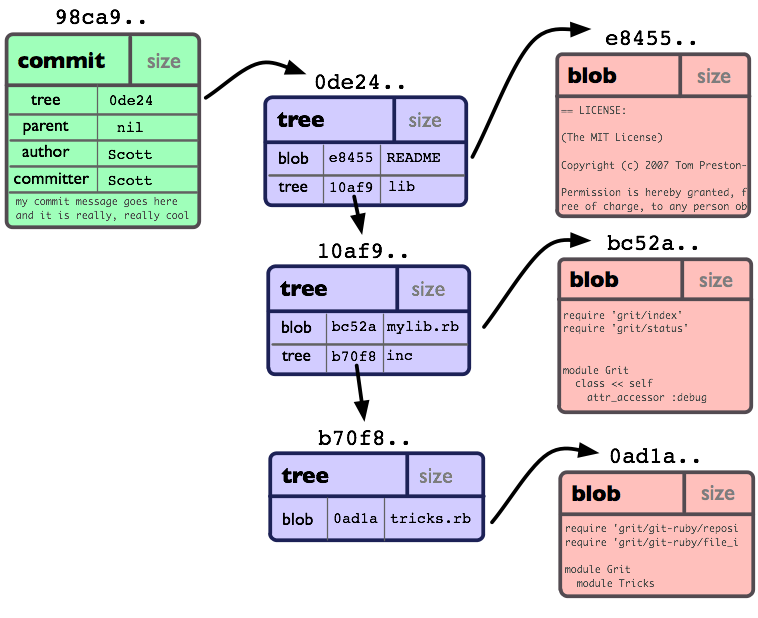
你可以看到:每個目錄都創建了 tree對象 (包括根目錄), 每個文件都創建了一個對應的 blob對象。最後有一個 commit 對象 來指向根 tree 對象 (root of trees) , 這樣我們就可以追蹤項目每一項提交內容.
標簽對象:
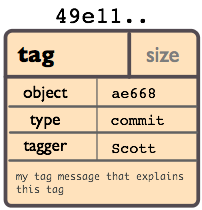
一個標簽對象包括一個對象名(SHA1簽名), 對象類型, 標簽名, 標簽創建人的名字(tagger), 還有一條可能包含有簽名(signature)的消息.
回到我們的問題
強大的git分支
有人把 Git 的分支模型稱為它的必殺技特性,也正因為這一特性,使得它 從眾多版本控制系統中脫穎而出。
Git 保存的不是文件的變化或者差異,而是一系列不同時刻的文件快照。
在進行提交操作時,Git 會保存一個提交對象(commit object)。知道了 Git 保存數據的方式,該提交對象會包含一個指向暫存內容快照的指針。 但不僅僅是這樣,該提交對象還包含了作者的姓名和郵箱、提交時輸入的信息以及指向它的父對象的指針。首次提交產生的提交對象沒有父對象,普通提交操作產生的提交對象有一個父對象,而由多個分支合併產生的提交對象有多個父對象,
當使用 git commit 新建一個提交對象前,Git 會先計算每一個子目錄的校驗和(40 個字元長度 SHA-1 字串),然後在 Git 倉庫中將這些目錄保存為樹(tree)對象。之後 Git 創建的提交對象,除了包含相關提交信息以外,還包含著指向這個樹對象(項目根目錄)的指針,如此它就可以在將來需要的時候,重現此次快照的內容了。
Git 中的分支,其實本質上僅僅是個指向 commit 對象的可變指針。Git 會使用 master 作為分支的預設名字。在若幹次提交後,你其實已經有了一個指向最後一次提交對象的 master 分支,它在每次提交的時候都會自動向前移動。
Git 是如何知道你當前在哪個分支上工作的呢?其實答案也很簡單,它保存著一個名為 HEAD 的特別指針。在 Git 中,它是一個指向你正在工作中的本地分支的指針,我們可以將 HEAD 想象為當前分支的別名。
由於 Git 中的分支實際上僅是一個包含所指對象校驗和的文件,所以創建和銷毀一個分支就變得非常廉價。說白了,新建一個分支就是向一個文件寫入 41 個位元組(外加一個換行符)那麼簡單,當然也就很快了。
大多數版本控制系統它們管理分支大多採取備份所有項目文件到特定目錄的方式,所以根據項目文件數量和大小不同,可能花費的時間也會有相當大的差別,快則幾秒,慢則數分鐘。
而 Git 的實現與項目複雜度無關,它永遠可以在幾毫秒的時間內完成分支的創建和切換。同時,因為每次提交時都記錄了祖先信息(parent 對象),將來要合併分支時,尋找恰當的合併基礎(譯註:即共同祖先)的工作其實已經自然而然地擺在那裡了,所以實現起來非常容易。Git 鼓勵開發者頻繁使用分支,正是因為有著這些特性作保障。
