
消息隊列 為什麼要用消息隊列,都有什麼優缺點? 要問的是消息隊列都有哪些場景,然後項目里具體實現的什麼場景,你在這個場景里用的什麼消息隊列? 期望的回答是,你們公司有個什麼業務,這個業務場景有什麼技術挑戰,如果不用MQ可能會很麻煩,但是你現在用了MQ帶給你什麼好處? 場景比較多,但是比較核心的是3個 ...
消息隊列
為什麼要用消息隊列,都有什麼優缺點?
-
要問的是消息隊列都有哪些場景,然後項目里具體實現的什麼場景,你在這個場景里用的什麼消息隊列?
-
期望的回答是,你們公司有個什麼業務,這個業務場景有什麼技術挑戰,如果不用MQ可能會很麻煩,但是你現在用了MQ帶給你什麼好處?
-
場景比較多,但是比較核心的是3個:解耦、非同步、削峰
解耦
需要去考慮你負責的系統中是否有類似的場景,一個系統調用了多個系統和模塊,互相之間的調用很複雜,維護起來很麻煩。但是這個調用並不需要直接同步調用介面,如果用MQ給它非同步化解耦,也是可以的,你就需要 考慮在你的項目中,是不是可以運用這個MQ去進行解耦。在簡歷中體現出來
非同步化
非同步化可以大幅度提升高延遲介面的性能
削鋒:
未使用MQ的時候: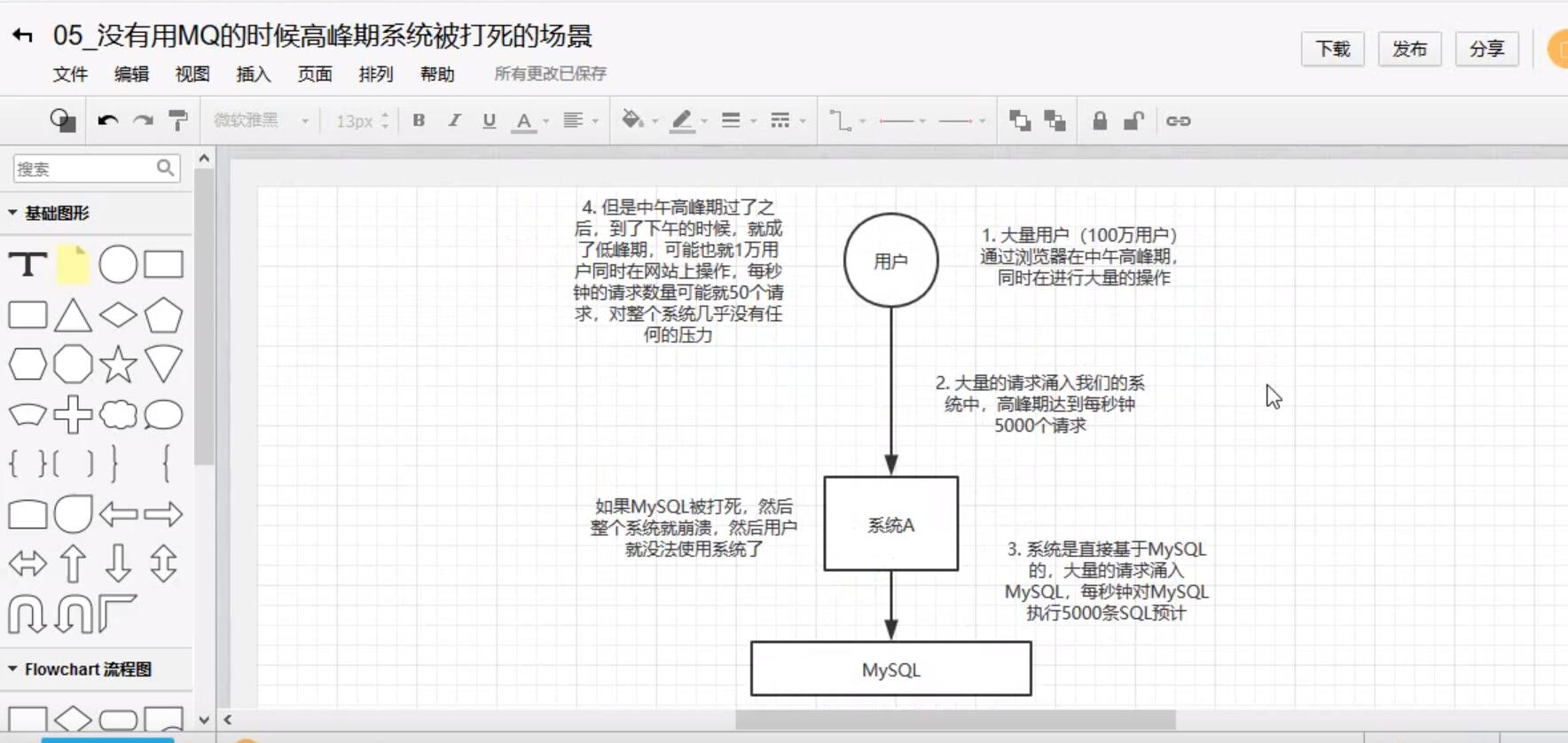

使用MQ以後:

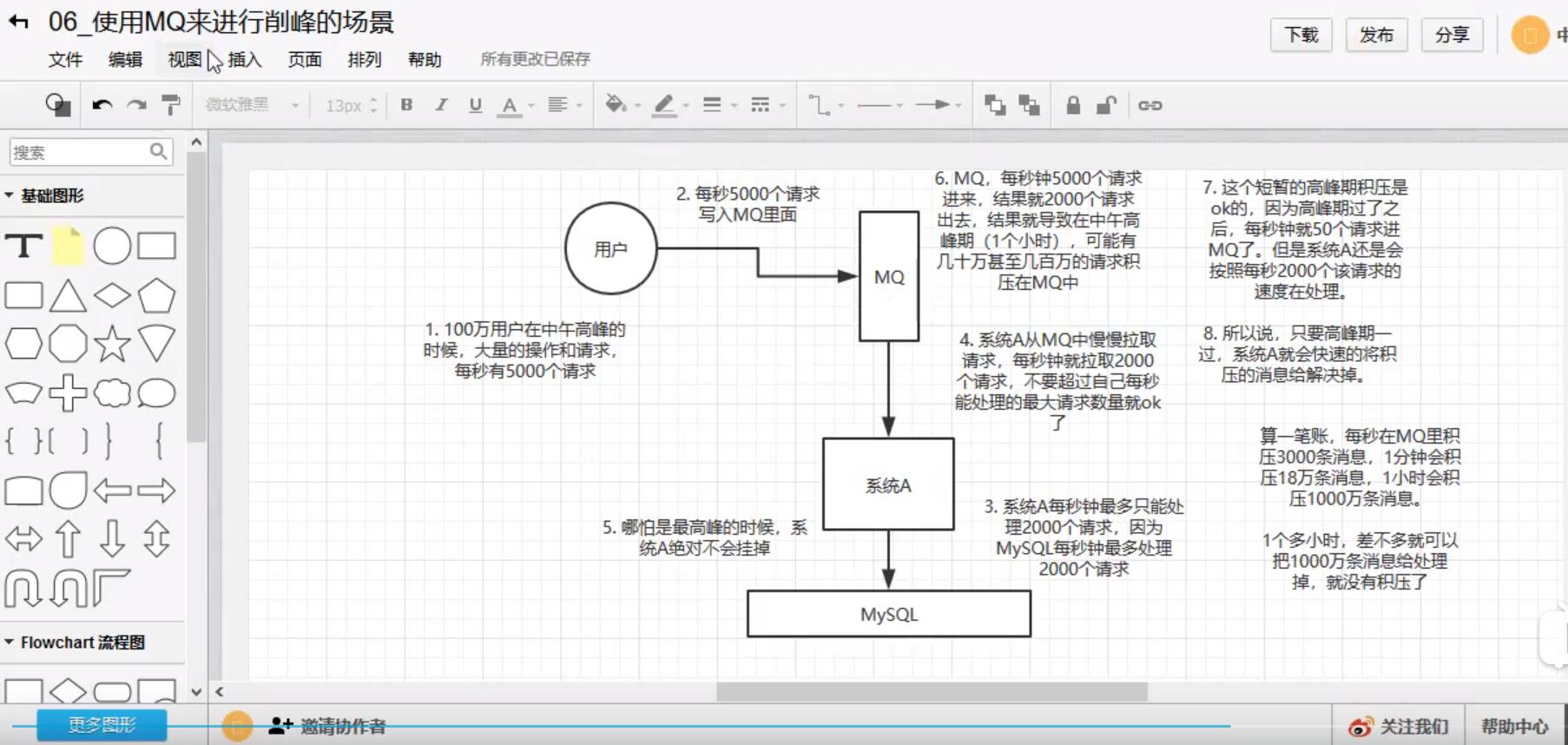
