
本文主要記錄對象存儲組件Minio、數據湖組件Hudi及查詢引擎Hive\Spark之間的相容性配置及測試情況,Spark及Hive無需多言,這裡簡單介紹下Minio及Hudi。 MinIO 是在 GNU Affero 通用公共許可證 v3.0 下發佈的高性能對象存儲。 它是與 Amazon S3 ...
本文主要記錄對象存儲組件Minio、數據湖組件Hudi及查詢引擎Hive\Spark之間的相容性配置及測試情況,Spark及Hive無需多言,這裡簡單介紹下Minio及Hudi。
MinIO 是在 GNU Affero 通用公共許可證 v3.0 下發佈的高性能對象存儲。 它是與 Amazon S3 雲存儲服務相容的 API。可使用s3a的標準介面進行讀寫操作。 基於 MinIO 的對象存儲(Object Storage Service)服務,能夠為機器學習、分析和應用程式數據工作負載構建高性能基礎架構。
Minio官網:https://min.io/
Minio中文官網:http://www.minio.org.cn/
GitHub:https://github.com/minio/
Hudi 是由Uber開源的一種數據湖的存儲格式,現已屬於Apache頂級項目,Hudi在Hadoop文件系統之上提供了更新數據和刪除數據的能力以及消費變化數據的能力。
Hudi表類型:Copy On Write
使用Parquet格式存儲數據。Copy On Write表的更新操作需要通過重寫實現。
Hudi表類型:Merge On Read
使用列式文件格式(Parquet)和行式文件格式(Avro)混合的方式來存儲數據。Merge On Read使用列式格式存放Base數據,同時使用行式格式存放增量數據。最新寫入的增量數據存放至行式文件中,根據可配置的策略執行COMPACTION操作合併增量數據至列式文件中。
Hudi官網:http://hudi.apache.org/
Hudi中文文檔:http://hudi.apachecn.org/
主要的實操步驟如下:
一、測試環境各組件版本說明
spark-3.1.2
hadoop-3.2.2
centos-7
jdk-1.8
hive-3.1.2
flink-1.14.2
scala-2.12.15
hudi-0.11.1
aws-java-sdk-1.11.563
hadoop-aws-3.2.2(需要與hadoop集群版本保持一致)
二、hive/spark的查詢相容性
2.1、hive讀取minio文件
hive-3.1.2與hadoop-3.2.2、aws的相關jar包依賴,主要分為以下部分:
aws-java-sdk-1.12.363.jar
aws-java-sdk-api-gateway-1.12.363.jar
aws-java-sdk-bundle-1.12.363.jar
aws-java-sdk-core-1.12.363.jar
aws-java-sdk-s3-1.12.363.jar
aws-lambda-java-core-1.2.2.jar
com.amazonaws.services.s3-1.0.0.jar
hadoop-aws-3.2.2.jar
將以上jar包複製到$HIVE_HOME下;另外需要在$HADOOP_HOME/etc/hadoop下,編輯core-site.xml文件,添加以下內容:
<property>
<name>fs.s3.access.key</name>
<value>minioadmin</value>
</property>
<property>
<name>fs.s3.secret.key</name>
<value>********</value>
