
本文總結了軟體開發過程中經常用到的基礎常識,分為基礎篇和實踐篇兩個篇章,其中基礎篇中著重講述了類,方法,變數的命名規範以及代碼註釋好壞的評判標準。實踐篇中從類,方法以及對象三個層面分析了常見的技術概念和落地實踐,希望這些常識能夠為讀者帶來一些思考和幫助。 ...
一 引言
儘管軟體開發一直致力於追求高效、可讀性強、易於維護的特性,但這些特性卻像是一個不可能三角,相互交織,此消彼長。就像底層語言(如彙編和C語言)能夠保持高效的運行性能,但在可讀性和維護性方面卻存在短板和劣勢;而高級語言(如Java和Python)在可讀性和可維護性方面表現出色,但在執行效率方面卻存在不足。
構建語言生態的優勢,彌補其存在短板,始終是編程語言的一個演進方向。
不同編程語言,擁有不同的特性和規約,下麵就以JAVA語言為例,細數那些開發過程中容易被人忽略,但必須掌握的知識點和實踐技能。
二 基礎篇
1999年,美國太空總署(NASA)的火星任務失敗:在這次任務中, 火星氣候探測者號上的飛行系統軟體使用公制單位牛頓計算推進器動力,而地面人員輸入的方向校正量和推進器參數則使用英制單位磅力,導致探測器進入大氣層的高度有誤,最終瓦解碎裂。
這是由於國際標準(牛)和本土化(磅)的衝突導致的一起事故。由此引出了程式需要關註可維護性這個話題,由於軟體生產往往需要多人協作,可維護性正是協作共識里的重要一環。關於這方面,讓人最容易想到的就是命名和註釋兩個方面了,下麵就展開來探討一下。
2.1 關於命名
按照閱讀習慣,程式的變數命名法都需要剋服單詞間的空格問題,從而把不同單詞串連起來,最終達到創造出一種易於閱讀的新“單詞”的效果。常見的命名方法有以下幾種:
- 蛇形命名法(snake case):又叫下劃線命名法,使用下劃線,單詞小寫,比如:my_system;
- 駝峰命名法(camel case):按照單詞首字母區分大小寫,又可細分為大駝峰命名法和小駝峰命名法,比如:MySystem,mySystem;
- 匈牙利命名法(HN case):屬性+類型+描述,比如:nLength,g_cch,hwnd;
- 帕斯卡命名法(Pascal case):全部首字母大寫,等同於大駝峰命名法,比如:MySystem;
- 脊柱命名法(spinal case):使用中劃線,比如:my-system;
- 自由命名法(studly caps):大小寫混雜,無簡明規則,比如:mySYSTEM,MYSystem;
按照受眾量與知名程度排名,駝峰命名法和蛇形命名法更受到大家的歡迎,畢竟它們在可讀性,易寫性等方面比較有優勢。
2.1.1 命名字典
見名知意:好的命名就是一種註釋。
建議研發同學將業內常見業務場景的命名熟記,當然,已經有人幫我們總結過了,這裡不再做過多的說明。這裡摘錄如下,可供參考:
管理類命名:Bootstrap,Starter,Processor,Manager,Holder,Factory,Provider,Registrar,Engine,Service,Task
傳播類命名:Context,Propagator
回調類命名:Handler,Callback,Trigger,Listener,Aware
監控類命名:Metric,Estimator,Accumulator,Tracker
記憶體管理類命名:Allocator,Chunk,Arena,Pool
過濾檢測類命名:Pipeline,Chain,Filter,Interceptor,Evaluator,Detector
結構類命名:Cache,Buffer,Composite,Wrapper,Option, Param,Attribute,Tuple,Aggregator,Iterator,Batch,Limiter
常見設計模式命名:Strategy,Adapter,Action,Command,Event,Delegate,Builder,Template,Proxy
解析類命名:Converter,Resolver,Parser,Customizer,Formatter
網路類命名:Packet,Encoder、Decoder、Codec,Request,Response
CRUD命名:Controller,Service,Repository
輔助類命名:Util,Helper
其他類命名:Mode,Type,Invoker,Invocation,Initializer,Future,Promise,Selector,Reporter,Constants,Accessor,Generator
2.1.2 命名實踐
工程通用命名規則都有哪些呢?不同的語言可能會有不同的習慣,以Java語言的駝峰命名規範舉例:
-
項目名全部小寫;
-
包名全部小寫;
-
類名首字母大寫,其餘組成詞首字母依次大寫;
-
變數名,方法名首字母小寫,如果名稱由多個單片語成,除首字母外的每個單詞首字母都要大寫;
-
常量名全部大寫;
規範比較抽象,先來看看不好的命名有哪些呢?