系統架構中引入MQ後可能存在的缺陷:
-
系統可用性降低:系統引入的外部依賴越多,越容易掛掉。
-
系統的複雜性更高:需要考慮的問題越多
-
一致性問題

問題2:kafka,activeMq,rabbitMq,rocketMq 都有什麼優缺點?
| 特性 | ACTIVEMQ | RABBITMQ | ROCKETMQ | KAFKA |
|---|---|---|---|---|
| 單擊吞吐量 | 萬級吞吐量,相比RocketMq和Kafka要第一個數量級 | 萬級,吞吐量相比RocketMq和 Kafka要低一個數量級 | 10萬級,RocketMq也是可以支撐高吞吐的一種MQ | 10萬級別,吞吐量高,一般是配合大數據系統來進行實時的數據計算,日誌採集等場景。 |
| 時效性 | ms級 | 微妙級,這是RabbitMq的一大特點,延時是最低的 | ms級 | ms級別以內 |
| 可用性 | 高,基於主從架構實現高可用性 | 高,基於主從架構實現高可用性 | 非常高,分散式架構 | 分散式,比較高,一個數據多個副本,少數機器宕機,不會丟失數據,不會導致不可用 |
| 消息可靠性 | 有較低的概率丟失消息 | 經過參數優化配置,可以做到0丟失 | 經過參數優化配置,可以做到0丟失 | |
