
小程式平臺是怎麼保證商家業務的穩定、健康發展,服務好這些外部商家的呢?這裡面非常重要的是我們平臺對小程式基本流量的運營與監控。如何不讓業務的小程式線上上裸奔?如何幫助業務對自身小程式流量的沖高回落有一種直觀的把握和監測?如何基於海量數據指導業務去進行一個精細化的運營?實際上,京東小程式數據中心就扮演... ...
一、京東小程式是什麼
京東小程式平臺能夠提供開放、安全的產品,成為品牌開發者鏈接京東內部核心產品的橋梁,致力於服務每一個信任我們的外部開發者,為不同開發能力的品牌商家提供合適的服務和產品,讓技術開放成為品牌的新機會。“Once Build, Run Anywhere”,一個小程式可以在多個APP運行,引擎層抹平差異,一套代碼,相同頁面,雲端下發,多端運行。
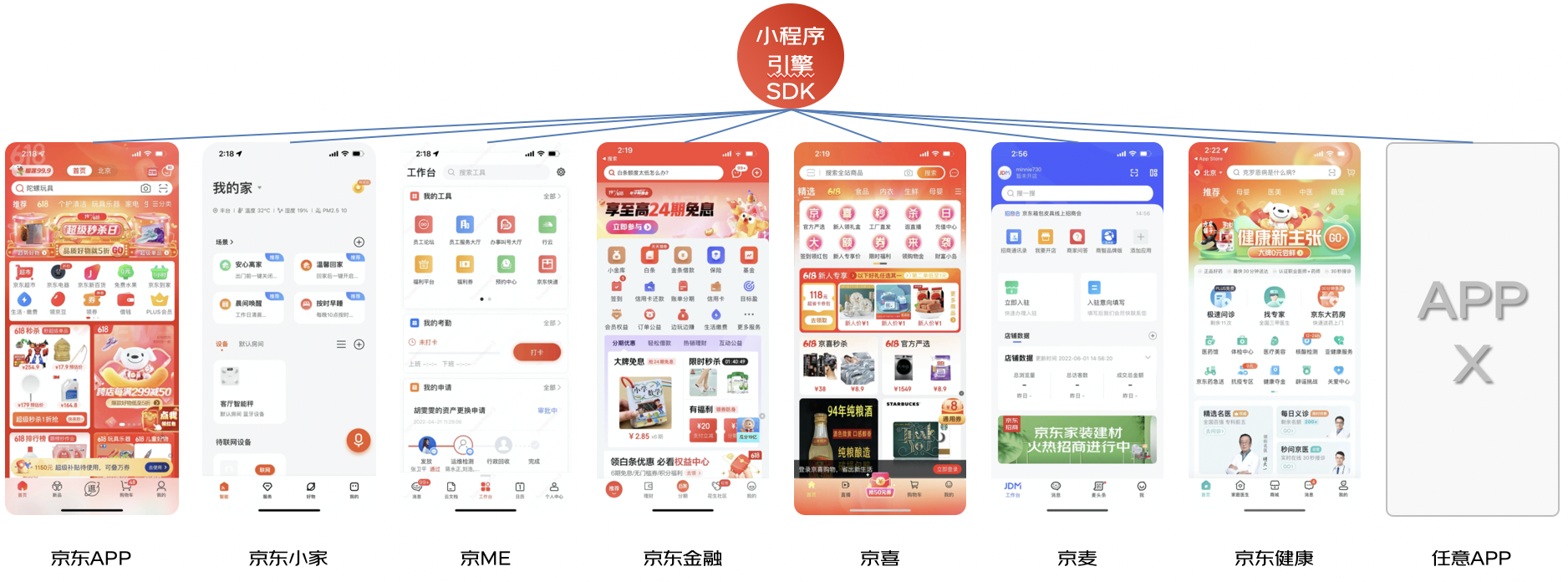
可能大家還不太瞭解我們的京東小程式,京東小程式到底是什麼呢?它和微信小程式有什麼區別?首先呢,需要明確的是,京東小程式不是運行在微信端的京東商城購物小程式,而是運行在京東APP的,基於京東小程式引擎的一套京東系的小程式。
它是和支付寶小程式或者微信小程式對標的一類京東化的小程式。
舉個例子,大家可以體驗一下,比如在主站搜索寶格麗,會通過搜索直達直接跳轉到寶格麗小程式上,我們可以在這裡購買奢侈品,或者在首頁的同城Tab頁下,可以瀏覽到非常多的到家門店類的小程式,總之,京東小程式所覆蓋的業務還是極其廣泛的!
