
常用的包 import torch import torchvision from torch import nn from torch.utils.data import DataLoader from torch.nn import Conv2d, MaxPool2d, Flatten, Lin ...
常用的包
import torch
import torchvision
from torch import nn
from torch.utils.data import DataLoader
from torch.nn import Conv2d, MaxPool2d, Flatten, Linear, Sequential
from torch.utils.tensorboard import SummaryWriter
Pytorch
pytorch安裝
準備環境
- 安裝Ancona工具
- 安裝python語言
- 安裝pycharm工具
以上工作安裝完成後,開始真正的pytorch安裝之旅,別擔心,很容易
1.打開Ancona Prompt創建一個pytorch新環境
conda create -n pytorch python=版本號比如3.11
後面步驟都是y同意安裝
2.激活環境
同樣在Ancona Prompt中繼續輸入如下指令
conda activate pytorch

3.去pytorch官網找到下載pytorch指令,根據個人配置進行選擇
- window下一般選擇Conda
- Linux下一般選擇Pip

這裡要區分自己電腦是否含有獨立顯卡,沒有的選擇cpu模式就行。
如果有獨立顯卡,那麼去NVIDIA官網查看自己適合什麼版本型號進行選擇即可。
如果有獨立顯卡,在Ancona Prompt中輸入如下指令,返回True即可確認安裝成功。

torch.cuda.is_available()
如果沒有cpu我們通過pycharm來進行判斷,首先創建一個pytorch工程,如下所示:

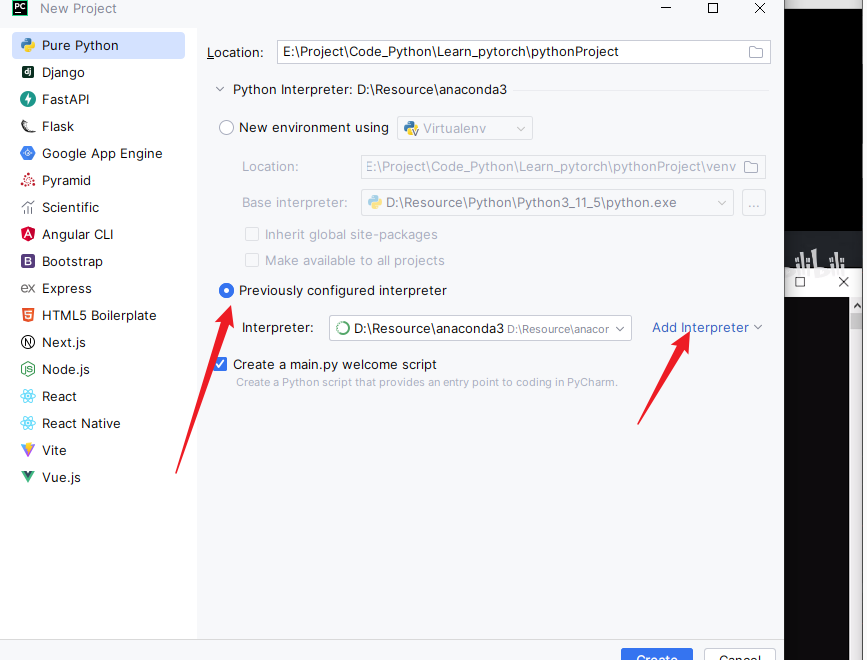



import torch
print(torch.cuda.is_available())
print(torch.backends.cudnn.is_available())
print(torch.cuda_version)
print(torch.backends.cudnn.version())
print(torch.__version__)
是不是發現輸出false, false, None, None,是不是以為錯了。不,那是因為我們安裝的是CPU版本的,壓根就沒得cuda,cudnn這個東西。我們只要檢測python版本的torch(PyTorch)在就行。
ok!恭喜你成功完成安裝pytroch!接下來開啟你的學習之路吧!
引言:python中的兩大法寶函數
- 這裡1、2、3、4是分隔區


# 查看torch裡面有什麼
for i in range(len(dir(torch))):
print(f"{dir(torch)[i]}")
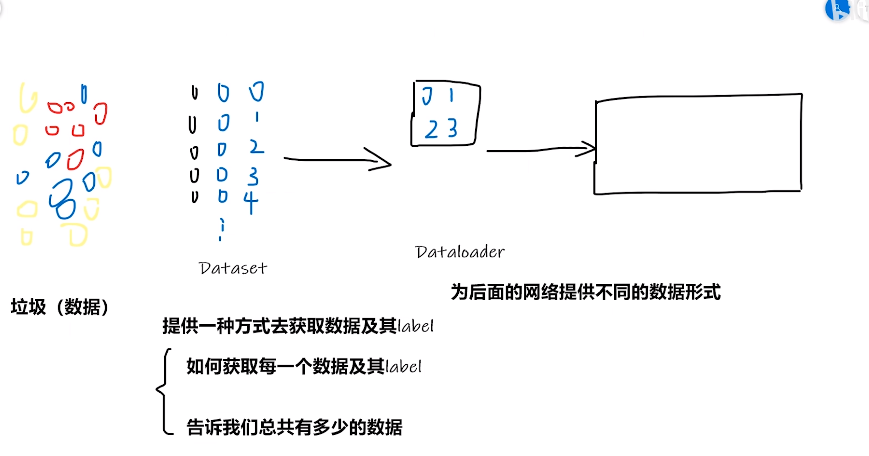
pytorch載入數據初認識
import import torch
from torch.utils.data import Dataset
- 看看Dataset裡面有什麼:

