
本文從提升用戶行為分析效率角度出發,詳細介紹了H5埋點方案規劃,埋點數據採集流程,提供可借鑒的用戶行為數據採集方案;且完整呈現了針對頁面分析,留存分析的數倉模型規劃方案。 ...
作者:vivo 互聯網大數據團隊- Zhao Wei、Tian Fengbiao、Li Xiong
本文從提升用戶行為分析效率角度出發,詳細介紹了H5埋點方案規劃,埋點數據採集流程,提供可借鑒的用戶行為數據採集方案;且完整呈現了針對頁面分析,留存分析的數倉模型規劃方案,在數倉模型設計過程中遇見的痛點難點問題也相應的給出瞭解決思路及案例代碼;在數據展示模塊,提供了分析指標數據展示的邏輯流程及UI案例,旨在幫助有需要的同學全方位的瞭解用戶行為數據全鏈路分析流程。
一、背景
針對用戶行為數據進行採集有個專業術語叫埋點,在h5頁面上做的埋點統稱為H5埋點。H5頁面因其靈活性,便捷的交互和豐富的功能,以及在移動設備上支持多媒體等特點目前被廣泛應用於網頁app開發。
現階段H5埋點的自由度較高,行業數據產品在同類高頻的業務場景上設計的時間花費較多,埋點開發、埋點測試等事項耗時,且需重覆勞動;同樣的埋點數據分析層面-基礎分析指標,留存指標,頁面分析等需求需多次開發模型,浪費寶貴的人力資源。
H5通用分析模型旨在通過規範化埋點設計方案,開發設計一套通用度高,擴展方便,需求響應迅速的模型,減少行業數據產品和開發在類似需求上的人力投入,提升數據分析效率。
二、分析模型概述
2.1 術語解釋

2.2 模型概述
針對業務發展的不同階段,會有相應的數據分析需求。如圖(1),在業務初期,用戶的訪問,留存情況等是階段性分析重點,業務產品運營可以根據分析數據適時的調整頁面佈局,運營策略等;應用發展中後期可能會更多的關註訂單、轉化、路徑等相關分析指標。如果能在應用上線之初,快速的拿到核心分析指標數據,對產品的推廣,迭代無疑是收益良多。所以,本次模型構建從應用初期分析最廣泛的核心指標出發,落地應用概況、頁面訪問、用戶留存等維度全方位核心分析指標體系。
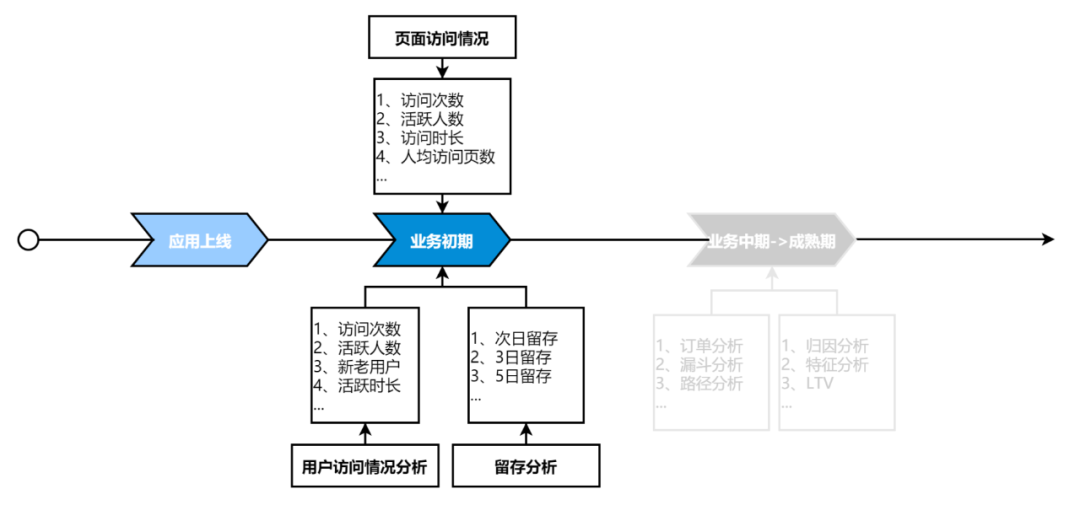 圖(1)應用生命周期內指標分析情況
圖(1)應用生命周期內指標分析情況
2.2.1 分析模型主題
本次通用分析模型圍繞以下分析主題構建。
-
【基礎分析】:從用戶瀏覽次數,人均訪問頁面數,人均使用時長,新老用戶等基礎指標展示用戶訪問大盤數據。
-
【頁面分析】:面向具體頁面,分析用戶訪問pv,uv,訪問時長等核心指標,有針對性的發現頁面訪量薄弱環節,為合理化頁面管理提供數據支撐,協助產品經理通過信息重組,提升頁面訪問量。
-
【留存分析】:通過用戶的留存,瞭解目前的產品現狀(用戶的哪些行為導致留存率的不同); 判斷產品的改進有無效果(用戶行為是否發生了改變導致留存率的提升);留存分析反映了用戶由初期的不穩定用戶轉化為活躍用戶,穩定用戶,忠誠用戶的過程。
2.2.2 分析指標定義
(以下示例中數據均為參考數據,非真實數據)
