
##一、 DataX為什麼要使用插件機制? 從設計之初,DataX就把異構數據源同步作為自身的使命,為了應對不同數據源的差異、同時提供一致的同步原語和擴展能力,DataX自然而然地採用了框架 + 插件 的模式: 插件只需關心數據的讀取或者寫入本身。 而同步的共性問題,比如:類型轉換、性能、統計,則交 ...
一、 DataX為什麼要使用插件機制?
從設計之初,DataX就把異構數據源同步作為自身的使命,為了應對不同數據源的差異、同時提供一致的同步原語和擴展能力,DataX自然而然地採用了框架 + 插件 的模式:
- 插件只需關心數據的讀取或者寫入本身。
- 而同步的共性問題,比如:類型轉換、性能、統計,則交由框架來處理。
作為插件開發人員,則需要關註兩個問題:
- 數據源本身的讀寫數據正確性。
- 如何與框架溝通、合理正確地使用框架。
二、插件視角看框架
邏輯執行模型
插件開發者基本只需要關註特定數據源系統的讀和寫,以及自己的代碼在邏輯上是怎樣被執行的,哪一個方法是在什麼時候被調用的。開發之前需要明確以下概念:
Job:Job是DataX用以描述從一個源頭到一個目的端的同步作業,是DataX數據同步的最小業務單元。比如:從一張mysql的表同步到odps的一個表的特定分區。Task:Task是為最大化而把Job拆分得到的最小執行單元。比如:讀一張有1024個分表的mysql分庫分表的Job,拆分成1024個讀Task,用若幹個併發執行。TaskGroup: 描述的是一組Task集合。在同一個TaskGroupContainer執行下的Task集合稱之為TaskGroupJobContainer:Job執行器,負責Job全局拆分、調度、前置語句和後置語句等工作的工作單元。類似Yarn中的JobTrackerTaskGroupContainer:TaskGroup執行器,負責執行一組Task的工作單元,類似Yarn中的TaskTracker。
簡而言之, Job拆分成Task,在分別在框架提供的容器中執行,插件只需要實現Job和Task兩部分邏輯。
物理執行模型
框架為插件提供物理上的執行能力(線程)。DataX框架有三種運行模式:
Standalone: 單進程運行,沒有外部依賴。Local: 單進程運行,統計信息、錯誤信息彙報到集中存儲。Distrubuted: 分散式多進程運行,依賴DataX Service服務。
當然,上述三種模式對插件的編寫而言沒有什麼區別,你只需要避開一些小錯誤,插件就能夠在單機/分散式之間無縫切換了。
當JobContainer和TaskGroupContainer運行在同一個進程內時,就是單機模式(Standalone和Local);當它們分佈在不同的進程中執行時,就是分散式(Distributed)模式。
編程介面
Job和Task的邏輯是怎麼對應到具體的代碼中的?
首先,插件的入口類必須擴展Reader或Writer抽象類,並且實現分別實現Job和Task兩個內部抽象類,Job和Task的實現必須是 內部類 的形式,原因見 載入原理 一節。以Reader為例:
public class SomeReader extends Reader {
public static class Job extends Reader.Job {
@Override
