
在我剛接觸編程的時候, 那時候面試小題目很喜歡問下麵這幾類問題 1' 浮點數如何和零比較大小? 2' 浮點數如何轉為整型? 然後過了七八年後這類問題應該很少出現在面試中了吧. 剛好最近我遇到線上 bug, 同大家交流科普下 問題最小現場 #include <stdio.h> int main(voi ...
在我剛接觸編程的時候, 那時候面試小題目很喜歡問下麵這幾類問題
1' 浮點數如何和零比較大小?
2' 浮點數如何轉為整型?
然後過了七八年後這類問題應該很少出現在面試中了吧. 剛好最近我遇到線上 bug, 同大家交流科普下
問題最小現場
#include <stdio.h> int main(void) { float a = 2.01f; double b = 2.01; printf("a1 : 2.01 * 1000 = %f\n", a * 1000); // a1 : 2.01 * 1000 = 2010.000000 printf("a2 : int(2.01 * 1000) = %d\n", (int)(a * 1000)); // a2 : int(2.01 * 1000) = 2010 printf("b1 : 2.01 * 1000 = %lf\n", b * 1000); // b1 : 2.01 * 1000 = 2010.000000 printf("b2 : int(2.01 * 1000) = %d\n", (int)(b * 1000)); // b2 : int(2.01 * 1000) = 2009 }
(用 Go Java 效果是一樣的, 絕大部分實現都是嚴格遵循 IEEE754 標準
問題解答
其中 a1 和 b1 在 C 中 等價於下麵的代碼
float a = 2.01f; double b = 2.01; printf("a1 : 2.01 * 1000 = %f\n", (double)(a * 1000)); printf("b1 : 2.01 * 1000 = %f\n", b * 1000);
其中 printf float 其實相當於 printf (double) 去處理的. 具體可以看這類源碼
#define PARSE_FLOAT_VA_ARG(INFO) \ do \ { \ INFO.is_binary128 = 0; \ if (is_long_double) \ the_arg.pa_long_double = va_arg (ap, long double); \ else \ the_arg.pa_double = va_arg (ap, double); \ } \ while (0)
其次二者輸出列印的數據內容一樣. 本質原因是, double 尾數的高23位和float的尾數23位一樣.
如果你用 %.8f 可能就不一樣了.
(float : 1 + 8 +23, 小數點後精度 6-7)
(double : 1 + 11 + 52, 小數點後精度 15-16)
簡單的, 我們可以用下麵代碼去驗證
#include <stdio.h> static void print_byte(unsigned char byte) { printf("%d%d%d%d%d%d%d%d" , ((byte >> 7) & 1) , ((byte >> 6) & 1) , ((byte >> 5) & 1) , ((byte >> 4) & 1) , ((byte >> 3) & 1) , ((byte >> 2) & 1) , ((byte >> 1) & 1) , ((byte >> 0) & 1) ); } static void print_number(const void * data, size_t n) { const unsigned char * bytes = data; # if __BYTE_ORDER__ == __ORDER_LITTLE_ENDIAN__ for (size_t i = n; i > 0; i--) { print_byte(bytes[i-1]); } # else for (size_t i = 0; i < n; i++) { print_byte(bytes[i]); } # endif } static void print_float(float num) { printf(" float = "); print_number(&num, sizeof num); printf("\n"); } static void print_double(double num) { printf("double = "); print_number(&num, sizeof num); printf("\n"); } int main(void) { float a = 2.01f; double b = 2.01; print_float(a); print_double(b); printf(" float 2.01f + %%.%df = %.*f\n", 8, 8, a); printf("double 2.01 + %%.%df = %.*lf\n", 8, 8, b); }
在 window 和 ubuntu 得到的測試數據如下
/* float = 01000000000000001010001111010111 double = 0100000000000000000101000111101011100001010001111010111000010100 float 2.01f = 0 10000000 00000001010001111010111 double 2.01 = 0 10000000000 00000001010001111010111 00001010001111010111000010100 float 2.01f + %.6f = 2.010000 double 2.01 + %.6f = 2.010000 float 2.01f + %.7f = 2.0100000 double 2.01 + %.7f = 2.0100000 float 2.01f + %.8f = 2.00999999 double 2.01 + %.8f = 2.01000000 float 2.01f + %.10f = 2.0099999905 double 2.01 + %.10f = 2.0100000000 float 2.01f + %.15f = 2.009999990463257 double 2.01 + %.15f = 2.010000000000000 float 2.01f + %.16f = 2.0099999904632568 double 2.01 + %.16f = 2.0099999999999998 float 2.01f + %.17f = 2.00999999046325684 double 2.01 + %.17f = 2.00999999999999979 */
明顯可以看出來 a = 2.01f 和 b = 2.01 在記憶體中二者是不一樣的. 即 a != b, a * 1000 != b * 1000. 有興趣的可以自行去實驗.
