
引言 隨著雲計算技術的發展,Amazon Web Services (AWS) 作為一個開放的平臺,一直在幫助開發者更好的在雲上構建和使用開源軟體,同時也與開源社區緊密合作,推動開源項目的發展。 本文主要探討2024年值得關註的一些開源軟體及其在AWS上的應用情況,希望能夠給大家參考使用! 2024 ...
一. 優化配置參數
1.down-after-milliseconds
# sentinel down-after-milliseconds <master-name> <milliseconds>
#
# Number of milliseconds the master (or any attached【所依附的】 slave or sentinel) should
# be unreachable (as in, not acceptable reply to PING, continuously, for the
# specified period) in order to consider it in S_DOWN state (Subjectively
# Down).
# 這段的意思是sentinel在和master【註意:不僅僅是master,還有slave、sentinel】失聯多少毫秒後,可以做出主節點S_DOWN的判斷。
# 此參數的作用範圍不僅僅是 sentinel到master的連接;還有sentinel到slave的連接;sentinel到sentinel的連接。
# Default is 30 seconds.
sentinel down-after-milliseconds mymaster 30000
換句話說
down-after-milliseconds is the time in milliseconds an instance should not be reachable (either does not reply to our PINGs or it is replying with an error) for a Sentinel starting to think it is down.
2. parallel-syncs
# sentinel parallel-syncs <master-name> <numslaves> # # How many slaves we can reconfigure to point to the new slave simultaneously【同時】 # during the failover. Use a low number if you use the slaves to serve query # to avoid that all the slaves will be unreachable at about the same # time while performing the synchronization with the master.
##如果想在failover期間,slave同步新master的這個過程中,仍然想有部分slave 可以提供查詢服務,那麼可以將這個
##值設置小一點。【需要註意的是,這樣帶來的壞處就是:提供的查詢服務,不保證數據的一致性,和主節點是有數據差異的;
##此外,faiover的master 和 所有slave的數據同步過程被拉長了】 sentinel parallel-syncs mymaster 1
parallel-syncs sets the number of replicas that can be reconfigured to use the new master after a failover at the same time. The lower the number, the more time it will take for the failover process to complete, however if the replicas are configured to serve old data, you may not want all the replicas to re-synchronize with the master at the same time. While the replication process is mostly non blocking for a replica, there is a moment when it stops to load the bulk data from the master. You may want to make sure only one replica at a time is not reachable by setting this option to the value of 1.
該屬性用於指定,在故障轉移期間,即老的master出現問題,新的master剛晉升後,允許多少個slave同時從新的master進行數據同步。預設值為1表示所有slave逐個從新master進行數據同步。
3.failover-timeout
# sentinel failover-timeout <master-name> <milliseconds> # # Specifies the failover timeout in milliseconds. It is used in many ways: ##【註意:這個時間有多個用途】 # # - The time needed to re-start a failover after a previous failover was # already tried against the same master by a given Sentinel, is two # times the failover timeout. ---定語比較多,比較複雜,
# 抽出核心主謂賓:The time is two times the failover timeout. # # - The time needed for a slave replicating to a wrong master according # to a Sentinel current configuration, to be forced to replicate # with the right master, is exactly【確切地;恰好】 the failover timeout (counting since # the moment a Sentinel detected the misconfiguration).##【從sentinel發現配置信息不准確時開始計時】
# 抽出核心主謂賓:The time is exactly the failover timeout. # # - The time needed to cancel a failover that is already in progress but # did not produced any configuration change (SLAVEOF NO ONE yet not # acknowledged by the promoted slave).
# 抽出核心主謂賓:The time needed to cancel a failover. # # - The maximum time a failover in progress waits for all the slaves to be # reconfigured as slaves of the new master. However even after this time # the slaves will be reconfigured by the Sentinels anyway, but not with # the exact parallel-syncs progression as specified. # 【however後面的意思是說:然而,不管怎麼樣,即是超過了這個定義的最大閾值,sentinel還是可以修改配置的;
# 但是,不是嚴格按照前面定義的parallel-syncs的方式,例如,不再是前面預設的一個一個slave節點處理了。】 # Default is 3 minutes. sentinel failover-timeout mymaster 180000
Moreover Sentinels have a rule: if a Sentinel voted another Sentinel for the failover of a given master, it will wait some time to try to failover the same master again. This delay is the 2 * failover-timeout you can configure in sentinel.conf. This means that Sentinels will not try to failover the same master at the same time, the first to ask to be authorized will try, if it fails another will try after some time, and so forth.