public void init() {
}
@Override
public void prepare() {
}
@Override
public List<Configuration> split(int adviceNumber) {
return null;
}
@Override
public void post() {
}
@Override
public void destroy() {
}
}
public static class Task extends Reader.Task {
@Override
public void init() {
}
@Override
public void prepare() {
}
@Override
public void startRead(RecordSender recordSender) {
}
@Override
public void post() {
}
@Override
public void destroy() {
}
}
}
Job介面功能如下:
init: Job對象初始化工作,此時可以通過super.getPluginJobConf()獲取與本插件相關的配置。讀插件獲得配置中reader部分,寫插件獲得writer部分。prepare: 全局準備工作,比如mysqlwriter在寫入新數據之前執行一個truncate table的操作、讀取Hive數據之前,完成Kerberos認證等。split: 拆分Task。參數adviceNumber框架建議的拆分數,一般是運行時所配置的併發度。值返回的是Task的配置列表。post: 全局的後置工作,比如mysqlwriter同步完影子表後的rename操作。destroy: Job對象自身的銷毀工作。
Task介面功能如下:
init:Task對象的初始化。此時可以通過super.getPluginJobConf()獲取與本Task相關的配置。這裡的配置是Job的split方法返回的配置列表中的其中一個。prepare:局部的準備工作。startRead: 從數據源讀數據,寫入到RecordSender中。RecordSender會把數據寫入連接Reader和Writer的緩存隊列。startWrite:從RecordReceiver中讀取數據,寫入目標數據源。RecordReceiver中的數據來自Reader和Writer之間的緩存隊列。post: 局部的後置工作。destroy: Task象自身的銷毀工作。
需要註意的是:
Job和Task之間一定不能有共用變數,因為分散式運行時不能保證共用變數會被正確初始化。兩者之間只能通過配置文件進行依賴。prepare和post在Job和Task中都存在,插件需要根據實際情況確定在什麼地方執行操作。
框架按照如下的順序執行Job和Task的介面:
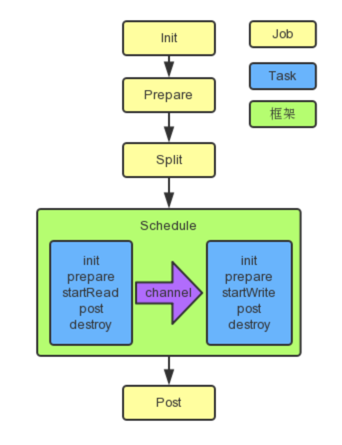
上圖中,黃色表示Job部分的執行階段,藍色表示Task部分的執行階段,綠色表示框架執行階段。
相關類關係如下:
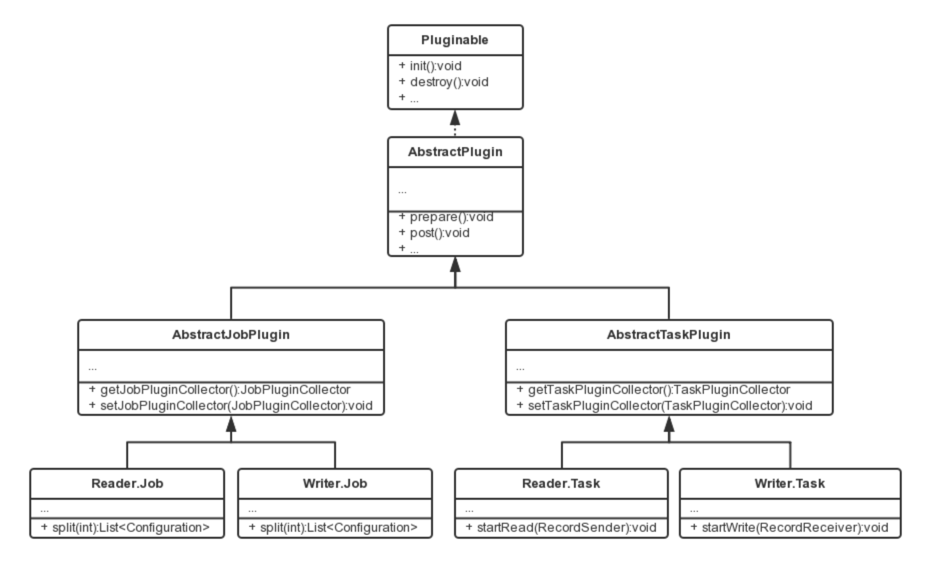
插件定義
代碼寫好了,有沒有想過框架是怎麼找到插件的入口類的?框架是如何載入插件的呢?
