
在之前的實時湖倉系列文章中,我們已經介紹了實時湖倉對於當前企業數字化轉型的重要性,實時湖倉的功能架構設計,以及實時計算和數據湖結合的應用場景。 在本篇文章中,將介紹袋鼠雲數棧在構建實時湖倉系統上的探索與落地實踐,及未來規劃。 數棧為什麼選擇實時湖倉 數棧作為一個數據開發平臺,在未引入實時湖倉之前提供 ...
在之前的實時湖倉系列文章中,我們已經介紹了實時湖倉對於當前企業數字化轉型的重要性,實時湖倉的功能架構設計,以及實時計算和數據湖結合的應用場景。
在本篇文章中,將介紹袋鼠雲數棧在構建實時湖倉系統上的探索與落地實踐,及未來規劃。
數棧為什麼選擇實時湖倉
數棧作為一個數據開發平臺,在未引入實時湖倉之前提供的是基於 Lambda 架構的開發模式,分了實時和離線兩條鏈路,這種開發模式帶來的問題在於:
· 複雜性高,需要維護流批雙鏈路的不同組件
· 存儲成本高,流批兩個鏈路維護兩份相同的數據
· 實時鏈路不可查,Kafka 中間數據查詢困難,不支持隨機查詢,只支持順序查詢
· 數據口徑一致性差,不同計算引擎難保證統一的數據口徑
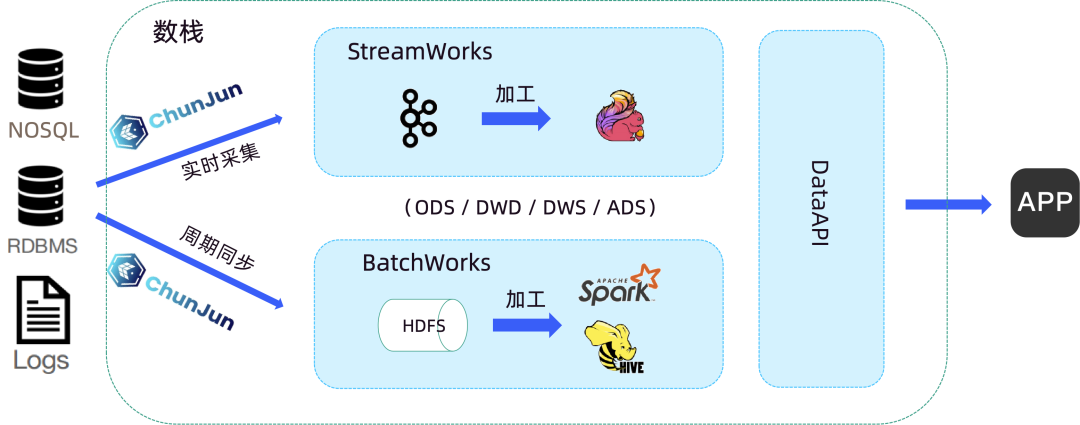
而實時湖倉則能夠節省存儲成本,極大地提升開發效率,並更快更好地挖掘數據價值。
· 提供了多樣化的分析能力,不限於批處理、流處理,在互動式查詢和機器學習方面都很友好
· 提供了 ACID 事物能力,可以更好的保障數據質量,並提供增刪改查等功能,傳統數倉則缺乏這一能力
· 提供了完善的數據管理能力,包括數據格式、數據 Schema 等