指定故障轉移的超時時間,預設時間為3分鐘。該超時時間的用途有很多:
- 由於第一次故障轉移失敗,在同一個master上進行第二次故障轉移嘗試的時間為gai值的兩倍。
- 新master晉升完畢,slave從老master強制移到新master進行數據同步的時間閾值。
- 取消正在進行的故障轉移所需的時間閾值。
- 新master晉升完畢,所有的replicas的配置文件更新為新master的時間閾值。
二. 動態修改配置
通過redis-cli連接上sentinel後,通過sentinel set 命令可動態修改配置信息。例如,下麵的的命令修改了sentinel monitor 中的quorum的值。
SENTINEL SET mymaster quorum 5
下麵是sentinel set命令支持的參數
| 參數 | 實例 |
| quorum | SENTINEL SET mymaster quorum 2 |
| down-after-milliseconds | SENTINEL SET mymaster down-after-milliseconds 50000 |
| failover-timeout | SENTINEL SET mymaster failover-timeout 300000 |
| parallel-syncs | SENTINEL SET mymaster parallel-syncs 3 |
| notification-script | SENTINEL SET mymaster notification-script /var/redis/notify.sh |
| client-reconfig-script | SENTINEL SET mymaster client-reconfig-script /var/redis/reconfig.sh |
補充
Starting with Redis version 2.8.4, Sentinel provides an API in order to add, remove, or change the configuration of a given master. Note that if you have multiple sentinels you should apply the changes to all to your instances for Redis Sentinel to work properly. This means that changing the configuration of a single Sentinel does not automatically propagate the changes to the other Sentinels in the network.
The following is a list of SENTINEL subcommands used in order to update the configuration of a Sentinel instance.
- SENTINEL MONITOR
<name><ip><port><quorum>This command tells the Sentinel to start monitoring a new master with the specified name, ip, port, and quorum. It is identical to thesentinel monitorconfiguration directive insentinel.confconfiguration file, with the difference that you can't use a hostname in asip, but you need to provide an IPv4 or IPv6 address. - SENTINEL REMOVE
<name>is used in order to remove the specified master: the master will no longer be monitored, and will totally be removed from the internal state of the Sentinel, so it will no longer listed bySENTINEL mastersand so forth. - SENTINEL SET
<name>[<option><value>...] The SET command is very similar to theCONFIG SETcommand of Redis, and is used in order to change configuration parameters of a specific master. Multiple option / value pairs can be specified (or none at all). All the configuration parameters that can be configured viasentinel.confare also configurable using the SET command.
Starting with Redis version 6.2, Sentinel also allows getting and setting global configuration parameters which were only supported in the configuration file prior to that.
- SENTINEL CONFIG GET
<name>Get the current value of a global Sentinel configuration parameter. The specified name may be a wildcard, similar to the RedisCONFIG GETcommand. - SENTINEL CONFIG SET
<name><value>Set the value of a global Sentinel configuration parameter.
三.哨兵機制原理
3.1 三個定時任務
Sentinel維護著三個定時任務以檢測Redis節點及其它Sentinel節點的狀態。
(1)info任務
每個Sentinel 節點每10秒就會向Redis集群中的每個節點發送info命令,以獲得最新的Redis拓撲結構。
(2)心跳任務
每個sentinel節點每1秒就會向所有Redis節點及其它Sentinel節點發送一條ping命令,以檢測這些節點的存活狀態,該任務是判斷節點線上狀態的重要依據。
(3)發佈/訂閱任務
每個Sentinel節點在啟動時都會向所有Redis節點訂閱__sentinel__:hello 主題的信息,當Redis節點中該主題的信息發生了變化,就會立即通知到所有訂閱者。
啟動後,每個sentinel節點每2秒就會向每個redis節點發佈一條__sentinel__:hello主題信息,該信息是當前sentinel對每個redis節點線上狀態的判斷結果及當前sentinel節點信息。
sentinel即是發佈者也是訂閱者;redis類似與sentinel間的信息中轉站。
