
[toc] # 一、爬蟲對象-豆瓣電影TOP250 前幾天,我分享了一個python爬蟲案例,爬取豆瓣讀書TOP250數據:[【python爬蟲案例】用python爬豆瓣讀書TOP250排行榜! ](https://www.cnblogs.com/mashukui/p/17514196.html) ...
目錄
一、爬蟲對象-豆瓣電影TOP250
前幾天,我分享了一個python爬蟲案例,爬取豆瓣讀書TOP250數據:【python爬蟲案例】用python爬豆瓣讀書TOP250排行榜!
今天,我再分享一期,python爬取豆瓣電影TOP250數據!
爬蟲大體流程和豆瓣讀書TOP250類似,細節之處見邏輯。
首先,打開豆瓣電影TOP250的頁面:https://movie.douban.com/top250
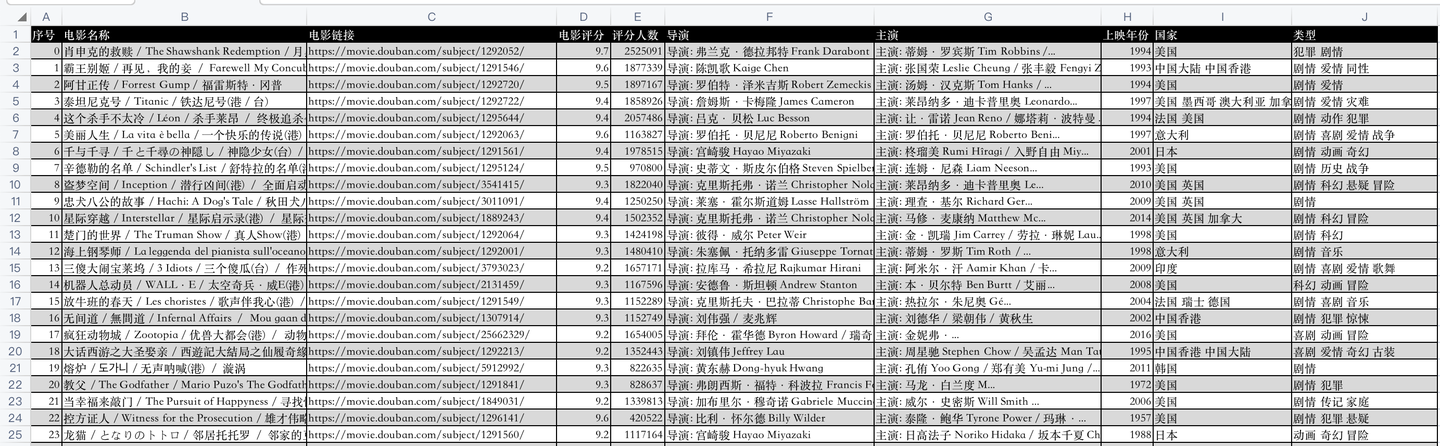
開發好python爬蟲代碼後,爬取成功後的csv數據,如下:
代碼是怎樣實現的爬取呢?下麵逐一講解python核心代碼。
二、python爬蟲代碼講解
首先,導入需要用到的庫:
import requests # 發送請求
from bs4 import BeautifulSoup # 解析網頁
import pandas as pd # 存取csv
from time import sleep # 等待時間
然後,向豆瓣電影網頁發送請求:
res = requests.get(url, headers=headers)
利用BeautifulSoup庫解析響應頁面:
soup = BeautifulSoup(res.text, 'html.parser')
用BeautifulSoup的select函數,(css解析的方法)編寫代碼邏輯,部分核心代碼:
for movie in soup.select('.item'):
name = movie.select('.hd a')[0].text.replace('\n', '') # 電影名稱
movie_name.append(name)
url = movie.select('.hd a')[0]['href'] # 電影鏈接
movie_url.append(url)
star = movie.select('.rating_num')[0].text # 電影評分
movie_star.append(star)
star_people = movie.select('.star span')[3].text # 評分人數
star_people = star_people.strip().replace('人評價', '')
movie_star_people.append(star_people)
其中,需要說明的是,《大鬧天宮》這部電影和其他電影頁面排版不同:

它的上映年份有3個(其他電影只有1個上映年份),並且以"/"分隔,正好和國家、電影類型的分割線衝突,
所以,這裡特殊處理一下:
if name == '大鬧天宮 / 大鬧天宮 上下集 / The Monkey King': # 大鬧天宮,特殊處理
year0 = movie_infos.split('\n')[1].split('/')[0].strip()
year1 = movie_infos.split('\n')[1].split('/')[1].strip()
year2 = movie_infos.split('\n')[1].split('/')[2].strip()
year = year0 + '/' + year1 + '/' + year2
movie_year.append(year)
country = movie_infos.split('\n')[1].split('/')[3].strip()
movie_country.append(country)
type = movie_infos.split('\n')[1].split('/')[4].strip()
movie_type.append(type)
最後,將爬取到的數據保存到csv文件中:
def save_to_csv(csv_name):
"""
數據保存到csv
:return: None
"""
df = pd.DataFrame() # 初始化一個DataFrame對象
df['電影名稱'] = movie_name
df['電影鏈接'] = movie_url
df['電影評分'] = movie_star
df['評分人數'] = movie_star_people
df['導演'] = movie_director
df['主演'] = movie_actor
df['上映年份'] = movie_year
df['國家'] = movie_country
df['類型'] = movie_type
df.to_csv(csv_name, encoding='utf_8_sig') # 將數據保存到csv文件
其中,把各個list賦值為DataFrame的各個列,就把list數據轉換為了DataFrame數據,然後直接to_csv保存。
這樣,爬取的數據就持久化保存下來了。
三、同步視頻
同步講解視頻:【python爬蟲】利用python爬蟲爬取豆瓣電影TOP250的數據!
四、獲取完整源碼
附完整源碼:【python爬蟲案例】利用python爬蟲爬取豆瓣電影TOP250的數據!
我是 @馬哥python說 ,持續分享python源碼乾貨中!


