
上一篇文章中我們聊了Caffeine的同步、非同步的數據回源方式。本篇文章我們再一起研討下經Caffeine改良過的非同步數據驅逐處理實現,以及Caffeine支持的多種不同的數據淘汰驅逐機制和對應的實際使用。 ...
一、選題的背景
為了實現對水果和蔬菜的分類識別,收集了香蕉、蘋果、梨、葡萄、橙子、獼猴桃、西瓜、石榴、菠蘿、芒果、黃瓜、胡蘿蔔、辣椒、洋蔥、馬鈴薯、檸檬、番茄、蘿蔔、甜菜根、捲心菜、生菜、菠菜、大豆、花椰菜、甜椒、辣椒、蘿蔔、玉米、甜玉米、紅薯、辣椒粉、生薑、大蒜、豌豆、茄子共36種果蔬的圖像。該項目使用resnet18網路進行分類。
二、機器學習案例設計方案
1.本選題採用的機器學習案例(訓練集與測試集)的來源描述
數據集來自百度AI studio平臺(https://aistudio.baidu.com/aistudio/datasetdetail/119023/0),共包含36種果蔬,每一個類別包括100張訓練圖像,10張測試圖像和10張驗證圖像。
2 採用的機器學習框架描述
本次使用的網路框架,主要用到了二維捲積、激活函數、最大池化、Dropout和全連接,下麵將對搭建的網路模型進行解釋。
首先是一個二維捲積層,輸入通道數為3,輸出通道數為100,捲積核大小是3*3,填充大小是1*1。輸入通道數為3是因為這個是第一層捲積,輸入的是RGB圖像,具有三個通道,輸出通道數量可以根據實際情況自定。填充是因為希望在捲積後,不要改變圖像的尺寸。
在捲積層之後是一個RELU激活函數,如果不用激活函數,在這種情況下每一層輸出都是上層輸入的線性函數。容易驗證,無論神經網路有多少層,輸出都是輸入的線性組合,與沒有隱藏層效果相當。因此引入非線性函數作為激活函數,這樣深層神經網路就有意義了(不再是輸入的線性組合,可以逼近任意函數)。最早的想法是sigmoid函數或者tanh函數,輸出有界,很容易充當下一層輸入。
引入RELU激活函數有以下三個原因:
第一,採用sigmoid等函數,算激活函數時(指數運算),計算量大,反向傳播求誤差梯度時,求導涉及除法,計算量相對大,而採用Relu激活函數,整個過程的計算量節省很多。
第二,對於深層網路,sigmoid函數反向傳播時,很容易就會出現 梯度消失 的情況(在sigmoid接近飽和區時,變換太緩慢,導數趨於0,這種情況會造成信息丟失),從而無法完成深層網路的訓練。
第三,ReLu會使一部分神經元的輸出為0,這樣就造成了 網路的稀疏性,並且減少了參數的相互依存關係,緩解了過擬合問題的發生。
然後再跟一個二維捲積層,輸入通道數應該和上一層捲積的輸出通道數相同,所以設為100, 輸出通道數同樣根據實際情況設定,此處設為150,其他參數與第一層捲積相同。
後續每一個捲積層和全連接層後面都會跟一個RELU激活函數,所以後面不再敘述RELU激活函數層。
再之後添加一個2*2的最大池化層,該層用來縮減模型的大小,提高計算速度,同時提高所提取特征的魯棒性。
再經過三次捲積後,使用Flatten將二維Tensor拉平,變為一維Tensor,然後使用全連接層,通過多個全連接層後,使用dropout層隨機刪除一些結點,該方法可以有效的避免網路過擬合,在最後一個全連接層的輸出對應需要分類的個數。
3.涉及到的技術難點與解決思路
下載的數據集沒有劃分訓練集、測試集和驗證集,需要自己寫代碼完成劃分。在剛開始寫代碼的時候對於文件路徑沒有搞清楚,沒有弄懂os.path.join方法如何使用,導致總是讀取不到圖像,並且代碼還沒有報錯誤正常運行結束,但是查看劃分後的文件夾里沒有數據。通過debug發現文件的路徑出現問題,具體是windows下的/和\混用,導致不能正確的對路徑進行處理。在排除問題後統一使用\\,最終問題得到解決。
