前面已經講了MySQL的其他查詢性能優化方式,沒看過可以去瞭解一下: MySQL查詢性能優化七種武器之索引潛水 MySQL查詢性能優化七種武器之鏈路追蹤 今天要講的是MySQL的另一種查詢性能優化方式 — 索引下推(Index Condition Pushdown,簡稱ICP),是MySQL5.6版... ...
前面已經講了MySQL的其他查詢性能優化方式,沒看過可以去瞭解一下:
今天要講的是MySQL的另一種查詢性能優化方式 — 索引下推(Index Condition Pushdown,簡稱ICP),是MySQL5.6版本增加的特性。
1. 索引下推的作用
主要作用有兩個:
- 減少回表查詢的次數
- 減少存儲引擎和MySQL Server層的數據傳輸量
總之就是了提升MySQL查詢性能。
2. 案例實踐
創建一張用戶表,造點數據驗證一下:
CREATE TABLE `user` (
`id` int NOT NULL AUTO_INCREMENT COMMENT '主鍵',
`name` varchar(100) NOT NULL COMMENT '姓名',
`age` tinyint NOT NULL COMMENT '年齡',
`gender` tinyint NOT NULL COMMENT '性別',
PRIMARY KEY (`id`),
KEY `idx_name_age` (`name`,`age`)
) ENGINE=InnoDB COMMENT='用戶表';
在 姓名和年齡 (name,age) 兩個欄位上創建聯合索引。
查詢SQL執行計劃,驗證一下是否用到索引下推:
explain select * from user where name='一燈' and age>2;

執行計劃中的Extra列顯示了Using index condition,表示用到了索引下推的優化邏輯。
3. 索引下推配置
查看索引下推的配置:
show variables like '%optimizer_switch%';
如果輸出結果中,顯示 index_condition_pushdown=on,表示開啟了索引下推。
也可以手動開啟索引下推:
set optimizer_switch="index_condition_pushdown=on";
關閉索引下推:
set optimizer_switch="index_condition_pushdown=off";