Dataset代碼實戰
from torch.utils.data import Dataset
from PIL import Image
import os
class MyData(Dataset):
def __init__(self, root_dir, label_dir):
self.root_dir = root_dir
self.label_dir = label_dir
self.path = os.path.join(self.root_dir, self.label_dir) # 根路徑和最後的路徑進行拼接
self.img_path = os.listdir(self.path) # 路徑地址img_path[0] 就是第一張地址
def __getitem__(self, idx):
"""
讀取每個照片
:param idx:
:return:
"""
img_name = self.img_path[idx]
img_item_path = os.path.join(self.root_dir, self.label_dir, img_name)
img = Image.open(img_item_path)
label = self.label_dir
return img, label
def __len__(self):
"""
查看圖片個數,即數據集個數
:return:
"""
return len(self.img_path)
# img_path = "E:\\Project\\Code_Python\\Learn_pytorch\\learn_pytorch\\dataset\\training_set\\cats\\cat.1.jpg"
# img = Image.open(img_path)
# print(img)
# img.show()
root_dir = "dataset/training_set"
cats_label_dir = "cats"
dogs_label_dir = "dogs"
cats_dataset = MyData(root_dir, cats_label_dir)
dogs_dataset = MyData(root_dir, dogs_label_dir)
img1, label1 = cats_dataset[1]
img2, label2 = dogs_dataset[1]
# img1.show()
# img2.show()
train_dataset = cats_dataset + dogs_dataset # 合併數據集
print(len(train_dataset))
print(len(cats_dataset))
print(len(dogs_dataset))
TensorBoard的使用(一)


from torch.utils.tensorboard import SummaryWriter
writer = SummaryWriter("logs") # 事件文件存儲地址
# writer.add_image()
# y = x
for i in range(100):
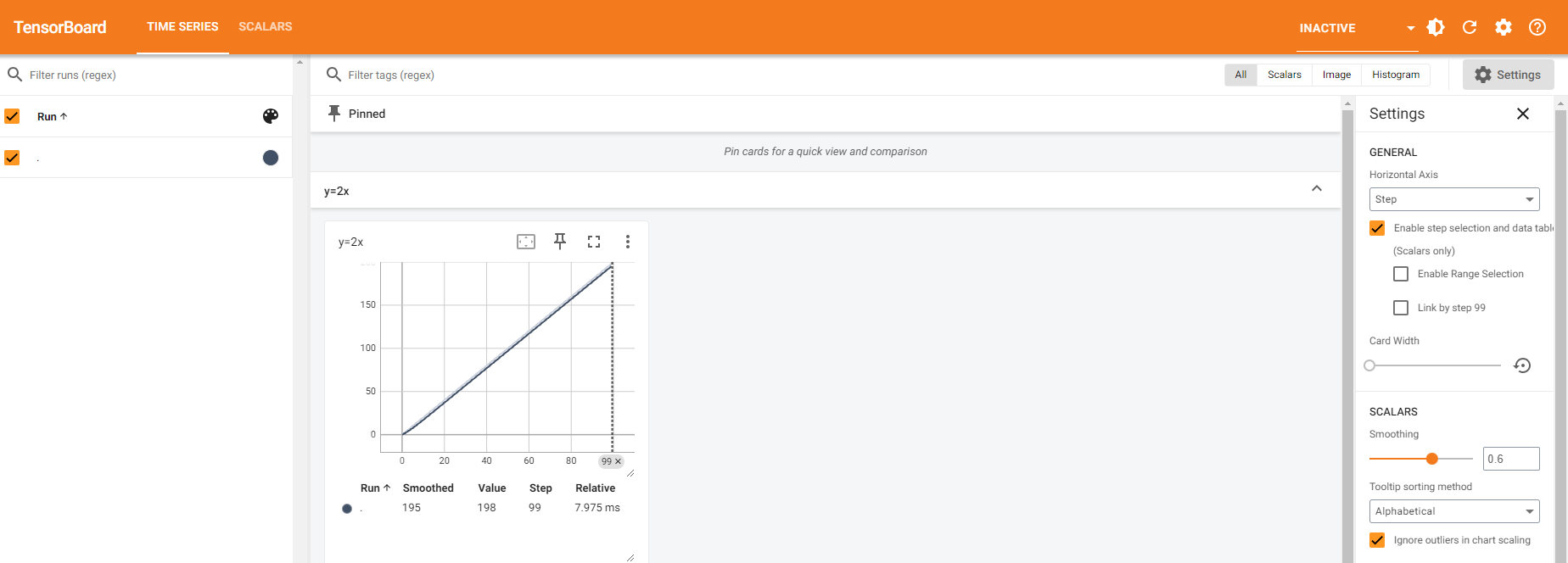
writer.add_scalar("y=2x", 2*i, i) # 標量的意思 參數2*i 是x軸 i是y軸
writer.close()
- 安裝tensorboard
pip install tensorboard
- 運行tensorboard
tensorboard --logdir="logs" --port=6007(這裡是指定埠號,也可以不寫--port,預設6006)
-
利用Opencv讀取圖片,獲得numpy型圖片數據
-
import numpy as np from torch.utils.tensorboard import SummaryWriter import cv2 writer = SummaryWriter("logs") # 事件文件存儲地址 img_array = cv2.imread("./dataset/training_set/cats/cat.2.jpg") # print(img_array.shape) writer.add_image("test",img_array,2,dataformats='HWC') # y = x for i in range(100): writer.add_scalar("y=2x", 2 * i, i) # 標量的意思 writer.close()

