
問題 MGR 中,新節點在加入時,為了與組內其它節點的數據保持一致,它會首先經歷一個分散式恢復階段。在這個階段,新節點會隨機選擇組內一個節點(Donor)來同步差異數據。 在 MySQL 8.0.17 之前,同步的方式只有一種,即基於 Binlog 的非同步複製,這種方式適用於差異數據較少或需要的 B ...
1 B*TREE索引
1.1 什麼是B*TREE索引
B*TREE索引是oracle資料庫中最常見的索引。可以根據索引鍵值快速定位到表裡的某一行數據或者根據索引鍵範圍定位多行數據。
1.2 B*TREE索引結構
B*TREE索引的構造類似於二叉樹,最底層的塊稱作葉塊,葉塊由索引鍵以及rowid組成。葉塊之上的塊稱為分支塊,檢索數據時就是通過分支塊到達葉塊的。
例如,我們想在索引中找到值42,就要從樹頂開始,找到左分支的一個塊(分支塊)。 然後我們在這個分支塊當中,發現需要繼續去找範圍為“42...50”的(葉)塊,而這個葉塊就會帶領我們找到表中值為42的那一行或幾行數據。
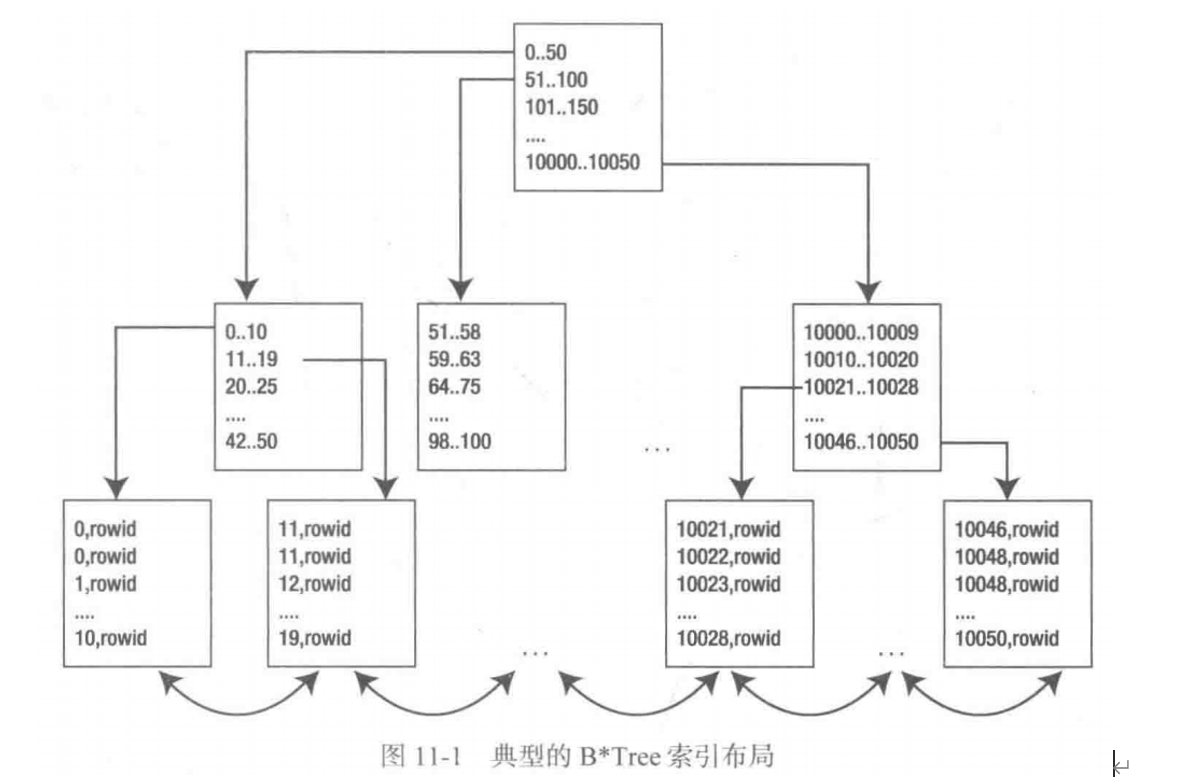
葉塊這一層是一個雙向鏈結構,這意味著範圍搜索時,不需要從樹根重新掃描,只需要向左或向右進行掃描。
1.3 B*TREE索引的唯一性和高度
BTREE索引的索引條目都是唯一的。如果索引鍵存儲重覆值,就會追加rowid到索引鍵後面,使索引條目唯一。在唯一性的索引中,資料庫不會追加rowid到索引鍵上。
索引的高度是指從根塊到葉塊所需遍歷的塊。大多數BTREE索引的高度都是2或者3,即使幾百萬行的索引也是如此。這意味只需要2到3次I/O,我們就能找對應的葉塊。
1.4 什麼情況下應該使用B*TREE索引
- 訪問表裡一小部分數據,就用BTREE索引。這一小部分數據的行數占總表的行數不應該超過20%。例如訪問一個學生表學號為1的數據,學生表有10萬條數據。學號為1的這一條數據就占很小的比例。所以,我們應該在學號這個欄位上建BTREE索引。
為什麼不應該在訪問占表大比例的數據上建B*TREE索引。例如表裡有1000條數據以及100個塊。如果我們要訪問表裡的200條數據,通過索引,我們就要掃描200次塊。但是我們不使用索引,使用全表掃描的方式,才掃描100次塊,比通過索引查找數據更高效。 - 要訪問大量數據時,不需要訪問表,可以直接通過索引就能得到時,就使用B*TREE索引。例如一個學生表的主鍵是學號(主鍵會自動建索引),我們需要統計學生表的學號的數量
select count(學號) from 學生表;
這時,資料庫不會去掃描表裡的數據統計數量,而是直接掃描學號的索引統計數據量。
2 點陣圖索引
B*TREE索引的索引條目和表裡的行是一對一的關係。但是點陣圖索引一個索引條目會指向表裡的多行數據。點陣圖索引適合在表裡高度重覆的列建立。高度重覆指相對於表裡的總行數而言,索引欄位只有少數幾個不同的值。例如一個學生表,有10萬數據,欄位性別隻有男女兩個不同的值,性別欄位就適合建點陣圖索引。
點陣圖索引適合建立在只讀的數據中。在OLTP資料庫中建立點陣圖索引會導致以下併發問題。因為點陣圖索引一個索引條目指向表裡多行數據,如果修改索引列的數據,這個索引條目指向的多行數據會同時被鎖定。
3 基於函數的索引
3.1 什麼是基於函數的索引
我們可以使用基於函數的索引,對錶里某些列的計算結果進行索引,這樣查詢時可以直接使用函數索引的結構。例如我們對學生表的學生名稱建立了轉換為大寫的索引。
create index stu_upper_idx on student(upper(sname));
當我們查詢select * from student where upper(sname)='JACK'時,資料庫就無需將sname轉換為大寫,再對數據進行搜索,而是直接使用stu_upper_idx索引的數據進行搜索。再根據索引存儲的ROWID找到對應的行數據。