</property>
<property>
<name>fs.s3.impl</name>
<value>org.apache.hadoop.fs.s3.S3FileSystem</value>
</property>
<property>
<name>fs.s3a.access.key</name>
<value>minioadmin</value>
</property>
<property>
<name>fs.s3a.secret.key</name>
<value>*********</value>
</property>
<property>
<name>fs.s3a.impl</name>
<value>org.apache.hadoop.fs.s3a.S3AFileSystem</value>
</property>
<property>
<name>fs.s3a.endpoint</name>
<value>192.168.56.101:9000</value>
</property>
<property>
<name>fs.s3a.connection.ssl.enabled</name>
<value>false</value>
</property>
<property>
<name>fs.s3a.path.style.access</name>
<value>true</value>
</property>
添加完以後重啟hadoop集群,並將core-site.xml分發到所有datanode,之後再複製到$HIVE_HOME/conf下。並重啟hive-server2服務。
測試結果
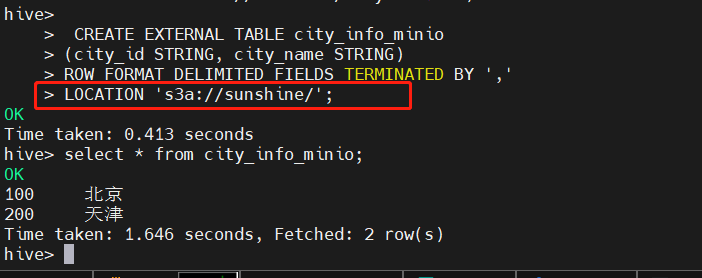
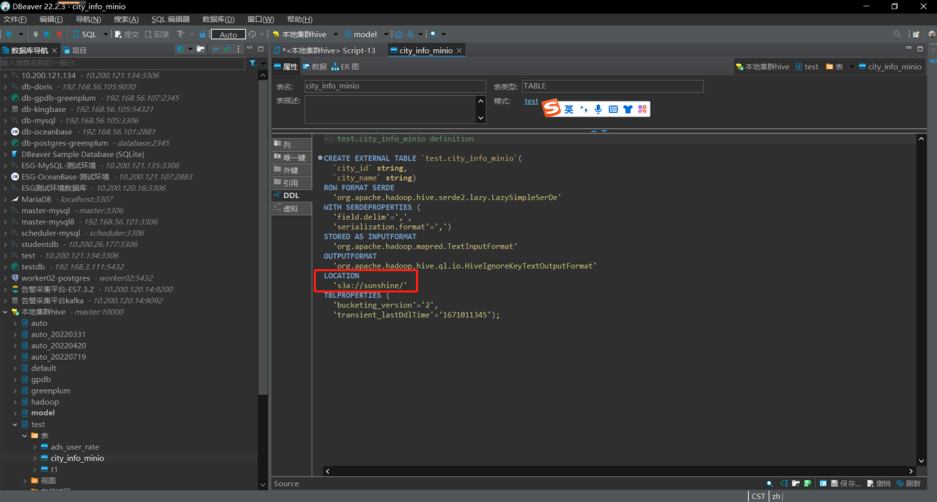
在hive中新建測試表,在此之前,需要在對象存儲Minio中提前上傳好建表所需的文件。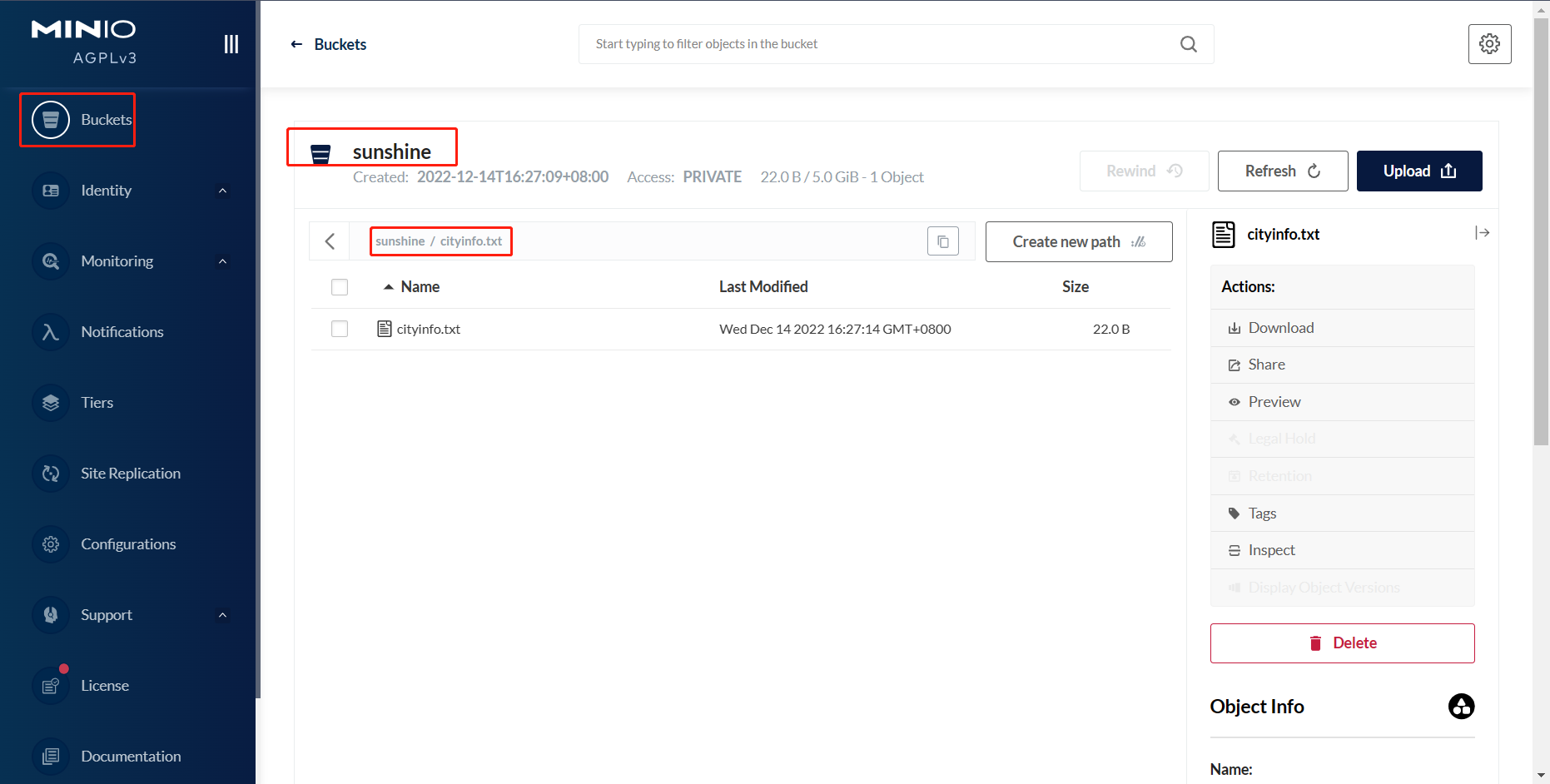
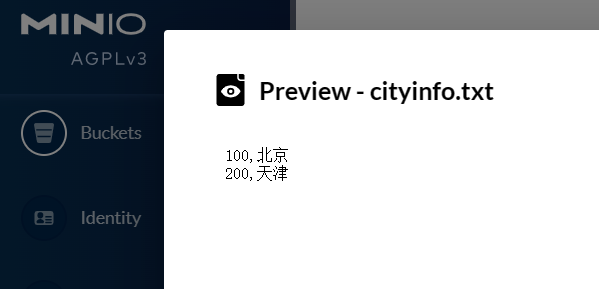
如本次新上傳文件為cityinfo.txt,內容為:
2.2、spark讀取minio文件
hive-3.1.2與hadoop3.2.2、aws的相關jar包調試,主要分為以下部分:
aws-java-sdk-1.12.363.jar
aws-java-sdk-api-gateway-1.12.363.jar
aws-java-sdk-bundle-1.12.363.jar
aws-java-sdk-core-1.12.363.jar
aws-java-sdk-s3-1.12.363.jar
aws-lambda-java-core-1.2.2.jar
com.amazonaws.services.s3-1.0.0.jar
hadoop-aws-3.2.2.jar
註意:此處一定要在aws官網下載目前最新的aws-java相關jar包,關於hadoop-aws-*.jar,需要與當前hadoop集群的版本適配,否則容易出現一些CLASS或PACKAGE找不到的報錯。在此之前,需要將$HIVE_HOME/conf/hive-site.xml複製到$SPARK_HOME/conf下
測試結果
進入spark-shell客戶端進行查看,命令為:
$SPARK_HOME/bin/spark-shell \
--conf spark.hadoop.fs.s3a.access.key=minioadmin \
--conf spark.hadoop.fs.s3a.secret.key=********** \