Transforms使用
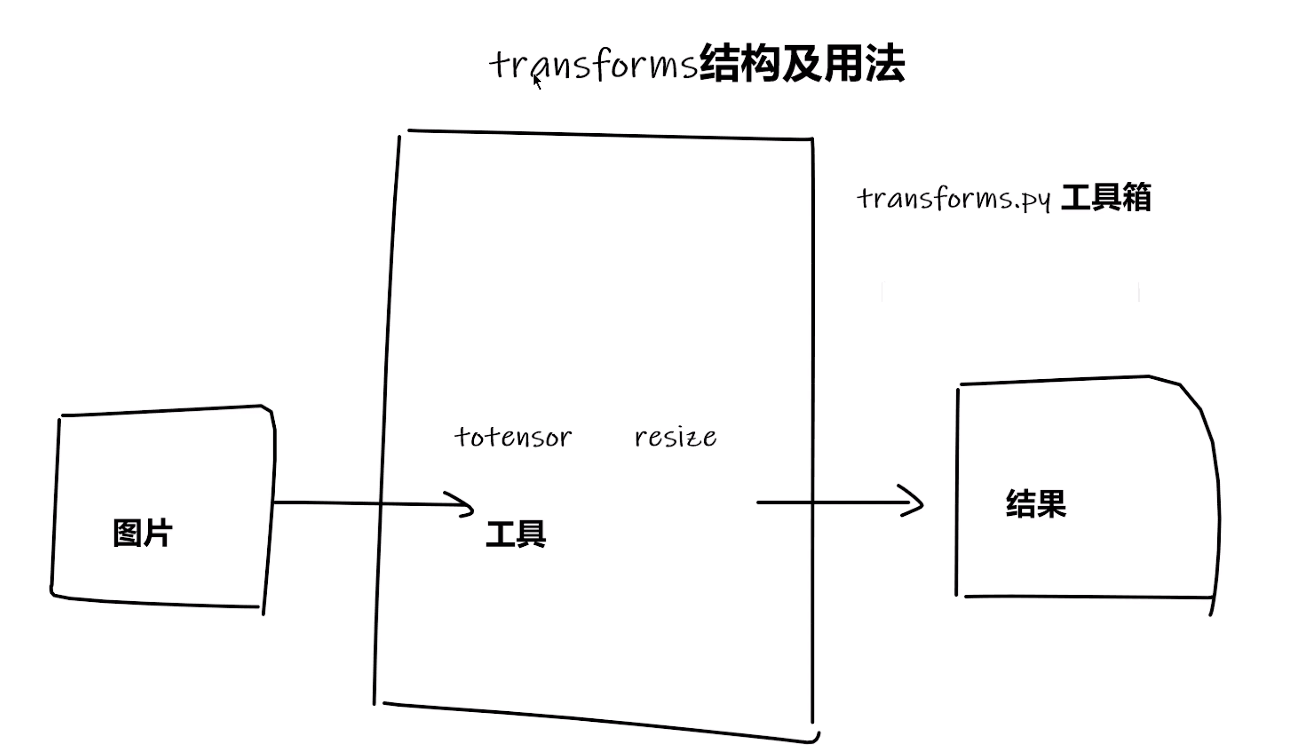
from torchvision import transforms
from PIL import Image
# python當中的用法
# tensor數據類型
# 通過transforms.ToTensor去解決兩個問題
# 1.transforms如何使用(pyhton)
# 2.為什麼需要Tensor數據類型:因為裡面包裝了神經網路模型訓練的數據類型
# 絕對路徑 E:\Project\Code_Python\Learn_pytorch\learn_pytorch\dataset\training_set\cats\cat.6.jpg
# 相對路徑 dataset/training_set/cats/cat.6.jpg
img_path = "dataset/training_set/cats/cat.6.jpg"
img = Image.open(img_path)
# 1.transforms如何使用(pyhton)
tensor_trans = transforms.ToTensor()
tensor_img = tensor_trans(img)
print(tensor_img.shape)

常見的Transforms

from PIL import Image
from torchvision import transforms
from torch.utils.tensorboard import SummaryWriter
writer = SummaryWriter("logs")
img = Image.open("dataset/training_set/cats/cat.11.jpg")
print(img)
# ToTensor的使用
trans_totensor = transforms.ToTensor()
img_tensor = trans_totensor(img)
writer.add_image("ToTensor", img_tensor)
# Normalize
print(img_tensor[0][0][0])
trans_norm = transforms.Normalize([1, 1, 1], [1, 1, 1])
img_norm = trans_norm(img_tensor)
print(img_norm[0][0][0])
writer.add_image("Normalize", img_norm, 0)
# Resize
print(img.size)
trans_resize = transforms.Resize((512, 512))
# img PIL -> resize -> img_resize PIL
img_resize = trans_resize(img)
# img_resize PIL -> totensor -> img_resize tensor
img_resize = trans_totensor(img_resize)
# print(img_resize)
writer.add_image("Resize", img_resize, 1)
# Compose - resize - 2
trans_resize_2 = transforms.Resize(144)
# PIL -> PIL -> tensor數據類型
trans_compose = transforms.Compose([trans_resize_2, trans_totensor])
img_resize_2 = trans_compose(img)
writer.add_image("Resize_Compose", img_resize_2, 2)
writer.close()
torchvision中的數據集使用
import torchvision
from torch.utils.tensorboard import SummaryWriter
dataset_transforms = torchvision.transforms.Compose([
torchvision.transforms.ToTensor()
])
# 下載數據集
train_set = torchvision.datasets.CIFAR10(root="./dataset", train=True, transform=dataset_transforms, download=True)
test_set = torchvision.datasets.CIFAR10(root="./dataset", train=False, transform=dataset_transforms, download=True)
print(test_set[0])
print(test_set.classes)
img, target = test_set[0]
print(img)
print(target)
print(test_set.classes[target])
# img.show()
writer = SummaryWriter("p10")
for i in range(10):
img, target = test_set[i]
writer.add_image("test_set", img, i)
writer.close()

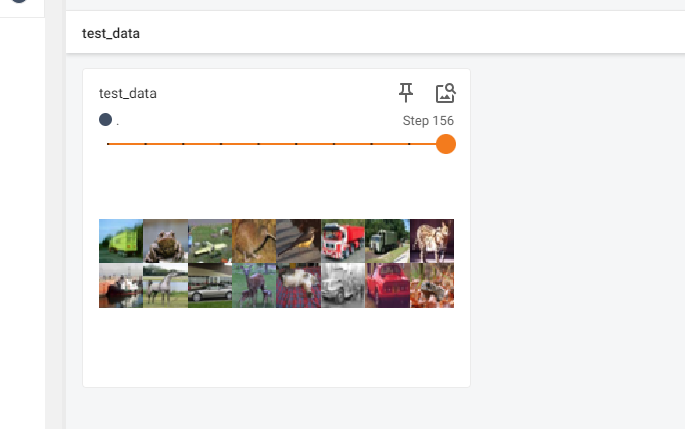
DataLoad的使用

import torchvision
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
# 準備的測試數據集
test_data = torchvision.datasets.CIFAR10("./dataset", train=False, transform=torchvision.transforms.ToTensor())
test_loader = DataLoader(dataset=test_data, batch_size=64, shuffle=True, num_workers=0, drop_last=False)
# 這裡數據集是之前官網下載下來的
# 測試數據集中第一張圖片及target
img, target = test_data[0]
print(img.shape)
print(target)
writer = SummaryWriter("dataloader")
step = 0
for data in test_loader:
imgs, targets = data
# print(imgs.shape)
# print(targets)
writer.add_images("test_data", imgs, step)
step = step + 1
writer.close()

