
MDB (Lightning Memory-Mapped Database) 是一個高性能的嵌入式鍵值存儲資料庫,由Symas Corporation開發,並作為OpenLDAP項目的一部分發佈。LMDB被設計為輕量級、快速且可靠,適合在各種應用環境中使用,從伺服器端應用到移動設備和嵌入式系統。 L ...
目錄
第四講:深入淺出索引(下)
引入
在上一篇文章中,我和你介紹了 InnoDB 索引的數據結構模型,今天我們再繼續聊聊跟 MySQL 索引有關的概念。
拋出問題:
在開始這篇文章之前,我們先來看一下這個問題:在下麵這個表 T 中,如果我執行
select * from T where k between 3 and 5;
需要執行幾次樹的搜索操作,會掃描多少行?
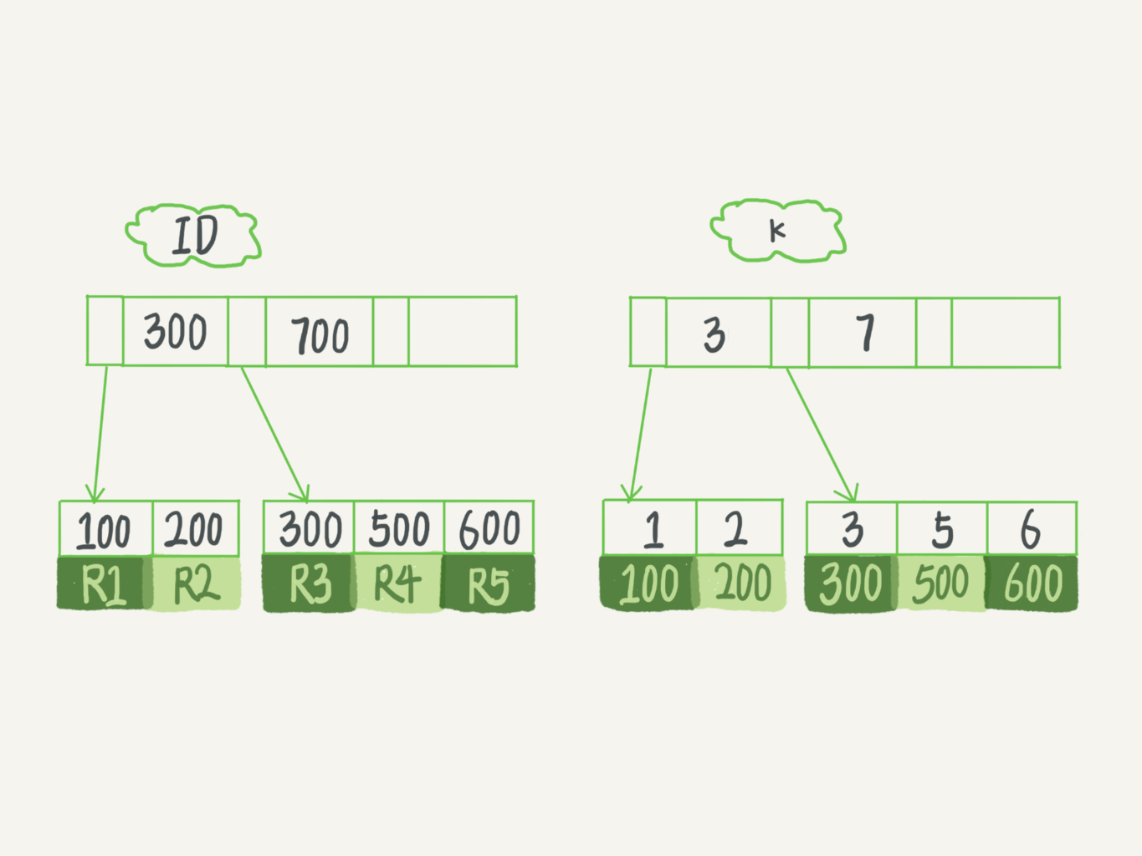
下麵是這個表的初始化語句。
mysql> create table T (
ID int primary key,
k int NOT NULL DEFAULT 0,
s varchar(16) NOT NULL DEFAULT '',
index k(k))
engine=InnoDB;
insert into T values(100,1, 'aa'),(200,2,'bb'),(300,3,'cc'),(500,5,'ee'),(600,6,'ff'),(700,7,'gg');
解決問題:
現在,我們一起來看看這條 SQL 查詢語句的執行流程:
-
在 k 索引樹上找到 k=3 的記錄,取得 ID = 300;
-
再到 ID 索引樹查到 ID=300 對應的 R3;
-
在 k 索引樹取下一個值 k=5,取得 ID=500;
-
再回到 ID 索引樹查到 ID=500 對應的 R4;
-
在 k 索引樹取下一個值 k=6,不滿足條件,迴圈結束。
在這個過程中,回到主鍵索引樹搜索的過程,我們稱為回表。可以看到,這個查詢過程讀了 k 索引樹的 3 條記錄(步驟 1、3 和 5),回表了兩次(步驟 2 和 4)。
在這個例子中,由於查詢結果所需要的數據只在主鍵索引上有,所以不得不回表。那麼,有沒有可能經過索引優化,避免回表過程呢?
覆蓋索引
如果執行的語句是 select ID from T where k between 3 and 5,這時只需要查 ID 的值,而 ID 的值已經在 k 索引樹上了,因此可以直接提供查詢結果,不需要回表。也就是說,在這個查詢裡面,索引 k 已經“覆蓋了”我們的查詢需求,我們稱為覆蓋索引。