--conf spark.hadoop.fs.s3a.endpoint=192.168.56.101:9000 \
--conf spark.hadoop.fs.s3a.connection.ssl.enabled=false \
--master spark://192.168.56.101:7077
註意此處命令一定要寫明endpoint,需要功能變數名稱或IP地址,執行以下操作:
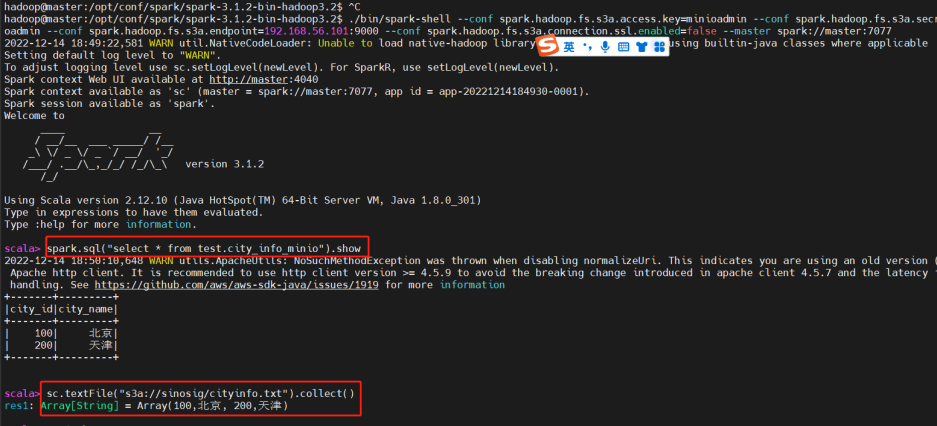
可以看到無論是通過rdd方式還是通過sql方式,都可以讀取到minio對象存儲的文件。
2.3、dbeaver測試minio文件外部表
可通過dbeaver或其他連接工具,進行簡單查詢或者關聯查詢。
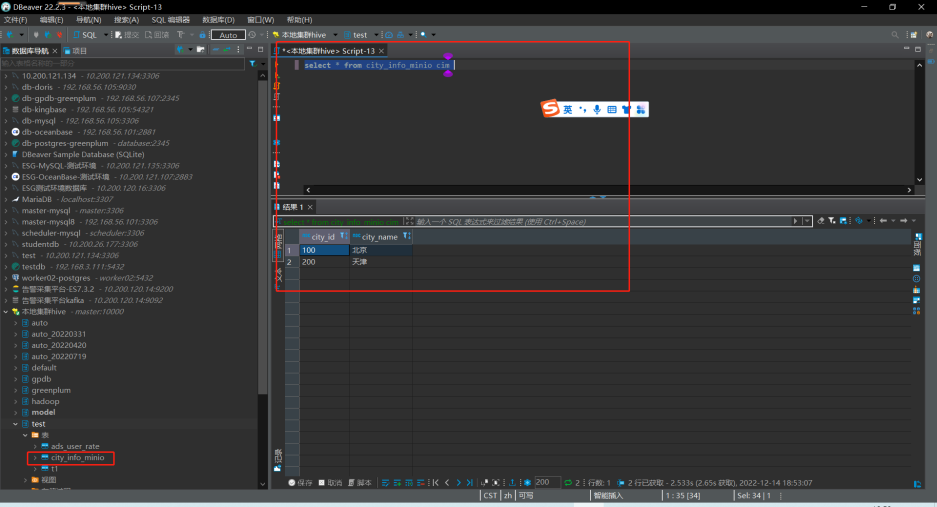
三、hudi與對象存儲的互相操作可行性
spark操作hudi
需要spark.hadoop.fs.s3a.xxx配置項的一些具體信息,如key\secret\endpoint等信息。
spark-shell \
--packages org.apache.hudi:hudi-spark3-bundle_2.11:0.11.1,org.apache.hadoop:hadoop-aws:3.2.2,com.amazonaws:aws-java-sdk:1.12.363 \
--conf 'spark.serializer=org.apache.spark.serializer.KryoSerializer' \
--conf 'spark.sql.catalog.spark_catalog=org.apache.spark.sql.hudi.catalog.HoodieCatalog' \
--conf 'spark.sql.extensions=org.apache.spark.sql.hudi.HoodieSparkSessionExtension' \
--conf 'spark.hadoop.fs.s3a.access.key=minioadmin' \
--conf 'spark.hadoop.fs.s3a.secret.key=<your-MinIO-secret-key>'\
--conf 'spark.hadoop.fs.s3a.endpoint=192.168.56.101:9000' \
--conf 'spark.hadoop.fs.s3a.path.style.access=true' \
--conf 'fs.s3a.signing-algorithm=S3SignerType'
以上啟動spark並初始化載入hudi的jar依賴,大概輸出為:
hadoop@master:/opt/conf/spark/spark-3.1.2-bin-hadoop3.2/jars$ spark-shell \
> --packages org.apache.hudi:hudi-spark3-bundle_2.11:0.11.1,org.apache.hadoop:hadoop-aws:3.2.2,com.amazonaws:aws-java-sdk:1.12.363 \
> --conf 'spark.serializer=org.apache.spark.serializer.KryoSerializer' \
> --conf 'spark.sql.catalog.spark_catalog=org.apache.spark.sql.hudi.catalog.HoodieCatalog' \
> --conf 'spark.sql.extensions=org.apache.spark.sql.hudi.HoodieSparkSessionExtension' \