當然,京東小程式不僅僅可以運行在京東APP上,只要宿主在運行時依賴了我們的小程式SDK引擎,就可以實現在各類其他宿主APP上的運行,譬如,在京東小家APP上,可以通過小程式去控制智能IOT設備,在京ME的APP上,可以遠程操作印表機,實現一鍵列印。小程式作為一種輕量級的即用即走的工具,用戶群體廣泛,早已覆蓋到了我們生活的方方面面。
京東小程式是鏈接商家和京東內部核心產品的重要橋梁,也是助力商家實現流量增長、業務發展的一個重要方式。
那麼,小程式平臺是怎麼保證商家業務的穩定、健康發展,服務好這些外部商家的呢?這裡面非常重要的是我們平臺對小程式基本流量的運營與監控。如何不讓業務的小程式線上上裸奔?如何幫助業務對自身小程式流量的沖高回落有一種直觀的把握和監測?如何基於海量數據指導業務去進行一個精細化的運營?實際上,京東小程式數據中心就扮演了一個這樣的小程式數據問題終結者的角色,充分利用各類數據手段,解決這些痛點問題。
二、京東小程式數據中心建設里程碑
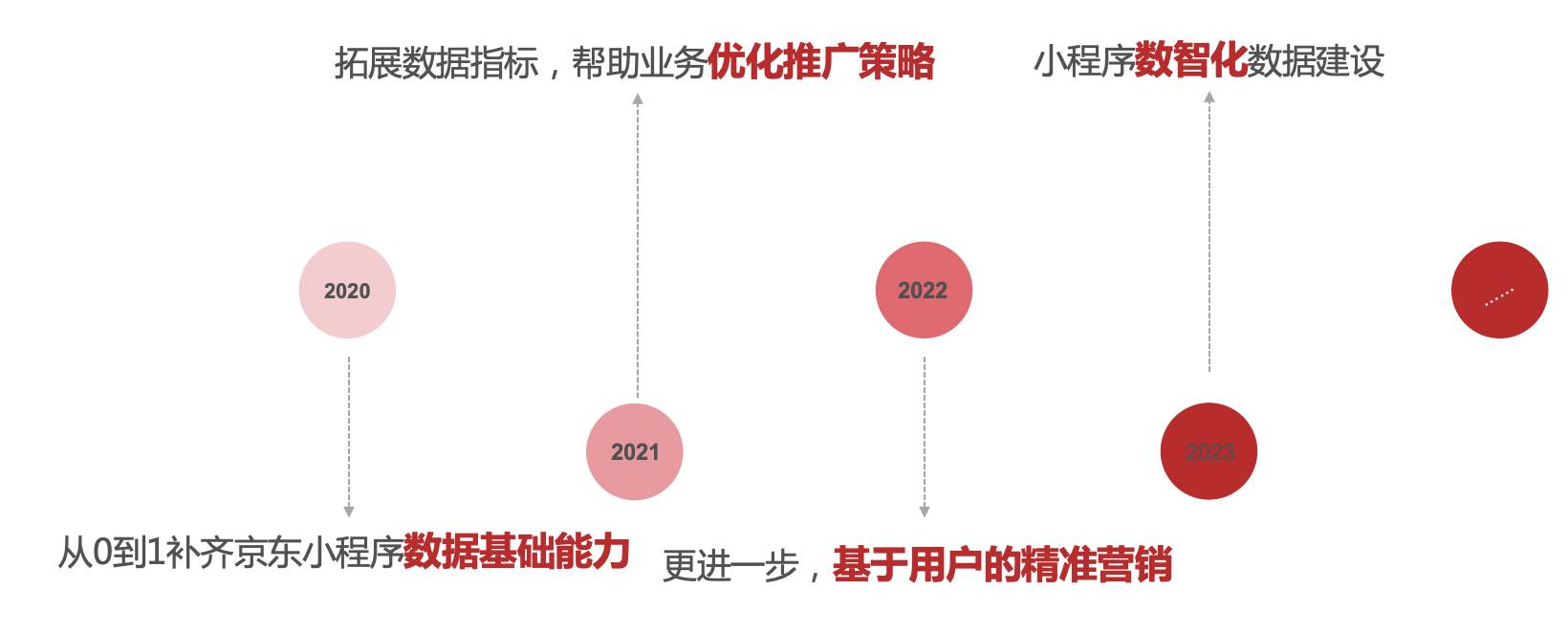