由於覆蓋索引可以減少樹的搜索次數,顯著提升查詢性能,所以使用覆蓋索引是一個常用的性能優化手段。
需要註意的是,在引擎內部使用覆蓋索引在索引 k 上其實讀了三個記錄,R3~R5(對應的索引 k 上的記錄項),但是對於 MySQL 的 Server 層來說,它就是找引擎拿到了兩條記錄,因此 MySQL 認為掃描行數是 2。
備註:關於如何查看掃描行數的問題,我將會在第 16 文章《如何正確地顯示隨機消息?》中,和你詳細討論。
引申:
基於上面覆蓋索引的說明,我們來討論一個問題:在一個市民信息表上,是否有必要將身份證號和名字建立聯合索引?
假設這個市民表的定義是這樣的:
CREATE TABLE `tuser` (
`id` int(11) NOT NULL,
`id_card` varchar(32) DEFAULT NULL,
`name` varchar(32) DEFAULT NULL,
`age` int(11) DEFAULT NULL,
`ismale` tinyint(1) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `id_card` (`id_card`),
KEY `name_age` (`name`,`age`)
) ENGINE=InnoDB
我們知道,身份證號是市民的唯一標識。也就是說,如果有根據身份證號查詢市民信息的需求,我們只要在身份證號欄位上建立索引就夠了。而再建立一個(身份證號、姓名)的聯合索引,是不是浪費空間?
如果現在有一個高頻請求,要根據市民的身份證號查詢他的姓名,這個聯合索引就有意義了。它可以在這個高頻請求上用到覆蓋索引,不再需要回表查整行記錄,減少語句的執行時間。
當然,索引欄位的維護總是有代價的。因此,在建立冗餘索引來支持覆蓋索引時就需要權衡考慮了。這正是業務 DBA,或者稱為業務數據架構師的工作。最左首碼原則
最左首碼原則
看到這裡你一定有一個疑問,如果為每一種查詢都設計一個索引,索引是不是太多了。
如果我現在要按照市民的身份證號去查他的家庭地址呢?雖然這個查詢需求在業務中出現的概率不高,但總不能讓它走全表掃描吧?反過來說,單獨為一個不頻繁的請求創建一個(身份證號,地址)的索引又感覺有點浪費。應該怎麼做呢?