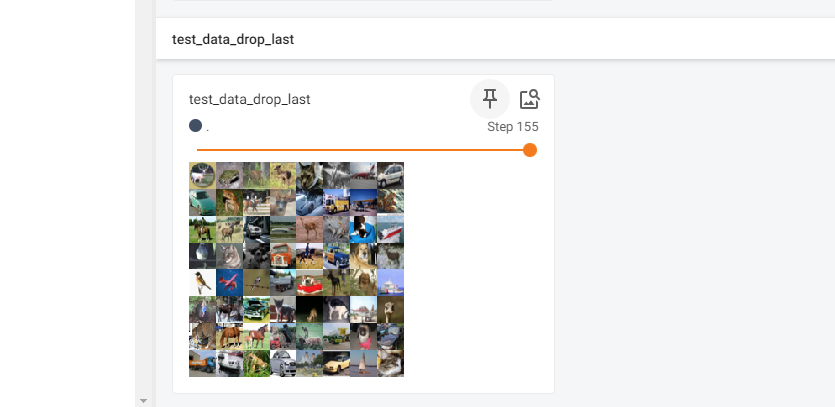
- 最後一次數據不滿足64張 於是將參數設置drop_last=True
import torchvision
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
# 準備的測試數據集
test_data = torchvision.datasets.CIFAR10("./dataset", train=False, transform=torchvision.transforms.ToTensor())
test_loader = DataLoader(dataset=test_data, batch_size=64, shuffle=True, num_workers=0, drop_last=True)
# 這裡數據集是之前官網下載下來的
# 測試數據集中第一張圖片及target
img, target = test_data[0]
print(img.shape)
print(target)
writer = SummaryWriter("dataloader_drop_last")
step = 0
for data in test_loader:
imgs, targets = data
# print(imgs.shape)
# print(targets)
writer.add_images("test_data", imgs, step)
step = step + 1
writer.close()
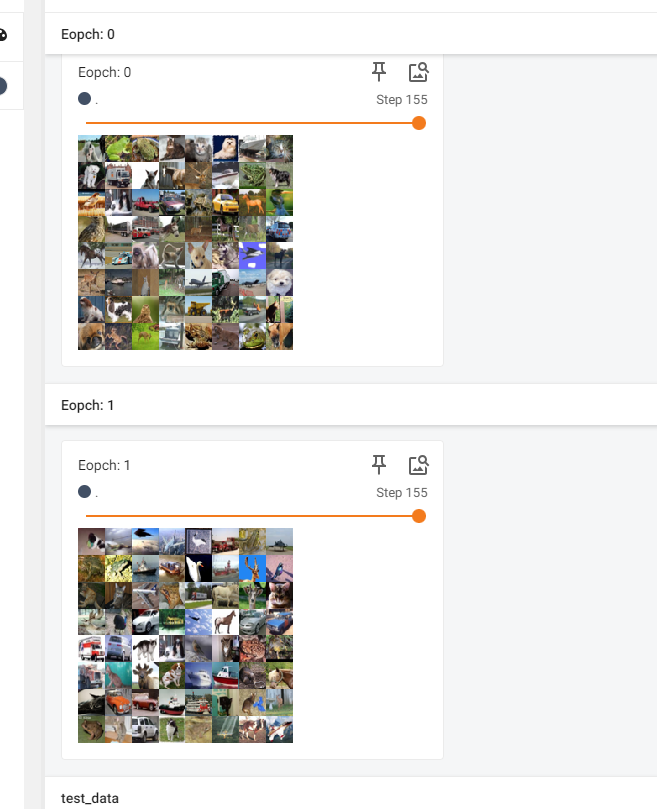
- shuffle 使用
- True 兩邊圖片選取不一樣
- False兩邊圖片選取一樣
import torchvision
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
# 準備的測試數據集
test_data = torchvision.datasets.CIFAR10("./dataset", train=False, transform=torchvision.transforms.ToTensor())
test_loader = DataLoader(dataset=test_data, batch_size=64, shuffle=True, num_workers=0, drop_last=True)
# 這裡數據集是之前官網下載下來的
# 測試數據集中第一張圖片及target
img, target = test_data[0]
print(img.shape)
print(target)
writer = SummaryWriter("dataloader")
for epoch in range(2):
step = 0
for data in test_loader:
imgs, targets = data
# print(imgs.shape)
# print(targets)
writer.add_images("Eopch: {}".format(epoch), imgs, step)
step = step + 1
writer.close()
神經網路的基本骨架
import torch
from torch import nn
class ConvModel(nn.Module):
def __init__(self, *args, **kwargs) -> None:
super().__init__(*args, **kwargs)
def forward(self, input):
output = input + 1
return output
convmodel = ConvModel()
x = torch.tensor(1.0)
output = convmodel(x)
print(output)
捲積操作

import torch
import torch.nn.functional as F
# 捲積輸入
input = torch.tensor([[1, 2, 0, 3, 1],
[0, 1, 2, 3, 1],
[1, 2, 1, 0, 0],
[5, 2, 3, 1, 1],
[2, 1, 0, 1, 1]])
# 捲積核
kernel = torch.tensor([[1, 2, 1],
[0, 1, 0],
[2, 1, 0]])
# 進行尺寸轉換
input = torch.reshape(input, (1, 1, 5, 5))
kernel = torch.reshape(kernel, (1, 1, 3, 3))
print(input.shape)
print(kernel.shape)
output = F.conv2d(input, kernel, stride=1)
print(output)
output2 = F.conv2d(input, kernel, stride=2)
print(output2)

- padding

# padding 預設填充值是0
output3 = F.conv2d(input, kernel, stride=1, padding=1)
print(output3)
結果:
tensor([[[[ 1, 3, 4, 10, 8],
[ 5, 10, 12, 12, 6],
[ 7, 18, 16, 16, 8],
[11, 13, 9, 3, 4],
[14, 13, 9, 7, 4]]]])
神經網路-捲積層
import torch
import torchvision
from torch.utils.data import DataLoader
from torch import nn
from torch.nn import Conv2d
from torch.utils.tensorboard import SummaryWriter
dataset = torchvision.datasets.CIFAR10("./dataset", train=False, transform=torchvision.transforms.ToTensor(),
download=True)
dataloader = DataLoader(dataset, batch_size=64)
class NN_Conv2d(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = Conv2d(in_channels=3, out_channels=6, kernel_size=3, stride=1, padding=0)
def forward(self, x):
x = self.conv1(x)
return x
nn_conv2d = NN_Conv2d()
# print(nn_conv2d)
writer = SummaryWriter("./logs")
step = 0
for data in dataloader:
imgs, targets = data
output = nn_conv2d(imgs)
print(f"imgs: {imgs.shape}")
print(f"output: {output.shape}")
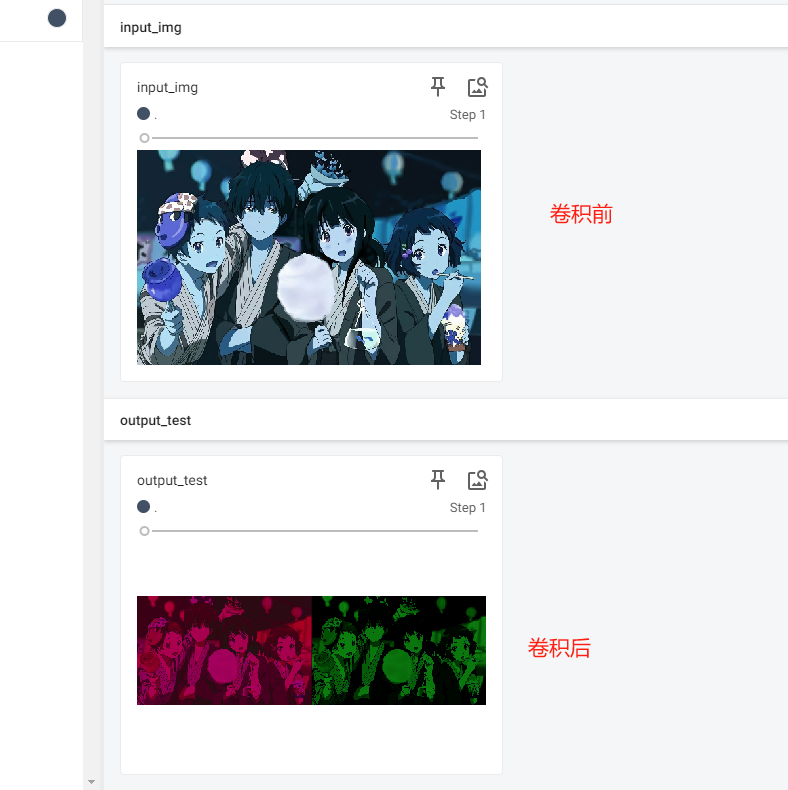
# 輸入的大小 torch.Size([64,3,32,32])
writer.add_images("input", imgs, step)
# 捲積後輸出的大小 torch.Size([64,,6,30,30) --> [xxx,3,30,30]
output = torch.reshape(output, (-1, 3, 30, 30))
writer.add_images("output", output, step)
step += 1

# import numpy as np
import torch
import torchvision
from torch import nn
from torch.nn import Conv2d
from torch.utils.tensorboard import SummaryWriter
import cv2
from torchvision import transforms
# 創建捲積模型
class NN_Conv2d(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = Conv2d(in_channels=3, out_channels=6, kernel_size=3, stride=1, padding=1)
def forward(self, x):
x = self.conv1(x)
return x
nn_conv2d = NN_Conv2d()
writer = SummaryWriter('logs_test')
input_img = cv2.imread("dataset/ice.jpg")
# 轉化為tensor類型
trans_tensor = transforms.ToTensor()
input_img = trans_tensor(input_img)
# 設置input輸入大小
input_img = torch.reshape(input_img, (-1, 3, 1312, 2100))
print(input_img.shape)
writer.add_images("input_img", input_img, 1)
# 進行捲積輸出
output = nn_conv2d(input_img)
output = torch.reshape(output, (-1, 3, 1312, 2100))
print(output.shape)
writer.add_images('output_test', output, 1)
writer.close()
神經網路-最大池化

import torch
from torch import nn
from torch.nn import MaxPool2d
input_img = torch.tensor([[1, 2, 0, 3, 1],
[0, 1, 2, 3, 1],
[1, 2, 1, 0, 0],
[5, 2, 3, 1, 1],
[2, 1, 0, 1, 1]], dtype=torch.float32)
input_img = torch.reshape(input_img, (-1, 1, 5, 5))
print(input_img.shape)
# 簡單的搭建捲積神經網路
class Nn_Conv_Maxpool(nn.Module):
def __init__(self):
super().__init__()
self.maxpool1 = MaxPool2d(kernel_size=3, ceil_mode=True)
def forward(self, input_img):
output = self.maxpool1(input_img)
return output
nn_conv_maxpool = Nn_Conv_Maxpool()
output = nn_conv_maxpool(input_img)
print(output)
import torch
import torchvision
from torch import nn
from torch.nn import MaxPool2d
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
dataset = torchvision.datasets.CIFAR10('./dataset', train=False, download=True,
transform=torchvision.transforms.ToTensor())
dataloader = DataLoader(dataset, batch_size=64)
# 簡單的搭建捲積神經網路
class Nn_Conv_Maxpool(nn.Module):
def __init__(self):
super().__init__()
self.maxpool1 = MaxPool2d(kernel_size=3, ceil_mode=True)
def forward(self, input_img):
output = self.maxpool1(input_img)
return output
nn_conv_maxpool = Nn_Conv_Maxpool()
writer = SummaryWriter('logs_maxpool')
step = 0
for data in dataloader:
imgs, targets = data
writer.add_images('input', imgs, step)
output = nn_conv_maxpool(imgs)
writer.add_images('output', output, step)
step += 1
writer.close()

神經網路-非線性激活
- ReLU
import torch
from torch import nn
from torch.nn import ReLU
input = torch.tensor([[1, -0.5],
[-1, 3]])
input = torch.reshape(input, (-1, 1, 2, 2))
print(input.shape)
class Nn_Network_Relu(nn.Module):
def __init__(self):
super().__init__()
self.relu1 = ReLU()
def forward(self, input):
output = self.relu1(input)
return output
nn_relu = Nn_Network_Relu()
output = nn_relu(input)
print(outputz)
- 使用圖片進行演示
import torch
import torchvision
from torch import nn
from torch.nn import ReLU
from torch.nn import Sigmoid
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
input = torch.tensor([[1, -0.5],
[-1, 3]])
input = torch.reshape(input, (-1, 1, 2, 2))
print(input.shape)
dataset = torchvision.datasets.CIFAR10('./dataset', train=False, download=True,
transform=torchvision.transforms.ToTensor())
dataloader = DataLoader(dataset, batch_size=64)
class Nn_Network_Relu(nn.Module):
def __init__(self):
super().__init__()
self.relu1 = ReLU()
self.sigmoid1 = Sigmoid()
def forward(self, input):
output = self.sigmoid1(input)
return output
nn_relu = Nn_Network_Relu()
nn_sigmoid = Nn_Network_Relu()
writer = SummaryWriter('logs_sigmoid')
step = 0
for data in dataloader:
imgs, targets = data
writer.add_images("input_imgs", imgs, step)
output = nn_sigmoid(imgs)
writer.add_images("output", output, step)
step += 1
writer.close()

神經網路-線性層及其他層
- 線性層(linear layer)通常也被稱為全連接層(fully connected layer)。在深度學習模型中,線性層和全連接層指的是同一種類型的神經網路層,它將輸入數據與權重相乘並加上偏置,然後通過一個非線性激活函數輸出結果。可以實現特征提取、降維等功能。
- 以VGG16網路模型為例,全連接層共有3層,分別是4096-4096-1000,這裡的1000為ImageNet中數據集類別的數量。

import torch
import torchvision
from torch.utils.data import DataLoader
from torch import nn
from torch.nn import Linear
dataset = torchvision.datasets.CIFAR10('./dataset', train=False, transform=torchvision.transforms.ToTensor(),
download=True)
dataloader = DataLoader(dataset, batch_size=64)
class Nn_LinearModel(nn.Module):
def __init__(self):
super().__init__()
self.linear1 = Linear(196608, 10)
def forward(self, input):
output = self.linear1(input)
return output
nn_linearmodel = Nn_LinearModel()
for data in dataloader:
imgs, targets = data
print(imgs.shape)
output = torch.flatten(imgs)
print(output.shape)
output = nn_linearmodel(output)
print(output.shape)
-
torch.flatten: 將輸入(Tensor)展平為一維張量
-
batch_size 一般不展開,以MNIST數據集的一個 batch 為例將其依次轉化為例:
[64, 1, 28, 28] -> [64, 784] -> [64, 128]
神經網路-實踐以及Sequential

import torch
from torch import nn
from torch.nn import Conv2d, MaxPool2d, Flatten, Linear
class Nn_SeqModel(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = Conv2d(3, 32, 5, padding=2)
self.maxpool1 = MaxPool2d(2)
self.conv2 = Conv2d(32, 32, 5, padding=2)
self.maxpool2 = MaxPool2d(2)
self.conv3 = Conv2d(32, 64, 5, padding=2)
self.maxpool3 = MaxPool2d(2)
self.flatten = Flatten()
self.linear1 = Linear(1024, 64)
self.linear2 = Linear(64, 10)
def forward(self, x):
x = self.conv1(x)
x = self.maxpool1(x)
x = self.conv2(x)
x = self.maxpool2(x)
x = self.conv3(x)
x = self.maxpool2(x)
x = self.flatten(x)
x = self.linear1(x)
x = self.linear2(x)
return x
if __name__ == '__main__':
nn_seqmodel = Nn_SeqModel()
print(nn_seqmodel)
# 對網路模型進行檢驗
input = torch.ones((64, 3, 32, 32))
output = nn_seqmodel(input)
print(output.shape)
Nn_SeqModel(
(conv1): Conv2d(3, 32, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))
(maxpool1): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(conv2): Conv2d(32, 32, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))
(maxpool2): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(conv3): Conv2d(32, 64, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))
(maxpool3): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(flatten): Flatten(start_dim=1, end_dim=-1)
(linear1): Linear(in_features=1024, out_features=64, bias=True)
(linear2): Linear(in_features=64, out_features=10, bias=True)
)
torch.Size([64, 10])
- Sequential 使代碼更加簡潔
import torch
from torch import nn
from torch.nn import Conv2d, MaxPool2d, Flatten, Linear, Sequential
class Nn_SeqModel(nn.Module):
def __init__(self):
super().__init__()
# self.conv1 = Conv2d(3, 32, 5, padding=2)
# self.maxpool1 = MaxPool2d(2)
# self.conv2 = Conv2d(32, 32, 5, padding=2)
# self.maxpool2 = MaxPool2d(2)
# self.conv3 = Conv2d(32, 64, 5, padding=2)
# self.maxpool3 = MaxPool2d(2)
# self.flatten = Flatten()
# self.linear1 = Linear(1024, 64)
# self.linear2 = Linear(64, 10)
self.model1 = Sequential(
Conv2d(3, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 64, 5, padding=2),
MaxPool2d(2),
Flatten(),
Linear(1024, 64),
Linear(64, 10)
)
def forward(self, x):
# x = self.conv1(x)
# x = self.maxpool1(x)
# x = self.conv2(x)
# x = self.maxpool2(x)
# x = self.conv3(x)
# x = self.maxpool2(x)
# x = self.flatten(x)
# x = self.linear1(x)
# x = self.linear2(x)
x = self.model1(x)
return x
if __name__ == '__main__':
nn_seqmodel = Nn_SeqModel()
print(nn_seqmodel)
# 對網路模型進行檢驗
input = torch.ones((64, 3, 32, 32))
output = nn_seqmodel(input)
print(output.shape)
Nn_SeqModel(
(model1): Sequential(
(0): Conv2d(3, 32, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))
(1): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(2): Conv2d(32, 32, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))
(3): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(4): Conv2d(32, 64, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))
(5): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(6): Flatten(start_dim=1, end_dim=-1)
(7): Linear(in_features=1024, out_features=64, bias=True)
(8): Linear(in_features=64, out_features=10, bias=True)
)
)
torch.Size([64, 10])
if __name__ == '__main__':
nn_seqmodel = Nn_SeqModel()
print(nn_seqmodel)
# 對網路模型進行檢驗
input = torch.ones((64, 3, 32, 32))
output = nn_seqmodel(input)
print(output.shape)
# 查看網路結構
writer = SummaryWriter('./logs_seq')
writer.add_graph(nn_seqmodel, input)
writer.close()
- 查看網路結構