京東小程式數據中心的建設,主要經歷了四個階段,從最開始的由0到1搭建了數據基礎能力,到豐富拓展各類數據指標,接著下鑽分析到用戶,幫助商家實現基於用戶的精細化的運營,到目前的小程式數智化建設,在整個小程式的迭代建設的過程中,都從各個維度為小程式的業務發展實現了保駕護航。
三、京東小程式數據中心業務全景圖
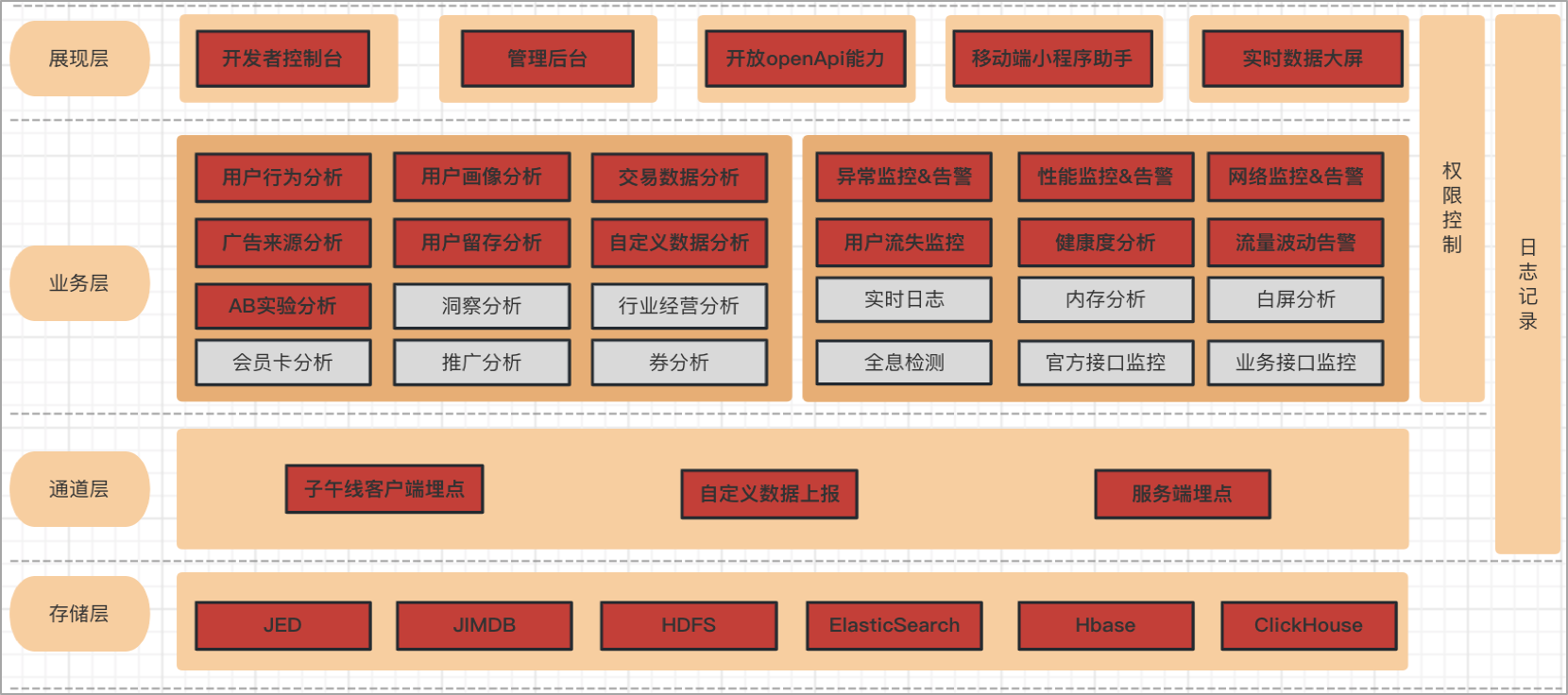
- 從功能角度,京東小程式運營數據分析,京東小程式監控數據分析;
- 從展現角度,開發者控制台,管理後臺,移動端小程式助手,宙斯開放能力;
- 從功能領域角度,用戶行為分析,交易鏈路數據分析,用戶畫像,流失率監控,流量監控等;
- 從上報通道角度,子午線,自定義上報,服務端埋點;
- 從數據存儲角度,JED,JimDB,ES,HBase等;
目前京東小程式數據中心功能範圍廣泛,我們在根據業務發展的需求,不斷完善整個京東小程式數據中心的功能架構。
從展現角度看,包括開發者控制台,管理後臺,移動端小程式助手,實時數據大屏, 開放openApi能力;
