
# concat 最近在寫數據的時候看到用一個concat函數進行整合,但是下麵這段代碼之後就碰上個很奇怪的地方 ```python for i, bag in enumerate(bags): coure_result = func() core_df = pd.DataFrame([core_r ...
concat
最近在寫數據的時候看到用一個concat函數進行整合,但是下麵這段代碼之後就碰上個很奇怪的地方
for i, bag in enumerate(bags):
coure_result = func()
core_df = pd.DataFrame([core_result])
dfs.append(core_df)
df = pd.concat(dfs)
這段代碼首先就是用dfs記錄了每一組數據,最後使用concat函數進行連接。在這之後我希望在特定位置插入一列數據
df_summary = pd.DataFrame(summary, columns = ["summary"])
df.insert(1,"summary",df_summary["summary"])
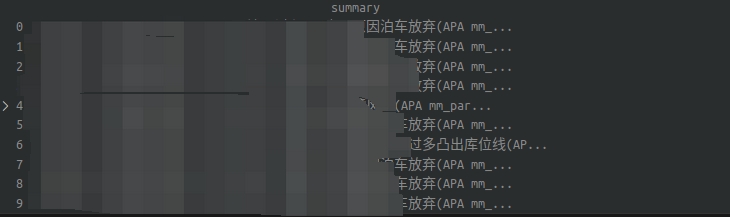
一共有三種類型的文本,10條數據,在df格式下前面也有索引。而我之前拼接好的內容如下圖:

按理來說運行insert之後,每一行都會對應一個summary裡面的欄位,但是最終的運行效果summary裡面的內容完全變成同樣的話
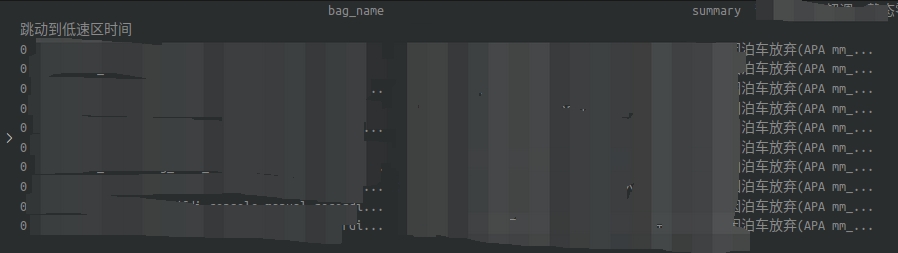
這讓我很是奇怪。研究了半天,發現df原來的內容預設索引全都是0,原因是因為在創建和合併DataFrame的時候,concat連接每一個dfs裡面的獨立的dataframe時,每個DataFrame都有自己獨立的索引,從0開始。在運行concat函數時會保留原始的索引,即使在最終的DataFrame裡面重覆了。因此,再重新插入新的有index的df時,會根據索引位置插入數據,而並不是像Excel那樣直接插入。
所以需要先改掉原先的索引才能插入
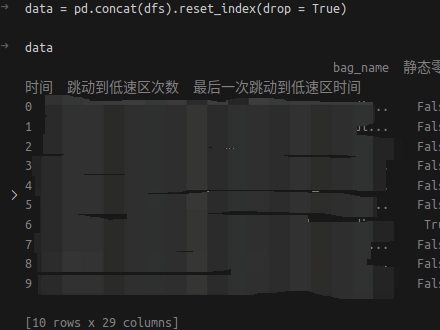
df = pd.concat(dfs).reset_index(drop = True)
意味著重置索引後丟棄掉原來的索引,如果不把drop改成True,那麼原來的索引將會變成新的列。
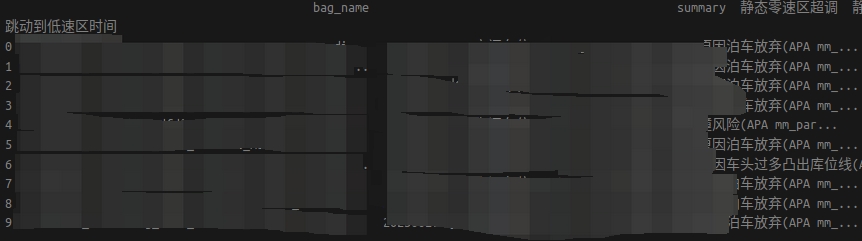
這樣的話,df的內容和我要插入內容的索引就可以對應上了,在進行插入的時候就可以了
本文來自博客園,作者:ivanlee717,轉載請註明原文鏈接:https://www.cnblogs.com/ivanlee717/p/17514757.html