在每個插件的項目中,都有一個plugin.json文件,這個文件定義了插件的相關信息,包括入口類。例如:
{
"name": "mysqlwriter",
"class": "com.alibaba.datax.plugin.writer.mysqlwriter.MysqlWriter",
"description": "Use Jdbc connect to database, execute insert sql.",
"developer": "alibaba"
}
name: 插件名稱,大小寫敏感。框架根據用戶在配置文件中指定的名稱來搜尋插件。 十分重要 。class: 入口類的全限定名稱,框架通過反射插件入口類的實例。十分重要 。description: 描述信息。developer: 開發人員。
打包發佈
DataX使用assembly打包,assembly的使用方法請咨詢谷哥或者度娘。打包命令如下:
mvn clean package -DskipTests assembly:assembly
DataX插件需要遵循統一的目錄結構:
${DATAX_HOME}
|-- bin
| `-- datax.py
|-- conf
| |-- core.json
| `-- logback.xml
|-- lib
| `-- datax-core-dependencies.jar
`-- plugin
|-- reader
| `-- mysqlreader
| |-- libs
| | `-- mysql-reader-plugin-dependencies.jar
| |-- mysqlreader-0.0.1-SNAPSHOT.jar
| `-- plugin.json
`-- writer
|-- mysqlwriter
| |-- libs
| | `-- mysql-writer-plugin-dependencies.jar
| |-- mysqlwriter-0.0.1-SNAPSHOT.jar
| `-- plugin.json
|-- oceanbasewriter
`-- odpswriter
${DATAX_HOME}/bin: 可執行程式目錄。${DATAX_HOME}/conf: 框架配置目錄。${DATAX_HOME}/lib: 框架依賴庫目錄。${DATAX_HOME}/plugin: 插件目錄。
插件目錄分為reader和writer子目錄,讀寫插件分別存放。插件目錄規範如下:
${PLUGIN_HOME}/libs: 插件的依賴庫。${PLUGIN_HOME}/plugin-name-version.jar: 插件本身的jar。${PLUGIN_HOME}/plugin.json: 插件描述文件。
儘管框架載入插件時,會把${PLUGIN_HOME}下所有的jar放到classpath,但還是推薦依賴庫的jar和插件本身的jar分開存放。
註意:
插件的目錄名字必須和plugin.json中定義的插件名稱一致。
配置文件
DataX使用json作為配置文件的格式。一個典型的DataX任務配置如下:
{
"job": {
"content": [
{
"reader": {
"name": "odpsreader",
"parameter": {
"accessKey": "",
"accessId": "",
"column": [""],
"isCompress": "",
"odpsServer": "",
"partition": [
""
],
"project": "",
"table": "",
"tunnelServer": ""
}
},
"writer": {
"name": "oraclewriter",
"parameter": {
"username": "",
"password": "",
"column": ["*"],
"connection": [
{
"jdbcUrl": "",
"table": [
""
]
}
]
}
}
}
]
}
}
DataX框架有core.json配置文件,指定了框架的預設行為。任務的配置裡頭可以指定框架中已經存在的配置項,而且具有更高的優先順序,會覆蓋core.json中的預設值。
配置中job.content.reader.parameter的value部分會傳給Reader.Job;job.content.writer.parameter的value部分會傳給Writer.Job ,Reader.Job和Writer.Job可以通過super.getPluginJobConf()來獲取。
DataX框架支持對特定的配置項進行RSA加密,例子中以*開頭的項目便是加密後的值。 配置項加密解密過程對插件是透明,插件仍然以不帶*的key來查詢配置和操作配置項 。
如何設計配置參數
配置文件的設計是插件開發的第一步!
任務配置中reader和writer下parameter部分是插件的配置參數,插件的配置參數應當遵循以下原則:
-
駝峰命名:所有配置項採用駝峰命名法,首字母小寫,單詞首字母大寫。
-
正交原則:配置項必須正交,功能沒有重覆,沒有潛規則。
-
富類型:合理使用json的類型,減少無謂的處理邏輯,減少出錯的可能。
- 使用正確的數據類型。比如,bool類型的值使用
true/false,而非"yes"/"true"/0等。 - 合理使用集合類型,比如,用數組替代有分隔符的字元串。
- 使用正確的數據類型。比如,bool類型的值使用
-
類似通用:遵守同一類型的插件的習慣,比如關係型資料庫的
connection參數都是如下結構:{ "connection": [ { "table": [ "table_1", "table_2" ], "jdbcUrl": [ "jdbc:mysql://127.0.0.1:3306/database_1", "jdbc:mysql://127.0.0.2:3306/database_1_slave" ] }, { "table": [ "table_3", "table_4" ], "jdbcUrl": [ "jdbc:mysql://127.0.0.3:3306/database_2", "jdbc:mysql://127.0.0.4:3306/database_2_slave" ] } ] } -
...