1、基礎分析:訪問pv,uv等指標(全維度)

2、頁面分析:頁面訪問相關pv,uv,時長等指標

註:用戶對訪問頁面進行命名,分析平臺提供配置入口,方便用戶對頁面進行命名。
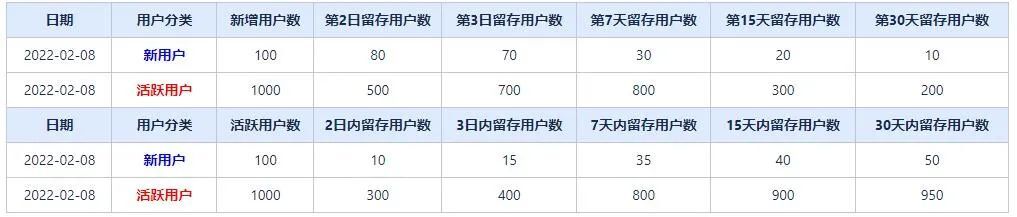
3、留存分析:新用戶留存,活躍用戶留存 包括:N日內留存 和 第N日留存。
通常意義上的留存分析指的是:用戶在APP產生行為後,在固定的第N日繼續訪問或使用APP的用戶;包括活躍用戶留存和新用戶留存
為滿足不同業務的分析需求。此次留存模型包含 n日內留存分析,即用戶在APP產生行為後,在固定的第N日內繼續訪問或使用APP的用戶(日期範圍留存)。
三、埋點方案
3.1 業務目標
-
採集用戶的pv,uv數據,幫助產品同學瞭解目前的產品現狀,並不斷改進產品;
-
自動採集,對pv,uv等這類埋點,業務無需再開發,打開開關即可採集這類數據。
3.2 自動採集
3.2.1 什麼是自動採集
自動採集是相對於前端開發者而言,目的是為了幫助前端開發者提升數據採集效率。通過自動採集開關配置,無需在手動實現上報邏輯。使用時前端開發者通過引入h5sdk.js(也稱jssdk.js),打開自動採集開關,我們就會在適當的時機,以適當的規則採集數據,併進行上報。開發者無需在關註採集代碼內部邏輯,以此來減輕同類數據採集的開發工作量。
3.2.2 如何自動採集
按照給定的規則進行頁面事件EventListener,當用戶活動觸發對應的事件時,我們會組裝好數據,然後將組裝好的數據通過https傳入到後臺。
3.2.3 自動採集的三大規則場景
我們的網站是一個SPA應用。SPA應用通過改變前端路由的變化,實現頁面內組件的切換。組件的切換,對於一個非前端開發者來說,可以泛指頁面的切換。所以我們第一場景是要覆蓋url變化的這類事件。在實踐中,我們發現,當我們需要採集頁面的用戶停留時長時,往往會不准確。為什麼不准確?用戶可以縮小化瀏覽器,也可以切換tab到其他網站,這個時候計算的用戶時長是不准確的。因為用戶雖然打開了我們網頁,但是並沒有聚焦到我們的網頁。這種不應該算作用戶停留時長,因此對於這些行為,我們又加上了失去焦點,得到焦點,以及切換瀏覽器tab事件的EventListener,這兩種場景。
綜上三大場景總結如下:
-
頁面切換時,進行採集,即url變化時觸發的事件;
-
頁面失去焦點,得到焦點時,進行採集。即focus,blur事件;
-
頁面通過瀏覽器tab切換離開,切換回來時,進行採集,即visibilitychange事件;
3.2.3.1 三大規則場景的界定
上文我們已經在實踐中總結出了自動採集的三大場景,在實際應用針對三大場景的使用我們也總結出了一套界定方案。
(1)規則一界定——怎麼判斷頁面切換?
a、現在的網站要麼是MPA,要麼是SPA模式,或者兩種模式混合,MPA主要是後臺路由,SPA主要是前端路由(hash模式和history模式)。但無論是SPA還是MPA,當頁面需要切換時,url一定會變化,基於此點,我們判斷當url變化時,用戶一定切換了頁面。此時觸發規則一的事件,產生數據上報。
