
一、導讀 愛奇藝的社交業務“泡泡”,擁有日活用戶6千萬+,後臺系統每日高峰期間介面QPS可以達到80K+,與視頻業務的主要區別是泡泡業務更多地引入了與用戶互動相關的數據,讀、寫的量均很大。無論是龐大的數據量,還是相對較高的QPS,使得我們在絕大多數場景下都依賴於高可靠、高性能、以及存儲量巨大的線上緩 ...
一、導讀
愛奇藝的社交業務“泡泡”,擁有日活用戶6千萬+,後臺系統每日高峰期間介面QPS可以達到80K+,與視頻業務的主要區別是泡泡業務更多地引入了與用戶互動相關的數據,讀、寫的量均很大。無論是龐大的數據量,還是相對較高的QPS,使得我們在絕大多數場景下都依賴於高可靠、高性能、以及存儲量巨大的線上緩存系統。本文介紹了一些我們在使用緩存方面的經驗以及優化的方法,希望對大家有所幫助。
二、Couchbase簡介
Couchbase(下文簡稱CB)是由CouchOne(創辦人包括CouchDB的設計者)和Membase(由memcached的主要開發人員建立)兩家公司在2011年初合併而來。Membase公司有一個名為Membase的產品,它是個鍵/值、持久化、可伸縮的解決方案,使用了memcached wire協議和SqlLite嵌入式存儲引擎。CouchOne支持的CouchDB是個文檔資料庫,提供了端到端的複製方法,這對於移動與分佈在不同位置的數據中心來說是很有用的。Couchbase是基於Membase與CouchDB開發的一款新產品,綜合了兩者的優點。
三、Couchbase vs Redis
Couchbase和Redis均是非常優秀的緩存產品,愛奇藝泡泡社交後臺根據不同的適用場景大量地使用了它們,總的來講它們各有優劣,總結如下:
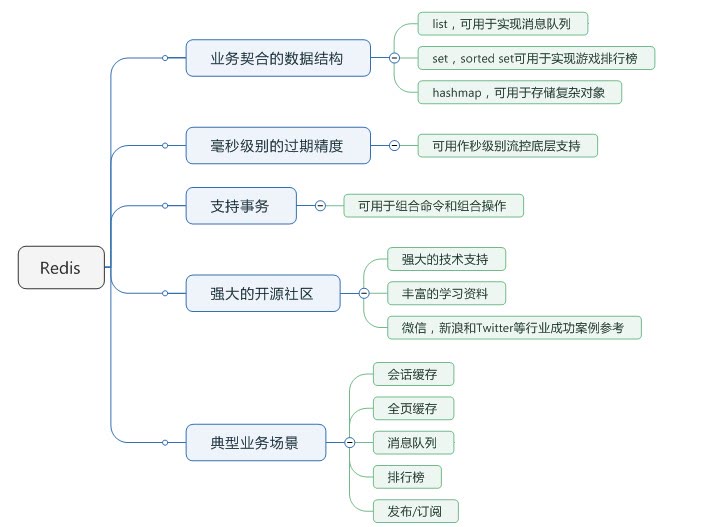
Redis優勢:
(1)Redis能夠支持更多的數據結構;
(2)Redis支持更多的應用場景(隊列、發佈訂閱、排行榜);
(3)Redis很多操作可以放到服務端做,減少了網路io;
(4)Redis社區更繁榮一點,文檔比較豐富,解決問題更快捷;
(5)Redis支持事務。
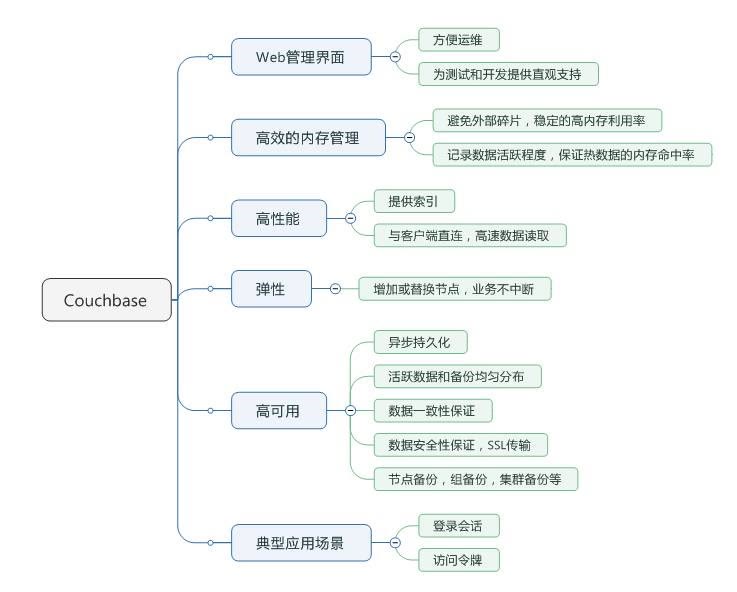
Couchbase優勢:
(1)CB能支撐更大的容量,Redis最好低於20G,否則failover之後恢復非常慢;
(2)CB有一個比較專業的管理界面;
(3)一致性hash發生在客戶端,性能更高;
(4)某台server宕機不影響業務方使用,只是可用記憶體受影響,可用性更高;
(5)可擴展性強。
Redis 的亮點在於業務契合度高,CB 的亮點在於高可用。以下節選一些具體的功能點對比:
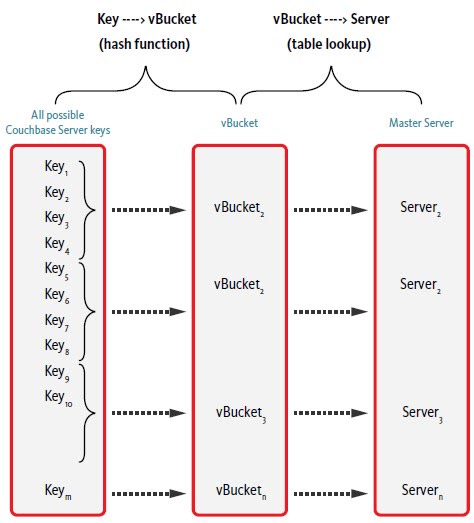
四、基礎知識:CB中的vBucket