(批註:這是在沒有以身份證號為主鍵的情況下所說的“全表掃描”)
這裡,我先和你說結論吧。B+ 樹這種索引結構,可以利用索引的“最左首碼”,來定位記錄。
示例:

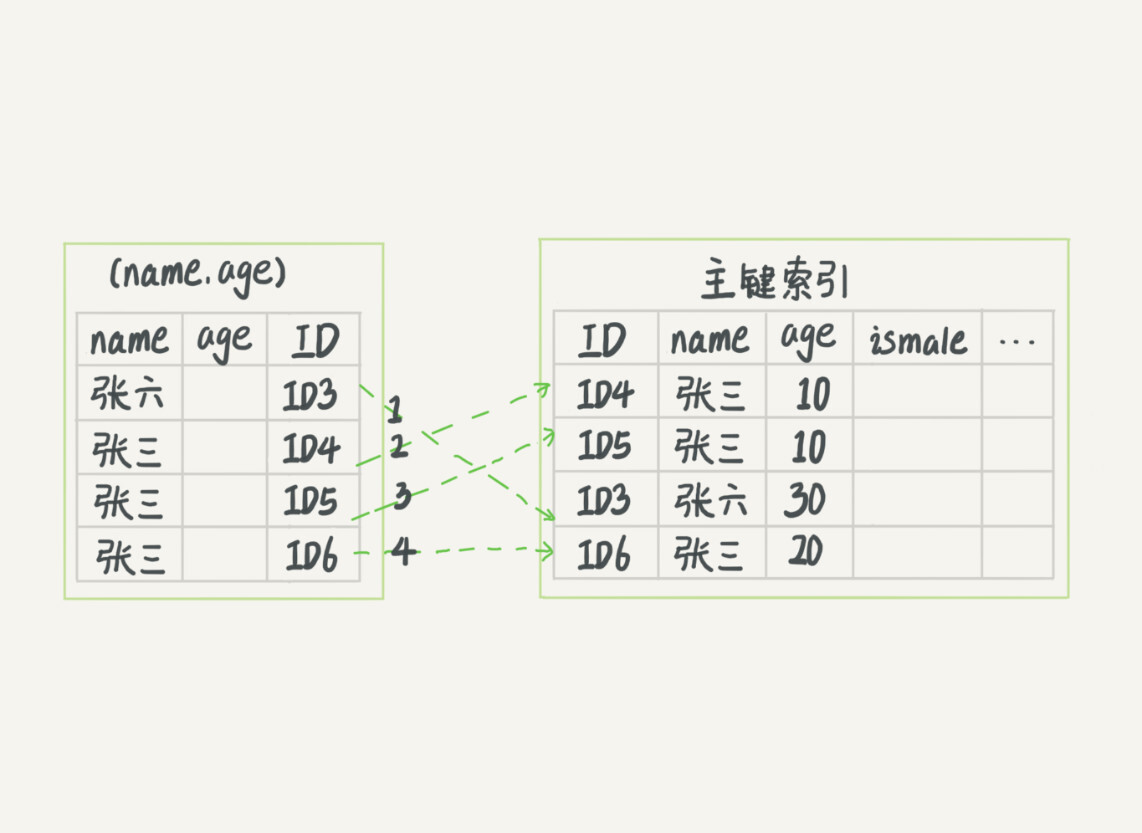
可以看到,索引項是按照索引定義裡面出現的欄位順序排序的。當你的邏輯需求是查到所有名字是“張三”的人時,可以快速定位到 ID4,然後向後遍歷得到所有需要的結果。
如果你要查的是所有名字第一個字是“張”的人,你的 SQL 語句的條件是"where name like ‘張 %’"。這時,你也能夠用上這個索引,查找到第一個符合條件的記錄是 ID3,然後向後遍歷,直到不滿足條件為止。
可以看到,不只是索引的全部定義,只要滿足最左首碼,就可以利用索引來加速檢索。這個最左首碼可以是聯合索引的最左 N 個欄位,也可以是字元串索引的最左 M 個字元。
基於上面對最左首碼索引的說明,我們來討論一個問題:在建立聯合索引的時候,如何安排索引內的欄位順序。
這裡我們的評估標準是,索引的復用能力。因為可以支持最左首碼,所以當已經有了 (a,b) 這個聯合索引後,一般就不需要單獨在 a 上建立索引了。因此,第一原則是,如果通過調整順序,可以少維護一個索引,那麼這個順序往往就是需要優先考慮採用的。
所以現在你知道了,這段開頭的問題里,我們要為高頻請求創建 (身份證號,姓名)這個聯合索引,並用這個索引支持“根據身份證號查詢地址”的需求。
那麼,如果既有聯合查詢,又有基於 a、b 各自的查詢呢?查詢條件裡面只有 b 的語句,是無法使用 (a,b) 這個聯合索引的,這時候你不得不維護另外一個索引,也就是說你需要同時維護 (a,b)、(b) 這兩個索引。
(批註:用不上最左首碼,如果是高頻的查詢,就再建一個單獨的索引,當然我們可以選擇交換順序,爭取建立的索引占用的記憶體越小)
這時候,我們要考慮的原則就是空間了。比如上面這個市民表的情況,name 欄位是比 age 欄位大的 ,那我就建議你創建一個(name,age) 的聯合索引和一個 (age) 的單欄位索引。
索引下推
示例:
上一段我們說到滿足最左首碼原則的時候,最左首碼可以用於在索引中定位記錄。這時,你可能要問,那些不符合最左首碼的部分,會怎麼樣呢?
我們還是以市民表的聯合索引(name, age)為例。如果現在有一個需求:檢索出表中“名字第一個字是張,而且年齡是 10 歲的所有男孩”。那麼,SQL 語句是這麼寫的:
mysql> select * from tuser where name like '張%' and age=10 and ismale=1;
你已經知道了首碼索引規則,所以這個語句在搜索索引樹的時候,只能用 “張”,找到第一個滿足條件的記錄 ID3。當然,這還不錯,總比全表掃描要好。