這裡需要註意2個問題:
-
第1個問題:url變化 = window.location.origin + window.location.pathname + window.location.hash 這三部分的任一部分變化,即為url變化,並不包括window.location.search這部分的變化;
-
第2個問題:在SPA中,如果一個頁面內有多個tab,當切換tab時,開發者也改變他的url的window.location.pathname,此時也會認為是頁面切換,也會產生上報數據,如下這種情況。
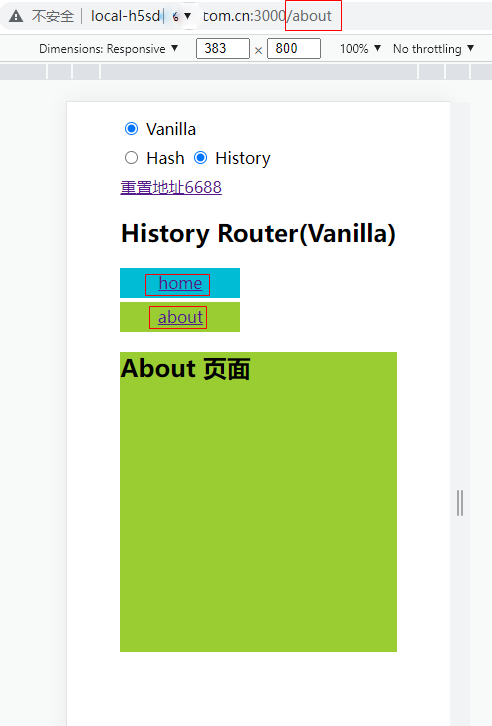
圖(2)
b、完整頁面切換上報流程,由頁面A切換到頁面B時,一共上報4個埋點;
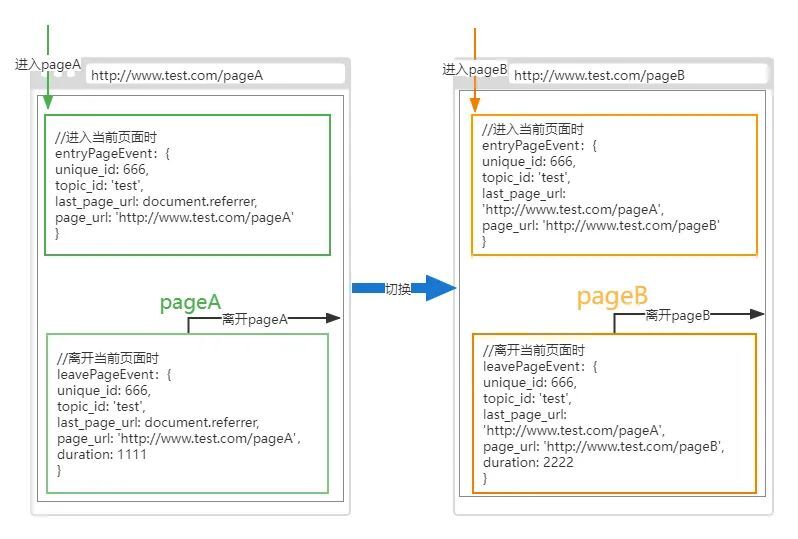 圖(3)
圖(3)
c、關於路由的EventListener
現在的大多網站,大多是SPA應用,SPA的前端路由有hash模式和history模式這兩種模式,當通過前端路由來頁面切換時,肯定會觸發hash模式或history相關的api。
因此,我們只需要把所有觸發事件的場景給全部進行EventListener即可。有如下2種路由的EventListener:window.hashchange事件——觸發hash模式時、window.popstate事件、pushstate,replacestate自定義事件——觸發history模式時。
這裡有2個問題需要關註:一是當某個SPA應用的路由事件,觸發了history模式時,我們應該移除hash模式的EventListener。二是pushstate,replacestate自定義事件,因為BOM並沒有提供相關的api支持EventListener,需要自行封裝使用,如下code。
引入JSSDK
/**
* 拼接通用化上報參數
* @param {string} 重寫路由事件類型
*/
function resetHistoryFun(type){
// 將原先的方法複製出來
let originMethod = window.history[type]
// 當window.history[type]函數被執行時,這個return出來的函數就會被執行
return function(){
// 執行原先的方法
let rs = originMethod.apply(this, arguments)
// 然後自定義事件
let e = new Event(type.toLocaleLowerCase())
// 將原先函數的參數綁定到自定義的事件上去,原先的是沒有的
e.arguments = arguments
// 然後用window.dispatchEvent()主動觸發