其次是從功能領域角度看,主要包括運營數據分析,監控數據分析。
運營數據分析,包括用戶行為分析,比如小程式基礎的pv和uv;
來源分析,可以去分析小程式在各個廣告投放渠道下的營銷轉化效果;
用戶畫像分析,可以分析到瀏覽過小程式的人群中的哪些是高凈值用戶群體,以及性別以及年齡等基礎的用戶畫像數據。
監控數據分析,主要是針對線上運行的小程式的奔潰異常,網路請求異常,啟動性能數據的分析,用戶流失率的實時監測等,可以在小程式出現異常時第一時間通知到開發者。
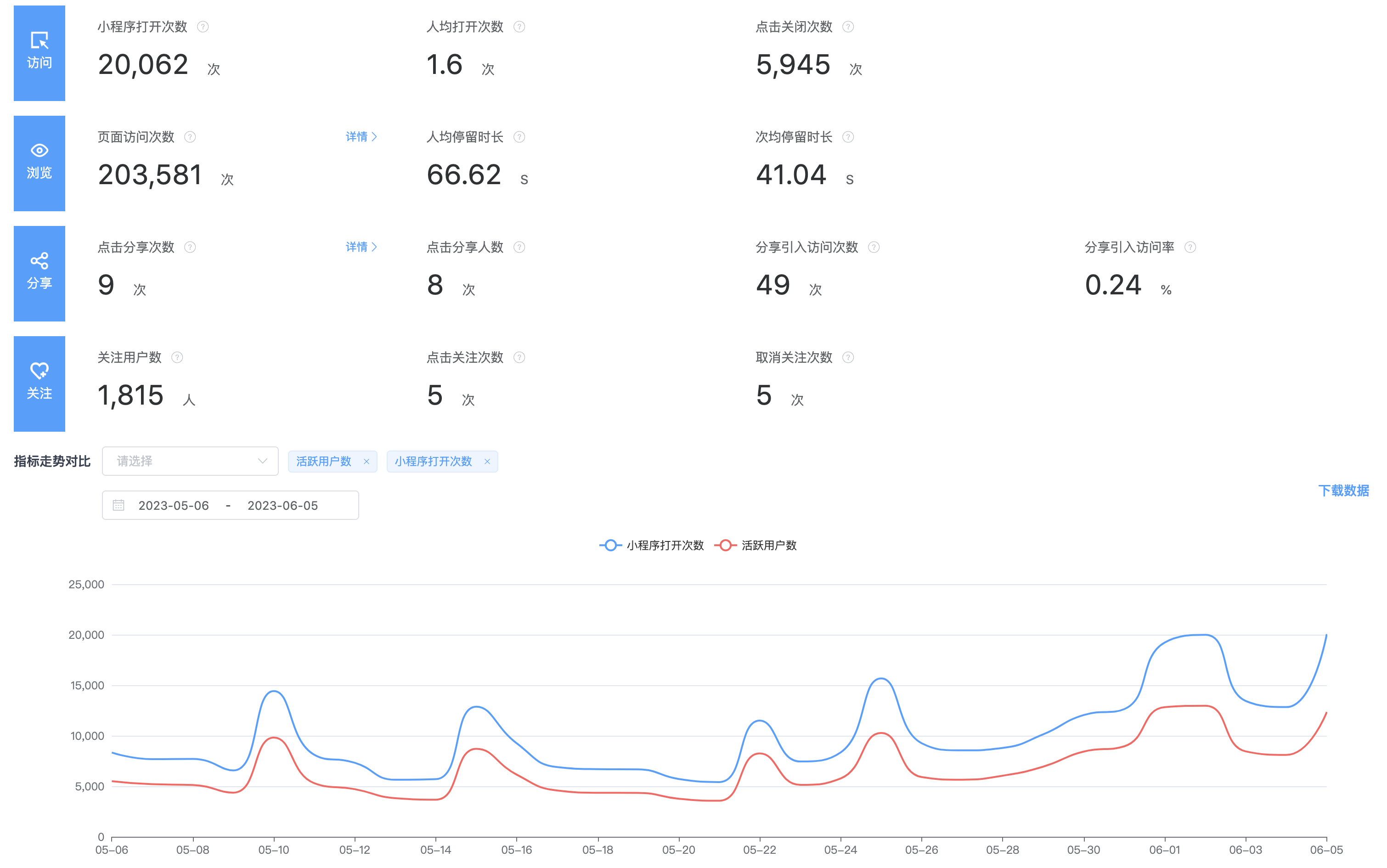
四、京東小程式數據中心技術架構圖
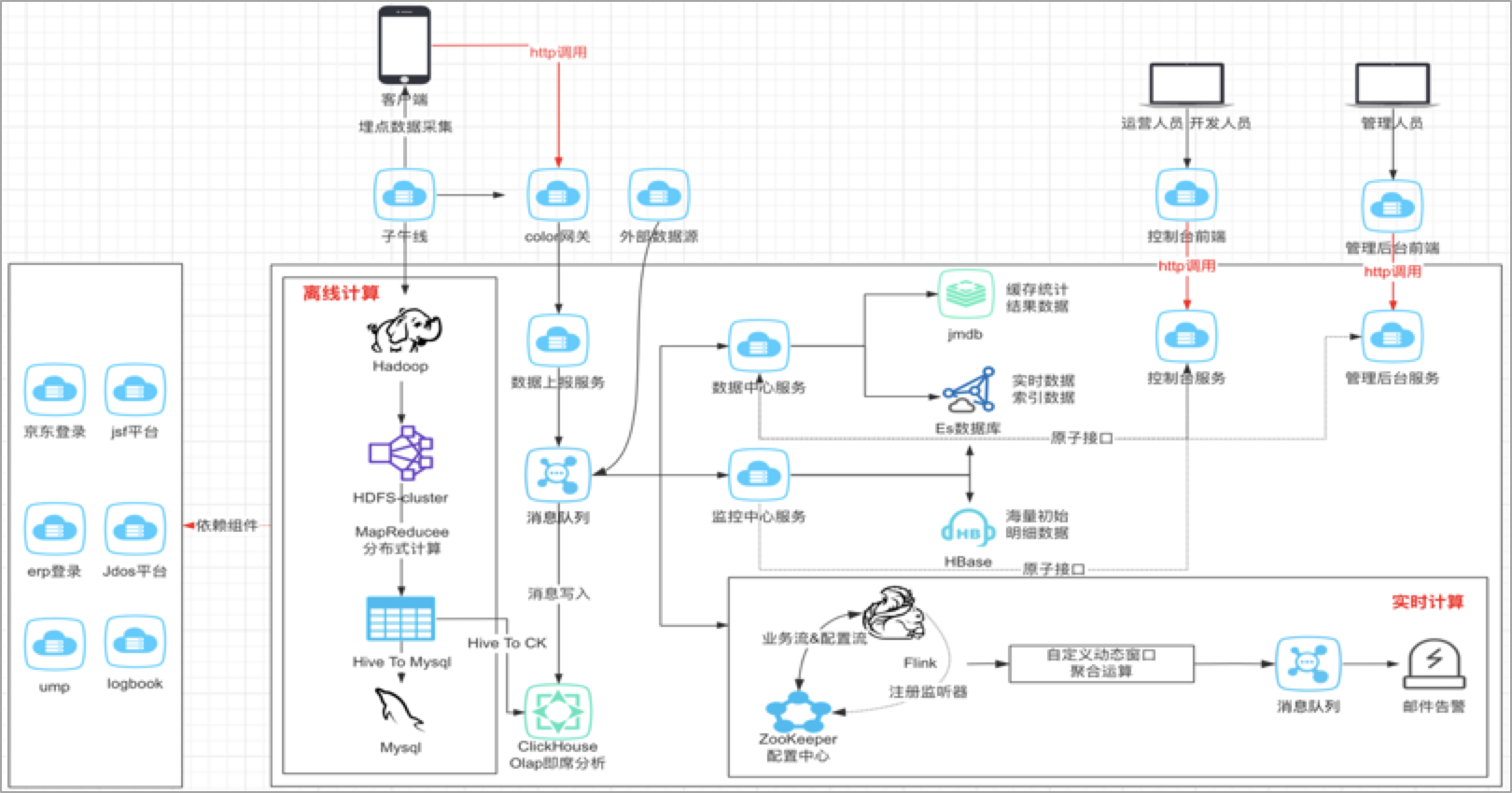
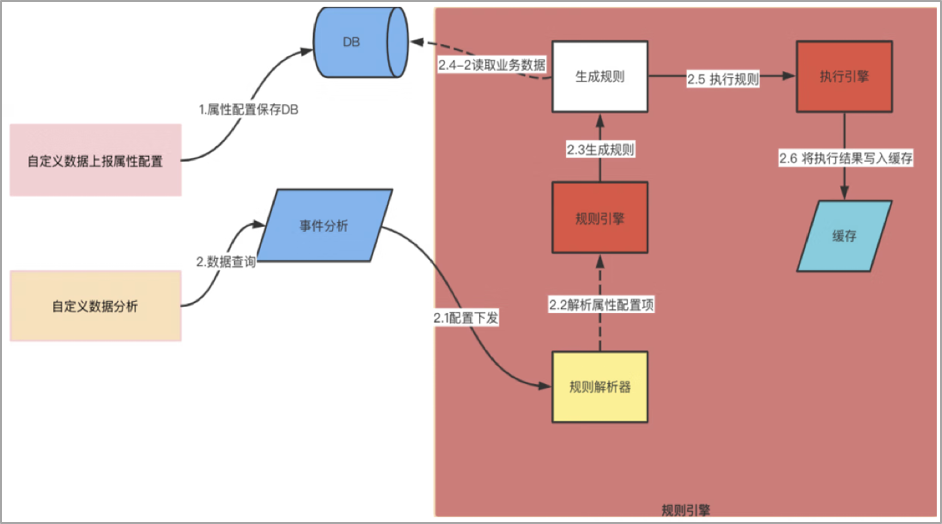
對於整體的架構設計,其實在我看來,數據的分析,主要是解決三個問題,第一個要解決的是數據如何上報的問題,第二個是解決數據如何存儲的問題?第三個才是解決數據如何分析的問題?