然後呢?
當然是判斷其他條件是否滿足。
在 MySQL 5.6 之前,只能從 ID3 開始一個個回表。到主鍵索引上找出數據行,再對比欄位值。
而 MySQL 5.6 引入的索引下推優化(index condition pushdown), 可以在索引遍歷過程中,對索引中包含的欄位先做判斷,直接過濾掉不滿足條件的記錄,減少回表次數。
下麵是這兩個過程的執行流程圖。

圖中每一個虛線箭頭表示回表一次。
分析:
第一張圖:在 (name,age) 索引裡面我特意去掉了 age 的值,這個過程 InnoDB 並不會去看 age 的值,只是按順序把“name 第一個字是’張’”的記錄一條條取出來回表。因此,需要回表 4 次
第一張圖跟第二張圖的區別是,InnoDB 在 (name,age) 索引內部就判斷了 age 是否等於 10,對於不等於 10 的記錄,直接判斷並跳過。在我們的這個例子中,只需要對 ID4、ID5 這兩條記錄回表取數據判斷,就只需要回表 2 次。
小結
今天這篇文章,我和你繼續討論了資料庫索引的概念,包括了覆蓋索引、首碼索引、索引下推。你可以看到,在滿足語句需求的情況下, 儘量少地訪問資源是資料庫設計的重要原則之一。我們在使用資料庫的時候,尤其是在設計表結構時,也要以減少資源消耗作為目標。
深入:
1.覆蓋索引的第二個使用:在聯合索引上使用,也可以避免回表。這個也可以應用到項目開發中。
2.數據中身份證 + 姓名占比比較高,一般不會再創建這樣的索引,真有高頻查詢也會使用緩存組件;當然作者這裡只是給大家舉個例子說明覆蓋索引的,明白覆蓋索引就行
3.給id_card 和 name建立聯合索引後,name的值也會被保存在id_card索引樹的節點上,這樣根據給定id_card的值找到的對應行時,就可以直接獲取到name了,而不需要拿著對應的主鍵再進行回表操作。
4.最左首碼原則是幹嘛的呢,很簡單,就是為瞭解決“為一個不頻繁的請求創建一個索引感覺很浪費”的問題的
5.B+ 樹這種索引結構,可以利用索引的“最左首碼”,來定位記錄。
6.最左首碼原則:當查詢條件只有b時,a沒有被用到,導致索引失效
問題:
實際上主鍵索引也是可以使用多個欄位的。DBA 小呂在入職新公司的時候,就發現自己接手維護的庫裡面,有這麼一個表,表結構定義類似這樣的:
CREATE TABLE `geek` (
`a` int(11) NOT NULL,
`b` int(11) NOT NULL,
`c` int(11) NOT NULL,
`d` int(11) NOT NULL,
PRIMARY KEY (`a`,`b`),
KEY `c` (`c`),
KEY `ca` (`c`,`a`),
KEY `cb` (`c`,`b`)
) ENGINE=InnoDB;