window.dispatchEvent(e)
return rs;
}
}
window.history.pushState = resetHistoryFun('pushState') // 覆蓋原來的pushState方法
window.history.replaceState = resetHistoryFun('replaceState') // 覆蓋原來的replaceState方法
window.addEventListener('pushstate', reportBothEvent)
window.addEventListener('replacestate', reportBothEvent)
(2)規則二界定——怎麼判斷頁面失去焦點,得到焦點?
失去焦點,得到焦點。我們主要進行如下這兩個事件的EventListener:
引入JSSDK
window.addEventListener('focus', ()=>{
console.log('頁面得到焦點')
});
window.addEventListener('blur', ()=>{
console.log('頁面失去焦點')
})
(3)規則三界定——怎麼判斷瀏覽器tab切換離開,切換回來?
tab切換離開,切換回來。我們主要進行如下這一個事件的EventListener:
引入JSSDK
document.addEventListener('visibilitychange', () => {
if(document.hidden) {
console.log('頁面離開')
} else {
console.log('頁面進入')
}
})
註意:如果一個行為同時滿足2個及2個以上的規則時,只會取一個規則上報數據。避免不重覆上報數據。
3.3 埋點設計
3.3.1 埋點個數
為了得到pv和uv的相關數據,我們設計了2個埋點,1個為頁面進入時上報的埋點,另外1個為頁面離開時的埋點,上報的數據都是一對的,離開-進入頁面為一對,失去焦點-得到焦點為一對,切換tab離開當前頁面-返回當前頁面也為一對;
為什麼要設計2個埋點?設計2個埋點,能覆蓋全面上述我們所說的3種規則場景;其次,方面計算頁面停留時長;最後就是方便邏輯判斷,避免重覆上報;
3.3.2 參數的設計
按照不同的需求,參數的設計分為如下4類:
-
pv,uv需要參數,開發者傳入參數:unique_id——標識用戶唯一標識、topic_id——當前網站唯一標識、current_env——當前網站環境,預設為prod,可用戶傳入;
-
pv,uv需要參數,sdk內部獲取參數:duration——頁面停留時長、last_page_url——上個頁面url、page_url——當前頁面url;
-
SDK需要的參數,幫助判斷事件觸發類型,SDK內部獲取參數:eventType
-
用戶其他需要補充的參數:自定義參數
3.4 數據上報