| 功能支持 | MQ領域的功能極其完備 | 基於erlang開發,所以併發能力很強,性能極其好,延時很低 | MQ的功能比較完備的,開始分散式的,擴展性比較好 | 功能較為簡單,主要支持簡單的MQ的功能,在大數據領域的實時計算和日誌採集都支持的比較好 |
| 優劣勢總結 | 非常成熟,業內大量的公司在使用;<br />偶爾會丟失消息,官方維護的比較少了<br />而且主要是基於解耦和非同步來用的,較少在大規模吞吐的場景中使用 | 基於erlang開發,所以併發能力很強,延時很低;MQ功能比較完備。而且開源版本提供的管理界面非常棒,用起來好用。 社區相對比較活躍,幾乎每個月都要發佈幾個版本,但是吞吐量只有幾萬,比較低,而且erlang開發,國內沒有幾個公司做erlang級別的源碼級別的研究和定製;很難去看懂源碼,公司對這個中間件的掌控能力比較多,只能依靠開源社區的版本迭代 | API簡單易用,而且是阿裡開源項目,質量還是可以肯定的。日處理消息可以達上百億之多,可以做大規模吞吐,分散式擴展也方便,社 區維護開可以,由於是java開發的,所以可以方便的閱讀源碼,定製自己公司的mq. | |
| TOPIC數量對吞吐量的影響 | topic可以達到幾百,幾千個級別,吞吐量有較小幅度的降低 | topic可以達到幾百,幾千個級別,吞吐量有較小幅度的降低 |
如何保證消息隊列的高可用?