當sentinel節點接受到__sentinel__:hello主題信息後,就會讀取並解析這些信息,然後主要完成以下三項工作:
- 如果發現有新的sentinel節點加入,則記錄下新加入sentinel節點信息,並與其建立連接。
- 如果發現有sentinel leader選舉的選票信息,則執行leader選舉過程。
- 彙總其他sentinel節點對當前redis節點線上狀態的判斷結果,作為redis節點客觀下線的判斷依據。
3.2 Redis節點下線判斷
(1)主觀下線--Subjectively Down state
每個sentinel節點每秒就會向每個redis節點發送ping心跳檢測,如果sentinel在down-after-milliseconds時間內沒有收到某redis節點的回覆,則sentinel節點就會對該redis節點做出“下線狀態”的判斷。這個判斷僅僅是當前sentinel節點的“一家之言”,所以被稱為主觀下線。
(2)客觀下線--Objectively Down state
當sentinel主觀下線的節點是master時,該sentinel節點會向每個其它sentinel節點發送sentinel is-master-down-by-addr 命令,以詢問其對master線上狀態的判斷結果。這些sentinel節點在接收到命令後就會向這個發問sentinel節點響應0(線上)或1(下線)。當sentinel收到超過quorum個下線判斷後,就會對master做出客觀下線判斷。
【Redis Sentinel has two different concepts of being down, one is called a Subjectively Down condition (SDOWN) and is a down condition that is local to a given Sentinel instance. Another is called Objectively Down condition (ODOWN) and is reached when enough Sentinels (at least the number configured as the quorum parameter of the monitored master) have an SDOWN condition, and get feedback from other Sentinels using the SENTINEL is-master-down-by-addr command.】
3.3 Sentinel Leader選舉
當sentinel節點對master做出客觀下線判斷後,會由sentinel leader來完成後續的故障轉移,即sentinel集群中的節點也並非是對等節點,是存在leader 與 follower的。
sentinel 集群的leader選舉是通過Raft演算法實現的。大致思路:
每個選舉參與者都具有當選leader的資格,當其完成了“客觀下線”的判斷後,就會立即“毛遂自薦”推選自己做leader,然後將自己的提案發送給所有參與者。其它參與者在收到提案後,只要自己手中的選票沒有投出去,其就會立即通過該提案將同意結果反饋給提案者,後續再過來的提案會由於該參與者沒有了選票而被拒絕。當提案者收到了同意反饋數量大於等於max(quorum,sentinelNum/2+1)時,該提案者當選leader。
說明:
(1)在網路良好的情況下,基本就是誰先做出了“客觀下線”判斷,誰就會首先發起sentinel leader的選舉,誰就會等到大多數參與者的支持,誰就會當選leader。
(2)sentinel leader選舉會在每次故障轉移執行前進行。
(3)故障轉移結束後,sentinel不再維護leader-follower關係,即leader不再存在。
3.4 master選擇演算法
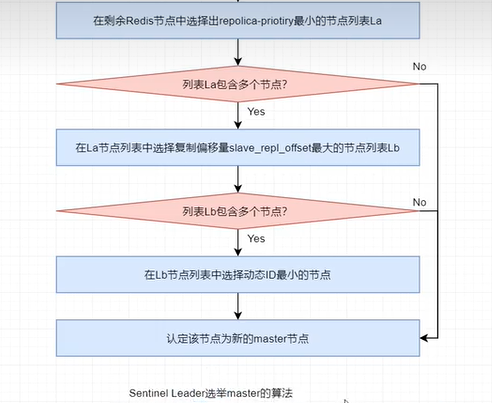
在進行故障轉移時,sentinel leader 需要從所有redis的slave節點中選擇出新的master。其選擇演算法為:
(1)過濾掉所有主觀下線的,或心跳沒有相應sentinel的,或replica-priority值為0的redis節點。
(2)在剩餘redis節點中選擇出replica-priority最小的節點列表。如果只有一個節點,則直接返回,否則,繼續。
(3)從優先順序相同的節點列表中選擇複製偏移量最大的節點。如果只有一個節點,則直接返回,否則,繼續。
(4)從複製偏移量相同的節點列表中選擇動態ID最小的節點返回。
簡單概況如下

3.5 故障轉移過程
sentinel leader 負責整個故障轉移過程,主要步驟如下;
(1)sentinel leader 根據master選擇演算法選擇出一個slave節點作為新的master。
(2)sentinel leader 向新master節點發送slaveof no one 指令,使其晉升為master。
(3)sentinel leader 向新的master發送info replication 指令,獲取到master的動態ID。
(4)sentinel leader 向其餘redis節點發送消息,以告知它們新master的動態ID。
(5)sentinel leader 向其餘redis節點發送slaveof <masterip> <masterport>指令,使它們稱為新master的slave。
(6)sentinel leader 從所有slave節點中每次選擇出parallel-syncs個slave,從新master同步數據,直至所有slave全部同步完畢。
(7)故障轉移完畢。
3.6 節點上線
分3類情況:原redis節點上線;新redis節點上線;sentinel節點上線。
(1)原redis節點上線
無論是原下線的master節點還是原下線的slave節點,只要是原redis集群中的節點上線,只需要啟動redis即可。因為每個sentinel中都保存有原來其監控的所有redis節點列表,sentinel會定時查看這些redis節點是否恢復。如果查看到其已恢復,就會命其從當前master進行數據同步。
不過,如果是原來master上線,在新的master晉升後,sentinel leader會立即將原來master節點更新為slave,然後才會定時查看其是否恢復。
(2)新redis節點上線
如果需要在redis集群中添加一個新的節點,其未曾出現在redis集群中,則上線操作只能手工完成。即添加者在添加之前必須知道當前master是誰,然後在新節點啟動後運行slaveof 命令加入集群。
(3)sentinel 節點上線
如果要添加的是sentinel節點,無論其是否曾經出現在sentinel集群中,都需要手工完成。即添加者在添加之前必須知道當前master是誰,然後在配置文件中修改sentinel monitor 屬性,指定要監控的master。然後啟動sentinel即可。
學習參閱特別聲明
1.《High availability with Redis Sentinel》
https://redis.io/docs/latest/operate/oss_and_stack/management/sentinel/
2.【Redis視頻從入門到高級】
【https://www.bilibili.com/video/BV1U24y1y7jF?p=11&vd_source=0e347fbc6c2b049143afaa5a15abfc1c】