分支的新建與合併
- 新建分支併進入
$ git checkout -b iss53
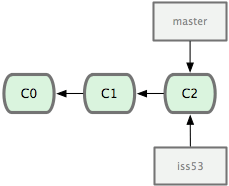
根據需求寫代碼並提交
$ git commit -a -m 'new text'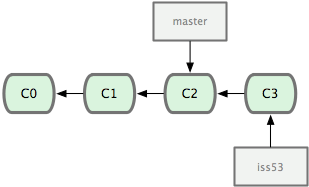
接到線上問題需要並且修改bug
$ git checkout master $ git checkout -b hotfix $ git commit -a -m 'fixed bug'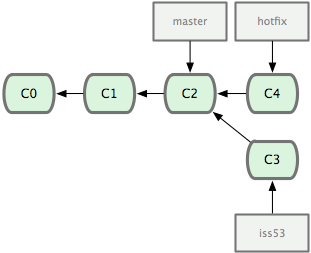
合併修改完bug的代碼進master(暫無衝突)
$ git checkout master $ git merge hotfix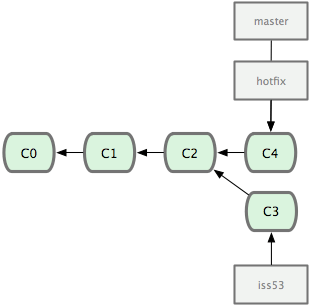
解決問題後刪除hotfix分支並返回原來的iss53分支繼續工作
$ git branch -d hotfix
$ git checkout iss53
$ git commit -a -m 'finished'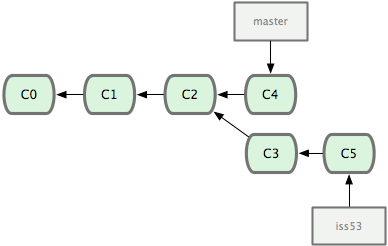
- 合併iss53分支進主分支
$ git checkout master
$ git merge iss53
請註意,這次合併操作的底層實現,並不同於之前 hotfix 的併入方式。因為這次你的開發歷史是從更早的地方開始分叉的。由於當前 master 分支所指向的提交對象(C4)並不是 iss53 分支的直接祖先,Git 不得不進行一些額外處理。就此例而言,Git 會用兩個分支的末端(C4 和 C5)以及它們的共同祖先(C2)進行一次簡單的三方合併計算。
這次,Git 沒有簡單地把分支指針右移,而是對三方合併後的結果重新做一個新的快照,並自動創建一個指向它的提交對象(C6)。這個提交對象比較特殊,它有兩個祖先(C4 和 C5)。
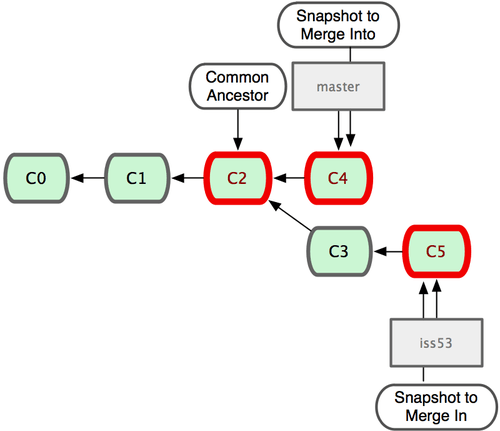
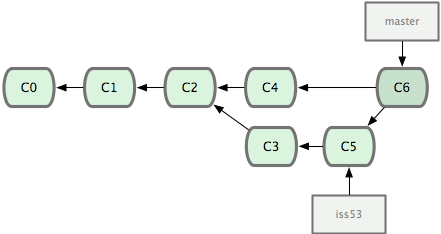
有時候合併操作並不會如此順利。如果在不同的分支中都修改了同一個文件的同一部分,Git 就無法乾凈地把兩者合到一起。如果你在解決問題 #53 的過程中修改了 hotfix 中修改的部分,將會出現問題。
Git 作了合併,但沒有提交,它會停下來等你解決衝突。
任何包含未解決衝突的文件都會以未合併 unmerged 的狀態列出。Git 會在有衝突的文件裡加入標準的衝突解決標記,可以通過它們來手工定位並解決這些衝突。
rebase 變基