> --conf 'spark.hadoop.fs.s3a.access.key=minioadmin' \
> --conf 'spark.hadoop.fs.s3a.secret.key=<your-MinIO-secret-key>'\
> --conf 'spark.hadoop.fs.s3a.endpoint=192.168.56.101:9000' \
> --conf 'spark.hadoop.fs.s3a.path.style.access=true' \
> --conf 'fs.s3a.signing-algorithm=S3SignerType'
Warning: Ignoring non-Spark config property: fs.s3a.signing-algorithm
:: loading settings :: url = jar:file:/opt/conf/spark/spark-3.1.2-bin-hadoop3.2/jars/ivy-2.4.0.jar!/org/apache/ivy/core/settings/ivysettings.xml
Ivy Default Cache set to: /home/hadoop/.ivy2/cache
The jars for the packages stored in: /home/hadoop/.ivy2/jars
org.apache.hudi#hudi-spark3-bundle_2.11 added as a dependency
org.apache.hadoop#hadoop-aws added as a dependency
com.amazonaws#aws-java-sdk added as a dependency
:: resolving dependencies :: org.apache.spark#spark-submit-parent-f268e29b-59b7-4ee6-8ace-eae921495080;1.0
confs: [default]
found org.apache.hadoop#hadoop-aws;3.2.2 in central
found com.amazonaws#aws-java-sdk-bundle;1.11.563 in central
found com.amazonaws#aws-java-sdk;1.12.363 in central
found com.amazonaws#aws-java-sdk-sagemakermetrics;1.12.363 in central
found com.amazonaws#aws-java-sdk-core;1.12.363 in central
found commons-logging#commons-logging;1.1.3 in central
found commons-codec#commons-codec;1.15 in central
found org.apache.httpcomponents#httpclient;4.5.13 in central
found org.apache.httpcomponents#httpcore;4.4.13 in central
found software.amazon.ion#ion-java;1.0.2 in central
found com.fasterxml.jackson.core#jackson-databind;2.12.7.1 in central