如何使用Configuration類
為了簡化對json的操作,DataX提供了簡單的DSL配合Configuration類使用。
Configuration提供了常見的get, 帶類型get,帶預設值get,set等讀寫配置項的操作,以及clone, toJSON等方法。配置項讀寫操作都需要傳入一個path做為參數,這個path就是DataX定義的DSL。語法有兩條:
- 子map用
.key表示,path的第一個點省略。 - 數組元素用
[index]表示。
比如操作如下json:
{
"a": {
"b": {
"c": 2
},
"f": [
1,
2,
{
"g": true,
"h": false
},
4
]
},
"x": 4
}
比如調用configuration.get(path)方法,當path為如下值的時候得到的結果為:
x:4a.b.c:2a.b.c.d:nulla.b.f[0]:1a.b.f[2].g:true
註意,因為插件看到的配置只是整個配置的一部分。使用Configuration對象時,需要註意當前的根路徑是什麼。
更多Configuration的操作請參考ConfigurationTest.java。
插件數據傳輸
跟一般的生產者-消費者模式一樣,Reader插件和Writer插件之間也是通過channel來實現數據的傳輸的。channel可以是記憶體的,也可能是持久化的,插件不必關心。插件通過RecordSender往channel寫入數據,通過RecordReceiver從channel讀取數據。
channel中的一條數據為一個Record的對象,Record中可以放多個Column對象,這可以簡單理解為資料庫中的記錄和列。
Record有如下方法:
public interface Record {
// 加入一個列,放在最後的位置
void addColumn(Column column);
// 在指定下標處放置一個列
void setColumn(int i, final Column column);
// 獲取一個列
Column getColumn(int i);
// 轉換為json String
String toString();
// 獲取總列數
int getColumnNumber();
// 計算整條記錄在記憶體中占用的位元組數
int getByteSize();
}
因為Record是一個介面,Reader插件首先調用RecordSender.createRecord()創建一個Record實例,然後把Column一個個添加到Record中。
Writer插件調用RecordReceiver.getFromReader()方法獲取Record,然後把Column遍歷出來,寫入目標存儲中。當Reader尚未退出,傳輸還在進行時,如果暫時沒有數據RecordReceiver.getFromReader()方法會阻塞直到有數據。如果傳輸已經結束,會返回null,Writer插件可以據此判斷是否結束startWrite方法。
Column的構造和操作,我們在《類型轉換》一節介紹。
類型轉換
為了規範源端和目的端類型轉換操作,保證數據不失真,DataX支持六種內部數據類型:
Long:定點數(Int、Short、Long、BigInteger等)。Double:浮點數(Float、Double、BigDecimal(無限精度)等)。String:字元串類型,底層不限長,使用通用字元集(Unicode)。Date:日期類型。Bool:布爾值。Bytes:二進位,可以存放諸如MP3等非結構化數據。
對應地,有DateColumn、LongColumn、DoubleColumn、BytesColumn、StringColumn和BoolColumn六種Column的實現。
Column除了提供數據相關的方法外,還提供一系列以as開頭的數據類型轉換轉換方法。
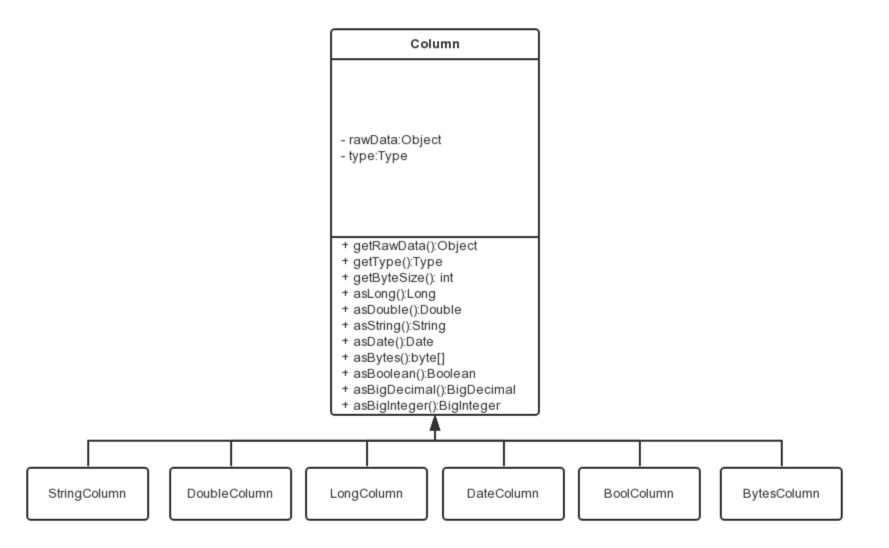
DataX的內部類型在實現上會選用不同的java類型:
| 內部類型 | 實現類型 | 備註 |
|---|---|---|
| Date | java.util.Date | |
| Long | java.math.BigInteger | 使用無限精度的大整數,保證不失真 |
| Double | java.lang.String | 用String表示,保證不失真 |
| Bytes | byte[] | |
| String | java.lang.String | |