最容易的整合分支的方法是 merge 命令,它會把兩個分支最新的快照(C3 和 C4)以及二者最新的共同祖先(C2)進行三方合併,合併的結果是產生一個新的提交對象(C5)。:
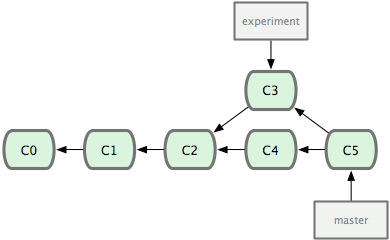
但是,如果你想讓 experiment分支歷史看起來像沒有經過任何合併一樣,還有另外一個選擇:你可以把在 C3 里產生的變化補丁在 C4 的基礎上重新打一遍。在 Git 里,這種操作叫做變基 (rebase)。有了 rebase 命令,就可以把在一個分支里提交的改變移到另一個分支里重放一遍。
$ git checkout experiment
$ git rebase master它的原理是回到兩個分支最近的共同祖先,根據當前分支(也就是要進行變基的分支 experiment )後續的歷次提交對象(這裡只有一個 C3),生成一系列文件補丁,然後以基底分支(也就是主幹分支 master)最後一個提交對象(C4)為新的出發點,逐個應用之前準備好的補丁文件,最後會生成一個新的合併提交對象(C3'),從而改寫 experiment 的提交歷史,使它成為 master 分支的直接下游
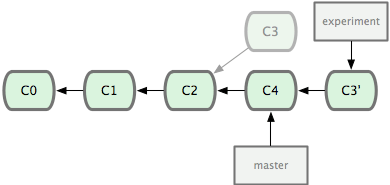
簡單講他就是把你的 experiment 分支里的每個提交 commit 取消掉,並且把它們臨時 保存為補丁 patch (這些補丁放到".git/rebase"目錄中),然後把 experiment 分支更新 到最新的 origin 分支,最後把保存的這些補丁應用到 experiment 分支上。
現在的 C3' 對應的快照,其實和普通的三方合併,即上個例子中的 C5 對應的快照內容一模一樣了。雖然最後整合得到的結果沒有任何區別,但變基能產生一個更為整潔的提交歷史。如果視察一個變基過的分支的歷史記錄,看起來會更清楚:仿佛所有修改都是在一根線上先後進行的,儘管實際上它們原本是同時並行發生的。
在 rebase 的過程中,也許會出現衝突 conflict。在這種情況,Git 會停止 rebase 並會讓你去解決 衝突;在解決完衝突後,用 git-add 命令去更新這些內容的索引 index, 然後,你無需執行 git-commit ,只要執行:
$ git rebase --continue
這樣git會繼續應用 apply 餘下的補丁。在任何時候,你可以用 --abort 參數來終止 rebase 的行動,並且 experiment 分支會回到 rebase 開始前的狀態。
$ git rebase --abort
git merge 應該只用於為了保留一個有用的,語義化的準確的歷史信息,而希望將一個分支的整個變更集成到另外一個 branch 時使用 rebase。這樣形成的清晰版本變更圖有著重要的價值。
所有其他的情況都是以不同的方式使用 rebase 的適合場景:經典型方式,三點式,interactive 和 cherry-picking。