-
自帶混淆功能的變數名:String zhrmghg = "極致縮寫型";
-
沒有意義的萬能變數名:String a,b,c="愛誰誰型";
-
長串拼音變數名:String HuaBuHua = "考古型";
-
各種符號混用:String $my_first_name_ = "打死記不住型";
-
大小寫,數字,縮寫混亂:String waitRPCResponse1 = "極易出錯型";
除了標準的規範之外,在實際的開發過程中還會有一些困擾我們的實際案例。
1. 在定義一個成員變數的時候,到底是使用包裝類型還是使用基本數據類型呢?
包裝類和基本數據類型的預設值是不一樣的,前者是null,後者依據不同類型其預設值也不一樣。從數據嚴謹的角度來講,包裝類的null值能夠表示額外信息,從而更加安全。比如可以規避基本類型的自動拆箱,導致的NPE風險以及業務邏輯處理異常風險。所以成員變數必須使用包裝數據類型,基本數據類型則在局部變數的場景下使用。
2. 為什麼不建議布爾類型的成員變數以is開頭?
關於Java Bean中的getter/setter方法的定義其實是有明確的規定的,根據JavaBeans(TM) Specification規定,如果是普通的參數,命名為propertyName,需要通過以下方式定義其setter/getter:
public <PropertyType> get<PropertyName>();
public void set<PropertyName>(<PropertyType> p)
但是,布爾類型的變數propertyName則是另外一套命名原則的:
public boolean is<PropertyName>();
public void set<PropertyName>(boolean p)
由於各種RPC框架和對象序列化工具對於布爾類型變數的處理方式存在差異,就容易造成代碼移植性問題。最常見的json序列化庫Jackson和Gson之間就存在相容性問題,前者是通過通過反射遍歷出該類中的所有getter方法,通過方法名截取獲得到對象的屬性,後者則是通過反射直接遍歷該類中的屬性。為了規避這種差異對業務的影響,建議所有成員變數都不要以is開頭,防止序列化結果出現不預知的情況發生。
3. 看看單詞大小寫能引起的哪些副作用?
JAVA語言本身是區分大小寫的,但是在用文件路徑、文件名對文件進行操作時,這裡的文件名和路徑是不區分大小寫的,這是因為文件系統不區分大小寫。典型的場景就是我們通過git等代碼管理平臺時,將package路徑里的大寫的文件名稱,修改為小寫時,git是無法更新的,為了規避不必要的麻煩,這裡建議包路徑統一使用小寫單詞,多個單詞通過路徑層次來進行定義。
4. 不同jar包里的類也會出現衝突問題?
-
一類是同一個jar包出現了多個不同的版本。應用選擇了錯誤的版本導致jvm載入不到需要的類或者載入了錯誤版本的類;(藉助maven管理工具相對容易解決)
-
另一類是不同的jar包出現了類路徑相同的類,同樣的類出現在不同的依賴jar里,由於jar載入的先後順序導致了JVM載入了錯誤版本的類;(比較難以解決)
這裡著重介紹第二種情況,這種情況容易出現在系統拆分重構時,將原有的項目進行了複製,然後刪減,導致部分工具或者枚舉類和原有的路徑和命名都一樣,當第三方調用方同時依賴了這兩個系統時,就容易為以後的迭代埋下坑。要規避此類問題,一定要為系統起一個獨一無二的package路徑。
補充:如果依賴的都是第三方的庫,存在著類衝突時,可以通過引入第三方庫jarjar.jar,修改其中某個衝突jar文件的包名,以此來解決jar包衝突。
5. 在變數命名的可讀性和占用資源(記憶體,帶寬)方面,如何去做權衡?