數據上報方式是XMLHttpRequest、window.navigator.sendBeacon,基於h5sdk上報邏輯架構。
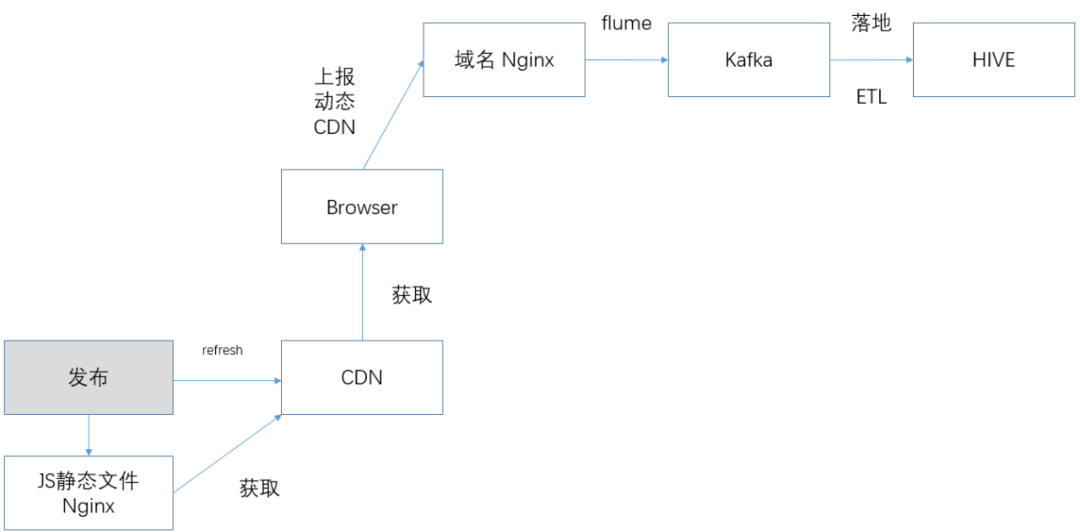 圖(4)
圖(4)
3.5 相容性和容錯性
關於相容性,依賴於window對象、不相容IE6、IE7,IE8;
關於容錯性,對通用化內部邏輯做了try catch的容錯相容,保證出錯時不影響業務主邏輯運行,同時上報一個出錯的事件類型,知道出錯的原因,以便提前做好對應的優化方案。
3.6 個人數據保護合規
為了保護好用戶的個人數據及其隱私並滿足法律法規要求,在埋點的設計、採集、使用等環節需要進行充分的隱私保護設計。例如,在埋點設計階段,需要確定標識符的選擇、埋點參數的最小必要、採集頻率的最小必要等;在埋點的採集、使用階段,需要確保相關處理行為的透明、可控,包括對用戶進行告知,獲取用戶的有效同意,提供撤回同意的渠道等等。
四、數倉方案
埋點方案已經具備,接下來的工作就是設計一套接入高效,拓展便捷的數倉分析模型;為實現以上既定的分析目標,模型設計過程中需要解決以下核心問題。
4.1 核心問題列表

4.2 模型分層標準
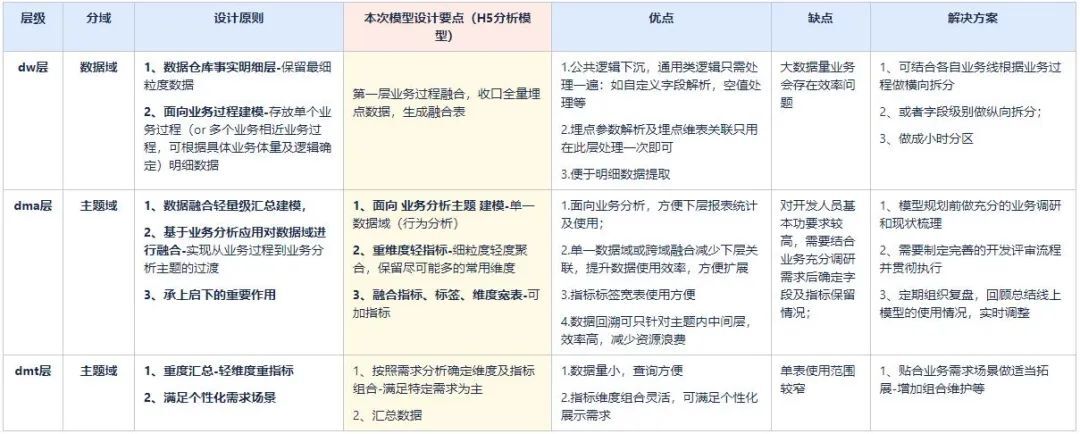
介紹模型設計前,先說下vivo 數倉模型分層基本原則,及本次模型分層思路,各層模型設計原則參照《vivo中台數倉建設方法論》,層級設計摘要如下:
4.3 模型層級架構
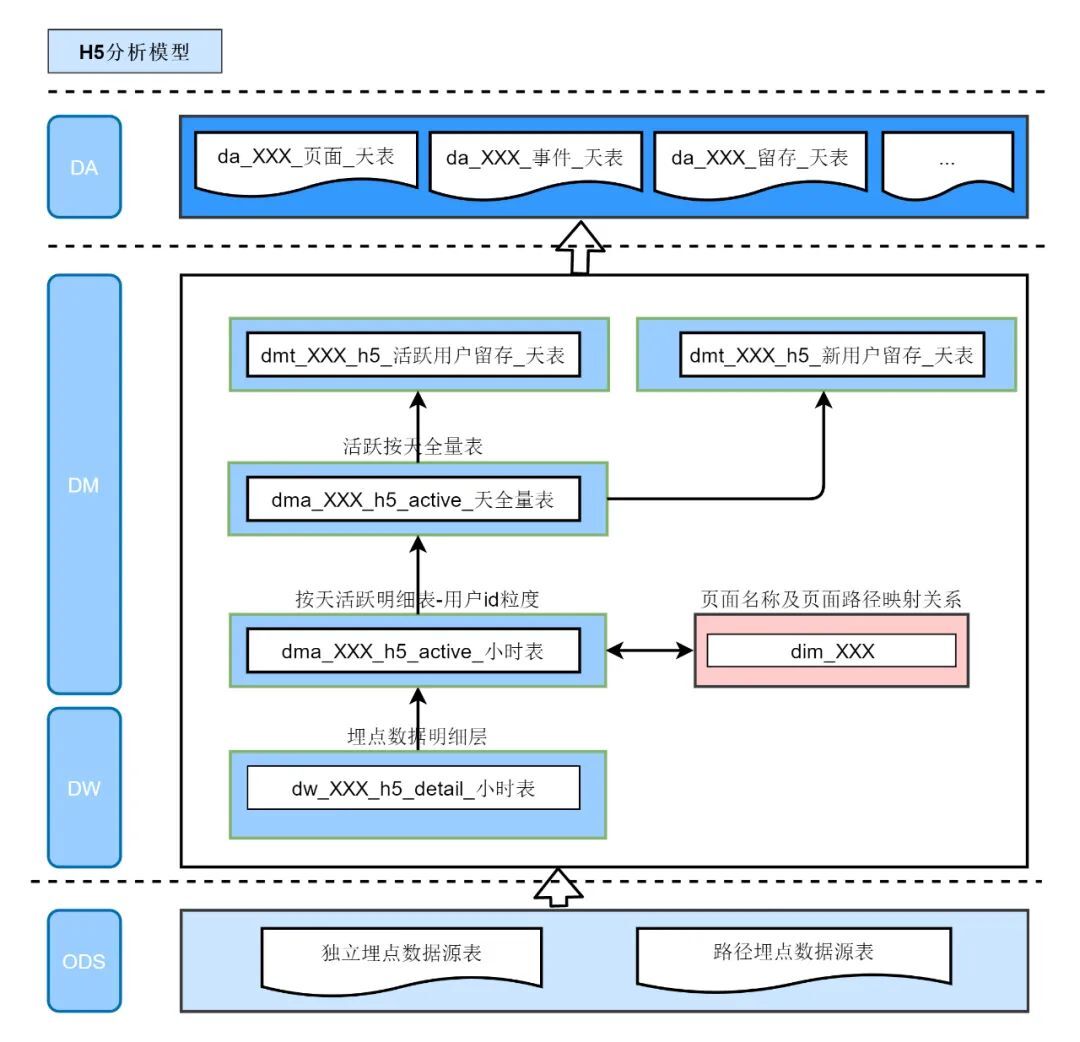
通過核心問題拆解發現,為實現通用分析模型方案,需要從數據接入層收口,在數據接入時統一參數解析,統一欄位命名,並設置相應的應用id欄位,區分各個業務數據源;接著需要生成活躍數據明細表,可統計相應的基礎分析,頁面分析指標;同時為滿足留存分析的需要,我們需要構建相應的活躍全量表,留存分析主題表基於活躍增量表和活躍全量表生成,用戶活躍信息通過打標簽的方式標記。至此涉及三個主題分析的模型規劃完畢。層級劃分原則及規劃邏輯模型明細,如:圖(5)
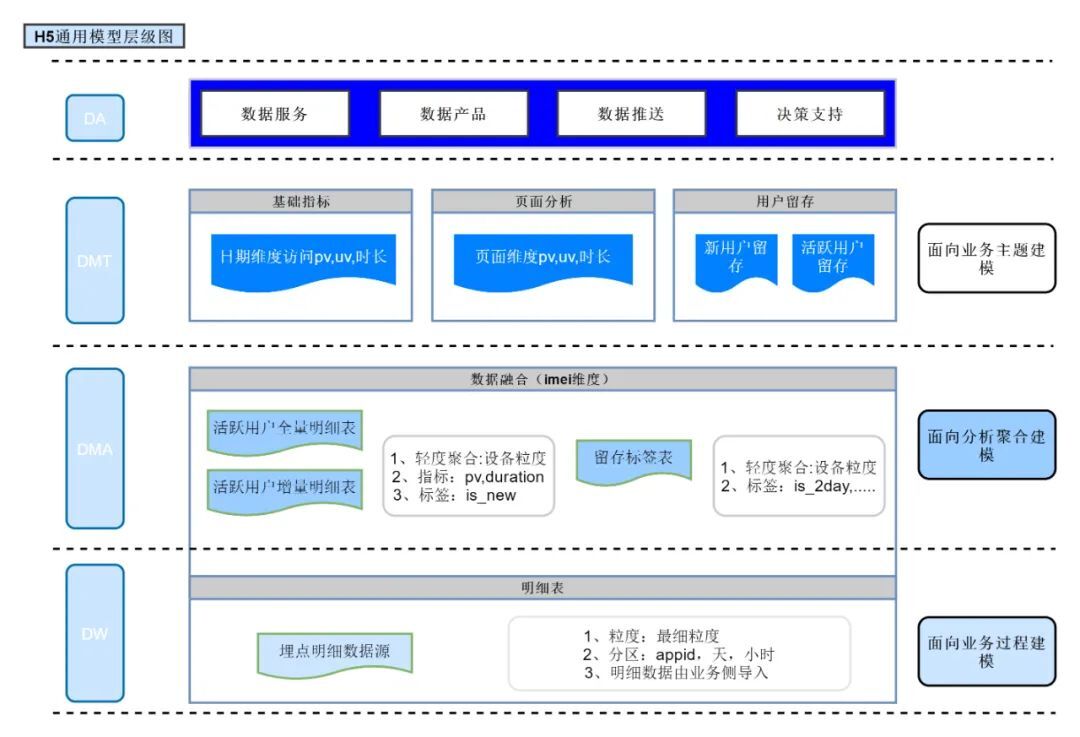
圖(5)
從分層架構圖可看出H5通用分析模型分為明細層(dw)、輕度彙總層(dma)、分析主題表 (dmt) 和指標層(da); 其中輕度彙總層可作為中間數據提供行業分析師及數據開發、業務產品等查詢分析使用;彙總層作為分析平臺通用分析模型報表數據源,導入mysql存儲,前端基於mysql表實現數據展示,各個模型設計細則如下:
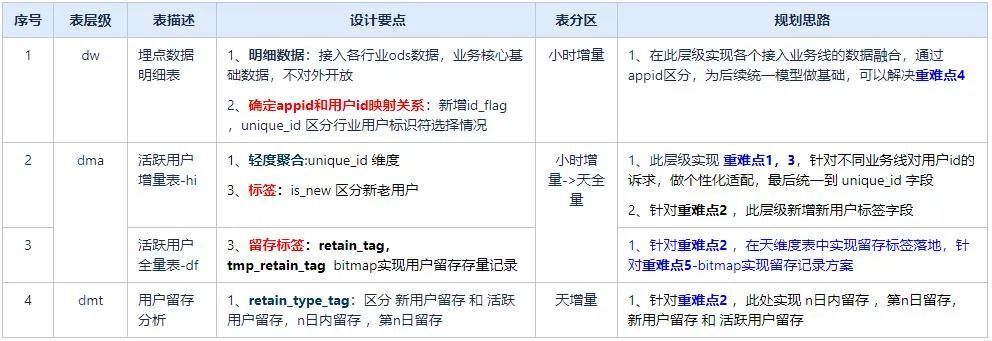
數據模型規劃及設計的核心在於三點:確定appid和用戶id映射關係,留存方案實現及留存記錄入庫bitmap方式讀寫。
1、確定appid和用戶id映射關係-unique_id 關聯設計
多業務id統一
## 明細層收口數據,統一id欄位
SELECT xx
,xx1