三、機器學習的實現步驟
(1)劃分數據集併進行縮放
1 import os 2 import glob 3 import random 4 import shutil 5 from PIL import Image 6 #對所有圖片進行RGB轉化,並且統一調整到一致大小,但不讓圖片發生變形或扭曲,劃分了訓練集和測試集 7 8 if __name__ == '__main__': 9 test_split_ratio = 0.05 #百分之五的比例作為測試集 10 desired_size = 128 # 圖片縮放後的統一大小 11 raw_path = './raw' 12 13 #把多少個類別算出來,包括目錄也包括文件 14 dirs = glob.glob(os.path.join(raw_path, '*')) 15 #進行過濾,只保留目錄,一共36個類別 16 dirs = [d for d in dirs if os.path.isdir(d)] 17 18 print(f'Totally {len(dirs)} classes: {dirs}') 19 20 for path in dirs: 21 # 對每個類別單獨處理 22 23 #只保留類別名稱 24 path = path.split('/')[-1] 25 print(path) 26 #創建文件夾 27 os.makedirs(f'train/{path}', exist_ok=True) 28 os.makedirs(f'test/{path}', exist_ok=True) 29 30 #原始文件夾當前類別的圖片進行匹配 31 files = glob.glob(os.path.join( path, '*.jpg')) 32 # print(raw_path, path) 33 34 files += glob.glob(os.path.join( path, '*.JPG')) 35 files += glob.glob(os.path.join( path, '*.png')) 36 37 random.shuffle(files)#原地shuffle,因為要取出來驗證集 38 39 boundary = int(len(files)*test_split_ratio) # 訓練集和測試集的邊界 40 41 for i, file in enumerate(files): 42 img = Image.open(file).convert('RGB') 43 44 old_size = img.size 45 46 ratio = float(desired_size)/max(old_size) 47 48 new_size = tuple([int(x*ratio) for x in old_size])#等比例縮放 49 50 im = img.resize(new_size, Image.ANTIALIAS)#後面的方法不會造成模糊 51 52 new_im = Image.new("RGB", (desired_size, desired_size)) 53 54 #new_im在某個尺寸上更大,我們將舊圖片貼到上面 55 new_im.paste(im, ((desired_size-new_size[0])//2, 56 (desired_size-new_size[1])//2)) 57 58 assert new_im.mode == 'RGB' 59 60 if i <= boundary: 61 new_im.save(os.path.join(f'test/{path}', file.split('\\')[-1].split('.')[0]+'.jpg')) 62 else: 63 new_im.save(os.path.join(f'train/{path}', file.split('\\')[-1].split('.')[0]+'.jpg')) 64 65 test_files = glob.glob(os.path.join('test', '*', '*.jpg')) 66 train_files = glob.glob(os.path.join('train', '*', '*.jpg')) 67 68 print(f'Totally {len(train_files)} files for training') 69 print(f'Totally {len(test_files)} files for test')
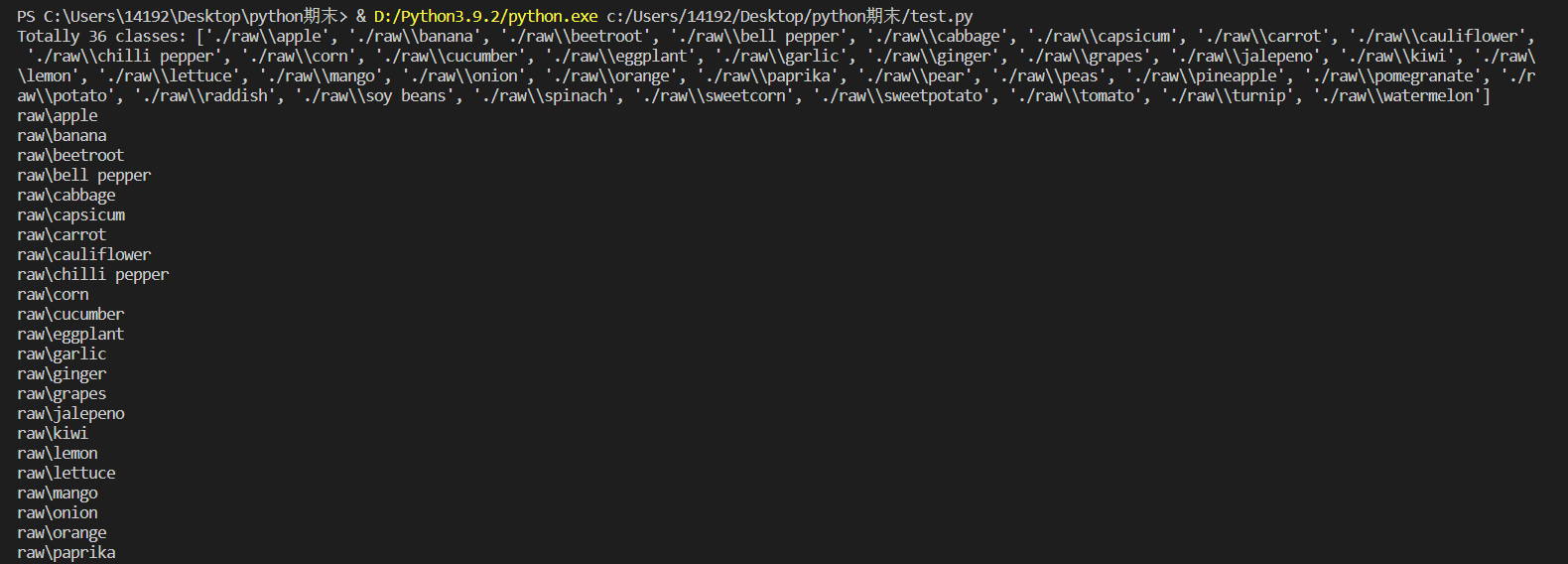
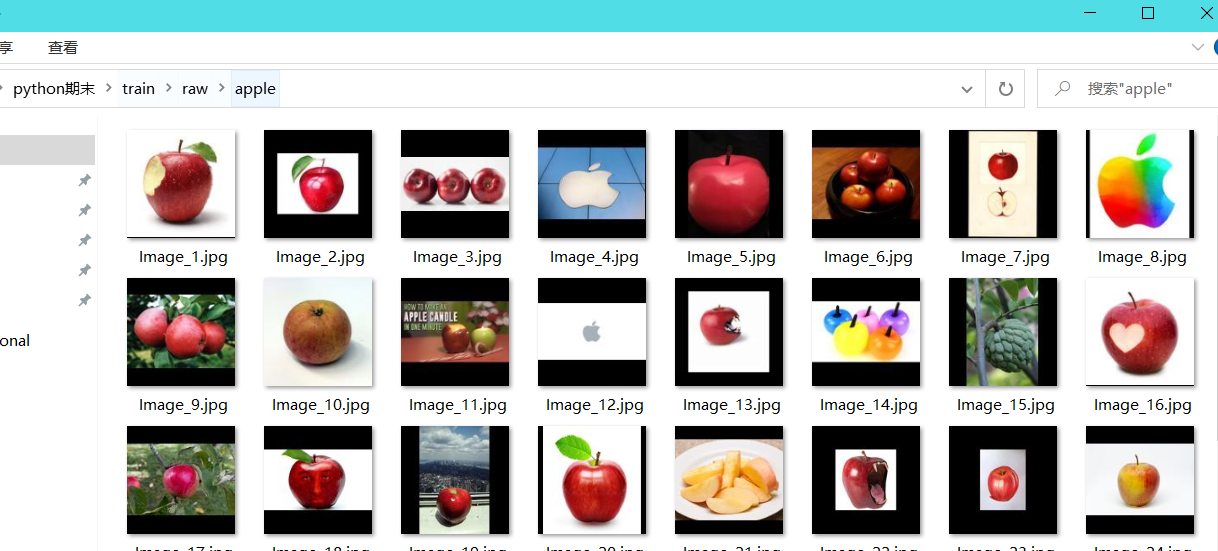
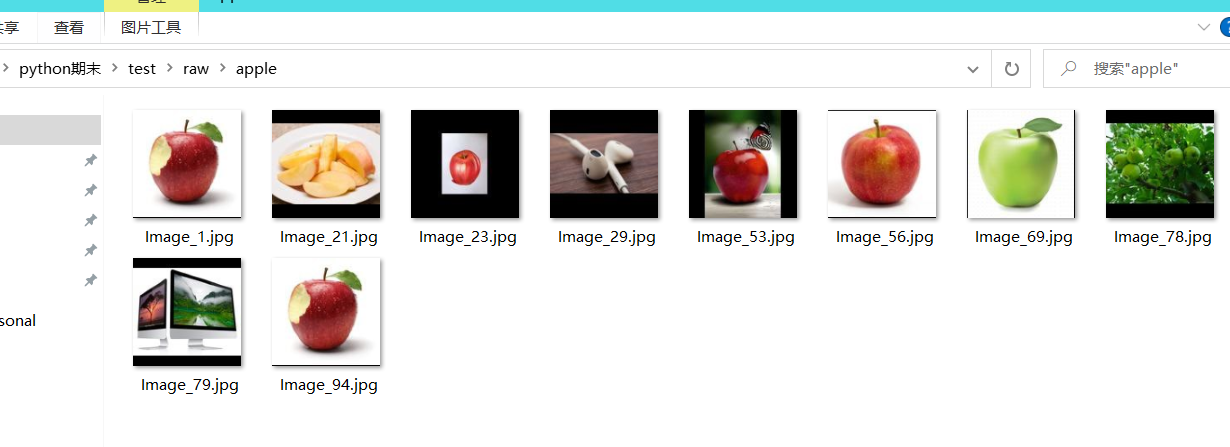
(2)圖像預處理
包括隨即旋轉、隨機翻轉、裁剪等,併進行歸一化。
1 #圖像預處理 2 train_dir = './train' 3 val_dir = './test' 4 test_dir = './test' 5 classes0 = os.listdir(train_dir) 6 classes=sorted(classes0) 7 print(classes) 8 train_transform=transforms.Compose([ 9 transforms.RandomRotation(10), # 旋轉+/-10度 10 transforms.RandomHorizontalFlip(), # 反轉50%的圖像 11 transforms.Resize(40), # 調整最短邊的大小 12 transforms.CenterCrop(40), # 作物最長邊 13 transforms.ToTensor(), 14 transforms.Normalize([0.485, 0.456, 0.406], 15 [0.229, 0.224, 0.225]) 16 ])
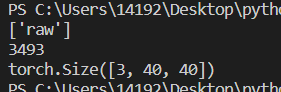
1 #顯示圖像 2 def show_image(img,label): 3 print('Label: ', trainset.classes[label], "("+str(label)+")") 4 plt.imshow(img.permute(1,2,0)) 5 plt.show() 6 7 show_image(*trainset[10]) 8 show_image(*trainset[20])
(3)讀取數據
1 batch_size = 64 2 train_loader = DataLoader(train_ds, batch_size, shuffle=True, num_workers=4, pin_memory=True) 3 val_loader = DataLoader(val_ds, batch_size*2, num_workers=4, pin_memory=True) 4 test_loader = DataLoader(test_ds, batch_size*2, num_workers=4, pin_memory=True)