4. 索引下推原理剖析
索引下推在底層到底是怎麼實現的?
是怎麼減少了回表的次數?
又減少了存儲引擎和MySQL Server層的數據傳輸量?
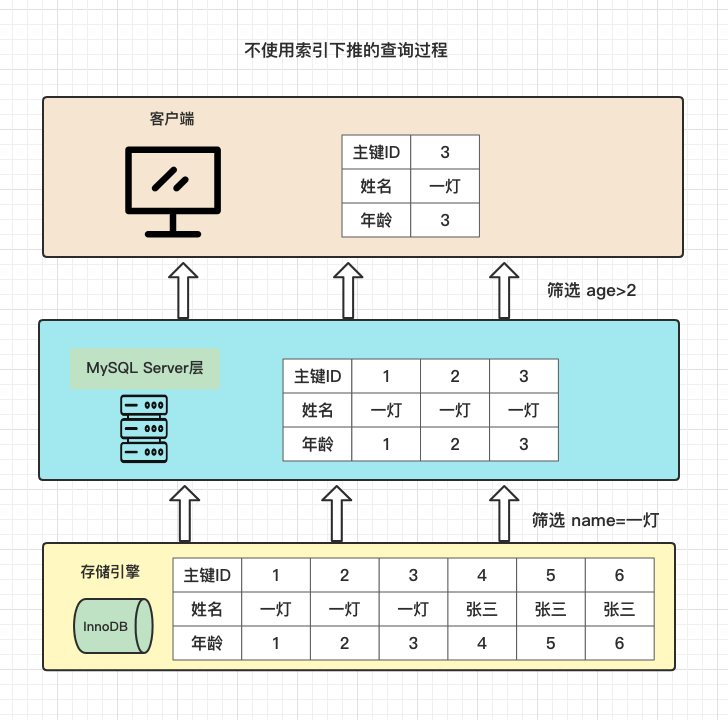
在沒有使用索引下推的情況,查詢過程是這樣的:
- 存儲引擎根據where條件中name索引欄位,找到符合條件的3個主鍵ID
- 然後二次回表查詢,根據這3個主鍵ID去主鍵索引上找到3個整行記錄
- 把數據返回給MySQL Server層,再根據where中age條件,篩選出符合要求的一行記錄
- 返回給客戶端
畫兩張圖,就一目瞭然了。
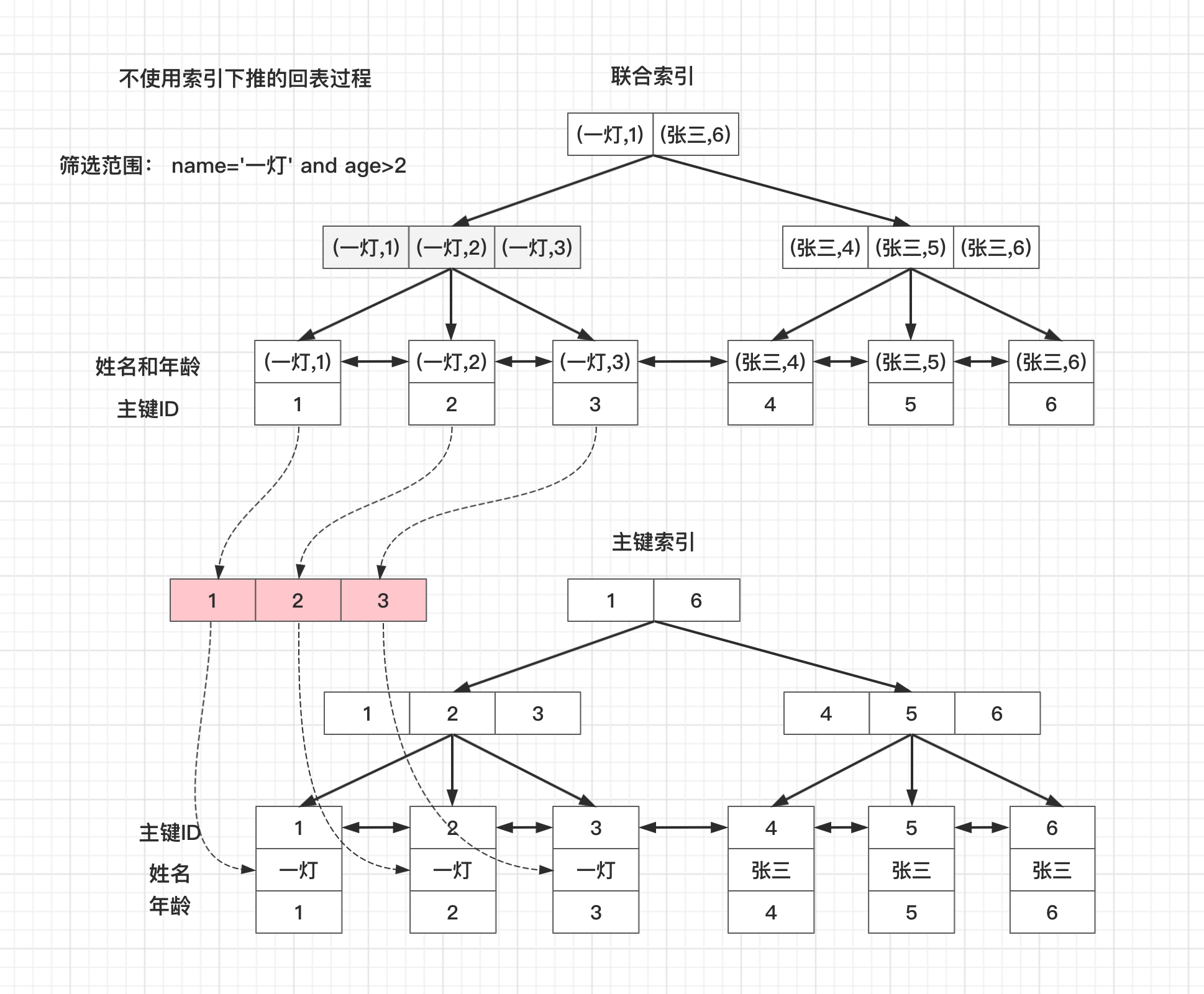
下麵這張圖是回表查詢的過程:
- 先在聯合索引上找到name=‘一燈’的3個主鍵ID
- 再根據查到3個主鍵ID,去主鍵索引上找到3行記錄
下麵這張圖是存儲引擎返回給MySQL Server端的處理過程:
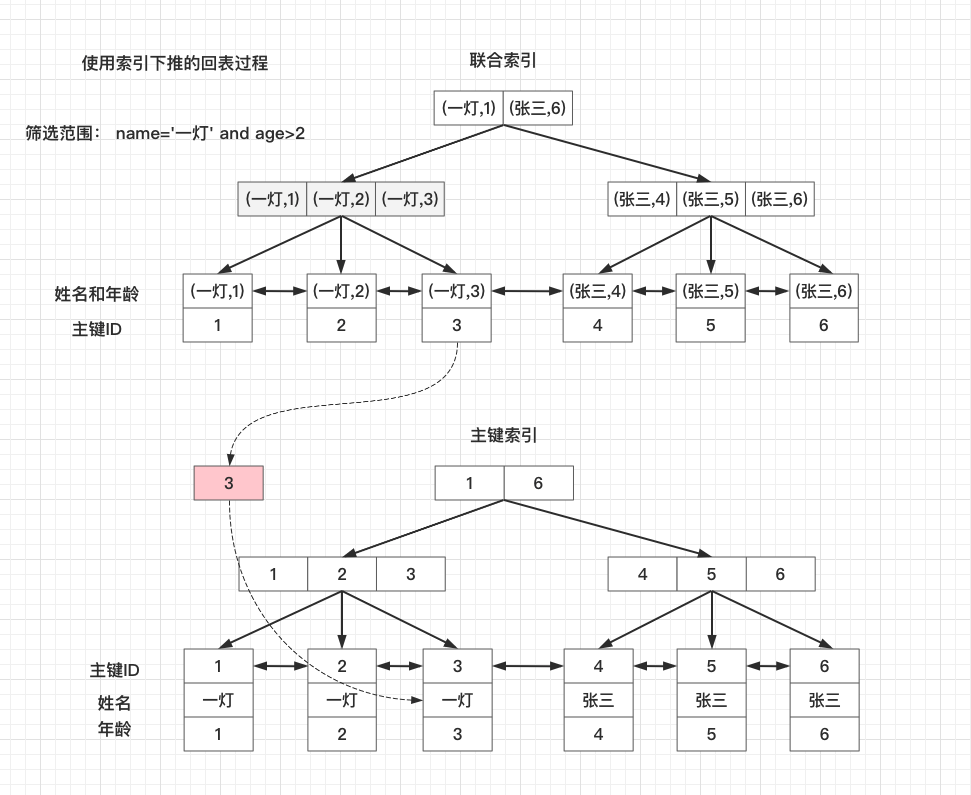
我們再看一下在使用索引下推的情況,查詢過程是這樣的:
- 存儲引擎根據where條件中name索引欄位,找到符合條件的3行記錄,再用age條件篩選出符合條件一個主鍵ID
- 然後二次回表查詢,根據這一個主鍵ID去主鍵索引上找到該整行記錄
- 把數據返回給MySQL Server層
- 返回給客戶端
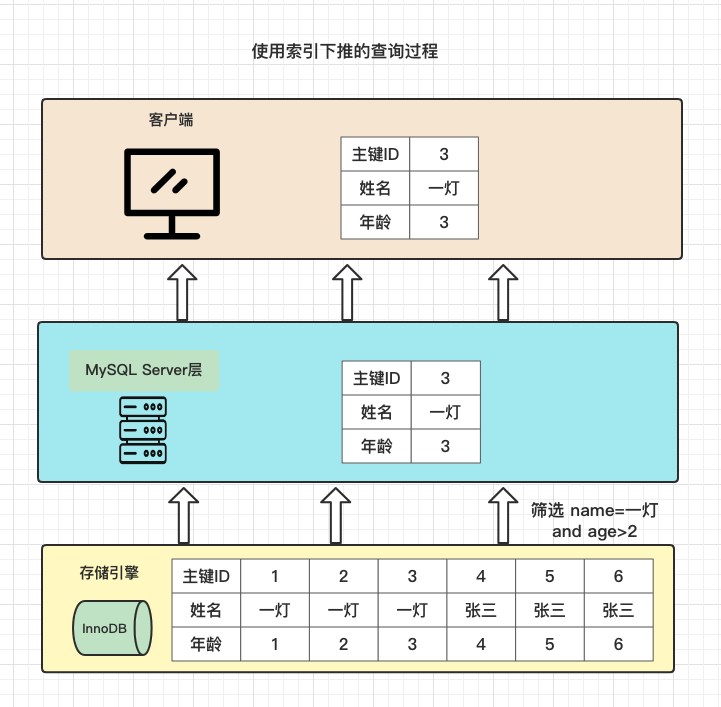
現在是不是理解了索引下推的兩個作用:
- 減少回表查詢的次數
- 減少存儲引擎和MySQL Server層的數據傳輸量
索引下推的含義就是,本來在MySQL Server層做的篩選操作,下推到存儲引擎層來做。
5. 索引下推應用範圍
- 適用於InnoDB 引擎和 MyISAM 引擎的查詢
- 適用於執行計劃是range, ref, eq_ref, ref_or_null的範圍查詢
- 對於InnoDB表,僅用於非聚簇索引。索引下推的目標是減少全行讀取次數,從而減少 I/O 操作。對於 InnoDB聚集索引,完整的記錄已經讀入InnoDB 緩衝區。在這種情況下使用索引下推 不會減少 I/O。
- 子查詢不能使用索引下推
- 存儲過程不能使用索引下推
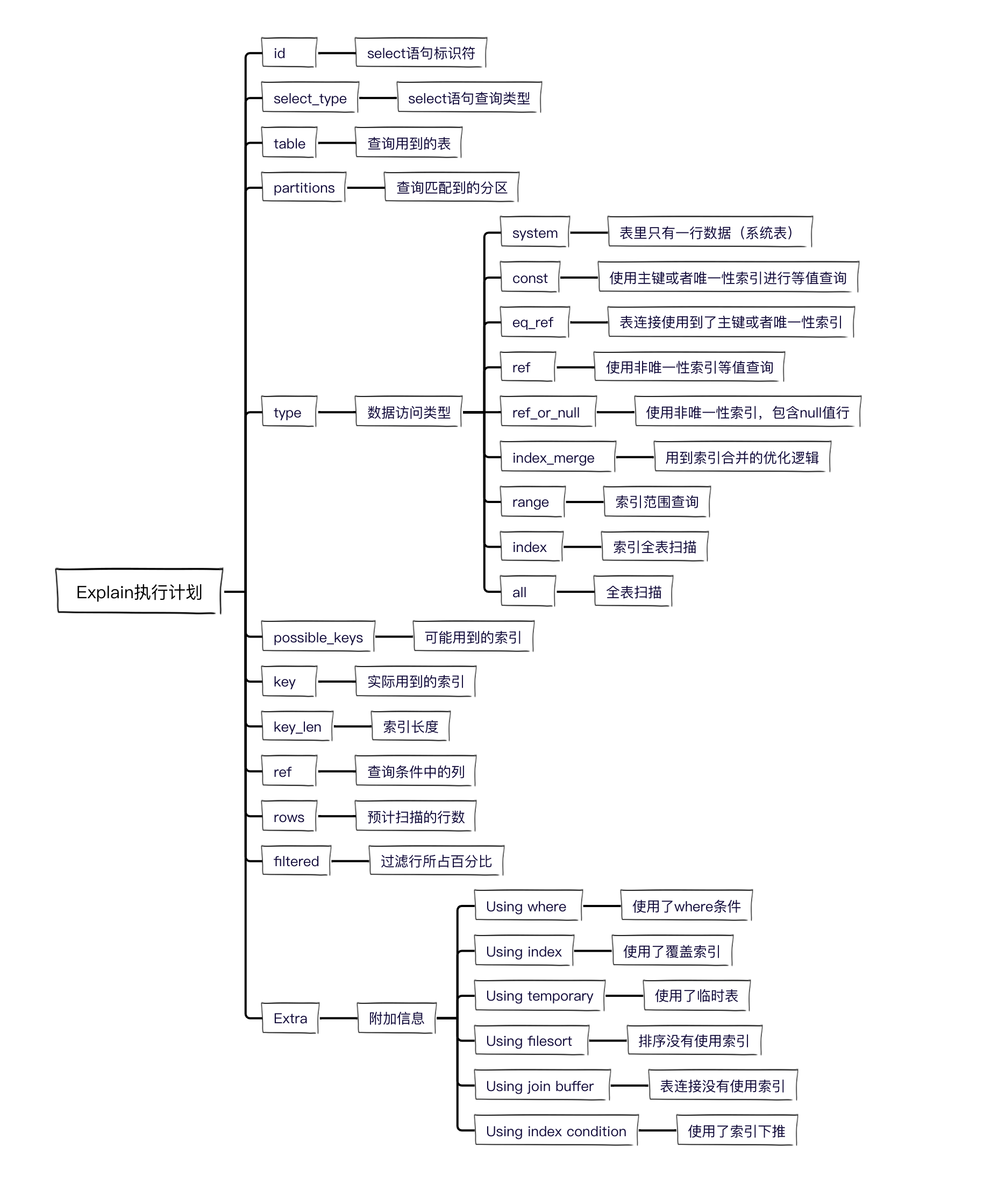
再附一張Explain執行計劃詳解圖: