
無論是在內部系統還是在外部的互聯網站上,都少不了檢索系統。數據是為了用戶而服務。電腦在採集數據,處理數據,存儲數據之後,各種客戶端的操作pc機或者是移動嵌入式設備都可以很好的獲取數據,得到 想要的數據服務。 檢索分為SQL過濾查詢和全文檢索。數據都是放在資料庫里,資料庫里的數據量太大,要檢索到精準 ...
無論是在內部系統還是在外部的互聯網站上,都少不了檢索系統。數據是為了用戶而服務。電腦在採集數據,處理數據,存儲數據之後,各種客戶端的操作pc機或者是移動嵌入式設備都可以很好的獲取數據,得到 想要的數據服務。
檢索分為SQL過濾查詢和全文檢索。數據都是放在資料庫里,資料庫里的數據量太大,要檢索到精準的數據是需要很好的用戶體驗。用戶對響應時長要求特別嚴格,最好控制在一定的響應時間內。SQL查詢是普通的欄位過濾,一般在沒有走全表掃描的情況下都是性能較好的數據查詢方式。全文檢索的實現方式是在資料庫設計的時候就有這些模塊,比如MySQL的全文檢索。之後在市面上有公司開發了成型的開源產品,比如Lucene等。 學過luncene框架, 能就是論事。在銀行工作的時候有接觸過es框架,到現在也沒仔細去弄懂。每個人的學習能力不一樣,有的工程師削尖了腦袋要去專研每個技術。 是在學習Java開發框架的時候接觸過Lucene框架, 跟著源碼敲了一遍那個搜索引擎。對於那種根據分詞查詢數據的方式有深刻的映像,但是並不是每個系統都是要使用全文檢索分詞搜索。
按需開發,意思就是根據需求進行商業開發。以用戶體驗為中心,金錢盈利為目的。沒有誰在為 做無用功,得到與失去,不要去說,也說不准。像普通的欄位搜索看起來十分簡單,其實就是很簡單。但是如果遇到數據量大的情況,或者是用戶不會使用系統的情況下,都是有問題的。像百度,Google,搜什麼就有什麼,這就是全文檢索。
搜索,依賴於搜索引擎。搜索引擎的建立是十分困難的事情。以 現在的水平理解的搜索, 能說個大概。 做Java 6年時間,雖然沒有寫過搜索引擎,但是沒有經驗的同學可以去嘗試著實踐下。做任何系統都是需要構建bs架構或者是cs架構,cs架構是client-server架構。
在操作系統中有客戶端軟體開發包,bs架構是broswer-server架構,在所有的數據操作都是在瀏覽器中實現,把瀏覽器當做一個子系統,子系統上面又有很多應用程式... bs架構是特殊的cs架構。
在大學學習電腦編程開發,首選的語言是C++。那種語言是寫客戶端軟體, 也是學的很糾結,以為沒有很好的效果。大三休學的時候學習了Java,接觸全文檢索,學習了前端頁面的設計開發,後臺資料庫的建立。到現在有更多的想法和思考。爬蟲的建立,爬蟲是怎麼從網站上爬數據,用戶是怎麼在網站上面搜索數據。
大學畢業之後對於搜索引擎的理解畫了個草圖
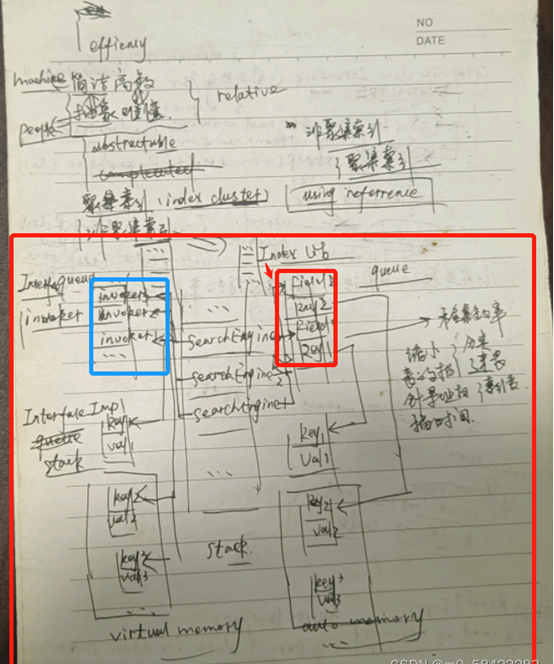
像 爬蟲

一般的java IDE的debug是這樣設計

爬蟲是怎麼在網站上爬數據,為什麼 能爬網站的數據。現在的web瀏覽器都支持HTML標簽編輯的網頁,HTML標簽頁是dom元素。每個DOM元素都是一個實體對象,在資料庫中體現的就是dom元素實體對象表。Dom元素表裡存放的就是網頁標簽所承載的基礎數據和一些基本屬性。每當一個網站上面的標簽包裹的數據發生變化,就要觸發數據寫write事件,即 WriteEventListener,更新索引庫里的索引數據,和文檔庫里的文檔數據。這種數據更新同步方式叫做即時同步方式,是的資料庫里的數據和索引庫里的數據保持一致性。用戶查詢數據的時候總能查到最新的數據,用戶查數據都是走索引庫再走文檔庫,這樣性能更好。