· 提供了存儲介質可擴展的能力,支持 HDFS、對象存儲、雲上存儲等
數棧基於實時湖倉的實踐
下圖便是基於實時湖倉的數棧解決方案結構圖:
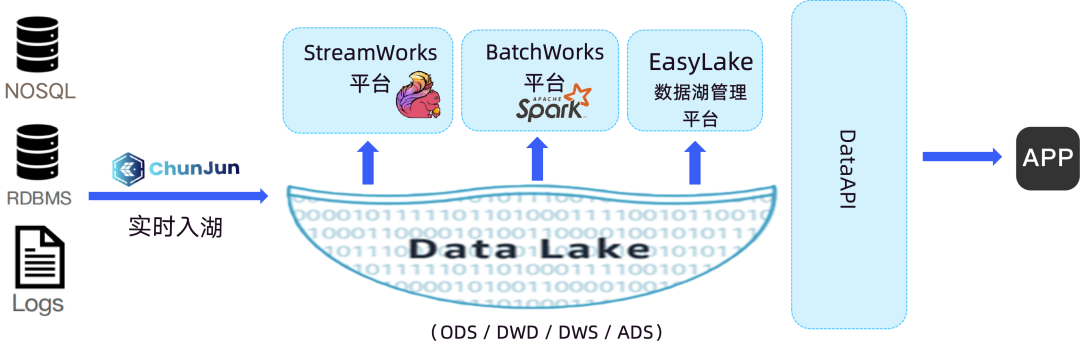
業務庫中的數據我們通過自研的數據集成框架 ChunJun 進行實時採集和入湖,目前支持 Iceberg/Hudi 實時入湖。之後在數棧實時開發平臺和離線開發平臺中進行業務的開發,Flink 和 Spark 支持對接 Iceberg/Hudi,以及 Iceberg/Hudi source 指標展示。再通過 EasyLake 湖倉一體平臺進行數據管理,如一鍵轉表、湖表治理等。
基於此,實時湖倉很好地解決了上文提到的 Lambda 架構開發模式帶來的痛點問題。實現了存儲層和計算層的流批一體,實時鏈路中間數據可查,統一的數據口徑,低成本存儲,為企業帶來更快、更靈活、更高效的數據處理體驗,這就是數棧原則實時湖倉的原因。
下文將為大家重點帶來實時入湖以及物化視圖的介紹。
CDC 實時入湖
Flink CDC 是基於資料庫日誌的 CDC 技術,實現了全增量一體化讀取的數據集成框架。配合 Flink 優秀的管道能力和豐富的上下游生態,Flink CDC 可以高效實現海量數據的實時集成。不過 CDC 數據實時入湖也面臨著不小的挑戰:
· 實時性高:CDC 數據對實時性要求高,數據新鮮度越高,往往業務價值越高
· 歷史數據量大:資料庫的歷史數據規模大
· 強一致性:數據處理必須要保證有序性而且結果需要一致性
