
當我們回到家,如果家裡有異樣,我們能夠很快就會發現家中的異樣,那是因為這些異常的擺設在我們的大腦中會產生較強的腦電波。 當我們聽到某個單詞,我們大腦中跟這個單詞相關的神經元會異常興奮,而同這個單詞無關的神經元就不會有很大的刺激。 這個就是大腦中的激勵函數。 有了激勵函數,我們才會對外部的刺激產生非線 ...
當我們回到家,如果家裡有異樣,我們能夠很快就會發現家中的異樣,那是因為這些異常的擺設在我們的大腦中會產生較強的腦電波。
當我們聽到某個單詞,我們大腦中跟這個單詞相關的神經元會異常興奮,而同這個單詞無關的神經元就不會有很大的刺激。
這個就是大腦中的激勵函數。
有了激勵函數,我們才會對外部的刺激產生非線性的反應,有的神經元反應比較強烈,而有的神經元基本沒有反應。
在神經網路中激勵函數有很多,但作為初學的我們,只要瞭解其中常用的幾個就可以了。
relu
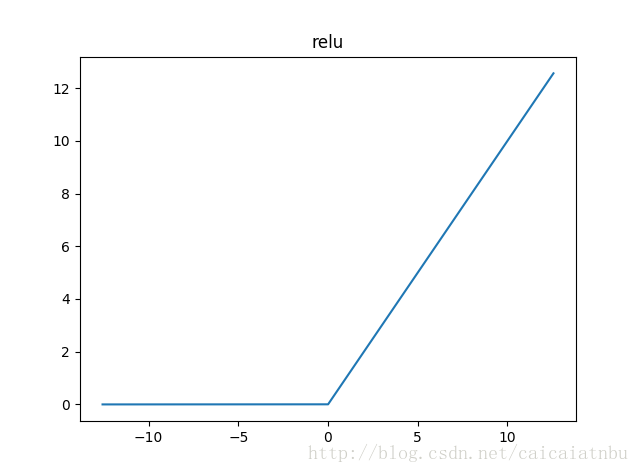
這是一種使用比較廣泛的並且計算量也很少的激勵函數。
這個激勵函數的意思是:如果值小於0就一直為0,大於0就是輸出那個值。
從我們的大腦中神經元來類比為:我們大腦中某神經元對於某信號的刺激太小的話,就一直處於睡眠狀態,而如果此輸入的信號激起了此神經元,則刺激的強度就跟輸入信息的強度成正比。
sigmoid
公式為:
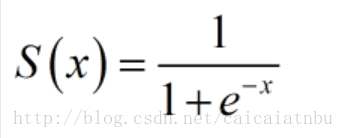
圖像為:
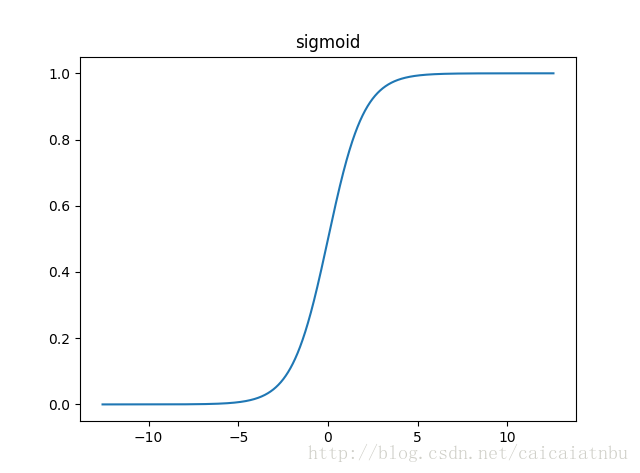
這裡不用被這個公式嚇到,不瞭解公式也沒關係。
我們從其圖像中看到,這個函數的值域為(0,1)內,並且是連續函數。
在機器學習中,我們一般會把數據映射到(0, 1)或者(-1, 1)這樣的範圍內。
它的特點是輸入信號在模糊區0附近時很快就能得出哪些信號需要被加強,哪些信號需要被抑制,也符合我們大腦中神經元對於信息輸入的應激反應特征。
tanh
反正切函數:
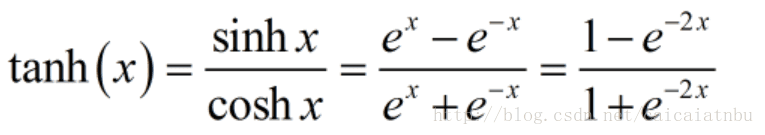
圖像為:
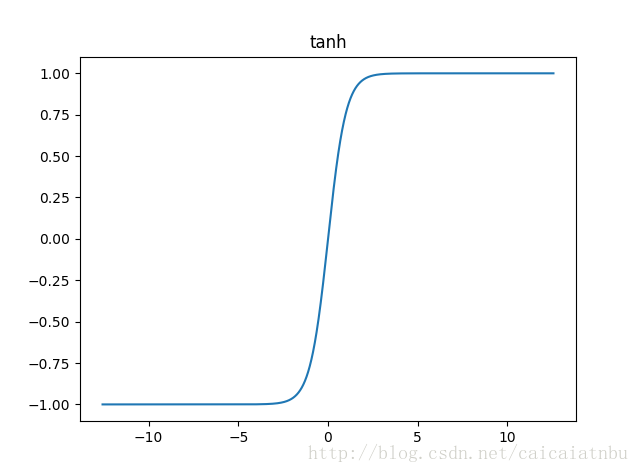
這個函數的樣子跟sigmoid類似,只是其值域位於(-1, 1)之間,輸入信號值在0附近會有一個突變的模糊區。
tanh作為激勵函數使用得也很廣泛。
大家可以來進行嘗試的。
softplus
softplus函數可以看作是relu函數的平滑版本,公式和函數圖像如下:
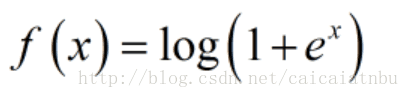
圖像為:

softplus主要用在最後一層分類中的輸出元激勵函數。
比如在手寫識別0-9的數字中,最後一層的激勵函數一般用softplus來實現。