3.2 只對部分行進行索引
對應B*TREE索引而言,對於索引列全為null的行是不會建立索引條目的。例如有如下索引
Create index I on t(a,b);
如果一行數據的a,b都是null,那索引I中就不會有這一行的索引條目。我們可以基於這個原理,對部分行進行索引。例如學生表有欄位是否退學(is_dropout)。我們需要查詢已退學的學生,我們就可以建如下索引
Create index id_drop on student(case when is_dropout='是' then '是' end);
那id_drop這個索引,只會建立is_dropout='是'的索引,不會建立is_dropout為其他值的索引。
3.3 實現有選擇的唯一性
我們有這麼一個需求,學生表中欄位是否退學(is_dropout),如果為'否',則學生姓名(s_name)不允許重覆。則我們可以建如下唯一性索引
Create unique index id_student_name On student ( case when is_dropout= '否' then s_name end );
4 索引常見的問題
4.1 可以在null建立索引嗎?
BTREE索引不會存儲索引鍵都是null的索引條目。而點陣圖和聚簇索引則會存儲。如果的確有'select * from t where name is null'這樣查詢某個欄位不為空的需求,而且null值的數量占表總數量很低,則可以使用索引鍵上追加一個常量,給索引鍵的null值建立bTREE索引。
CREATE INDEX id_name ON t (name, '1');
- 為什麼重要欄位不建議使用null
[1] B*TREE索引不存儲索引鍵都是null值數據,影響查詢效率。
[2] 不對null值處理後再參加聚合函數計算,容易造成聚合函數的統計產生錯誤的結果。
例如統計數據,要先加1再合計。寫sum(length+1),有條數據時空,則統計結果會少1。因為null+1還是null。應該寫成sum(nvl(length,0)+1)
[3] 不對null值處理後再參加NOT IN查詢,則會讓查詢查不出結果。
例如查詢 where id not in(select id2 from student),如果id2有空值,則不會查出任何數據
4.2 為什麼優化器沒有使用建立的索引
- 索引建立在訪問表裡大部分數據的欄位上。例如,'select * from student where sex='男''。男性別數量占表裡數量一半左右。即使在sex建立索引,資料庫優化器判斷通過索引搜索數據的效率還不如全表掃描,資料庫就會直接通過全表掃描搜索數據。
- 類似於'SELECT COUNT(1) FROM T'的查詢。表T存在索引,但是索引列存在空值。因為索引鍵全為空的數據不會建B*TREE索引條目,使用索引統計會導致統計錯誤。所以資料庫不會使用索引統計數據量,而是選擇全表掃描。要讓統計全表數據量使用索引,可以在建立not null約束的欄位上建立索引。
- 表上的統計信息並不是最新的。所以可以嘗試收集一下表上的統計信息,再次查詢數據。
- 索引處於不可用狀態。查詢索引狀態,如果是'UNUSABLE',則需要重建索引。

- 謂詞沒有使用索引的最前列。例如查詢 'SELECT * FROM T where y=1'。但是是在T(X,Y)上建立的索引。那優化器就很可能不會用到索引,因為謂詞中沒有用到X列。
- 使用函數對索引列進行了轉化。例如查詢 'SELECT * FROM T where upper(y)='A''。即使在y列建立索引,也不會使用到索引。應該建立基於upper(y)函數的索引。
- 查詢值類型和欄位類型不一致。例如 'SELECT * FROM T where a=1'。a欄位時varchar2類型,查詢的值是數字。這樣也使用不到索引。