問的是你用的哪種MQ,是如何保證高可用的?
-
RabbitMQ的高可用性
RabbitMQ是比較有代表性的,因為主要是基於主從做高可用的,我們就以他為例講第一種MQ的高可用性的具體實現
-
單擊模式
就是Demo級別的,一般是本地啟動體驗一下
-
普通集群模式
多台機器啟動多個rabbitMq實例,每個機器啟動一個,但是你創建的queue只會放在一個rabbitmq實例上,但是每個實例同步queue的元數據,完了你消費完以後,實際上如果你連接到另外一個實例, 那麼這個實例會從queue所在實例上拉取數據過來。
缺點:可能會在rabbitMq集群內部產生大量的數據傳輸
可用性幾乎沒有什麼保障,如果queue所在實例的節點的機器宕機了,整個消息隊列都不可用
圖解:
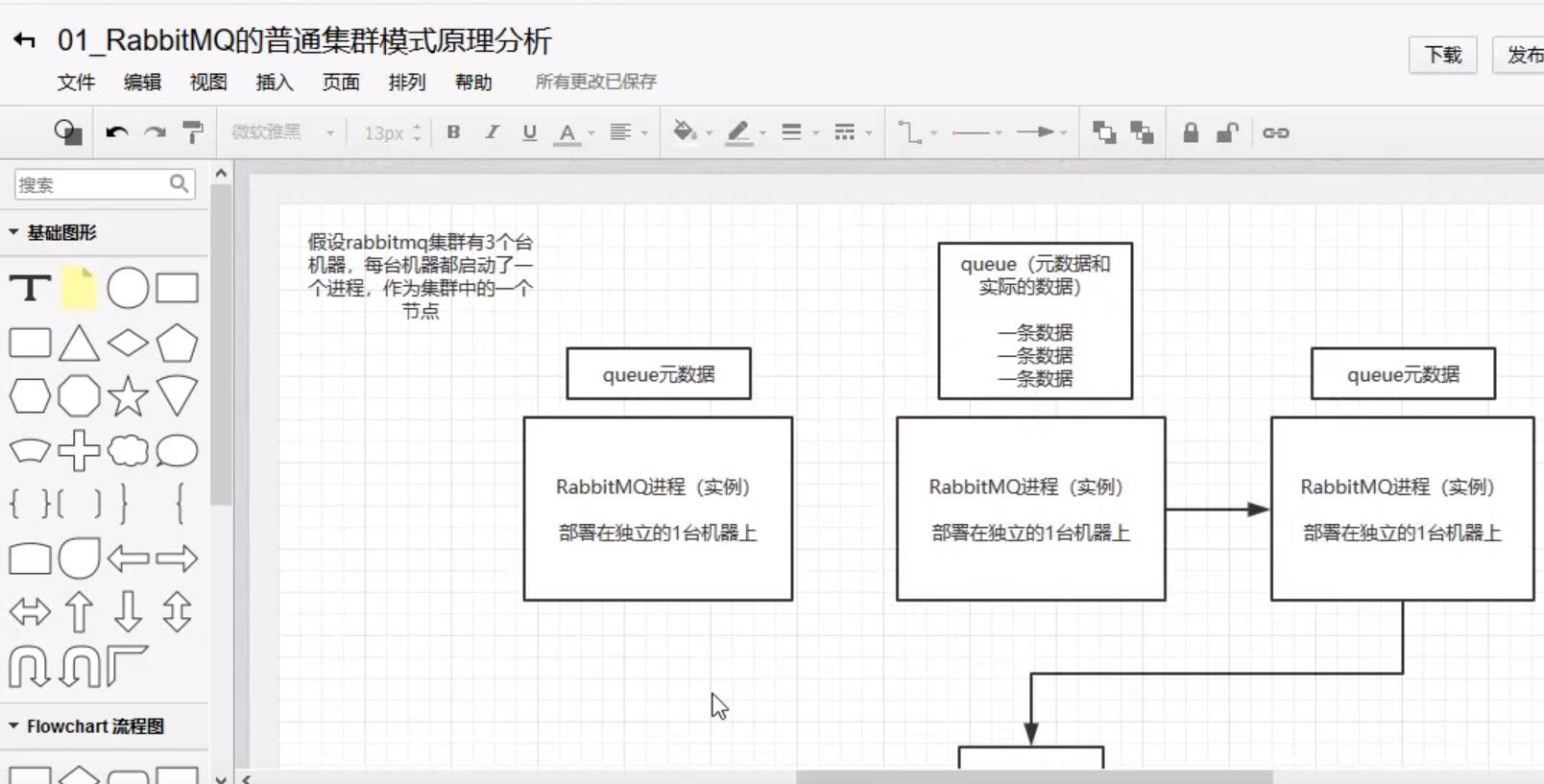

-
3.鏡像集群模式