(4)構建CNN模型
#構建CNN模型
1 #構建CNN模型 2 class CnnModel(ImageClassificationBase): 3 def __init__(self): 4 super().__init__() 5 #cnn提取特征 6 self.network = nn.Sequential( 7 nn.Conv2d(3, 100, kernel_size=3, padding=1),#Conv2D層 8 nn.ReLU(), 9 nn.Conv2d(100, 150, kernel_size=3, stride=1, padding=1), 10 nn.ReLU(), 11 nn.MaxPool2d(2, 2), #池化層 12 13 nn.Conv2d(150, 200, kernel_size=3, stride=1, padding=1), 14 nn.ReLU(), 15 nn.Conv2d(200, 200, kernel_size=3, stride=1, padding=1), 16 nn.ReLU(), 17 nn.MaxPool2d(2, 2), 18 19 nn.Conv2d(200, 250, kernel_size=3, stride=1, padding=1), 20 nn.ReLU(), 21 nn.Conv2d(250, 250, kernel_size=3, stride=1, padding=1), 22 nn.ReLU(), 23 nn.MaxPool2d(2, 2), 24 25 #全連接 26 nn.Flatten(), 27 nn.Linear(6250, 256), 28 nn.ReLU(), 29 nn.Linear(256, 128), 30 nn.ReLU(), 31 nn.Linear(128, 64), 32 nn.ReLU(), 33 nn.Linear(64, 32), 34 nn.ReLU(), 35 nn.Dropout(0.25), 36 nn.Linear(32, len(classes))) 37 38 def forward(self, xb): 39 return self.network(xb)
(5)訓練網路
#訓練網路
1 #訓練網路 2 @torch.no_grad() 3 def evaluate(model, val_loader): 4 model.eval() 5 outputs = [model.validation_step(batch) for batch in val_loader] 6 return model.validation_epoch_end(outputs) 7 8 def fit(epochs, lr, model, train_loader, val_loader, opt_func=torch.optim.SGD): 9 history = [] 10 optimizer = opt_func(model.parameters(), lr) 11 for epoch in range(epochs): 12 # 訓練階段 13 model.train() 14 train_losses = [] 15 for batch in tqdm(train_loader,disable=True): 16 loss = model.training_step(batch) 17 train_losses.append(loss) 