可以通過對象序列化工具為突破口,以常見的Json(Jackson)序列化方式來舉例:
public class SkuKey implements Serializable {
@JsonProperty(value = "sn")
@ApiModelProperty(name = "stationNo", value = " 門店編號", required = true)
private Long stationNo;
@JsonProperty(value = "si")
@ApiModelProperty(name = "skuId", value = " 商品編號", required = true)
private Long skuId;
// 省略get/set方法
}
其中@JsonProperty註解的作用就是將JavaBean中的普通屬性在序列化的時候,重新命名成指定的新的名字。而這一實現對於業務實現沒有影響,依然以原來的命名操作為準,只在對外RPC需要序列化和反序列化的過程生效。如此,比較好的解決了可讀性和資源占用的衝突問題。
6. 對外提供服務的入參和出參,我們是用class對象,還是Map容器?
從靈活性的角度看,Map容器穩定且更靈活。從穩定性和可讀性上來看,Map容器是個黑盒子,不知道裡面有什麼,得有輔助的詳細說明文檔才能協作,由於維護文檔的動作往往與工程代碼是分開的,這中機制就會導致信息的準確性和實時性很難得到保障。所以還是建議使用class結構對象維護出入參結構。
2.2 關於註釋
註釋是程式員和閱讀者之間交流的重要手段,是對代碼的解釋和說明,好的註釋可以提高軟體的可讀性,減少維護軟體的成本。
2.2.1 好的註釋
分層次 :按照系統,包,類,方法,代碼塊,代碼行等不同粒度,各有側重點的進行註釋說明。
-
系統註釋:通過README.md文件體現巨集觀的功能和架構實現;
-
包註釋:通過package-info文件體現模塊職責邊界,另外該文件也支持聲明友好類,包常量以及為標註在包上的註解(Annotation)提供便利;
-
類註釋:主要體現功能職責,版本支持,作者歸屬,應用示例等相關信息;
-
方法註釋:關註入參,出參,異常處理聲明,使用場景舉例等相關內容;
-
代碼塊和代碼行註釋:主要體現邏輯意圖,閉坑警示,規劃TODO,放大關註點等細節內容;
有規範 :好的代碼優於大量註釋,這和我們常說的“約定大於配置”是相同的道理。藉助swagger等三方庫實現 註解即介面文檔 ,是一個不錯的規範方式;
2.2.2 壞的註釋
為了能使註釋準確清晰的表達出功能邏輯,註釋的維護是有相當的維護成本的,所以註釋並不是越多,越詳細越好。下麵就舉一些壞的註釋場景,輔助理解:
-
冗餘式:如果一個函數,讀者能夠很容易的就讀出來代碼要表達的意思,註釋就是多餘的;
-
錯誤****式:如果註釋的不清楚,甚至出現歧義,那還不如不寫;
-
簽名式:類似“add by liuhuiqing 2023-08-05”這種註釋,容易過期失效而且不太可信(不能保證所有人每次都採用這種方式註釋),其功能完全可以由git代碼管理工具來實現;
-
長篇大論式:代碼塊里,夾雜了大篇幅的註釋,不僅影響代碼閱讀,而且維護困難;
-
非本地註釋:註釋應該在離代碼實現最近的地方,比如:被調用的方法註釋就由方法本身來維護,調用方無需對方法做詳細的說明;
-
註釋掉的代碼:無用的代碼應該刪除,而不是註釋。歷史記錄交給git等代碼管理工具來維護;
2.3 關於分層
系統分層設計的主要目是通過分離關註點,來降低系統的複雜度,同時提高可復用性和降低維護成本。所以懂得分層的概念,很大程度上系統的可維護性就有了骨架。
2.3.1 系統分層
在ISO((International Standardization Organization))於1981年制定網路通信七層模型(Open System Interconnection Reference Model,OSI/RM)之前,電腦網路中存在眾多的體繫結構,其中以IBM公司的SNA(系統網路體繫結構)和DEC公司的DNA(DigitalNetworkArchitecture)數字網路體繫結構最為著名。
最早之前,各個廠家提出的不同標準都是以自家設備為基礎的,用戶在選擇產品的時候就只能用同一家公司的,因為不同公司間大家的標準不一樣,工作方式也可能不一樣,結果就是不同廠商的網路產品間,可能會出現不相容的情況。如果說同一家的公司的產品都能滿足用戶的需求的話,那就看哪家公司實力強點,實力強的,用戶粘性高的,用戶自然也不會說什麼,問題是一家公司並不是對所有的產品都擅長。這就會導致廠商和用戶都面臨著痛苦的煎熬。類比一下當前手機充電介面協議(Micro USB介面、Type- c介面、Lightning介面),手頭總是要備有各種充電線的場景,就能深刻理解標準的意義了。
2.3.2 軟體伸縮性
軟體伸縮性指的是軟體系統在面對負載壓力時,能夠保持原有性能並擴展以支持更多任務的能力。
