
摘要:SPL實現了更優演算法,性能遠遠超過存儲過程,能顯著提高單機計算效率,非常適合跑批計算。 本文分享自華為雲社區《Java開源專業計算引擎:跑批真的這麼難嗎?》,作者: Java李楊勇。 業務系統產生的明細數據通常要經過加工處理,按照一定邏輯計算成需要的結果,用以支持企業的經營活動。這類數據加工任 ...
摘要:SPL實現了更優演算法,性能遠遠超過存儲過程,能顯著提高單機計算效率,非常適合跑批計算。
本文分享自華為雲社區《Java開源專業計算引擎:跑批真的這麼難嗎?》,作者: Java李楊勇。
業務系統產生的明細數據通常要經過加工處理,按照一定邏輯計算成需要的結果,用以支持企業的經營活動。這類數據加工任務一般會有很多個,需要批量完成計算,在銀行和保險行業常常被稱為跑批,其它像石油、電力等行業也經常會有跑批的需求。
大部分業務統計都會要求以某日作為截止點,而且為了不影響生產系統的運行,跑批任務一般會在夜間進行,這時候才能將生產系統當天產生的新明細數據導出來,送到專門的資料庫或數據倉庫完成跑批計算。第二天早上,跑批結果就可以提供給業務人員使用了。
和線上查詢不同,跑批計算是定時自動執行的離線任務,不會出現多人同時訪問一個任務的情況,所以沒有併發問題,也不必實時返回結果。但是,跑批必須在規定的視窗時間內完成。比如某銀行的跑批視窗時間是晚上8:00到第二天早上7:00,如果到了早上7:00跑批任務還沒有完成,就會造成業務人員無法正常工作的嚴重後果。
跑批任務涉及的數據量非常大,很可能用到所有的歷史數據,而且計算邏輯複雜、步驟眾多,所以跑批時間經常是以小時計的,一個任務兩三小時是家常便飯,跑到十個小時也不足為奇。隨著業務的發展,數據量還在不斷增加。跑批資料庫的負擔快速增長,就會發生整晚都跑不完的情況,嚴重影響用戶的業務,這是無法接受的。
問題分析
要解決跑批時間過長的問題,必須仔細分析現有的系統架構中的問題。
跑批系統比較典型的架構大致如下圖:
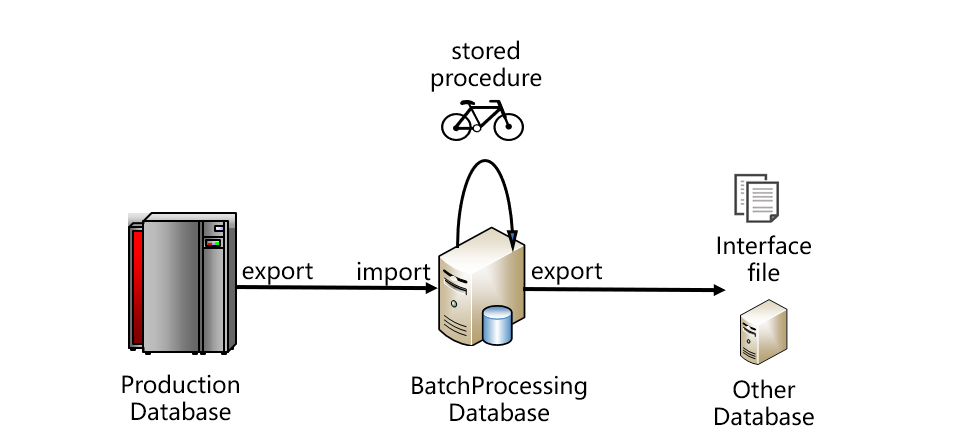
從圖上看,數據要從生產資料庫取出,存入跑批資料庫。跑批資料庫通常是關係型的,編寫存儲過程代碼完成跑批計算。跑批的結果一般不會直接使用,而是再從跑批資料庫中導出,採用介面文件的方式提供給其他系統,或者再導入其他系統資料庫。這是比較典型的架構,圖中的生產資料庫也可能是某個中央數據倉庫或者Hadoop等。一般情況下,生產庫和跑批庫不會是同一種資料庫,它們之間往往通過文件的方式傳遞數據,這樣也比較有利於降低耦合度。跑批計算完成後,結果要給多個應用系統使用,一般也都是以文件方式傳遞。
跑批很慢的第一個原因,是用來完成跑批任務的關係資料庫入庫、出庫太慢。由於關係資料庫的存儲和計算能力具有封閉性,數據的進出要做過多的約束檢查和安全處理,當數據量較大時,寫入讀出的效率非常低,耗時會非常長。所以,跑批資料庫導入文件數據的過程,以及跑批計算結果再導出文件的過程都會很慢。