18 loss.backward() 19 optimizer.step() 20 optimizer.zero_grad() 21 # 驗證階段 22 result = evaluate(model, val_loader) 23 result['train_loss'] = torch.stack(train_losses).mean().item() 24 model.epoch_end(epoch, result) 25 history.append(result) 26 return history 27 28 model = to_device(CnnModel(), device) 29 30 history=[evaluate(model, val_loader)] 31 32 num_epochs = 100 33 opt_func = torch.optim.Adam 34 lr = 0.001 35 36 history+= fit(num_epochs, lr, model, train_dl, val_dl, opt_func)
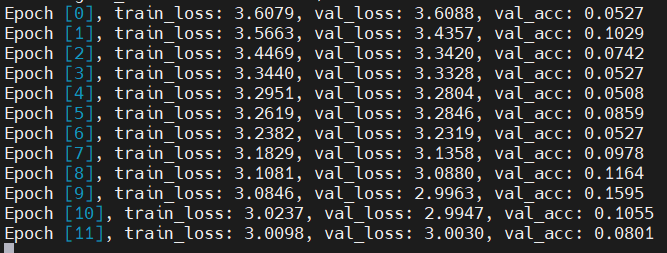
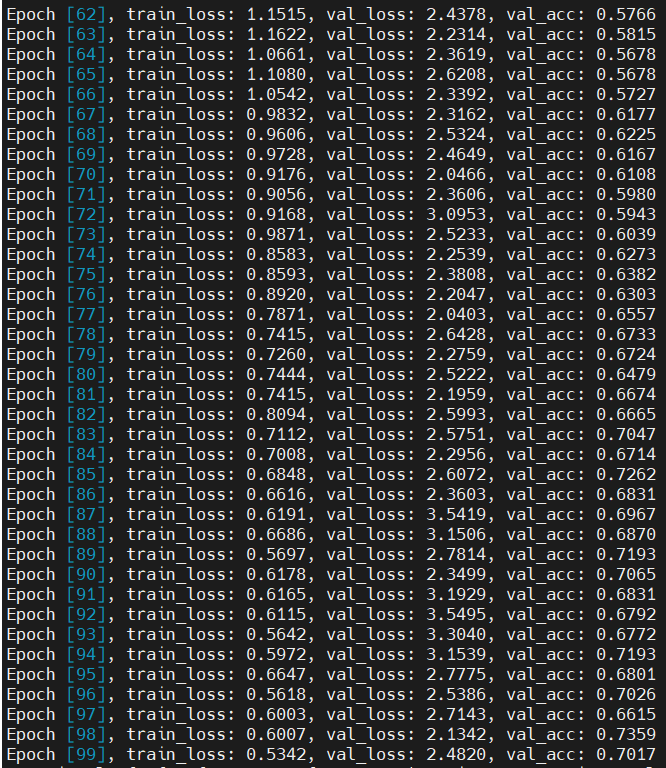
(6)繪製損失函數和準確率圖
1 def plot_accuracies(history): 2 accuracies = [x['val_acc'] for x in history] 3 plt.plot(accuracies, '-x') 4 plt.xlabel('epoch') 5 plt.ylabel('accuracy') 6 plt.title('Accuracy vs. No. of epochs') 7 plt.show() 8 9 def plot_losses(history): 10 train_losses = [x.get('train_loss') for x in history] 11 val_losses = [x['val_loss'] for x in history] 12 plt.plot(train_losses, '-bx') 13 plt.plot(val_losses, '-rx') 14 plt.xlabel('epoch') 15 plt.ylabel('loss') 16 plt.legend(['Training', 'Validation']) 17 plt.title('Loss vs. No. of epochs') 18 plt.show() 19 20 plot_accuracies(history) 21 plot_losses(history) 22 23 evaluate(model, test_loader)
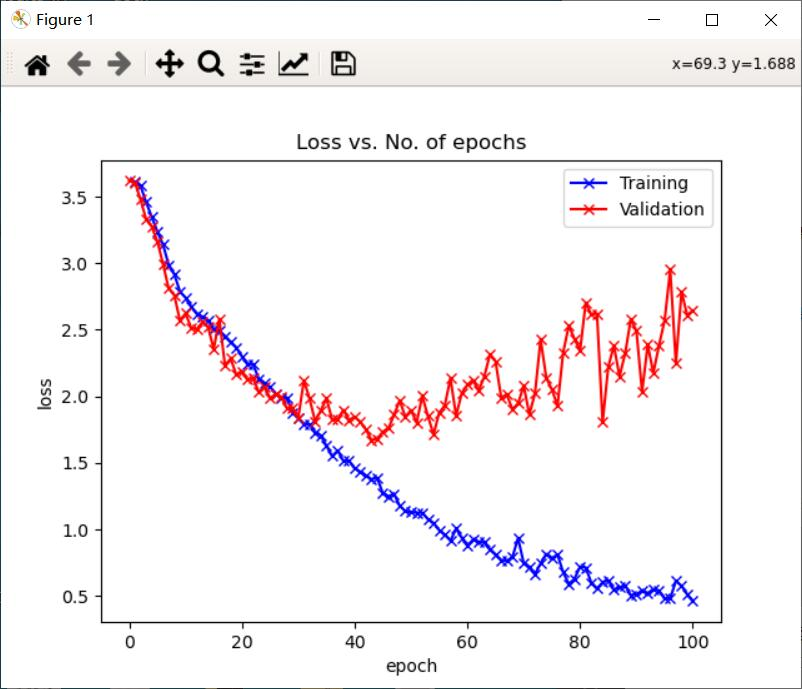
(7)預測
1 #預測分類 2 y_true=[] 3 y_pred=[] 4 with torch.no_grad(): 5 for test_data in test_loader: 6 test_images, test_labels = test_data[0].to(device), test_data[1].to(device) 7 pred = model(test_images).argmax(dim=1) 8 for i in range(len(pred)): 9 y_true.append(test_labels[i].item()) 10 y_pred.append(pred[i].item()) 11 12 from sklearn.metrics import classification_report 13 print(classification_report(y_true,y_pred,target_names=classes,digits=4))