伸縮性可以有兩個方面,垂直伸縮性和水平伸縮性,垂直伸縮性是通過在同一個業務單元中增加資源來提高系統的吞吐量,比如增加伺服器cpu的數量,增加伺服器的記憶體等。水平伸縮性是通過增加多個業務單元資源,使得所有的業務單元邏輯上就像是一個單元一樣。比如ejb分散式組件模型,微服務組件模型等都屬於此種方式。
軟體系統在設計時需要考慮如何進行有效的伸縮性設計,以確保在面對負載壓力時能夠提供足夠的性能支持。
系統分層從伸縮性角度看,更多的屬於水平伸縮性的範疇。在J2EE系統開發當中,我們普遍採用了分層構架的方式,一般分為表現層,業務層和持久層。採用分層以後,因為層與層之間通信會引來額外的開銷,所以給我們軟體系統帶來的就是每個業務處理開銷會變大。
既然採用分層會帶來額外的開銷,那麼我們為什麼還要進行分層呢?
這是因為單純依靠堆硬體資源的垂直伸縮方式來提高軟體性能和吞吐是有上限的,而且隨著系統規模的擴大,垂直伸縮的代價也將變得非常昂貴。當採用了分層以後,雖然層與層之間帶來了通信開銷,但是它有利於各層的水平伸縮性,並且各個層都可以進行獨立的伸縮而不會影響到其它的層。也就是說當系統要應對更大的訪問量的時候,我們可以通過增加多個業務單元資源來增加系統吞吐量。
2.4 小結
本章內容主要從可讀性和可維護性方面講述了在開發過程中,要做好命名和註釋的統一共識。除了共識之外,在設計層面也需要做好關註點的隔離,這包含系統職責的拆分,模塊功能的劃分,類能力的收斂,實體結構的關係都需要做好規劃。
三 實踐篇
下麵就從程式的擴展性,維護性,安全性以及性能等幾個重要質量指標,來學習那些經典的實踐案例。
3.1 類定義
3.1.1 常量定義
常量是一種固定值,不會在程式執行期間發生改變。你可以使用枚舉(Enum)或類(Class)來定義常量。
如果你需要定義一組相關的常量,那麼使用枚舉更為合適。枚舉從安全性和可操作性(支持遍歷和函數定義)上面擁有更大的優勢。
public enum Color {
RED, GREEN, BLUE;
}
如果你只需要定義一個或少數幾個只讀的常量,那麼使用類常量更為簡潔和方便。
public class MyClass {
public static final int MAX_VALUE = 100;
}
3.1.2 工具類
工具類通常包含具有通用性的、某一非業務領域內的公共方法,不需要配套的成員變數,僅僅是作為工具方法被使用。因此,將其做成靜態方法最合適,不需要實例化,能夠獲取到方法的定義並調用就行。
工具類不實例化的原因是可以節省記憶體空間,因為工具類提供的是靜態方法,通過類就能調用,不需要實例化工具類對象。
public abstract class ObjectHelper {
public static boolean isEmpty(String str) {
return str == null || str.length() == 0;
}
}
為了實現不需要實例化對象的約束,我們最好在類定義時,加上abstract關鍵字進行聲明限定,這也是為什麼spring等開源工具類大都使用abstract關鍵字修飾的原因。
3.1.3 JavaBean
JavaBean的定義有兩種常見實現方式:手動編寫和自動生成。
public class Person {
private String name;
private int age;
public Person(String name, int age) {
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
}
使用lombok插件,通過註解方式來增強Java代碼的編寫,在編譯期動態生成get和set方法。
import lombok.Data;
@NoArgsConstructor
@Data
@Accessors(chain = true)
public class Person {
private String name;
private int age;
}
插件包還提供了@Builder和@Accessors等比較實用的鏈式編程能力,在一定程度上能提高編碼效率。
3.1.4 不可變類
在某些場景下,類為了保證其功能和行為的穩定性和一致性,會被設計為不能被繼承和重寫的。
定義方式就是在類上面添加final關鍵字,示例:
public final class String implements Serializable, Comparable<String>, CharSequence {
}
以下是一些不能被繼承和重寫的類,這在一些底層中間件中會有應用:
java.lang.String
java.lang.Math
java.lang.Boolean
java.lang.Character
java.util.Date
java.sql.Date
java.lang.System
java.lang.ClassLoader
3.1.5 匿名內部類
匿名內部類通常用於簡化代碼,它的定義和使用通常發生在同一處,它的使用場景如下:
-
直接作為參數傳遞給方法或構造函數;
-
用於實現某個介面或抽象類的匿名實例;
public class Example {
public static void main(String[] args) {
// 創建一個匿名內部類
Runnable runnable = new Runnable() {
@Override
public void run() {
System.out.println("Hello, World!");
}
};
// 調用匿名內部類的方法
runnable.run();
}
}
3.1.6 聲明類
聲明類是Java語言中的基本類型或介面,用於定義類的行為或特性,有的甚至只是個聲明,沒有具體的方法定義。
• AutoCloseable:表示實現了該介面的類可以被自動關閉,通常用於資源管理。
• Comparable:表示實現了該介面的類可以與其他實現了該介面的對象進行比較。
• Callable:表示實現了該介面的類可以作為參數傳遞給線程池,並返回結果。
• Cloneable:表示實現了該介面的類可以被克隆。
• Enum:表示實現了該介面的類是一個枚舉類型。
• Iterable:表示實現了該介面的類可以迭代。
• Runnable:表示實現了該介面的類可以作為線程運行。
• Serializable:表示實現了該介面的類可以被序列化和反序列化。
• interface:表示實現了該介面的類是一個介面,可以包含方法聲明。
• Annotation:表示實現了該介面的類是一個註解,可以用於元數據描述。
3.1.7 Record 類
Record 類在 Java14 中就開始預覽,一直到Java17 才正式發佈。根據 JEP395 的描述,Record 類是不可變數據的載體,類似於當下廣泛應用的各種 model,dto,vo 等 POJO 類,但 record 本身在構造之後不再可賦值。所有的 record 類都繼承自 java.lang.Record。Record 類預設提供了全欄位的構造器,屬性的訪問,還有 equals,hashcode,toString 方法,其作用和 lombok 插件非常類似。
定義方式
/**
* 關鍵定義的類是不可變類
* 將所有成員變數通過參數的形式定義
* 預設會生成全部參數的構造方法
* @param name
* @param age
*/
public record Person(String name, int age) {
public Person{
if(name == null){
throw new IllegalArgumentException("提供緊湊的方式進行參數校驗");
}
}
/**
* 定義的類中可以定義靜態方法
* @param name
* @return
*/
public static Person of(String name) {
return new Person(name, 18);
}
}
使用方式
Person person = new Person("John", 30);
// Person person = Person.of("John");
String name = person.name();
int age = person.age();
使用場景
通過Record 構建一個臨時存儲對象,將 Person 數組對象按照年齡排序。
public List<Person> sortPeopleByAge(List<Person> people) {
record Data(Person person, int age){};
return people.stream()
.map(person -> new Data(person, computAge(person)))
.sorted((d1, d2) -> Integer.compare(d2.age(), d1.age()))
.map(Data::person)
.collect(toList());
}
public int computAge(Person person) {
return person.age() - 1;
}
3.1.8 密封類
Java 17推出的新特性密封類(Sealed Classes),主要作用就是限制類的繼承。我們知道之前對類繼承功能的限制主要有兩種:
-
final修飾類,這樣類就無法被繼承了;
-
package-private類,可以控制只能被同一個包下的類繼承;
但很顯然,這兩種限制方式的力度都非常粗,而密封類正是對類繼承的更細粒度的控制。
sealed class SealedClass permits SubClass1, SubClass2 {
}
class SubClass1 extends SealedClass {
}
class SubClass2 extends SealedClass {
}