1、京東小程式數據中心的數據上報主要包括三個途徑,主要包括客戶端埋點,服務端埋點或者其他外部的數據源,客戶端埋點主要利用的是子午線,服務端埋點主要是我們服務之間採集數據,服務之間消費和同步。
2、數據存到哪裡去,這個需要基於我們業務上對這些數據的實時性要求,判斷是實時還是離線,進而採用不同的數據源進行存儲,數據指標是要秒級的?分鐘級的?還是T+1l類型的,實時性要求不同,那麼存儲的數據源自然也就不同。
3、數據如何分析,實際上就是我們的業務邏輯,在設計時也需要充分考慮數據模型的復用性和可拓展性。
小程式數據中心對於來自子午線客戶端埋點數據,以離線的方式構建小程式自己的業務數倉,一層一層地進行數據的降噪,清洗和計算,將聚合好的維度數據再推送到關係型資料庫,方便業務快速接入。對於來自自建通道的實時數據以及外部系統的埋點數據,通過統一上報服務將數據上報到消息隊列,進行流量數據的非同步處理和消峰,採用專門的消費者服務對上報數據進行消費落庫,存儲到ES和HBase資料庫,便於平臺進行多維度的明細或者彙總數據查詢;同時,也會基於Flink對消息隊列中的數據進行流式實時計算,實現異常波動流量的告警和分析。
五、它山之石可以攻玉,藉助集團數據工具打造小程式業務數倉
痛點問題:
1.京東小程式的數據來源多樣化,數據量級龐大,如何立足業務數據,發揮數據價值,幫助商家實現精細化的運營?
2.如何復用主站已有的數據模型和能力,讓更多的小程式商家參與到京東主站的流量場,讓數據驅動商家精準營銷?
3.業務指標紛繁複雜,如何沉澱和抽離通用數據模型,減少重覆工作?
如何解決:
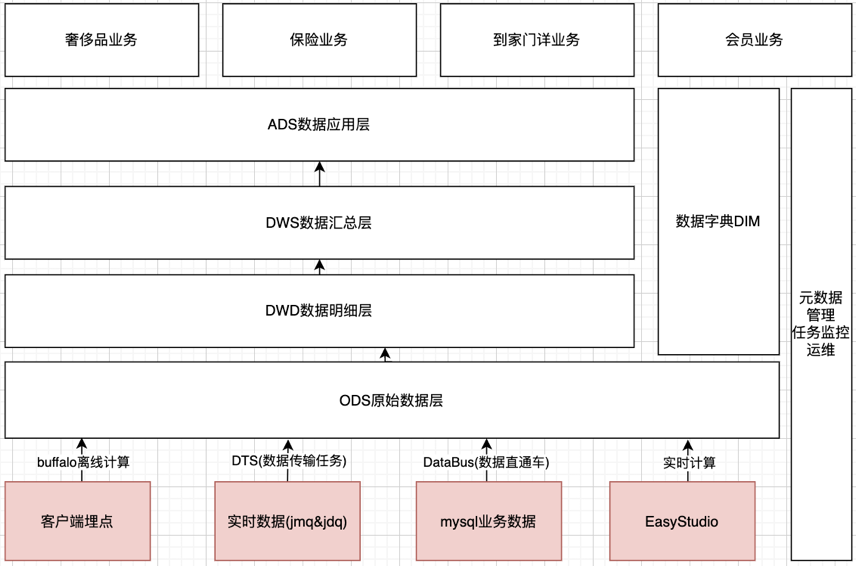
基於集團BDP平臺,自上而下構建京東小程式的業務數倉,藉助BDP平臺豐富的數據產品工具,多維度地構建小程式的數據能力。離線計算+實時計算相結合,小程式業務數據+集團模型數據相結合。
1.數據分類化,將小程式流量進行主題劃分,拆分為點擊、瀏覽、曝光、訂單等大維度的主題模型,方便數據定位,增加業務理解;
2.數據分層化,同一個流量主題下,進一步按照ODS->DWD->DWS->ADS的層級結構進行分層,方便追蹤數據血緣,減少重覆數據模型的開發;
3.數據多元化,下游系統可從小程式數據倉庫拉取符合業務需要的領域數據,比如數紡,搜推廣等系統,利用下游系統成熟穩定的數據能力,為商家營銷充分賦能;
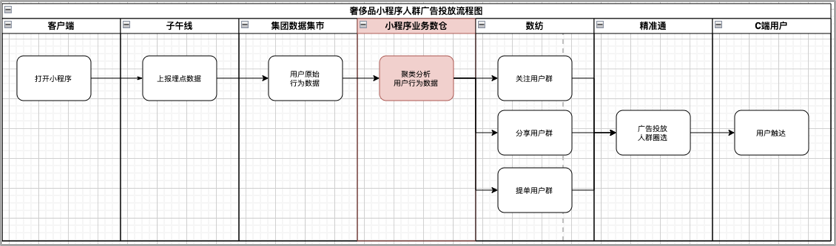
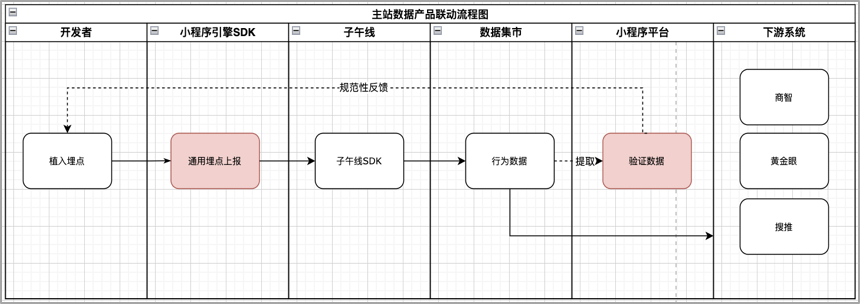
在京東小程式的業務數倉搭建過程中,主要還是應用了集團BDP大數據平臺提供的豐富的產品工具和通用能力。
幾種典型的使用案例是:
1、離線hive表數據同步到jed等關係型業務庫,使用buffalo任務中的出庫運算元;
2、業務產生的實時MQ數據同步到hive數倉,使用DTS,實時數據傳輸任務,可以把業務數據同步到數倉;
3、我們需要在數倉中構建業務維表,比如構建小程式基本信息的維表,業務數據需要同步到hive表,可以採用數據直通車DataBus,在表記錄的生成上,可以根據業務的需要,採用全量表,增量表,快照表,拉鏈表或者流水錶的不同的記錄生成方式。
京東小程式客戶端埋點統一上報的子午線,需要從最原始的gdm層底表提取小程式自己的業務數據,原始底表數據量級非常大,不可能每次直接對原始底表查詢,這樣的話耗費計算資源,效率較低。所以,我們儘量提高底層數據模型的復用度,對數據進行分類化和分層化處理。
所謂分類話,就是將小程式流量進行主題劃分,拆分為點擊、瀏覽、曝光、訂單等大維度的主題模型,方便數據定位,增加業務理解;
所謂分層化,就是在同一個流量主題下,進一步按照ODS->DWD->DWS->ADS的層級結構進行數據分層,方便追蹤數據血緣,減少重覆數據模型的開發。
所謂多元化,就是復用度,加工好的這些數據,可以給下游的團隊接入使用,比如商智,黃金眼,數紡這些團隊。以小程式廣告投放為例,在小程式數倉中我們構建了各個類型的用戶群體,在數紡註冊了用戶群體標簽,比如關註用戶,粉絲用戶或者提單用戶等,下游的廣告精準通系統會基於我們的這些標簽進行人群的圈選,進而實現小程式廣告的投放。
總之,根據業務特點,充分利用好集團BDP的數據工具,幫助我們實現數倉的搭建。
六、基於FLINK實時計算,落地小程式異常奔潰監控利器
痛點問題:京東小程式線上上運行時,需要實時監測到小程式的業務代碼崩潰異常、性能數據波動,網路請求耗時等,在有異常崩潰的情況下,保證可以第一時間通知到商家開發者,幫助業務及時止損。
如何解決:
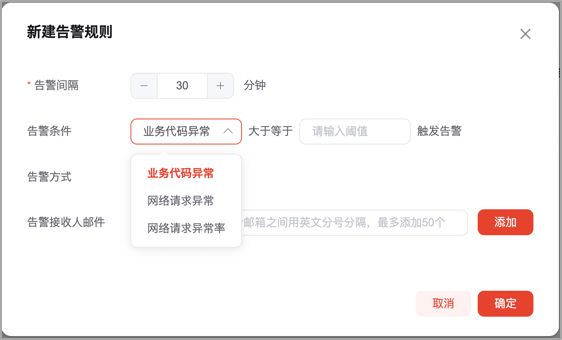
1.報警規則可配置,基於Zookeeper分散式配置中心存儲小程式自定義的告警規則,實時監聽規則節點變化,當節點數據變化時,實時聚合到業務流;
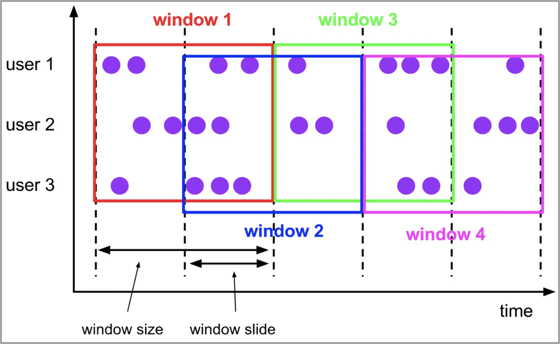
2.自定義滑動視窗,每個小程式的告警視窗大小不一樣,拓展實現WindowAssigner,基於用戶動態規則確定告警視窗開始時間和截止時間;
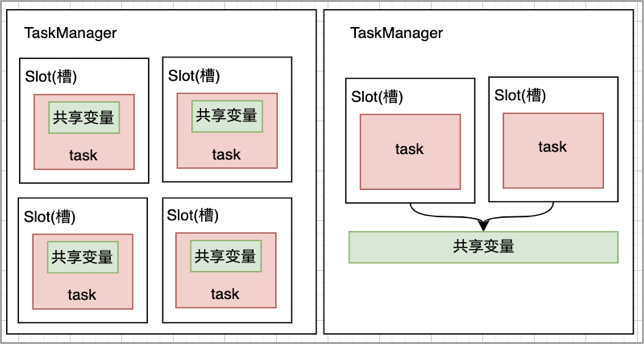
3.廣播變數,broadcast機制,將告警配置信息廣播到各個Task任務記憶體,廣播變數就是一個公共的共用變數,將一個數據集廣播後,不同的Task都可以在節點上獲取到,每個節點只存一份,否則,每一個Task都會拷貝一份數據集,會造成記憶體資源浪費。