跑批很慢的第二個原因,是存儲過程性能差。由於SQL的語法體系過於陳舊,存在諸多限制,很多高效的演算法無法實施,所以存儲過程中的SQL語句計算性能很不理想。而且,業務邏輯比較複雜的時候很難用一個SQL實現,經常要分成多個步驟,用十幾甚至幾十個SQL語句才能完成。每個SQL的中間結果,都要存入臨時表給後續步驟的SQL使用。臨時表數據量較大時就必須落地,會造成大量的數據寫出。而資料庫的寫出要比讀入性能差很多,會嚴重拖慢整個存儲過程。
對於更複雜的計算,甚至很難用SQL語句直接實現,需要用資料庫游標遍歷取出數據,迴圈計算。但資料庫游標遍歷計算性能又要比SQL語句差很多,一般也都不直接支持多線程並行計算,很難利用多CPU核的計算能力,會讓計算性能更加糟糕。
那麼,是否可以考慮用分散式資料庫來代替傳統關係資料庫,通過增加節點數量的辦法,來提高跑批任務的速度呢?
答案仍然是不可行。主要原因是跑批計算的邏輯相當複雜,即使是用傳統資料庫的存儲過程,也常常要寫幾千甚至上萬行代碼,而分散式資料庫的存儲過程計算能力還比較弱,很難實現這麼複雜的跑批計算。
而且,當複雜計算任務不得不分成多個步驟時,分散式資料庫也面臨中間結果落地的問題。由於數據可能在不同的節點上,所以前序步驟將中間結果落地,後續步驟再讀取的時候,都會造成大量跨網路的讀寫操作,性能很不可控。
這時,也不能採用分散式資料庫依靠數據冗餘來提升查詢速度的辦法。這是因為,查詢之前可以預先準備好多份冗餘數據,但是,跑批的中間結果是臨時生成的,如果冗餘的話就要臨時生成多份,整體的性能只會變得更慢。
所以,現實的跑批業務通常仍然是使用大型單體資料庫進行,計算強度太大時會採用類似ExaData這樣的一體機(ExaData是多資料庫,但被Oracle專門優化過,可以看成是個超大型單體資料庫)。雖然很慢,但是暫時找不到更好的選擇,只有這類大型資料庫有足夠的計算能力,所以只能用它來完成跑批任務了。
SPL用於跑批
開源的專業計算引擎SPL提供了不依賴資料庫的計算能力,直接利用文件系統計算,可以解決關係資料庫出庫入庫太慢的問題。而且SPL實現了更優演算法,性能遠遠超過存儲過程,能顯著提高單機計算效率,非常適合跑批計算。
利用SPL實現的跑批系統新架構是下麵這樣的:
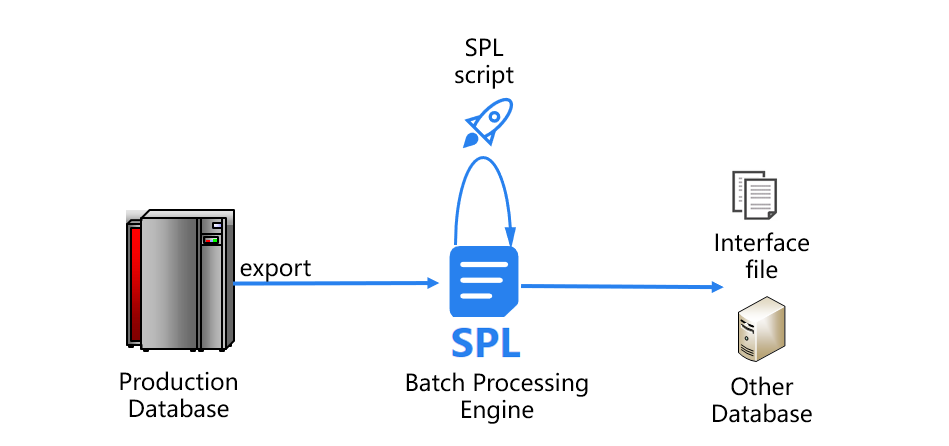
在新架構中,SPL解決了造成跑批慢的兩大瓶頸問題。
首先來看數據的入庫、出庫問題。SPL可以直接基於生產庫導出的文件計算,不必再將數據導入到關係資料庫中。完成跑批計算後,SPL還能將最終結果直接存儲成文本文件等通用格式,傳遞給其他應用系統,避免了原有跑批資料庫的出庫操作。這樣一來,SPL就省去了關係資料庫緩慢的入庫、出庫過程。
下麵再來看計算的過程。SPL提供了更優的演算法(有許多是業界首創),計算性能遠遠超過存儲過程和SQL語句。這些高性能演算法包括:

這些高性能演算法可以應用於跑批任務中的常見JOIN計算、遍歷、分組彙總等,能有效提升計算速度。例如,跑批任務常常要遍歷整個歷史表。有些情況下,對一個歷史表還要遍歷好多次,來完成多種業務邏輯的計算。歷史表數據量一般都很大,每次遍歷都要消耗很多的時間。此時我們可以應用SPL的遍歷復用機制,僅對大表遍歷一次,就可以同時完成多種計算,可以節省大量時間。
SPL的多路游標能做到數據的並行讀取和計算,即使是很複雜的跑批邏輯,也可以利用多CPU核實現多線程並行運算。而資料庫游標是很難並行的,這樣一來,SPL的計算速度常常可以達到存儲過程的數倍。
SPL的延遲游標機制,可以在一個游標上定義多個計算步驟,之後讓數據流按順序依次完成這些步驟,實現鏈式計算,能夠有效減少中間結果落地的次數。在數據必須落地的情況下,SPL也可以將中間結果存成內置的高性能數據格式,供下一個步驟使用。SPL高性能存儲基於文件,採用有序壓縮存儲、自由列式存儲、倍增分段、自有壓縮編碼等技術,減少了硬碟占用,讀寫速度要遠遠好於資料庫。
應用效果
SPL在技術架構上打破了關係型跑批資料庫存在的兩大瓶頸,在實際應用中也取得了非常好的效果。
L 銀行跑批任務採用傳統架構,以關係資料庫作為跑批資料庫,用存儲過程編程實現跑批邏輯。其中,貸款協議存儲過程需要執行 2 個小時,而且是很多其他跑批任務的前序任務,耗時這麼久,對整個跑批任務造成了嚴重影響。
採用SPL後,使用高性能列存、文件游標、多線程並行、小結果記憶體分組、游標復用等高性能演算法和存儲機制,將原來2個小時的計算時間縮短為10分鐘,性能提高12倍。
而且,SPL代碼更簡潔。原存儲過程3300多行,改為SPL後,僅有500格語句,代碼量減少了6倍多,大大提高了開發效率。
P保險公司的車險業務中,需要用往年曆史保單來關聯新的保單,在跑批中稱為歷史保單關聯任務。原來也採用關係資料庫完成跑批,存儲過程計算10天的新增保單關聯歷史保單,運行時間47分鐘;30天則需要112分鐘,接近2小時;如果日期跨度更大,運行時間就會長的無法忍受,基本就變成不可能完成的任務了。
採用SPL後,應用了高性能文件存儲、文件游標、有序歸併分段取出、記憶體關聯和遍歷復用等技術,計算10天新增保單僅需13分鐘;30天新增保單隻需要17分鐘,速度提高了近7倍。而且,新演算法執行的時間隨著保單天數的增長並不是很大,並沒有像存儲過程那樣成正比的增長。
從代碼總量來看,原來存儲過程有2000行代碼,去掉註釋後還有1800多行,而SPL的全部代碼只有不到500格,不到原來的1/3。
T銀行通過互聯網渠道發放貸款的明細數據,需要每天執行跑批任務,統計彙總指定日期之前的所有歷史數據。跑批任務採用關係資料庫的SQL語句實現,運行總時間7.8小時,占用了過多的跑批時間,甚至影響了其他的跑批任務,必須優化。
採用SPL後,應用了高性能文件、文件游標、有序分組、有序關聯、延遲游標、二分法等技術,原來需要7.8小時的跑批任務,單線程僅需180秒,2線程僅需137秒,速度提高了204倍。

