
HDFS採用的是master/slaves這種主從的結構模型管理數據,這種結構模型主要由四個部分組成,分別是Client(客戶端)、Namenode(名稱節點)、Datanode(數據節點)和SecondaryNameNode。HDFS作為hadoop的分散式儲存框架,最重要的莫過於數據流的讀寫過程 ...
HDFS採用的是master/slaves這種主從的結構模型管理數據,這種結構模型主要由四個部分組成,分別是Client(客戶端)、Namenode(名稱節點)、Datanode(數據節點)和SecondaryNameNode。HDFS作為hadoop的分散式儲存框架,最重要的莫過於數據流的讀寫過程了,下麵就HDFS得數據流的讀寫流程做個詳細的剖析。
HDFS的寫流程
首先寫操作的代碼操作:
hdfs dfs -put ./file02 /file02
hdfs dfs -copyFromLocal ./file02 /file02
FSDataOutputStream fsout = fs.create(path);fsout.write(byte[])
fs.copyFromLocal(path1,path2)
具體流程詳解:
如下圖所示是整個寫流程及原理(上傳)
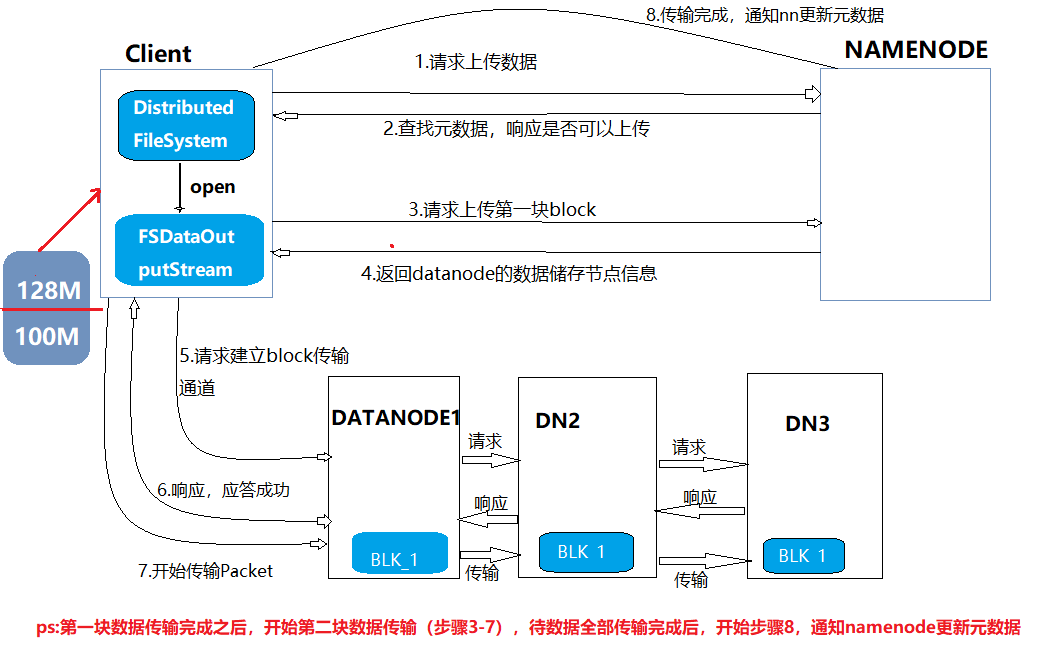
1.客戶端向namenode發出請求上傳數據;
2.namenode在接到請求之後,開始查找元數據(查找是否存在這個目錄以及查詢上傳者是否有這個許可權),查詢後向客戶端響應是否可以上傳數據。
3.客戶端接到響應之後,再開始請求上傳第一塊數據(數據分塊是由客戶端操作的),例如圖中的0-128m為第一塊數據。
4.namenode接到請求後,向客戶端返回datanode節點信息(副本放在哪個節點上,例如放在DN1,DN2,DN3這三台機器上)。一般規則有近遠遠,近遠近
5.客戶端根據返回的副本信息向datanode請求建立傳輸通道,以級聯的方式進行請求
6.datanode向客戶端響應,若都應答成功,則傳輸通道建立成功。
7.開始傳輸數據,以packet方式傳輸,以chunk為單位進行校驗,預設1m。
8.第一塊上傳成功,第二塊開始從3-7步驟繼續傳輸
9.待傳輸完成之後,客戶端向namenode報告數據傳輸遠程,由namenode更新元數據
在hdfs的寫流程有幾個核心問題:
1.傳輸blk1的過程中,dn3如果死了,集群會怎麼處理?
不做任何處理,錯誤會想nn報告
2.接1,如果dn3又啟動了,集群會如何處理?
dn3啟動時,會向nn發送塊報告,然後nn指示dn3刪除blk1(因為傳輸數據不完整)
3.客戶端建立通道時,發現dn3連接不上,會怎麼辦?
nn會重新分配三個節點
4.傳輸過程中,packet出錯,會如何處理?
會重新上傳,但是重傳次數只有4次,超過限制則提示傳輸失敗
5.如果bk1上傳成功,blk2壞了,或者blk2上傳時,dn1掛了,如何處理?
nn會將整個文件標記為無效,下次dn向nn發送塊報告時,nn會通知這些塊所在的節點刪除
HDFS的讀操作
首先讀操作的代碼(下載)
hdfs dfs -get /file02 ./file02
hdfs dfs -copyToLocal /file02 ./file02
FSDataInputStream fsis = fs.open(path);
fsis.read(byte[] a)
fs.copyToLocal(path1,path2)
具體流程詳解

由圖可知HDFS的讀流程要比寫流程簡單很多,主要步驟:
1.客戶端請求下載數據
2.nn檢測數據是否存在,給客戶端響應
3.客戶端請求下載第一塊數據
4.nn返回目標文件的元數據
5.客戶端請求dn建立傳輸通道
6.dn響應
7.開始傳輸數據
註意點:
在讀操作中在客戶端和dn建立傳輸通道時不是採用級聯方式,而是首先尋找離自己最近的副本(dn1)下載,如果數據不完整或者沒有找到,就再向dn2建立傳輸通道,然後傳輸數據,依次往下,直到下載到目標文件為止。


