註: 出於職業要求, 本文中所有數字均被人為修改過, 並非真實數字, 很抱歉也不能貼出源代碼 目標: 個險客戶特征分析 背景: 目前市場部使用的推廣活動分析系統只能針對客戶調查返回的信息分析,且僅有年齡/性別/婚姻狀態/收入四個維度, 預測精度不高. 市場部希望能從現有的壽險客戶信息分析出影響他們選 ...
註: 出於職業要求, 本文中所有數字均被人為修改過, 並非真實數字, 很抱歉也不能貼出源代碼
目標:
個險客戶特征分析
背景:
目前市場部使用的推廣活動分析系統只能針對客戶調查返回的信息分析,且僅有年齡/性別/婚姻狀態/收入四個維度, 預測精度不高. 市場部希望能從現有的壽險客戶信息分析出影響他們選擇保險產品的關鍵因素, 藉此更有針對性地改進市場推廣活動
建模過程:
輸入: 從現有上千萬的客戶信息抽取其個人信息, 清洗後留下100多個特征, 包括婚姻, 年齡, 收入, 身高體重, 職業風險度, 居住區等. 用現有產品的類別作為分類信息, 包括儲蓄險, 終身險, 定期險, 投資險等.
演算法:
首先使用決策樹作粗略的預測檢驗輸入數據的有效性,使用隨機森林輸出重要的特征
決策樹的優點在於直觀, 容易實現, 並且能同時處理離散型和連續型變數, 過程中添加變數的改動也不大. 從數據中抽取了一年的客戶信息作為訓練集, 建立決策樹來預測客戶選擇的保險產品類別.
結果分析:
第一次運行命中率只有40%, 分析其混淆矩陣:

可以看出, 決策樹在最後一個分類的效果很差, 可以說沒有效果,在第三第四個分類上區分度也不高.
最後一個分類是投資險, 說明現有客戶特征並不能滿足投資險種分類的區別, 需要添加特征值
第三,四個分類其實都是定期險, 一種是繳費年限定期, 另一種是被保年齡定期, 本質上區別不大,可以合併起來
暫時過濾掉投資險客戶信息, 合併定期險客戶信息後, 重運行的混淆矩陣

可以看到分類已經有所改進了, 命中率可以達到60%
二三四分類的區分度看上去已經不錯了, 唯有第一類儲蓄險種區分度不高, 把這部分客戶信息過濾掉之後, 就可以達到不錯的命中率了.
隨機森林相比決策樹的優點除了準確率高之外, 更重要的是它能夠給出哪些feature比較重要! 而這正好就是市場部分所需要的東西.
最終結果顯示, 在過去的10年中, 客戶的婚姻狀態/年齡/身高體重對客戶的保險產品選擇貢獻度最高.
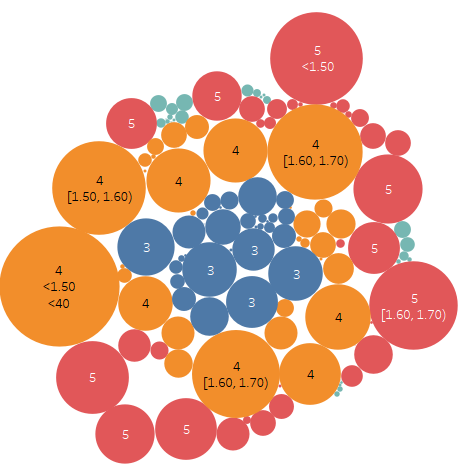
模型的結果最終會在Tableau上顯示:
如特征值貢獻度走勢

重要特征分類下的保單數統計