公司的同事告訴他說,由於歷史原因,這個表需要 a、b 做聯合主鍵,這個小呂理解了。
但是,學過本章內容的小呂又納悶了,既然主鍵包含了 a、b 這兩個欄位,那意味著單獨在欄位 c 上創建一個索引,就已經包含了三個欄位了呀,為什麼要創建“ca”“cb”這兩個索引?
同事告訴他,是因為他們的業務裡面有這樣的兩種語句
select * from geek where c=N order by a limit 1;
select * from geek where c=N order by b limit 1;
(從geek表中找出c列值等於某個特定值的所有行,然後按照a列的值進行排序,並只返回排序後的第一行數據。)
我給你的問題是,這位同事的解釋對嗎,為了這兩個查詢模式,這兩個索引是否都是必須的?為什麼呢?
答案:
表記錄
–a--|–b--|–c--|–d--
1 2 3 d
1 3 2 d
1 4 3 d
2 1 3 d
2 2 2 d
2 3 4 d
主鍵 a,b 的聚簇索引組織順序相當於 order by a,b ,也就是先按 a 排序,再按 b 排序,c 無序。(標記1)
索引 ca 的組織是先按 c 排序,再按 a 排序,同時記錄主鍵
–c--|–a--|–主鍵部分b-- (註意,這裡不是 ab,而是只有 b)
2 1 3
2 2 2
3 1 2
3 1 4
3 2 1
4 2 3
這個跟索引 c 的數據是一模一樣的。
索引 cb 的組織是先按 c 排序,在按 b 排序,同時記錄主鍵
–c--|–b--|–主鍵部分a-- (同上)
2 2 2
2 3 1
3 1 2
3 2 1
3 4 1
4 3 2
所以,結論是 ca 可以去掉,cb 需要保留。
深入分析上題:
1.索引“cb”有必要,“ca”沒必要,因為索引“c”會包含主鍵值,where c=x order by a,因為c是固定值,所以 a 值是順序的,可以避免排序。但是 where c=x order by b,因為a 值不固定,所以 b 值不是按順序的(在標記一提到),單純靠索引“c”無法避免排序,所以需要 “cb”索引。
2.InnoDB會把主鍵欄位放到索引定義欄位後面, 當然同時也會去重。 所以,當主鍵是(a,b)的時候, 定義為c的索引,實際上是(c,a,b); 定義為(c,a)的索引,實際上是(c,a,b) 你看著加是相同的 ps 定義為(c,b)的索引,實際上是(c,b,a)
3.解析: c欄位上創建了索引,所以最終的業主節點值為(c,a,b),也就是索引節點+主鍵; ca上創建了索引,由於a是主鍵的一部分,所以葉子節點不會再重覆添加a (c,a,a,b),而是(c,a,b),那麼這顆索引樹和1中的重覆了,所以可以去掉; cb上創建索引,葉子節點為(c,b,a)
標記一處:如果a一樣的情況下,才會根據b去排序