這個才是rabbit高可用的解決方案,創建的queue,無論元數據還是queue里的消息都會存在與多個實例中,然後每次寫消息到queue中時,都會自動把消息放到多個實例的queue中進行數據同步。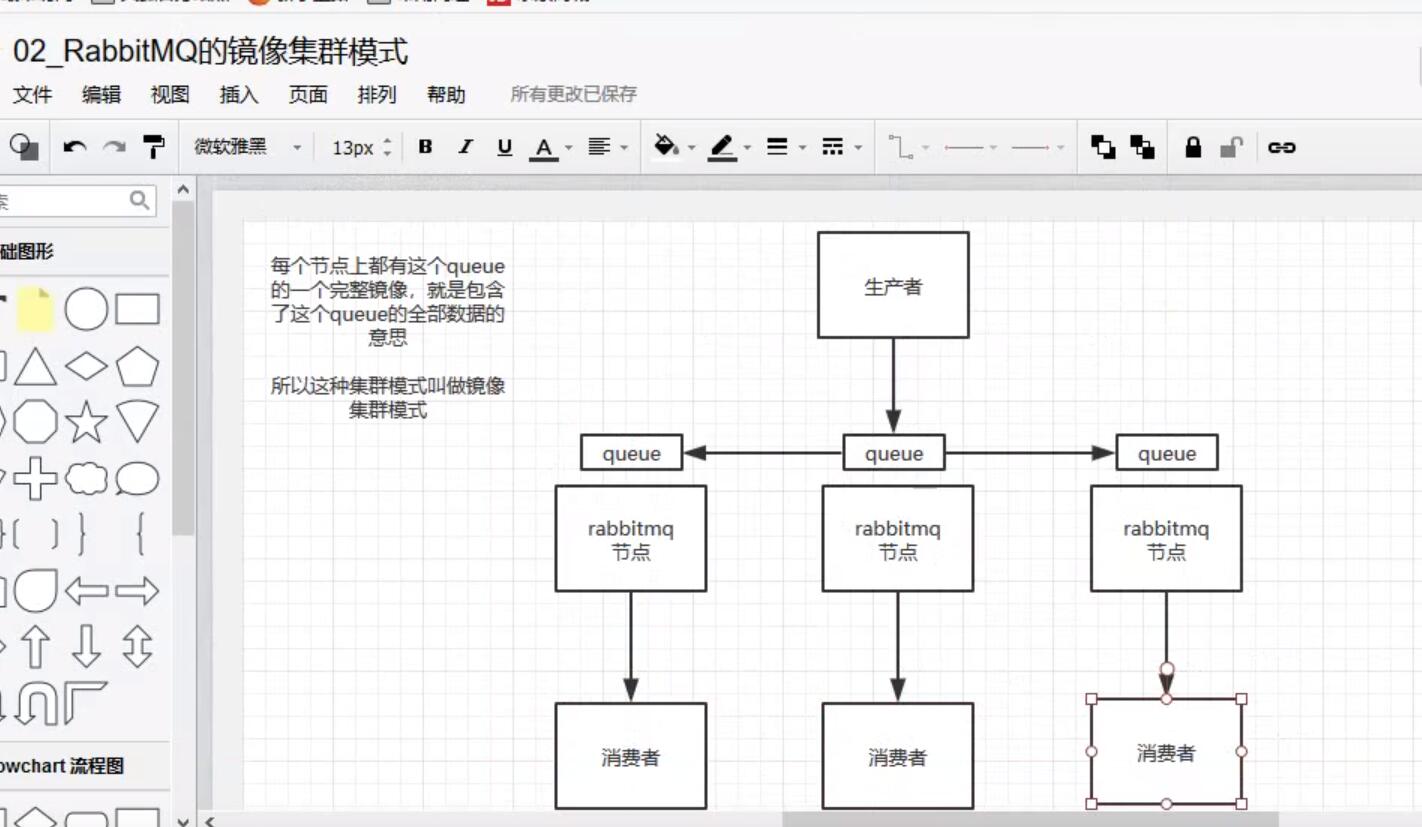

如何開啟鏡像策略:
在rabbitMq有一個管理控制台,在後臺新增一個策略,這個策略就是鏡像集群模式的策略,指定的時候可以要求數據同步到所有節點,也可以要求同步到指定數量的節點,然後再次創建queue時,應用這個策略,就會自動同步數據到其他節點上
4.kafka的高可用性:
一個最基本的架構認識,多個broker組成,每個broker是一個節點,創建一個topic,這個topic可以劃分為多個partition,每個partition可以存在與不同的broker上,每個partiton就放一部分數據。
kafka是一個天然的分散式的消息隊列,就是說一個topic的數據分佈在多個機器上面,每個機器就放一部分數據

如何保證消息不被重覆消費?如何保證消費的時候是冪等?

冪等性:
一條數據或者一個請求,給你重覆來多次,你得確保對應的數據是不會改變的,不能出錯

如何保證冪等呢?
一條數據重覆出現了兩次,資料庫里只有一條數據,這就保證了系統的冪等性
(1) 比如拿到數據要入庫,你先根據主鍵查一下,如果這個數據有了,就別再插入了,update一下就好
(2) 比如是寫redis,那就沒問題,因為是set,天然冪等的。
(3) 如果不是以上所述的場景,你需要讓生產者發送數據的時候,添加一個全局唯一的ID,然後到了消費者的時候,現根據id去排查,之前是否消費過? 如果沒有就處理,然後這個ID 寫入到map或者redis中;如果消費過了,那就別處理了,保障消息不被重覆處理即可;
如何保證消息的可靠性傳輸?要是消息丟了怎麼辦?