(8)讀取圖片測試
1 import numpy as np 2 from PIL import Image 3 import matplotlib.pyplot as plt 4 import torchvision.transforms as transforms 5 6 def predict(img_path): 7 img = Image.open(img_path) 8 plt.imshow(img) 9 plt.show() 10 img = img.resize((32,32)) 11 img = transforms.ToTensor()(img) 12 img = img.unsqueeze(0) 13 img = img.to(device) 14 pred = model(img).argmax(dim=1) 15 print('預測結果為:',classes[pred.item()]) 16 return classes[pred.item()] 17 18 predict('./raw/apple/Image_1.jpg')


四、總結
在本次課程設計中,使用深度學習的方法實現了果蔬的36分類,相對來說分類數量是比較多的,在訓練了100個epoch以後,分類的準確率可以達到74.3%。通過對果蔬的分類,我明白了當訓練集的圖像數量較少時,可以採用數據增強對原始圖像進行處理,獲得更多的數據來增強網路的泛化能力,避免網路過擬合。數據增強的方法一般有隨機翻轉、隨即旋轉、隨即裁剪、明暗變化、高斯雜訊、椒鹽雜訊等。除此之外,對整個深度學習中圖像分類的流程也有了一定的瞭解,從收集數據、對數據進行預處理、自己構建網路模型、訓練網路到最後的預測結果,加深了對圖像分類過程的理解。希望在以後的學習中,可以學習更多深度學習的方法和應用。
五、全部代碼
1 import os 2 import glob 3 import random 4 import shutil 5 from PIL import Image 6 #對所有圖片進行RGB轉化,並且統一調整到一致大小,但不讓圖片發生變形或扭曲,劃分了訓練集和測試集 7 8 if __name__ == '__main__': 9 test_split_ratio = 0.05 #百分之五的比例作為測試集 10 desired_size = 128 # 圖片縮放後的統一大小 11 raw_path = './raw' 12 13 #把多少個類別算出來,包括目錄也包括文件 14 dirs = glob.glob(os.path.join(raw_path, '*')) 15 #進行過濾,只保留目錄,一共36個類別 16 dirs = [d for d in dirs if os.path.isdir(d)] 17 18 print(f'Totally {len(dirs)} classes: {dirs}') 19 20 for path in dirs: 21 # 對每個類別單獨處理 22 23 #只保留類別名稱 24 path = path.split('/')[-1] 25 print(path) 26 #創建文件夾 27 os.makedirs(f'train/{path}', exist_ok=True) 