問題解答繼續
這裡說說 a2 和 b2 case 造成的原因.
printf("a2 : int(2.01 * 1000) = %d\n", (int)(a * 1000)); // a2 : int(2.01 * 1000) = 2010 printf("b2 : int(2.01 * 1000) = %d\n", (int)(b * 1000)); // b2 : int(2.01 * 1000) = 2009
我們首先獲取其記憶體佈局
float 2010.0f = 0 10001001 11110110100000000000000 double 2010.0 = 0 10000001001 1111011001111111111111111111111111111111111111111111
隨後藉助場外信息, 引述 <<深入理解電腦系統-第三版>> 部分舍入概念
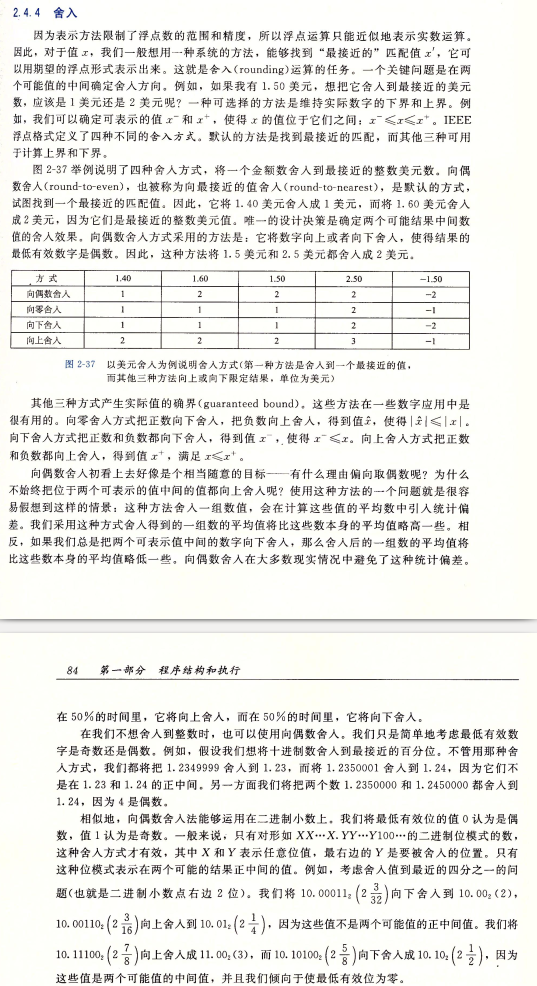
誤差來自浮點數無法精確表示和轉換過程中舍入起的效果.
問題反思
這類問題, 或多或少遇到過, 希望我們這裡對這類問題做個了結 ~
此刻不知道有心人會不會著急下結論,
那以後的業務中還是別用 float 了, 或者直接用 double, 或者定點小數, 或者整數替代 float 等等 ...
這麼考慮很不錯, 在大多數領域是完全沒有問題的. 也是值得推薦的.
補充下, 也有些領域例如嵌入式, 他們還是會用 float, 因為對他們而言 double 有的時候太浪費記憶體了,
還存在著地址對齊等問題.
雖然不同領域(場景)會有不同方式方法, 但有一點需要大家一塊遵守, 沒有特殊情況別混著用 ~
希望以上能幫助朋友們對這類問題知其所以然 ~
後記 - 再見, 祝好運 ~
錯誤是難免的, 歡迎交流指正, 當找個樂子 ~ 哈哈哈 ~