在上面的示例中,SealedClass是一個密封類,它包含兩個子類SubClass1和SubClass2。在SubClass1和SubClass2的定義中,必須使用extends關鍵字來繼承自SealedClass,並且使用permits關鍵字來指定它們允許哪些子類來繼承。通過使用密封類,可以確保只有符合特定條件的子類才能繼承或實現該協議或規範。
3.2 方法定義
3.2.1 構造方法
構造方法是一種特殊的方法,用於創建和初始化對象。構造方法的名稱必須與類名相同,並且沒有返回類型。在創建對象時,可以通過使用 new 關鍵字來調用構造方法。
public class MyClass {
private int myInt;
private String myString;
// 構造方法
public MyClass(int myInt, String myString) {
this.myInt = myInt;
this.myString = myString;
}
}
實現單例模式的一個重要特性就是不允許用戶隨意創建(new)對象,如何做到安全控制呢?將構造方法聲明為私有(private)是必不可少的一步。
3.2.2 方法重寫
方法重寫是指在子類中重新定義與父類中同名的方法。方法重寫允許子類覆蓋父類中的方法實現,以便根據子類的需要實現其自己的行為。
class Animal {
public void makeSound() {
System.out.println("Animal is making a sound");
}
}
class Cat extends Animal {
@Override
public void makeSound() {
System.out.println("Meow");
}
}
public class Main {
public static void main(String[] args) {
Animal myCat = new Cat();
myCat.makeSound(); // 輸出 "Meow"
}
}
面向對象的三大特性之一的多態,方法重寫是其核心。
3.2.3 方法重載
類中定義多個方法,它們具有相同的名稱但參數列表不同。方法重載允許我們使用同一個方法名執行不同的操作,根據傳遞給方法的參數不同來執行不同的代碼邏輯。
public class Calculator {
public int add(int a, int b) {
return a + b;
}
public double add(double a, double b) {
return a + b;
}
}
public class Main {
public static void main(String[] args) {
Calculator calculator = new Calculator();
int result1 = calculator.add(2, 3);
double result2 = calculator.add(2.5, 3.5);
System.out.println(result1); // 輸出 5
System.out.println(result2); // 輸出 6.0
}
}
3.2.4 匿名方法
Java 8 引入了 Lambda 表達式,可以用來實現類似匿名方法的功能。Lambda 表達式是一種匿名函數,可以作為參數傳遞給方法,或者直接作為一個獨立表達式使用。
public static void main(String args[]) {
List<String> names = Arrays.asList("hello", "world");
// 使用 Lambda 表達式作為參數傳遞給 forEach 方法
names.forEach((String name) -> System.out.println("Name: " + name));
// 使用 Lambda 表達式作為獨立表達式使用
Predicate<String> nameLengthGreaterThan5 = (String name) -> name.length() > 5;
boolean isLongName = nameLengthGreaterThan5.test("John");
System.out.println("Is long name? " + isLongName);
}
3.3 對象定義
3.3.1 單例對象
單例對象是一種可以重覆使用的對象,但只有一個實例。它有以下幾個作用:
-
控制資源的使用:通過線程同步來控制資源的併發訪問。
-
控制實例產生的數量:達到節約資源的目的。
-
作為通信媒介使用:也就是數據共用,它可以在不建立直接關聯的條件下,讓多個不相關的兩個線程或者進程之間實現通信。
比如,使用枚舉實現單例模式:
public enum Singleton {
INSTANCE;
public void someMethod() {
// ...其他代碼...