28 os.makedirs(f'test/{path}', exist_ok=True) 29 30 #原始文件夾當前類別的圖片進行匹配 31 files = glob.glob(os.path.join(raw_path, path, '*.jpg')) 32 # print(raw_path, path) 33 34 files += glob.glob(os.path.join(raw_path, path, '*.JPG')) 35 files += glob.glob(os.path.join(raw_path, path, '*.png')) 36 37 random.shuffle(files)#原地shuffle,因為要取出來驗證集 38 39 boundary = int(len(files)*test_split_ratio) # 訓練集和測試集的邊界 40 41 for i, file in enumerate(files): 42 img = Image.open(file).convert('RGB') 43 44 old_size = img.size 45 46 ratio = float(desired_size)/max(old_size) 47 48 new_size = tuple([int(x*ratio) for x in old_size])#等比例縮放 49 50 im = img.resize(new_size, Image.ANTIALIAS)#後面的方法不會造成模糊 51 52 new_im = Image.new("RGB", (desired_size, desired_size)) 53 54 #new_im在某個尺寸上更大,我們將舊圖片貼到上面 55 new_im.paste(im, ((desired_size-new_size[0])//2, 56 (desired_size-new_size[1])//2)) 57 58 assert new_im.mode == 'RGB' 59 60 if i <= boundary: 61 new_im.save(os.path.join(f'test/{path}', file.split('/')[-1].split('.')[0]+'.jpg')) 62 else: 63 new_im.save(os.path.join(f'train/{path}', file.split('/')[-1].split('.')[0]+'.jpg')) 64 65 test_files = glob.glob(os.path.join('test', '*', '*.jpg')) 66 train_files = glob.glob(os.path.join('train', '*', '*.jpg')) 67 68 69 print(f'Totally {len(train_files)} files for training') 70 print(f'Totally {len(test_files)} files for test') 71 72 73 import os 74 import random 75 import numpy as np 76 import pandas as pd 77 import torch 78 import torch.nn as nn 79 import torch.nn.functional as F 80 from tqdm.notebook import tqdm 81