· Schema 動態演進:資料庫對應的 Schema 會隨著業務不斷變更
那麼,數棧是怎麼做的呢?
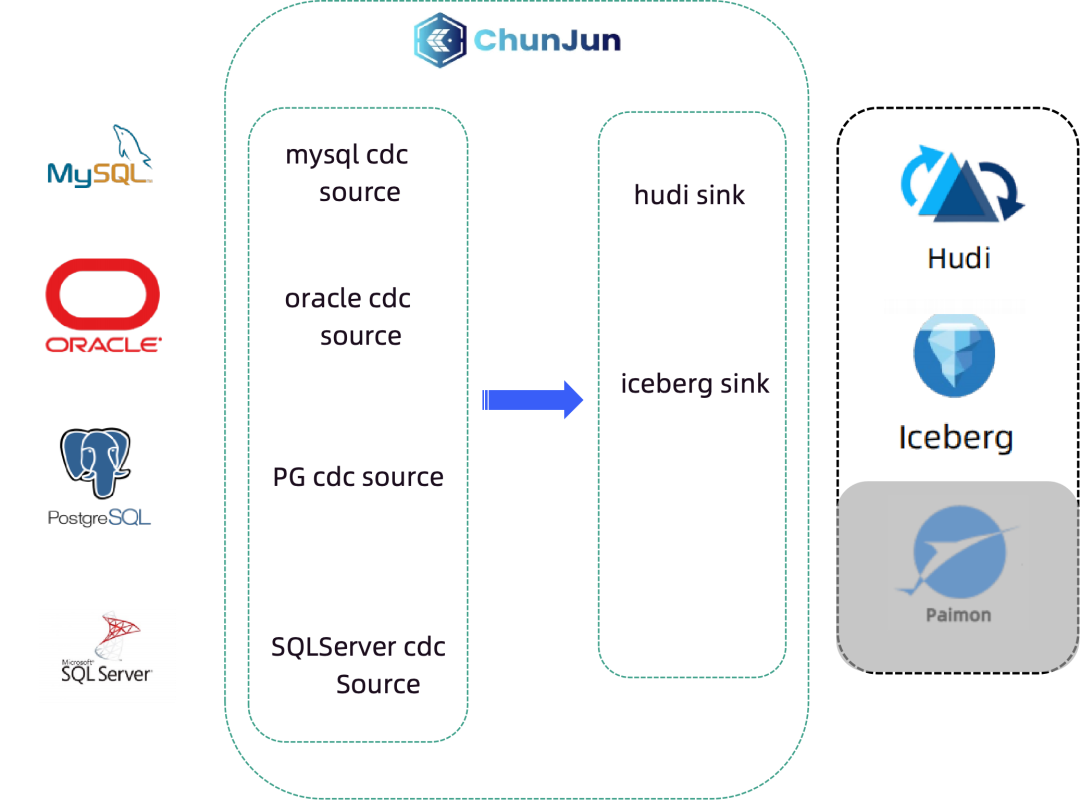
袋鼠雲自研的數據集成框架 ChunJun 支持 CDC 數據的採集,包括 MySQL CDC、Oracle CDC、PG CDC、SQLServer CDC。CDC 數據採集完之後,寫到 Iceberg/Hudi Sink 中,完成實時入湖的工作。
這樣下來的整條鏈路和架構都是袋鼠雲自主研發、完全可控的,並且實現了全增量一體化、分鐘級時延,對業務穩定性也不會造成任何影響。
ChunJun:https://github.com/DTStack/chunjun.git
實時入湖落地中的問題
在實時入湖落地的過程中,我們當然也遇到過問題和挑戰:
· 小文件問題:小文件影響讀寫效率,導致 HDFS 集群穩定性變差
· Hudi 適配 Flink1.12:客戶群體使用的 Flink 版本大多還停留在1.12
· 跨集群入湖:多套 Hadoop 集群的場景下存在跨集群的需求
數棧又是如何個個突破這些問題的呢?
● 小文件問題優化
· 合理設置 Checkpoint Interval
整個 Compaction 過程是一個 I/O 比較多的操作過程,假設一味的調小 Checkpoint Interval,會產生諸如小文件問題、導致 HDFS 壓力變大、checkpoint 失敗、任務不穩定等一系列問題。