1).生產者弄丟數據
生產者將數據發送到rabbitmq的時候,可能數據就在半路給弄丟了,因為網路原因,都用可能
此時可以選擇用rabbitmq提供的事務功能,就是生產者發送數據之前開啟rabbitMQ事務(channel.txSelect)
,然後發送消息,如果消息沒有成功被rabbitmq接收到,那麼生產者會收到異常報錯,此時就可以回滾事務(channel.txRollback),然後嘗試重發消息;如果收到消息,那麼可以提交事務(channel.txCommit).但是問題是,rabbitMQ事務機制一搞,吞吐量就會下來,因為太耗性能。

2).MQ自己弄丟了數據
對於rabbitMQ,可以開啟持久化,寫入的消息以後會持久化到磁碟里,哪怕是mq自己掛了,恢復之後會自動讀取之前存儲的數據;
設置持久化有兩個步驟:
-
創建queue的時候將其設置為持久化,這樣就可以保證rabbitmq持久化queue的元數據,但是不會持久化queue裡面的數據;
-
發送消息的時候將消息 deliveryMode 設置為2,就是將消息設置為持久化,此時,rabbitMQ就會將消息持久化到磁碟里。 因此必須要同時設置這兩個持久化才行
總結: 生產者處的方案:開啟confirm模式,通過回調介面來得知是否成功發送到MQ
MQ內部的方案: 通過持久化到磁碟的方式,避免機器宕機導致記憶體中的數據丟失
消費者處的方案: 關閉 autoAck ,當消費者消費並處理完後手動進行ACK
3).Kafka
-
kafka消費者端丟失數據
唯一可能導致消費者端丟失數據的情況,在消費到這個消息的時候,消費者那邊自動提交了ofttset,讓kafka以為你已經消費了這個消息;其實剛準備處理消息,還沒處理完 ,就已經掛了,此時這條消息就已經丟了。
因為kafka會自動提交offset,那麼只要關閉自動提交offset,在處理玩以後再提交,就能夠避免這一類問題
-
kafka自己丟失數據
即kafka某個broker所在的機器宕機了,然後重新選partition的leader時,要是此時其他的follower還沒同步完數據,leader掛了,就造成數據的丟失。
一般要求有如下設置步驟:
-
給這個topic 設置 replication.factor參數 ,這個數值必須大於1,要求每個partition至少有2個副本
-
在kafka服務端設置 min.insync.replicas參數,這個數值必須大於1,這個要求一個leader至少感知到至少一個follower還跟自己保持聯繫,這樣才能保證leader掛了以後還有一個follower。
-
在producer端設置 acks=null : 這個要求生產者在寫消息,必須寫入leader,而且同步到所有的follower之後,生產者才會認為這條消息已經寫入了kafka中 ;
-
在procuduer端設置 retries=max(很大很大的值):這個要求一旦寫入失敗,就無限重試,卡在這裡
-
生產者會不會丟失數據
如果按照上面的思路設置 acks=null,一定不會丟失,因為leader收到消息後,要同步數據到所有的follower後,才認為本次寫入消息成功,否則生產者會不斷重試寫入,無限重試。
如何保證消息的順序性?
先看看順序出錯的場景
-