,CASE WHEN appid IN(1) THEN 1
WHEN appid IN(2) THEN 2
WHEN appid IN(3) THEN 3
WHEN appid IN(4,5,6,...) THEN 4
ELSE 0 END AS id_flag
,CASE WHEN appid IN(1) THEN id1
WHEN appid IN(2) THEN id2
WHEN appid IN(3) THEN id3
WHEN appid IN(4,5,6,...) THEN IF(NVL(params['id1'],'')='',NVL(params['id2'],'NA'),params['id1'])
ELSE 'NA' END AS unique_id
,appid
FROM ods_table_name_XXX a -- 各個接入業務線數據源 ods
WHERE day='${today}'
AND hour = '${etl_hour}'
-- APPID 和 事件id 要匹配新增
AND appid in (1,2,3 ...)
AND 事件id in (XXX|167,XXX|168,...);
## id欄位後續關聯使用方式
## 增量關聯全量,確定是否新用戶
SELECT if(b.unique_id is null,1,0) AS is_new
FROM
(
SELECT *
FROM table_XXX_hi
WHERE day= '${today}'
AND hour = '${etl_hour}'
GROUP BY XX
) a
-- 取全量表唯一 unique_id 作為關聯條件,判斷新老用戶
-- 新用戶是相對於歷史全量的
LEFT JOIN ( SELECT unique_id,appid
FROM
( SELECT unique_id
,appid
,row_number() over(partition by unique_id,appid order by 活躍日期 asc) as rn_0
FROM table_XXX_df
WHERE day='${etl_date}'
) a
WHERE rn_0 = 1
) b
ON a.unique_id = b.unique_id AND a.appid = b.appid;
2、留存方案實現及留存記錄入庫bitmap方式讀寫
留存方案
## 利用bitmap思想,留存標簽滿8位轉化為16進位組合到retain_tag之前,這樣可以利用很少的位數記錄較長的活躍情況
## 示例代碼如下
SELECT user_unique_id
,if(length(tmp_retain_tag) = 8,is_active,concat(is_active,tmp_retain_tag)) as tmp_retain_tag
-- 如果tmp_retain_tag長度為8的時候,將數據轉化為十六進位添加到retain_tag前,並將本欄位清空,從頭開始計數