| Bool | java.lang.Boolean |
類型之間相互轉換的關係如下:
| from\to | Date | Long | Double | Bytes | String | Bool |
|---|---|---|---|---|---|---|
| Date | - | 使用毫秒時間戳 | 不支持 | 不支持 | 使用系統配置的date/time/datetime格式轉換 | 不支持 |
| Long | 作為毫秒時間戳構造Date | - | BigInteger轉為BigDecimal,然後BigDecimal.doubleValue() | 不支持 | BigInteger.toString() | 0為false,否則true |
| Double | 不支持 | 內部String構造BigDecimal,然後BigDecimal.longValue() | - | 不支持 | 直接返回內部String | |
| Bytes | 不支持 | 不支持 | 不支持 | - | 按照common.column.encoding配置的編碼轉換為String,預設utf-8 |
不支持 |
| String | 按照配置的date/time/datetime/extra格式解析 | 用String構造BigDecimal,然後取longValue() | 用String構造BigDecimal,然後取doubleValue(),會正確處理NaN/Infinity/-Infinity |
按照common.column.encoding配置的編碼轉換為byte[],預設utf-8 |
- | "true"為true, "false"為false,大小寫不敏感。其他字元串不支持 |
| Bool | 不支持 | true為1L,否則0L |
true為1.0,否則0.0 |
不支持 | - |
臟數據處理
什麼是臟數據?
目前主要有三類臟數據:
- Reader讀到不支持的類型、不合法的值。
- 不支持的類型轉換,比如:
Bytes轉換為Date。 - 寫入目標端失敗,比如:寫mysql整型長度超長。
如何處理臟數據
在Reader.Task和Writer.Task中,通過AbstractTaskPlugin.getTaskPluginCollector()可以拿到一個TaskPluginCollector,它提供了一系列collectDirtyRecord的方法。當臟數據出現時,只需要調用合適的collectDirtyRecord方法,把被認為是臟數據的Record傳入即可。
用戶可以在任務的配置中指定臟數據限制條數或者百分比限制,當臟數據超出限制時,框架會結束同步任務,退出。插件需要保證臟數據都被收集到,其他工作交給框架就好。
載入原理
- 框架掃描
plugin/reader和plugin/writer目錄,載入每個插件的plugin.json文件。 - 以
plugin.json文件中name為key,索引所有的插件配置。如果發現重名的插件,框架會異常退出。 - 用戶在插件中在
reader/writer配置的name欄位指定插件名字。框架根據插件的類型(reader/writer)和插件名稱去插件的路徑下掃描所有的jar,加入classpath。 - 根據插件配置中定義的入口類,框架通過反射實例化對應的
Job和Task對象。
三、插件介紹文檔
每個插件都必須在DataX官方wiki中有一篇文檔,文檔需要包括但不限於以下內容:
- 快速介紹:介紹插件的使用場景,特點等。
- 實現原理:介紹插件實現的底層原理,比如
mysqlwriter通過insert into和replace into來實現插入,tair插件通過tair客戶端實現寫入。 - 配置說明
- 給出典型場景下的同步任務的json配置文件。
- 介紹每個參數的含義、是否必選、預設值、取值範圍和其他約束。
- 類型轉換
- 插件是如何在實際的存儲類型和
DataX的內部類型之間進行轉換的。 - 以及是否存在特殊處理。
- 插件是如何在實際的存儲類型和
- 性能報告
- 軟硬體環境,系統版本,java版本,CPU、記憶體等。
- 數據特征,記錄大小等。
- 測試參數集(多組),系統參數(比如併發數),插件參數(比如batchSize)
- 不同參數下同步速度(Rec/s, MB/s),機器負載(load, cpu)等,對數據源壓力(load, cpu, mem等)。
- 約束限制:是否存在其他的使用限制條件。
- FAQ:用戶經常會遇到的問題。