損失函數與反向傳播
- loos 損失函數



- 註意輸入和輸出

import torch
from torch.nn import L1Loss
inputs = torch.tensor([1, 2, 3], dtype=torch.float32)
targets = torch.tensor([1, 2, 5], dtype=torch.float32)
inputs = torch.reshape(inputs, (1, 1, 1, 3))
targets = torch.reshape(targets, (1, 1, 1, 3))
loss = L1Loss() # reduction='sum'
result = loss(inputs, targets)
print(result)
tensor(0.6667)
- 交叉熵loss

x = torch.tensor([0.1, 0.2, 0.3])
y = torch.tensor([1])
x = torch.reshape(x, (1, 3))
loss_cross = nn.CrossEntropyLoss()
result_cross = loss_cross(x, y)
print(f"The result_cross of CrossEntropyLoss: {result_cross}")
The result_cross of CrossEntropyLoss: 1.1019428968429565
- 測試
import torch
import torchvision
from torch import nn
from torch.nn import Conv2d, MaxPool2d, Flatten, Linear, Sequential
from torch.utils.tensorboard import SummaryWriter
from torch.utils.data import DataLoader
dataset = torchvision.datasets.CIFAR10("./dataset", train=False, transform=torchvision.transforms.ToTensor(),
download=True)
dataloader = DataLoader(dataset, batch_size=1)
class Nn_LossNetworkModel(nn.Module):
def __init__(self):
super().__init__()
self.model1 = Sequential(
Conv2d(3, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 64, 5, padding=2),
MaxPool2d(2),
Flatten(),
Linear(1024, 64),
Linear(64, 10)
)
def forward(self, x):
x = self.model1(x)
return x
loss = nn.CrossEntropyLoss()
if __name__ == '__main__':
nn_lossmodel = Nn_LossNetworkModel()
for data in dataloader:
imgs, targets = data
outputs = nn_lossmodel(imgs)
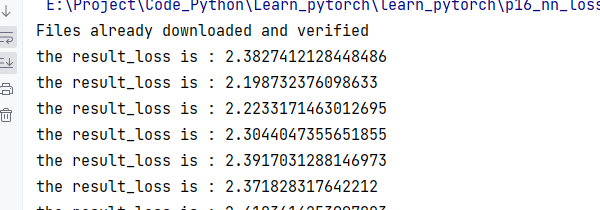
result_loss = loss(outputs, targets)
print(f"the result_loss is : {result_loss}")
- 梯度下降 進行反向傳播
- debug測試查看 grad
if __name__ == '__main__':
nn_lossmodel = Nn_LossNetworkModel()
for data in dataloader:
imgs, targets = data
outputs = nn_lossmodel(imgs)
result_loss = loss(outputs, targets)
# print(f"the result_loss is : {result_loss}")
result_loss.backward()
print("ok")
優化器
import torch
import torchvision
from torch import nn
from torch.nn import Conv2d, MaxPool2d, Flatten, Linear, Sequential
from torch.utils.tensorboard import SummaryWriter
from torch.utils.data import DataLoader
# 載入數據集轉換為tensor類型
dataset = torchvision.datasets.CIFAR10("./dataset", train=False, transform=torchvision.transforms.ToTensor(),
download=True)
# 使用DataLoader將數據集進行載入
dataloader = DataLoader(dataset, batch_size=1)
# 創建網路
class Nn_LossNetworkModel(nn.Module):
def __init__(self):
super().__init__()
self.model1 = Sequential(
Conv2d(3, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 64, 5, padding=2),
MaxPool2d(2),
Flatten(),
Linear(1024, 64),
Linear(64, 10)
)
def forward(self, x):
x = self.model1(x)
return x
if __name__ == '__main__':
loss = nn.CrossEntropyLoss()
nn_lossmodel = Nn_LossNetworkModel()
optim = torch.optim.SGD(nn_lossmodel.parameters(), lr=0.01)
for data in dataloader:
imgs, targets = data
outputs = nn_lossmodel(imgs)
result_loss = loss(outputs, targets)
optim.zero_grad()
result_loss.backward()
optim.step()