found com.fasterxml.jackson.core#jackson-annotations;2.12.7 in central
found com.fasterxml.jackson.core#jackson-core;2.12.7 in central
found com.fasterxml.jackson.dataformat#jackson-dataformat-cbor;2.12.6 in central
found joda-time#joda-time;2.8.1 in local-m2-cache
found com.amazonaws#jmespath-java;1.12.363 in central
found com.amazonaws#aws-java-sdk-pipes;1.12.363 in central
found com.amazonaws#aws-java-sdk-sagemakergeospatial;1.12.363 in central
found com.amazonaws#aws-java-sdk-docdbelastic;1.12.363 in central
found com.amazonaws#aws-java-sdk-omics;1.12.363 in central
found com.amazonaws#aws-java-sdk-opensearchserverless;1.12.363 in central
found com.amazonaws#aws-java-sdk-securitylake;1.12.363 in central
found com.amazonaws#aws-java-sdk-simspaceweaver;1.12.363 in central
found com.amazonaws#aws-java-sdk-arczonalshift;1.12.363 in central
found com.amazonaws#aws-java-sdk-oam;1.12.363 in central
found com.amazonaws#aws-java-sdk-iotroborunner;1.12.363 in central
found com.amazonaws#aws-java-sdk-chimesdkvoice;1.12.363 in central
found com.amazonaws#aws-java-sdk-ssmsap;1.12.363 in central
found com.amazonaws#aws-java-sdk-scheduler;1.12.363 in central
found com.amazonaws#aws-java-sdk-resourceexplorer2;1.12.363 in central
found com.amazonaws#aws-java-sdk-connectcases;1.12.363 in central
found com.amazonaws#aws-java-sdk-migrationhuborchestrator;1.12.363 in central
found com.amazonaws#aws-java-sdk-iotfleetwise;1.12.363 in central
found com.amazonaws#aws-java-sdk-controltower;1.12.363 in central
found com.amazonaws#aws-java-sdk-supportapp;1.12.363 in central
found com.amazonaws#aws-java-sdk-private5g;1.12.363 in central