,if(length(tmp_retain_tag) = 8,concat(con_tmp_retain_tag,retain_tag),retain_tag) as retain_tag
,is_active
FROM
(
SELECT unique_id
-- 前一天的臨時存儲,與con_tmp_retain_tag保持一致
,tmp_retain_tag
-- 如果轉換為十六進位後的長度不為2,則在左邊添加0
,if(length(conv(tmp_retain_tag,2,16)) = 2,conv(tmp_retain_tag,2,16),concat('0',conv(tmp_retain_tag,2,16))) as con_tmp_retain_tag
-- 歷史軌跡
,retain_tag
,first_value(is_active) over(partition by unique_id,appid,topic_id order by first_active_day desc) as is_active
FROM
( SELECT unique_id
,topic_id
,appid
,first_active_day
,last_active_day
-- 留存標簽
,'0' as is_active
,tmp_retain_tag -- 形如 11101010
,retain_tag -- 形如 A0E3
FROM table_active_XX_df -- 活躍全量表
WHERE day= '${last_etl_date}'
UNION ALL
SELECT unique_id
,topic_id
,appid
,day as first_active_day
,day as last_active_day
-- 留存標簽
,'1' as is_active
,'' as tmp_retain_tag
,'' as retain_tag
FROM table_active_XX_hi -- 活躍明細表
WHERE day= '${etl_date}'
) a
) b
WHERE rn =1;
## 留存指標統計:## 以3日內及第3日留存為例
WITH tmp_table AS (
SELECT DAY
,unique_id
,appid
,首次活躍日期
,CONCAT(tmp_retain_tag,retain_tag) AS login_trace
FROM (
SELECT DAY
,unique_id
,tmp_retain_tag
,appid
,首次活躍日期
,IF(nvl(retain_tag,'') <> '',CONV(SUBSTR(retain_tag,1,8),16,2),'') AS retain_tag
-- 如果retain_tag為空時,直接取空值。如果長度超過8位數,取最後八位數;如果長度不超過8位數,取全部。如果是30日內新用戶,長度不超過8位