}
}
3.3.2 不可變對象
Java中的不可變對象是指那些一旦被創建,其狀態就不能被修改的對象。不可變對象是一種非常有用的對象,因為它們可以確保對象的狀態在任何時候都是一致的,從而避免了因為修改對象狀態而引發的問題。實現不可變對象有以下幾種方式:
-
將對象的狀態存儲在不可變對象中:String、Integer等就是內置的不可變對象類型;
-
將對象的狀態存儲在final變數中:final變數一旦被賦值就不能被修改;
-
將對象的所有屬性都設為不可變對象:這樣就可以確保整個對象都是不可變的;
一些容器類的操作也有對應的包裝類實現容器對象的不可變,比如定義不可變數組對象:
Collections.unmodifiableList(new ArrayList<>());
當領域內的對象作為入參往外傳遞時,將其定義為不可變對象,這在保持數據一致性方面非常重要,否則對象屬性變更的不可預測性,在進行問題定位時,將會非常麻煩。
3.3.3 元組對象
元組(Tuple)是函數式編程語言中的常見概念,元組是一個不可變,並且能夠以類型安全的形式保存多個不同類型的對象。它是一種非常有用的數據結構,可以讓開發者在處理多個數據元素時更加方便和高效。但原生的Java標準庫並沒有提供元組的支持,需要我們自己或藉助第三方類庫來實現。
二元組實現
public class Pair<A,B> {
public final A first;
public final B second;
public Pair(A a, B b) {
this.first = a;
this.second = b;
}
public A getFirst() {
return first;
}
public B getSecond() {
return second;
}
}
三元組實現
public class Triplet<A,B,C> extends Pair<A,B>{
public final C third;
public Triplet(A a, B b, C c) {
super(a, b);
this.third = c;
}
public C getThird() {
return third;
}
public static void main(String[] args) {
// 表示姓名,性別,年齡
Triplet<String,String,Integer> triplet = new Triplet("John","男",18);
// 獲得姓名
String name = triplet.getFirst();
}
}
多元組實現
public class Tuple<E> {
private final E[] elements;
public Tuple(E... elements) {
this.elements = elements;
}
public E get(int index) {
return elements[index];
}
public int size() {
return elements.length;
}
public static void main(String[] args) {
// 表示姓名,性別,年齡
Tuple<String> tuple = new Tuple<>("John", "男", "18");
// 獲得姓名
String name = tuple.get(0);
}
}
Tuple主要有以下幾個功能:
1. 存儲多個數據元素:Tuple可以存儲多個不同類型的數據元素,這些元素可以是基本類型、對象類型、數組等;
2. 簡化代碼:Tuple可以使代碼更加簡潔,減少重覆代碼的編寫。通過Tuple,我們可以將多個變數打包成一個對象,從而減少了代碼量;
3. 提高代碼可讀性:Tuple可以提高代碼的可讀性。通過Tuple,我們可以將多個變數打包成一個對象,從而使代碼更加易讀;
4. 支持函數返回多個值:Tuple可以支持函數返回多個值。在Java中,函數只能返回一個值,但是通過Tuple,我們可以將多個值打包成一個對象返回;