if __name__ == '__main__':
loss = nn.CrossEntropyLoss()
nn_lossmodel = Nn_LossNetworkModel()
optim = torch.optim.SGD(nn_lossmodel.parameters(), lr=0.01)
for epoch in range(20):
running_loss = 0.0
for data in dataloader:
imgs, targets = data
outputs = nn_lossmodel(imgs)
result_loss = loss(outputs, targets)
optim.zero_grad()
result_loss.backward()
optim.step()
running_loss = running_loss + result_loss
print("running_loss: ", running_loss)
Files already downloaded and verified
running_loss: tensor(18788.4355, grad_fn=)
running_loss: tensor(16221.9961, grad_fn=) ........
現有網路模型的使用以及修改
import torchvision
import torch
from torch import nn
# train_data = torchvision.datasets.ImageNet("./data_image_net", split="train",
# transform=torchvision.transforms.ToTensor(), download=True)
vgg16_false = torchvision.models.vgg16(pretrained=False)
vgg16_true = torchvision.models.vgg16(pretrained=True)
print('ok')
print(vgg16_true)
train_data = torchvision.datasets.CIFAR10('./dataset', train=True, transform=torchvision.transforms.ToTensor(),
download=True)
# vgg16_true.add_module('add_linear', nn.Linear(1000, 10))
vgg16_true.classifier.add_module('add_linear', nn.Linear(1000, 10))
print(vgg16_true)
print(vgg16_false)
vgg16_false.classifier[6] = nn.Linear(4096, 10)
print(vgg16_false)
網路模型的保存與讀取
- save
import torch
import torchvision
from torch import nn
vgg16 = torchvision.models.vgg16(pretrained=False)
# 保存方式1: 模型結構+模型參數
torch.save(vgg16, "vgg16_method1.pth")
# 保存方式2: 模型參數(官方推薦)
torch.save(vgg16.state_dict(), "vgg16_method2.pth")
# 陷阱
class Nn_Model(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = nn.Conv2d(3, 64, 3)
def forward(self, x):
x = self.conv1(x)
return x
nn_model = Nn_Model()
torch.save(nn_model, "nnModel_method1.pth")
- load
import torch
import torchvision
from torch import nn
from p19_model_save import *
# 載入方式1 ---> 對應保存方式1 ,載入模型
model = torch.load("vgg16_method1.pth")
# print(model)
# 載入方式2
model2 = torch.load("vgg16_method2.pth")
print(model2)
# 方式2 的回覆網路模型結構
vgg16 = torchvision.models.vgg16(pretrained=False)
vgg16.load_state_dict(torch.load("vgg16_method2.pth"))
print(vgg16)
# 陷阱1
# class Nn_Model(nn.Module):
# def __init__(self):
# super().__init__()
# self.conv1 = nn.Conv2d(3, 64, 3)
#
# def forward(self, x):
# x = self.conv1(x)
# return x
model1 = torch.load("nnModel_method1.pth")
print(model1)
完成的模型訓練套路(一)
- 建包 train.py 和 model.py
- model.py
import torch
from torch import nn
# 搭建神經網路
class Nn_Neural_NetWork(nn.Module):
def __init__(self):
super().__init__()
self.model = nn.Sequential(
nn.Conv2d(3, 32, 5, 1, 2),
nn.MaxPool2d(2),
nn.Conv2d(32, 32, 5, 1, 2),
nn.MaxPool2d(2),
nn.Conv2d(32, 64, 5, 1, 2),
nn.MaxPool2d(2),
nn.Flatten(),
nn.Linear(64 * 4 * 4, 64),
nn.Linear(64, 10)
)
def forward(self, x):
x = self.model(x)
return x
if __name__ == '__main__':
# 測試一下模型準確性
nn_model = Nn_Neural_NetWork()
input = torch.ones((64, 3, 32, 32))
output = nn_model(input)
print(output.shape)
- train.py
import torch
import torchvision
from torch import nn
from torch.utils.data import DataLoader
from torch.nn import Conv2d, MaxPool2d, Flatten, Linear, Sequential
from model import *
# 準備數據集
train_data = torchvision.datasets.CIFAR10(root='./data', train=True, transform=torchvision.transforms.ToTensor(),
download=True)
test_data = torchvision.datasets.CIFAR10(root='./data', train=False, transform=torchvision.transforms.ToTensor(),
download=True)
train_data_size = len(train_data)
test_data_size = len(test_data)
print("訓練數據集的長度為:{}".format(train_data_size))
print("測試數據集的長度為:{}".format(test_data_size))
# 利用DataLoader 來載入數據集
train_loader = DataLoader(train_data, batch_size=64)
test_loader = DataLoader(test_data, batch_size=64)
# 創建網路模型
nn_model = Nn_Neural_NetWork()
# 損失函數
loss_fn = nn.CrossEntropyLoss()
# 優化器
# 1e-2 = 1 x (10)^(-2) = 1/100 = 0.01
learning_rate = 0.01
optimizer = torch.optim.SGD(nn_model.parameters(), lr=learning_rate)
# 設置訓練網路的一些參數
# 記錄訓練的次數
total_train_step = 0
# 記錄測試的次數
total_test_step = 0
# 訓練的輪數
epoch = 10
for i in range(epoch):
print("--------第{}輪訓練開始-------".format(i + 1))
# 訓練步驟開始
for data in train_loader:
imgs, targets = data
output = nn_model(imgs)
loss = loss_fn(output, targets)
# 優化器優化模型
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_train_step += 1
print("訓練次數: {}, Loss: {}".format(total_train_step, loss.item()))
完成的模型訓練套路(二)
- train.py
- 增加了tenorboard
- 增加了精確度Accuracy
import torch
import torchvision
from torch import nn
from torch.utils.data import DataLoader
from torch.nn import Conv2d, MaxPool2d, Flatten, Linear, Sequential
from torch.utils.tensorboard import SummaryWriter
from p20_model import *
# 準備數據集
train_data = torchvision.datasets.CIFAR10(root='./data', train=True, transform=torchvision.transforms.ToTensor(),
download=True)
test_data = torchvision.datasets.CIFAR10(root='./data', train=False, transform=torchvision.transforms.ToTensor(),
download=True)
train_data_size = len(train_data)
test_data_size = len(test_data)
print("訓練數據集的長度為:{}".format(train_data_size))
print("測試數據集的長度為:{}".format(test_data_size))
# 利用DataLoader 來載入數據集
train_loader = DataLoader(train_data, batch_size=64)
test_loader = DataLoader(test_data, batch_size=64)
# 創建網路模型
nn_model = Nn_Neural_NetWork()
# 損失函數
loss_fn = nn.CrossEntropyLoss()
# 優化器
# 1e-2 = 1 x (10)^(-2) = 1/100 = 0.01
learning_rate = 0.01
optimizer = torch.optim.SGD(nn_model.parameters(), lr=learning_rate)
# 設置訓練網路的一些參數
# 記錄訓練的次數
total_train_step = 0
# 記錄測試的次數
total_test_step = 0
# 訓練的輪數
epoch = 10
# (可加可不加) 添加tensorboard
writer = SummaryWriter('./logs_train')
for i in range(epoch):
print("--------第{}輪訓練開始-------".format(i + 1))
# 訓練步驟開始
for data in train_loader:
imgs, targets = data
output = nn_model(imgs)
loss = loss_fn(output, targets)
# 優化器優化模型
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_train_step += 1
if total_train_step % 100 == 0:
print("訓練次數: {}, Loss: {}".format(total_train_step, loss.item()))
writer.add_scalar("train_loss", loss.item(), total_train_step)
# 測試步驟開始
total_test_loss = 0
# 精確度
total_accuracy = 0
with torch.no_grad():
for data in test_loader:
imgs, targets = data
outputs = nn_model(imgs)
loss = loss_fn(outputs, targets)
total_test_loss += loss
accuracy = (outputs.argmax(1) == targets).sum()
total_accuracy += accuracy
print("整體測試集上的Loss: {}".format(total_test_loss))
print("整體測試集上的正確率Accuracy: {}".format(total_accuracy / test_data_size))
writer.add_scalar("test_loss", total_test_loss, total_test_step)
writer.add_scalar("test_accuracy", total_accuracy / test_data_size, total_test_step)
total_test_step += 1
# 保存模型結果
torch.save(nn_model, "model_{}.pth".format(i))
print("模型保存")
writer.close()