rabbitMQ:一個queue,多個consumer;這就明顯亂了
-
kafka: 一個topic,一個partition,一個consumer,多個線程去併發處理,就可能產生順序錯亂
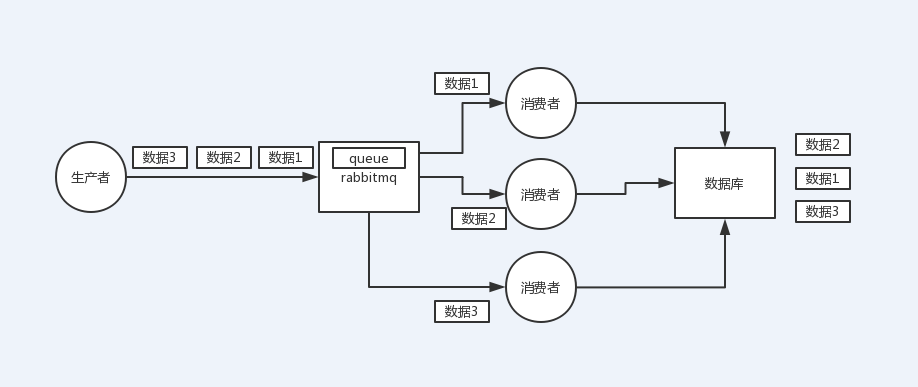
rabbitMQ如何保證消息的順序性:如果有多個消費者,就配置多個queue,將需要保證順序的消息全部寫到一個queue里,這樣就能保證消息的順序性
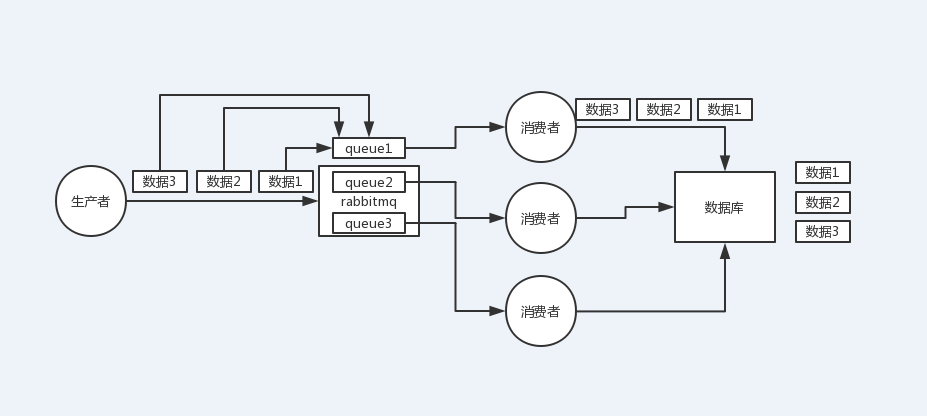
kafka順序性問題

1個topic,3個partition,3個consumer,每個消費者消費一個partition,需要保證順序的消息都放入同一個partiton,但是如果一個消費者開啟多個線程來處理,還是無法保證消息的順序性。
kafka如何保證消息的順序性:

解決辦法:每個消費者內部設置多個記憶體隊列,對消息的key做hash,將需要保證順序的消息映射到同一個記憶體隊列中,每個線程負責處理一個記憶體隊列
如何解決消息隊列的延時過期失效問題?消息隊列滿了以後該如何處理?有幾百萬消息持續積壓幾個小時,說說怎麼解決?
本質針對的場景是,消費端出問題了,不消費了,或者消費端消費速度很慢,可能消息隊列集群的磁碟都快滿了,都沒消費者來消費,導致整個就積壓了幾個小時,這個時候該怎麼辦?
RabbitMQ中由於消息積壓導致過期被清理了怎麼辦
假設你用的是rabbitmq,rabbitmq是可以設置過期時間的,就是TTL,如果消息在queue中積壓超過一定的時間就會被rabbitmq給清理掉,這個數據就沒了。
這就不是說數據會大量積壓在mq里,而是大量的數據會直接搞丟。
這個情況下,就不是說要增加consumer消費積壓的消息,因為實際上沒啥積壓,而是丟了大量的消息。
我們可以採取一個方案,就是批量重導。就是大量積壓的時候,我們當時就直接丟棄數據了,然後等過了高峰期以後,這個時候我們就開始寫程式,將丟失的那批數據,寫個臨時程式,一點一點的查出來,然後重新灌入mq裡面去,把白天丟的數據給他補回來。
假設1萬個訂單積壓在mq裡面,沒有處理,其中1000個訂單都丟了,你只能手動寫程式把那1000個訂單給查出來,手動發到mq里去再補一次
如果讓你來寫一個消息隊列,該如何進行架構設計?說一下你的思路?
-
首先這個MQ得支持可伸縮性,就是需要的時候快速擴容,就可以增加吞吐量和容量,如何搞? 設計一個分散式的系統唄,參考kafka的設計理念, broker->topic->partition ,每個partition放一個機器,就存一部分數據。如果現在資源不夠,就給topic增加partition(分區),然後做數據遷移,增加機器,就可以存放更多數據,提供更高的吞吐量。。。
-
其次要考慮這個MQ是否需要持久化到磁碟,肯定是要的,比如MQ進程掛了,數據還保存在磁碟中,導致數據不丟失。如何落地到磁碟?順序寫,這樣就沒有磁碟隨機讀取的定址開銷,磁碟順序讀寫的性能是很高的,這就是 Kafka的設計理念
-
其次還得考慮MQ的可用性,參照Kafka的高可用的策略。多副本->leader&follower->broker 掛了重新選舉leader即可對外服務
-
能不能支持0數據丟失,可以參照Kafka的數據零丟失方案
其實MQ是一個相當複雜的東西