found com.amazonaws#aws-java-sdk-backupstorage;1.12.363 in central
found com.amazonaws#aws-java-sdk-licensemanagerusersubscriptions;1.12.363 in central
found com.amazonaws#aws-java-sdk-iamrolesanywhere;1.12.363 in central
found com.amazonaws#aws-java-sdk-redshiftserverless;1.12.363 in central
found com.amazonaws#aws-java-sdk-connectcampaign;1.12.363 in central
found com.amazonaws#aws-java-sdk-mainframemodernization;1.12.363 in central
初次載入會稍慢,需要等候全部載入完畢。以上載入完畢後,進入改界面,證明所有依賴全部不存在衝突。如果伺服器無法連接公網,則需手動安裝依賴到本地倉庫。
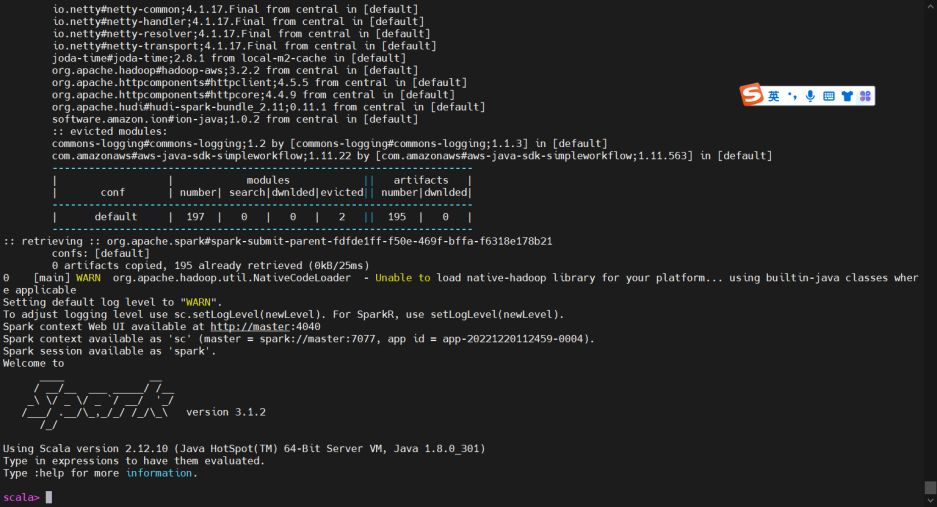
成功載入hudi部分jar包進入spark-shell客戶端
之後需要依照自行編譯的hudi源代碼,查看hadoop、spark、hudi、scala四者之間互相依賴的jar包,大概有10數個,要註意,scala小版本之間的變化也比較頻繁看,如scala-2.12.10與scala-2.12.12之間一些基礎類包都有版本差異,API調用會報錯,目前已針對spark-3.1.2、hadoop-3.2.3、scala-2.12.12、java8、aws-1.12.368之間的互相依賴進行了調整,能夠進入spark-shell通過hudi操作minio的s3a介面,需要主要的錯誤如:
aws小版本與hadoop-aws協議的衝突問題,這裡選定aws-java-sdk-1.12.368即可
以下是比較複雜的多方依賴jar包,需要通過源碼的pom文件來確認小版本。
其他需要註意的點就是,某些內網環境或者屏蔽阿裡雲maven鏡像等的伺服器,需要手動安裝
org.apache.spark.sql.adapter.BaseSpark3Adapter
org/apache/spark/internal/Logging
com.fasterxml.jackson.core.jackson-annotations/2.6.0/jackson-annotations-2.6.0.jar
mvn install:install-file -Dmaven.repo.local=/data/maven/repository -DgroupId=com.fasterxml.jackson.core -DartifactId=jackson-annotations -Dversion=2.6.0 -Dpackaging=jar -Dfile=/opt/conf/spark/spark-3.1.2-bin-hadoop3.2/jars/jackson-annotations-2.6.0.jar
mvn install:install-file -Dmaven.repo.local=/data/maven/repository -DgroupId=org.apache.spark -DartifactId=hudi-spark-bundle_2.12 -Dversion=0.11.1 -Dpackaging=jar -Dfile=/opt/conf/hudi/hudi-0.11.1/packaging/hudi-spark-bundle/target/original-hudi-spark-bundle_2.11-0.11.1.jar