除了自定義之外,實現了元組概念的第三方類庫有:Google Guava,Apache Commons Lang,JCTools,Vavr等。
Google Guava庫的Tuple提供了更多的功能,並且被廣泛使用。比如,為了使元組的含義更加明確,Guava提供了命名元組(NamedTuple)的概念。通過給元組命名,可以更清晰地表示每個元素的意義。示例:
NamedTuple namedTuple = Tuples.named("person", "name", "age");
3.3.4 臨時對象
臨時對象是指在程式執行過程中臨時需要,但生命周期較短的對象。這些對象通常只在使用過程中短暫存在,不需要長期存儲或重覆使用。
關於臨時對象的優化建議如下:
-
儘量重用對象。由於系統不僅要花時間生成對象,以後可能還需花時間對這些對象進行垃圾回收和處理,因此,生成過多的對象將會給程式的性能帶來很大的影響,重用對象的策略有緩存對象,也可以針對具體場景進行定向優化,比如使用StringBuffer代替字元串拼接的方式;
-
儘量使用局部變數。調用方法時傳遞的參數以及在調用中創建的臨時變數都保存在棧中,速度較快。其他變數,如靜態變數、實例變數等,都在堆中創建,速度較慢;
-
分代收集。分代垃圾回收策略,是基於這樣一個事實:不同的對象的生命周期是不一樣的。因此,不同生命周期的對象可以採取不同的收集方式,以便提高回收效率;
3.3.5 Valhalla
Java作為高級語言,和更為底層的C語言,彙編語言在性能方面一直存在著不小的差距。為了彌補這一差距,Valhalla 項目於 2014 年啟動,目標是為基於 JVM 的語言帶來更靈活的扁平化數據類型。
我們都知道Java支持原生類型和引用類型兩種。原生數據類型按值傳遞,賦值和函數傳參都會把值給複製一份,複製之後兩份之間就再無關聯; 引用類型無論什麼情況傳的都是指針,修改指針指向的內容會影響到所有的引用。而Valhalla又引入了值類型(value types),一種介於原生類型和引用類型之間的概念。
由於應用程式中的大多數Java數據結構都是對象,因此我們可以將Java視為指針密集型語言。這種基於指針的對象實現用於啟用對象標識,對象標識本身用於語言特性,如多態性、可變性和鎖定。預設情況下,這些特性適用於每個對象,無論它們是否真的需要。這就是值類型(value types)發揮作用的地方。
值類型(value types)的概念是表示純數據聚合,這會刪除常規對象的功能。因此,我們有純數據,沒有身份。當然,這意味著我們也失去了使用對象標識可以實現的功能。由於我們不再有對象標識,我們可以放棄指針,改變值類型的一般記憶體佈局。讓我們來比較一下對象引用和值類型記憶體佈局。
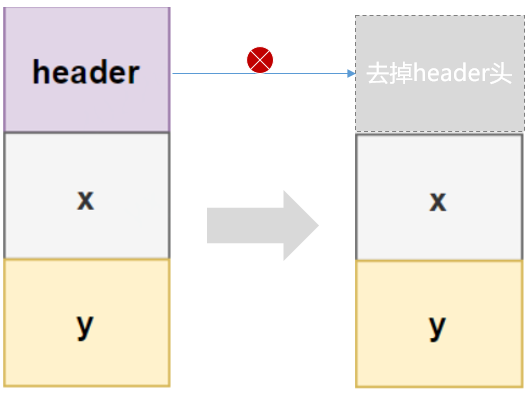
去掉了對象頭信息,在64位操作系統中值類型節約了對象頭16個位元組的空間。同時,也意味著放棄對象唯一身份(Identity)和初始化安全性,之前的wait(),notify(),synchronized(obj),System.identityHashCode(obj)等關鍵字或方法都將失效,無法使用。
Valhalla 在提高性能和減少泄漏的抽象方面將會顯著提高:
• 性能增強通過展平對象圖和移除間接來解決。這將獲得更高效的記憶體佈局和更少的分配和垃圾回收。
• 當用作泛型類型時,原語和對象具有更相似的行為,這是更好的抽象。
截止到2023年9月,Valhalla 項目仍在進行中,還沒有正式版本的發佈,這一創新項目值得期待的。
四 總結
本文總結了軟體開發過程中經常用到的基礎常識,分為基礎篇和實踐篇兩個篇章,其中基礎篇中著重講述了類,方法,變數的命名規範以及代碼註釋好壞的評判標準。實踐篇中從類,方法以及對象三個層面分析了常見的技術概念和落地實踐,希望這些常識能夠為讀者帶來一些思考和幫助。
作者:京東零售 劉慧卿
來源:京東雲開發者社區 轉載請註明來源