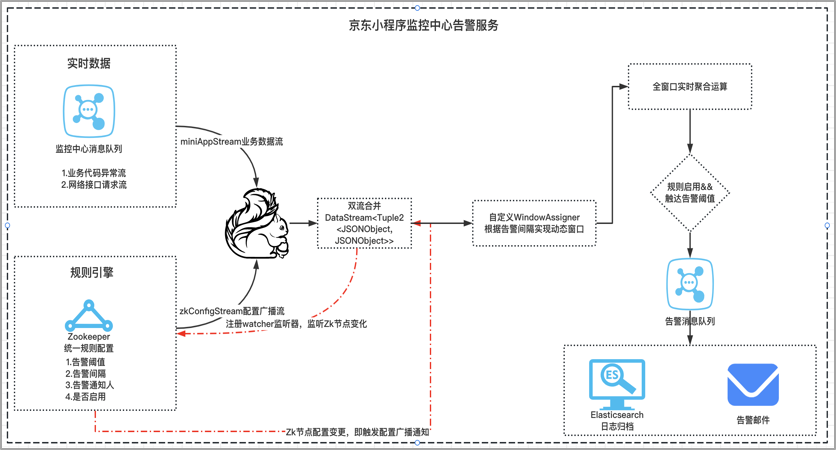
對於小程式的實時監控能力,我們採用flink作為實時計算的框架,小程式線上上運行時,需要實時監測到小程式的業務代碼崩潰異常、這種異常很可能會導致小程式白屏或者閃退,需要在探測到有異常崩潰的情況下,保證第一時間通知到商家開發者,幫助業務及時止損。
這裡的難點在於告警的規則是支持用戶自定義的,比如配置觀測多長時間視窗內的異常數據,當達到多少的異常閾值,應該去觸發告警,應該判定為異常,這裡是需要把告警規則配置的的主動權交給用戶的,在這樣的背景下,
1、 我們採用的是將告警規則放到分散式的統一配置中心,實時監聽節點規則的變化,將業務流和規則流進行connet雙流合併;
2、 然後根據告警規則,實現windowAssigner生成自定義的動態計算視窗,從而實現視窗動態化;
3、 最後,採用廣播變數的broadcast機制,當告警規則變更時,可以高效地將告警配置廣播刷新到各個Task任務記憶體,提高資源利用率,保證計算時效性。
七、探索OLAP領域的黑馬,基於ClickHouse搭建自定義數據分析引擎
痛點問題:小程式內部的數據波動如何自由埋點分析?京東內部業務直接基於子午線埋點上報,業務團隊內部自行分析;外部的開發者需要依賴神策,GA等外部的分析系統,無法將數據迴流京東,且復用京東現有流量工具進行精細化運營。
如何解決:
1.選擇合適的表存儲引擎:採用多副本的ReplicatedMergeTree,保證查詢性能和數據存儲的高可用;
2.按天分區存儲數據: PARTITION BY:分區鍵,PARTITION BY toYYYYMMDD(EventDate),不同分區下的數據會分開存儲,合理建立分區可以加快查詢的速度;
3.統一上報協議:生成全局唯一事件ID,事件ID綁定業務數據;
4.動態數據解析:基於visitParamExtract函數解析json動態業務數據;
5.查詢腳本下推:Sql引擎生成查詢Sql,下沉至ClickHouse完成查詢;
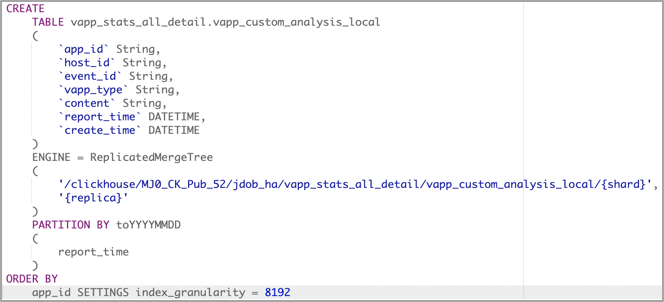
小程式內部的數據波動如何自由埋點分析?京東內部業務是可以直接基於子午線埋點上報,業務團隊內部自行分析,但是子午線這種產品本身不對外開放,外部的開發者如果想分析小程式自身的內部數據,需要依賴神策,GA等外部的數據分析系統,這樣的話,小程式的數據無法迴流京東,那麼也就無法復用京東現有流量工具進行小程式的精細化運營。
在這樣的背景下,我們落地了小程式的自定義分析引擎,底層採用了clickhouse這種適合做即席查詢的olap引擎,用來存儲小程式上報數據.