至於怎麼構建dom元素資料庫,怎麼構建dom元素索引庫。那些都是商業庫,需要開發註冊維護,就像 在某個地方開商店一樣,需要辦理很多手續。
當時學習操作lucene 框架架構方式是通過AOP的方式實現數據同步。數據同步是文檔庫和索引庫的同步操作方式。文檔庫存放的是Document 文檔對象,索引庫存放的是欄位對象 Field 。欄位對象 分為索引文檔號和經歷過分詞器分詞之後的關鍵字集合。中文分詞器是Analyzer 堆中文的語句進行分詞。
中文的分詞器對中文語句的此法進行分析。中文的語句分為 主+謂+賓+定+狀+補 . 分詞器分為標準的國際分詞器和中國大陸簡體的中文分詞器。原理十分相似,實詞和虛詞需要區分。實詞是名詞,虛詞是冠詞,語氣詞,稱謂詞,形容詞,狀態詞,補語詞,謂語詞 。分詞器分析網站上面的文章關鍵字,中文摘要,具體的文章正文內容。分詞器的分詞結果生成關鍵字和文檔索引組裝成的欄位 Field 對象。欄位對象集合 fieldList 放在lucene 索引庫中。文檔庫中存放大量的文檔對象,文檔Document 與 欄位 Field 對象的索引表中的文檔索引關聯。
用戶在前端使用日用語句在lucene搜索引擎中搜索數據集合的過程十分複雜。簡單的過程可以分為
- 查詢語句詞的錄入接收。
- 後臺對中文查詢語句分詞,抽取關鍵字形成關鍵字集合。
- 使用關鍵字集合在lucene索引庫 中的關鍵字進行匹配,匹配成功會有文檔集合 documentList 。
- 文檔集合返回給業務邏輯層 service . 使用高亮器hlighter 對文檔中的存在的關鍵詞高亮。
- 文檔集合的返回通過評分對象 score 綜合得分排序。
a) 命中文檔的得分 score 有預設的得分規則和自定義得分規則。
數據同步在企業項目中使用很多。平安集團的hrx人力資源管理系統使用Elasticsearch 搜索引擎搜索數據。Lucene 和 Elasticsearch 兩種引擎搜索數據的方式都是全文檢索。全文檢索在資料庫軟體中普遍存在。企業的IDE 開發環境有搜索框的地方或許會有全文檢索的影子。軟體和應用程式系統都有數據。檢索方式分為通過表單的方式和一個表單輸入框的方式。一個表單輸入框的輸入方式面向的用戶是大眾化的互聯網網名。Java 的web信息系統安全新能和開發維護團隊有保障,使用sql 查詢語句查找數據的方式限制用戶量。內部系統的用戶量分為內部用戶和外圍用戶。使用sql查詢語句查詢數據使用全文檢索索引庫和文檔庫。數據查詢是否全表還是走索引表有用戶自定義,系統預設,AI 演算法相應的操作模式。
數據同步索引庫和文檔庫中的數據。同步平安銀行ES庫和PJ 庫中的數據。開發任務涉及到項目不同版本發佈的同步數據代碼。數據量大小和性能問題對於開發工程師是更高級別的操作。保證數據的正確性,代碼的質量高低。項目組之間的工程師都會相互借閱不同開發分支的代碼。每個開發都會有不同的編寫代碼的方式。
Elasticsearch 搜索原理和Lucene 類似。每個企業採用的技術架構選型不盡相同。