FROM table_active_XX_df WHERE DAY = 統計日
) x1
)
## 以3日內及第3日留存為例:
SELECT -- 第N日留存指標:第N日來訪
,SUM(IF(SUBSTR(login_trace,3,1) = '1',1,null)) AS retain_cnt_3th
-- N日內留存指標:N日內訪問過1次或N次
,SUM(IF(instr(SUBSTR(login_trace,2,2) ,'1')= 0,null,1)) AS retain_cnt_between_3th
FROM (
SELECT '統計日-2天' AS dt
,unique_id
,REVERSE(SUBSTR(login_trace,1,3)) AS login_trace
,appid
FROM tmp_table WHERE SUBSTR(login_trace,3,1) = '1' AND 首次活躍日期 = 統計日-2天
) X GROUP BY dt,appid;
4.4 模型數據流圖
至此,模型的設計落地全部完成,模型包含埋點數據表2張,dw明細層模型1張,維表1張,dma輕度彙總主題層2張,dmt主題表2張,任務層深4層,模型層2層,模型數據接入0.5人日可完成。
數據流圖如下:
 圖(6)
圖(6)
五、數據展示
模型數據展示可基於用戶行為分析平臺,數據指標存儲使用 MySQL 資料庫,數據展示邏輯實現如下:
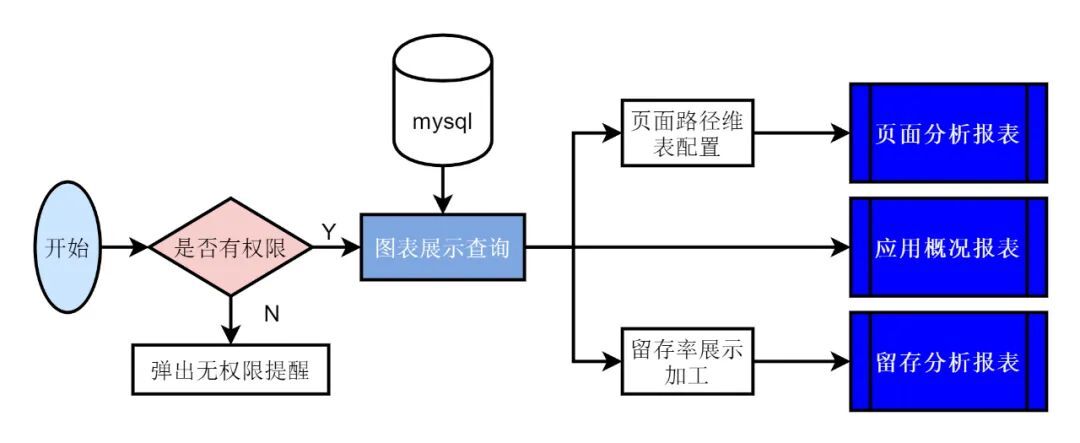
圖(7)
5.1 報表展示
報表配置完成後,各個分析模塊的前臺展示示例如下:
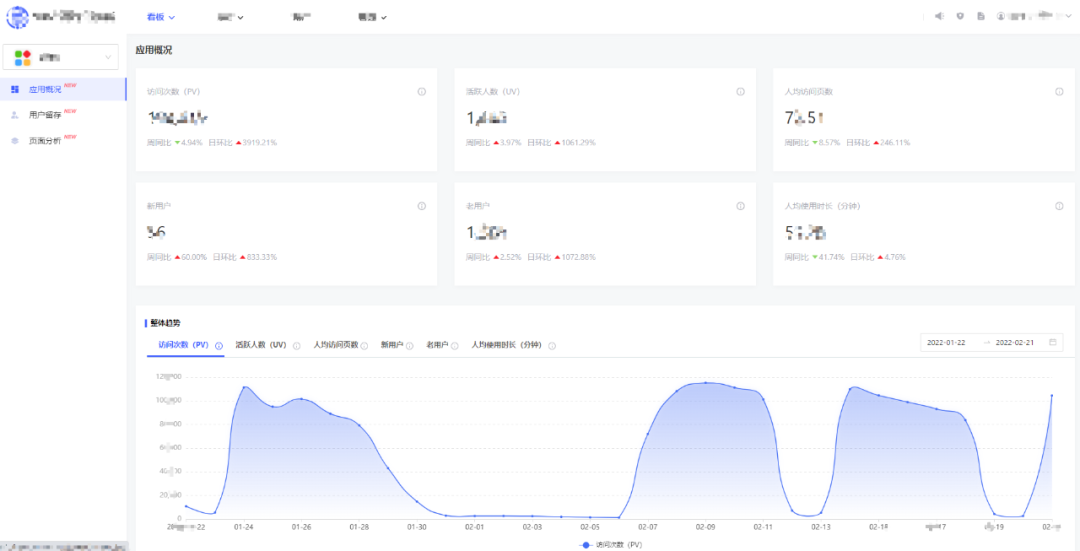 圖(8)應用概況報表
圖(8)應用概況報表
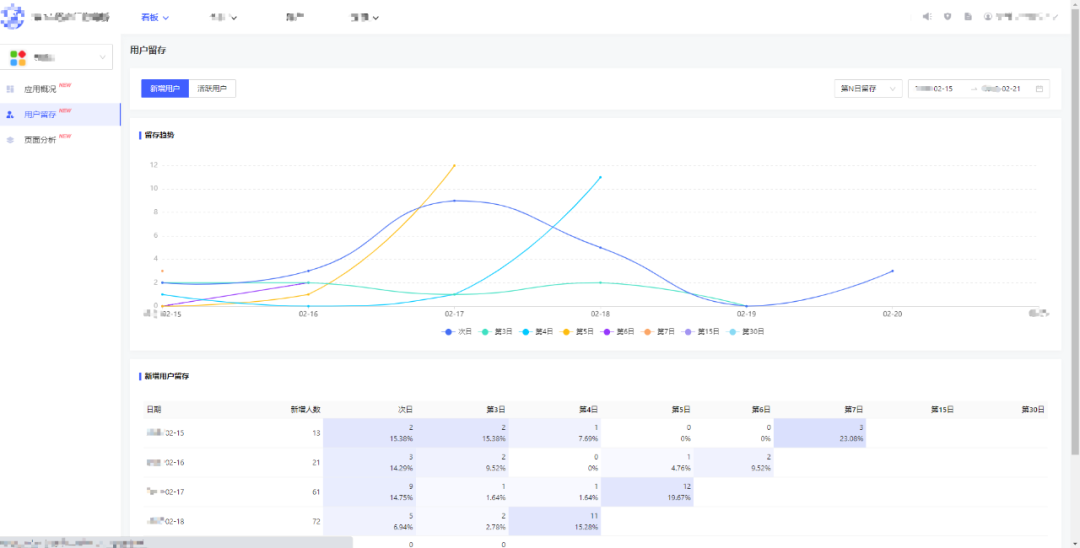 圖(9)用戶留存報表
圖(9)用戶留存報表
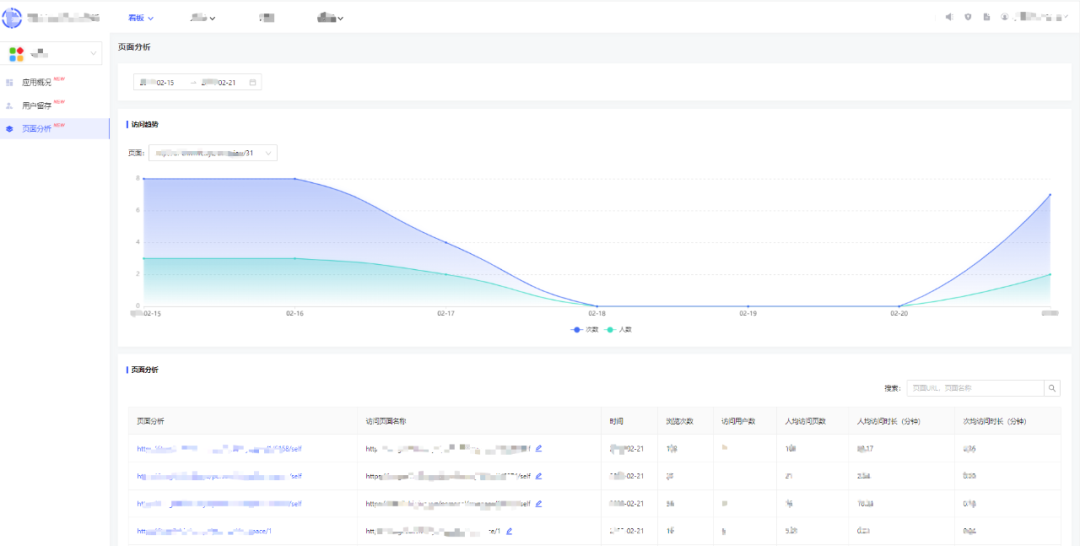 圖(10)頁面分析報表
圖(10)頁面分析報表
六、未來展望
至此,H5通用分模型落地流程已介紹完畢。本文主要是基於業務初期訴求,快速落地通用的、統一的數據解決方案,滿足業務分析人員在產品初期最迫切的分析需求。隨著業務的不斷發展迭代,運營產品的分析方向也會不斷的擴展和深入,同時不同的業務關註點不同,針對分析模型的訴求也不盡相同。例如在業務中後期,簡單的訪問留存分析已經支撐不了更進一步的決策制定,此時針對頁面訪問的路徑分析模型;針對營銷分析的訂單轉化模型、歸因分析模型;針對頁面跳轉分析的用戶漏斗模型等需求會相應變多。
所以,為更好的支撐業務目標達成,H5通用分析模型系列在後期會根據業務訴求落地相應的分析模型,持續為產品運營提供高效穩定的數據解決方案。
相關文章:
分享 vivo 互聯網技術乾貨與沙龍活動,推薦最新行業動態與熱門會議。