為什麼採用clickhouse? clickhouse是基於列式來存儲數據,查詢性能非常高,在億級數據的體量下,可以做到秒級的響應,適合做線上的OLAP。
同時,ck支持水平的拓展,適合大數據量的存儲,支持按天進行數據的分區存儲,在建表時,根據記錄的創建時間劃分partition,在查詢數據時,可以只查某些partition分區的數據,也可以加快查詢的效率。
包括本地表和分散式表,本地表運行在各個具體的數據節點,分散式表負責數據的轉發和路由。寫入數據只寫本地表,50-200M/S ,對於大量的數據更新非常實用。
在小程式自定義分析引擎中,規範了數據上報協議,首先由用戶配置需要上報的事件ID和業務指標,按照協議約定調用前端jsAPI上報業務數據。在自助查詢區域,當用戶觸發查詢時,先基於規則引擎利用自定義事件ID生成查詢規則SQL腳本,將規則下推至服務端執行引擎,執行引擎從CK獲取業務數據,完成業務數據的一次自定義查詢。
八、巧用Elasticsearch特性,讓用戶行為分析不再困難
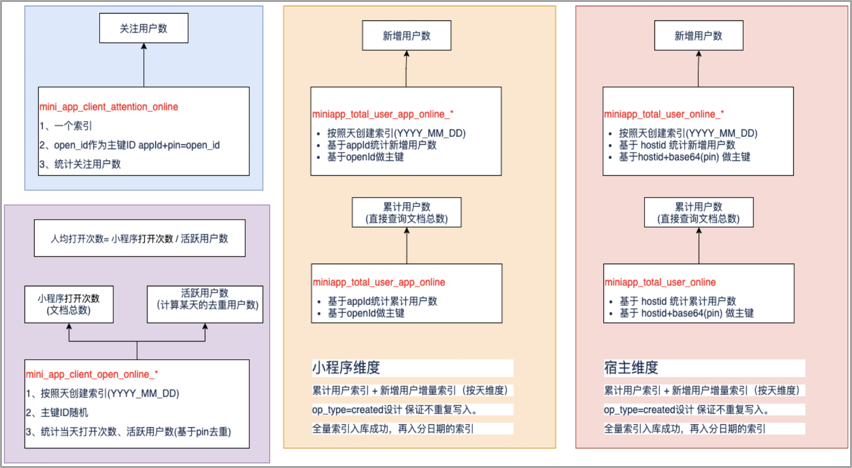
痛點問題:需要實時分析小程式的pv、uv、新增用戶數、累計用戶數以及關註用戶數等用戶行為類指標,幫助小程式商家掌握自身小程式的用戶波動情況。
如何解決:
1.實時性,從小程式的用戶行為埋點數據上報到可訪問,支持秒級響應;
2.全文檢索,基於倒排索引,支持靈活的搜索分析,支持按照小程式不同業務維度進行聚合分析,滿足不同的業務需要;
3.易於運維,小程式的日均DAU在300W+,可以基於天、月等維度創建索引,方便進行冷熱數據分析;
創建ES模板: 周期性按天創建ES索引:

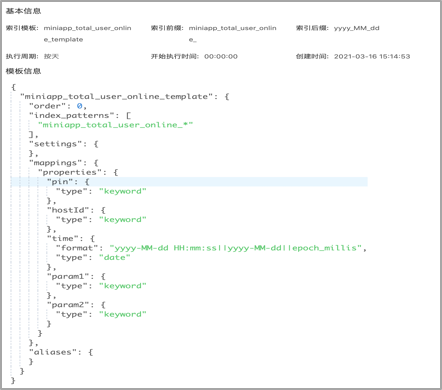
利用索引主鍵碰撞實現新增&累計用戶統計:
語法:
index語法: PUT miniapps/_doc/1
create語法: PUT miniapps/_create/1
語義:
index自動生成id,多次創建,會生成多個document;
index多次索引同一個id,會刪除重建,版本號一直++,上個版本刪除,保留最新版本;
create自動生成id,多次創建,會生成多個document;
create的重覆創建指定文檔id的內容,第二次執行創建會報錯(主鍵碰撞),而不是版本號++;
我們是如何做小程式的實時用戶行為分析的呢?行為分析需要實時計算小程式的pv、uv、新增用戶數、累計用戶數以及關註用戶數等用戶行為類指標,幫助小程式商家掌握自身小程式的用戶波動情況。我們將這些數據統一放在ES中進行查詢,主要考慮到ES支持靈活的搜索分析,支持按照不同維度進行聚合分析,保證了數據查詢的靈活性和實時性的需要。
在創建索引時,不是將數據都堆放到一個索引,而是將按天去創建,基於索引模板,周期性地創建ES索引,保證索引查詢效率。
在構建小程式的新增用戶的指標時,利用了ES索引碰撞的原理,設置操作類型operateType為create,create的語義是重覆創建指定文檔id的內容,第二次執行創建會報錯(出現主鍵碰撞),這樣的話,保證新增用戶的記錄在ES索引中只出現一次。
九、不足和展望
1、沉澱小程式行業數據解決方案
沉澱比如車企、保險、3C家電等行業類數據,形成統一的京東小程式行業數據解決方案
2、技術沉澱復用
後續可以把成型的京東小程式數據分析技術方案推廣到其他技術棧,比如RN等平臺系統
3、智能化建設
考慮如何基於機器學習、人工智慧、ChatGPT等技術手段,加強京東小程式數據的智能化建設,如何結合機器學習、深度學習、人工智慧AI等技術手段,繼續實現京東小程式數據中心的智能化建設。
- 預測性分析能力:
小程式的智能告警,基於時間序列預測演算法,比如Facebook Prophet演算法等,做一些告警預判,提升告警的智能性和準確率;
- 數據挖掘演算法:
在小程式的預下載場景,可以基於協同過濾演算法,做小程式偏好人群的判斷,實現預下載的千人千面,從而減少網路帶寬,節省資源成本等;
- 語義引擎:
如何將ChatGpt這種AI智能模型,可以分析和理解大量的數據,自動提取和歸類數據,使得小程式數據運維更加高效、準確;
作者:京東零售 徐佳慶
來源:京東雲開發者社區 轉載請註明出處