在經過多方實踐驗證後,推薦將 Checkpoint Interval 設置為 1-5 分鐘為優。
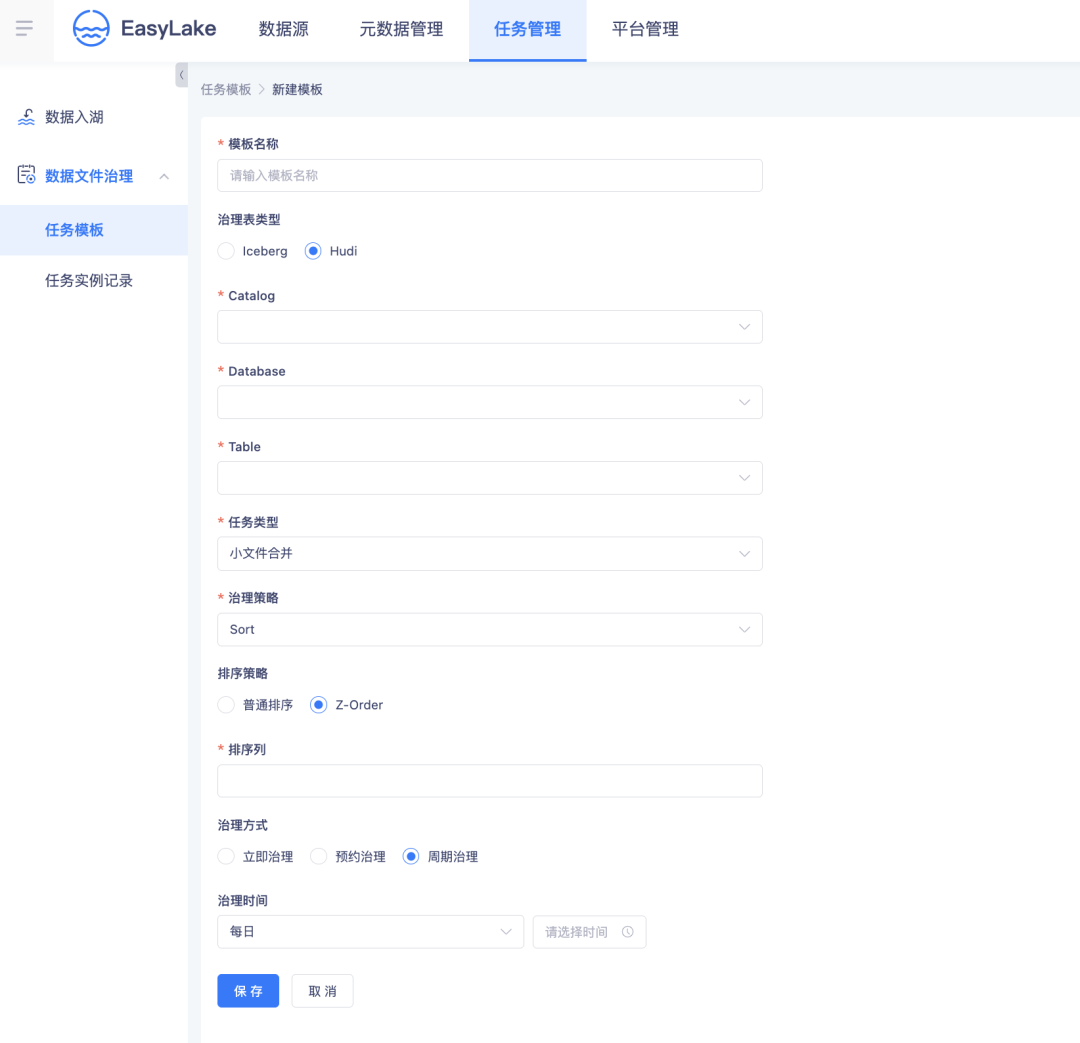
· 平臺化小文件治理
調整 Checkpoint,能夠緩解小文件的產生,之後還要進行平臺化的小文件治理,從根本上解決問題。
EasyLake 湖表治理功能支持數據文件治理,支持快照文件治理,支持 Hudi MOR 增量文件合併,將小文件數量控制在一定的範圍內,提升治理效率。
● Hudi 適配 Flink 1.12 版本做法
數棧在這方面並不是一張白紙,首先我們基於 hudi-flink1.13.x 模塊開發 hudi-flink1.12,將 Flink 版本修改成1.12.7,再針對不相容的點逐個進行修複,最後進行完整的功能測試即完成了適配的工作。
· 跨集群入湖方案
Hudi 和 Iceberg Sink 預設從 HADOOP_CONF_DIR 環境變數獲取 core-site.xml 和 hdfs-site.xml 訪問對應的 HDFS。
數棧基於自研的 ChunJun,在 ChunJun iceberg-connector 和 hudi-connector 中對 hadoop conf dir 的獲取方式進行擴展,支持通過指定 hadoopConfig 自定義參數的方式。
如此便能夠使集群之間的數據流動起來,打破數據孤島,完成跨集群入湖的支持。

ETL 加速探索-物化視圖
在介紹數棧在物化視圖方面的探索之前,必須先理清楚我們為什麼需要物化視圖?