vn install:install-file -Dmaven.repo.local=/data/maven/repository -DgroupId=org.apache.hudi -DartifactId=hudi-spark-bundle_2.12 -Dversion=0.11.1 -Dpackaging=jar -Dfile=/opt/conf/hudi/hudi-0.11.1/packaging/hudi-spark-bundle/target/original-hudi-spark-bundle_2.11-0.11.1.jar
mvn install:install-file -Dmaven.repo.local=/data/maven/repository -DgroupId=com.amazonaws -DartifactId=aws-java-sdk-bundle -Dversion=1.12.368 -Dpackaging=jar -Dfile=/opt/conf/spark/spark-3.1.2-bin-hadoop3.2/jars/aws-java-sdk-bundle-1.12.363.jar
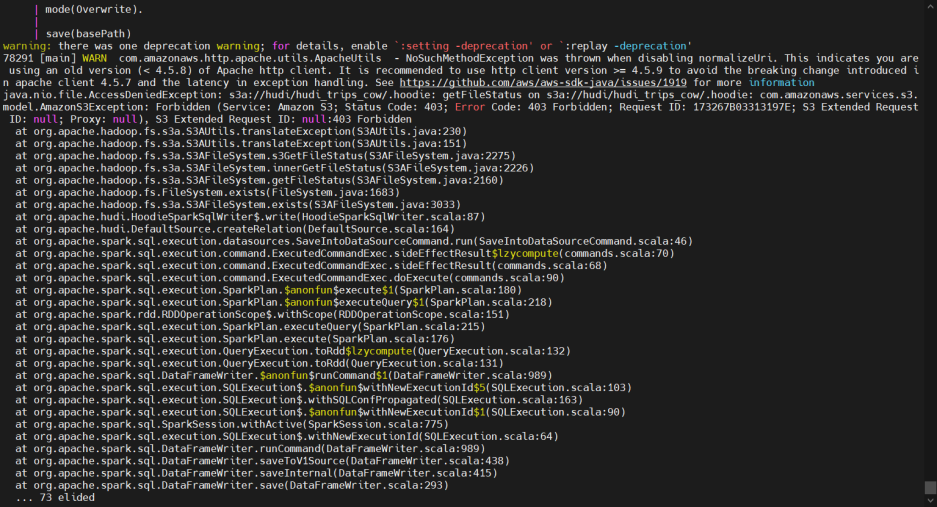
四、通過spark操作hudi進行對象存儲minio的s3a介面讀寫
在spark集群中初始化hudi
引入相關的jar包
import org.apache.hudi.QuickstartUtils._
import scala.collection.JavaConversions._
import org.apache.spark.sql.SaveMode._
import org.apache.hudi.DataSourceReadOptions._
import org.apache.hudi.DataSourceWriteOptions._
import org.apache.hudi.config.HoodieWriteConfig._
import org.apache.hudi.common.model.HoodieRecord
val tableName = "hudi_trips_cow"
val basePath = "s3a://sunshine/hudi_trips_cow"
val dataGen = new DataGenerator
val inserts = convertToStringList(dataGen.generateInserts(10))
val df = spark.read.json(spark.sparkContext.parallelize(inserts, 2))
df.write.format("hudi").
options(getQuickstartWriteConfigs).
option("PRECOMBINE_FIELD_OPT_KEY", "ts").
option("RECORDKEY_FIELD_OPT_KEY", "uuid").
option("PARTITIONPATH_FIELD_OPT_KEY", "partitionpath").
option("TABLE_NAME", tableName).
mode(Overwrite).
save(basePath)
創建一個簡單的小型 Hudi 表。Hudi DataGenerator 是一種基於示例行程模式生成示例插入和更新的快速簡便的方法