我們使用變基的目的:是想要得到一個能在遠程分支上乾凈應用的補丁 — 比如某些項目你不是維護者,但想幫點忙的話,最好用變基:先在自己的一個分支里進行開發,當準備向主項目提交補丁的時候,根據最新的 origin/master 進行一次變基操作然後再提交,這樣維護者就不需要做任何整合工作(實際上是把解決分支補丁同最新主幹代碼之間衝突的責任,化轉為由提交補丁的人來解決。),只需根據你提供的倉庫地址作一次快進合併,或者直接採納你提交的補丁。
需要註意,合併結果中最後一次提交所指向的快照,無論是通過變基,還是三方合併,都會得到相同的快照內容,只不過提交歷史不同罷了。變基是按照每行的修改次序重演一遍修改,而合併是把最終結果合在一起。
有趣的變基
- 我在不同的topic之間來回切換,這樣會導致我的歷史中不同topic互相交叉,邏輯上組織混亂;
- 我們可能需要多個連續的commit來解決一個bug;
- 我可能會在commit中寫了錯別字,後來又做修改;
甚至我們在一次提交時純粹就是因為懶惰的原因,我可能吧很多的變更都放在一個commit中做了提交。
rebase可以合併commit
rebase可以用來修改commit信息
rebase可以用來拆分commit
git rebase -i HEAD~3變基也可以放到其他分支進行,並不一定非得根據分化之前的分支。
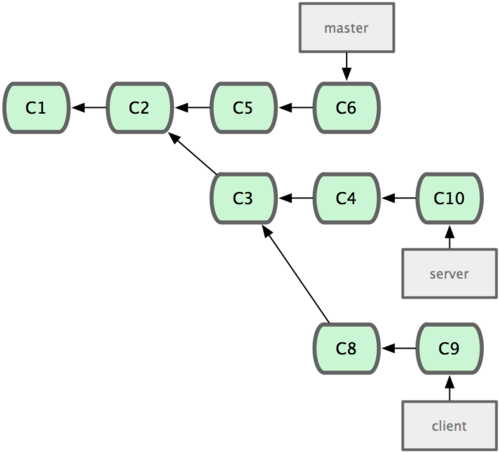
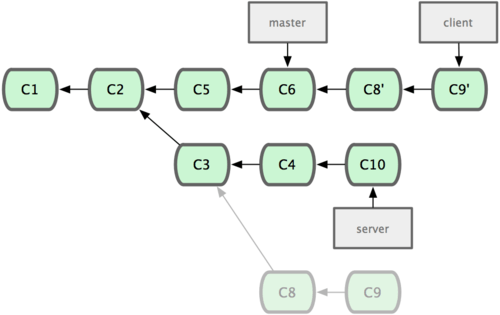
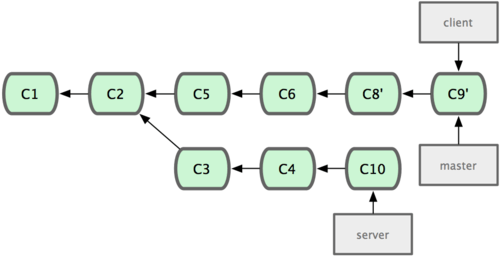
變基的風險
要用它得遵守一條準則:
不要在公共分支上使用rebase。
“No one shall rebase a shared branch” — Everyone about rebase
如果你遵循這條金科玉律,就不會出差錯。
在進行變基的時候,實際上拋棄了一些現存的提交對象而創造了一些類似但不同的新的提交對象。如果你把原來分支中的提交對象發佈出去,並且其他人更新下載後在其基礎上開展工作,而稍後你又用 git rebase 拋棄這些提交對象,把新的重演後的提交對象發佈出去的話,你的合作者就不得不重新合併他們的工作,這樣當你再次從他們那裡獲取內容時,提交歷史就會變得一團糟。
註意rebase往往會重寫歷史,所有已經存在的commits雖然內容沒有改變,但是commit本身的hash都會改變。
結論:只要你的分支上需要rebase的所有commits歷史還沒有被push過(比如上例中rebase時從分叉處開始有兩個commit歷史會被重寫),就可以安全地使用git rebase來操作。
上述結論可能還需要修正:對於不再有子分支的branch,並且因為rebase而會被重寫的commits都還沒有push分享過,可以比較安全地做rebase
思考下它的功能吧 git pull --rebase