在實時湖倉中包含三類任務,實時 ETL、離線 ETL 和 OLAP,以上三類任務在 ODS -> ADS 的加工過程中,都會出現聚合操作越來越多,IO 越來越密集,多個任務 SQL 中具有相同邏輯的 SQL 片段等現象。
物化視圖可以將表連接或者聚合等耗時較多的結果進行預計算並將計算結果保存下來,在對複雜 SQL 進行查詢的時候,直接基於上一步預計算的結果進行計算,從而避免耗時的操作,更快的得到結果。
而在實時湖倉中基於數據湖構建的物化視圖可實現流、批和 OLAP 任務之間的共用,從而進一步降低實時數據湖中數據在整條鏈路中的延時。為實時加工鏈路加速,並節省計算成本,提高查詢性能和響應速度。
● 實時湖倉中落地物化視圖需要完成的內容
· 平臺化數據湖物化視圖管理
· Spark 支持基於數據湖表格式管理物化視圖
· Trino 支持基於數據湖表格式管理物化視圖
· Flink 支持基於數據湖表格式管理物化視圖
目前數棧實時湖倉已經完成了 Spark 和 Trino 的部分,之後也會將這四部分內容都完成落地,充分發揮物化視圖的作用。
● 物化視圖實現原理
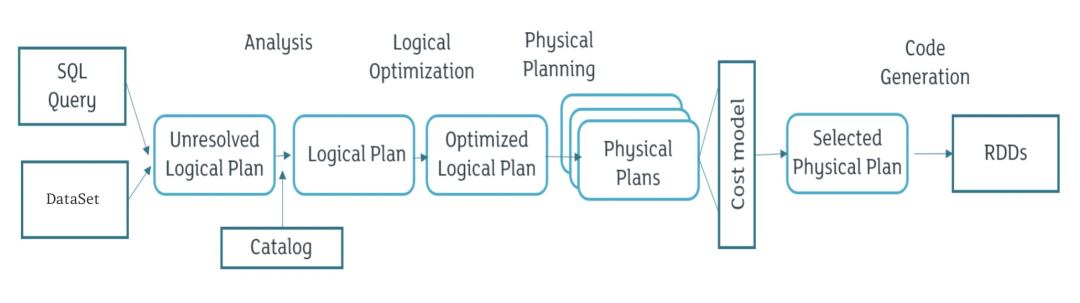
· 創建物化視圖語法
CREATE MATERIALIZED VIEW (IF NOT EXISTS)? multipartIdentifier
('(' colTypeList ')')? tableProvider?
((OPTIONS options=tablePropertyList) |
(PARTITIONED BY partitioning=partitionFieldList) |
skewSpec |
bucketSpec |
rowFormat |
createFileFormat |
locationSpec |
commentSpec |
(TBLPROPERTIES tableProps=tablePropertyList))*
AS query
· 示例
CREATE MATERIALIZED VIEW mv
AS SELECT
a.id,
a.name
FROM jinyu_base a
JOIN jinyu_base_partition b
ON a.id = b.id;
未來規劃
袋鼠雲基於實時湖倉的實踐之路遠不止於此,未來還將進行更多、更深層次的探索,為企業提供更高效、更靈活、更智能的數據處理解決方案。
· 易用性:增加平臺湖表管理的易用性
· 引入 Paimon:平臺支持對接 Paimon、增加基於 Paimon 的湖倉一體建設
· 提升入湖性能:深入並增強內核,提升入湖的的性能
· 安全性探索:實時湖倉提供數據共用、支持多引擎,探索實時湖倉的安全管理方案
本文根據《實時湖倉實踐五講第三期》直播內容總結而來,感興趣的朋友們可點擊鏈接觀看直播回放視頻及免費獲取直播課件。
直播課件:
https://www.dtstack.com/resources/1054?src=szsm
直播視頻:
https://www.bilibili.com/video/BV1Ee411d7Py/?spm_id_from=333.999.0.0&
《數棧產品白皮書》:https://www.dtstack.com/resources/1004?src=szsm
《數據治理行業實踐白皮書》下載地址:https://www.dtstack.com/resources/1001?src=szsm
想瞭解或咨詢更多有關袋鼠雲大數據產品、行業解決方案、客戶案例的朋友,瀏覽袋鼠雲官網:https://www.dtstack.com/?src=szbky
同時,歡迎對大數據開源項目有興趣的同學加入「袋鼠雲開源框架釘釘技術qun」,交流最新開源技術信息,qun號碼:30537511,項目地址:https://github.com/DTStack