在 CB 中,我們所操作的每一個bucket會邏輯劃分為1024個vBucket,其數據的儲存是基於每個vBucket儲存,並且每個 vBucket都會映射到相對應的伺服器節點,這種儲存結構的方式叫做集群映射。如圖所示,當應用與Couchbase伺服器交互時,會通過SDK與伺服器數據進行交互,當應用操作某一個bucket的key值時,在SDK中會通過哈希的方式計算,使用公式crc32(key)%1024確定key 值是屬於1024個vBucket中的某個,然後根據vBucket所映射的節點伺服器對數據進行操作。
為了保證分散式存儲系統的高可靠性和高可用性,數據在系統中一般存儲多個副本。當某個副本所在的存儲節點出現故障時,分散式存儲系統能夠自動將服務切換到其它的副本,從而實現自動容錯。
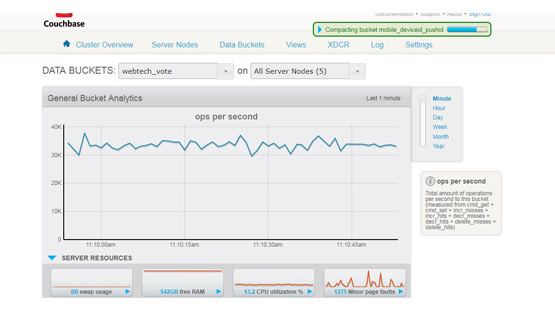
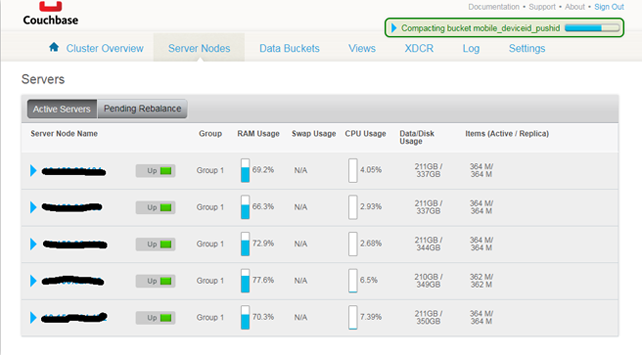
五、友善的Web console
CB自帶了一套非常友善的Web console,使得運維及監控操作非常地方便。
六、案例1: 點贊系統緩存優化
首先介紹一下點贊系統業務場景:
點贊系統承載了兩種業務的點贊,第一種叫做feed點贊:我們管泡泡圈子承載的信息流叫做feed流,而其中的每一篇帖子叫做一條feed。為了便於理解,大家可以把微信朋友圈當做是個feed流,而其中的每一條狀態帖子就是一條feed。這類業務系統的要求是,有feed流漏出的地方就會查詢點贊系統,查詢方式是一個uid(全站用戶唯一id)+一組[feedid]列表;
第二種業務是評論業務的點贊,評論列表漏出的地方就會查詢點贊系統,查詢方式是一個uid+一組[commentid]列表(每條評論也有一個全局唯一id叫commentid)。
階段一:Redis緩存
使用Redis做為緩存,緩存30G打滿,通過LRU置換key。
點贊系統的第一個階段,緩存結構中的key是實體id(即feedid或commentid),value是點贊過該實體的uid 集合。按照實體id查詢所有給這個實體點過贊的uid,並且更新Redis緩存。採用這種設計的系統情況是成功率經常抖動,響應時間不穩定。
通過業務日誌分析,發現hbase穿透很頻繁,緩存命中率不高,原因是緩存容量過低。由於公司雲平臺提供的是主從模式非集群的Redis,理論上最大緩存量(max_memory)不宜過大(30G已經是上限了),否則會引起主節點故障後failover到備用節點時間過長、甚至迴圈failover的情況。
當時考慮了兩種可能的優化方案:使用CB;或使用 Redis cluster。調研之後發現,原生的Redis cluster不支持批量查詢,而如果使用Redis cluster proxy的話可能會有較大性能損耗,並且Redis cluster不支持cluster集群之間的數據同步(我們的場景會用到三個IDC之間的集群同步),所以最終捨棄掉這個方案,考慮使用CB。
階段二:使用CB替換Redis
緩存key的考慮:uid維度,浪費空間,很多過時的數據會被載入到記憶體,並且受制於hbase表結構,無法實時拿到某用戶點過的所實體。而使用實體id維度,CB不支持server端查詢,需要把數據拉到客戶端來判斷,對於比較熱門的實體,uid可能成千上萬,數據量太大。uid+實體id維度,CB用量可能比較大,不過查詢數據量很小。
最終我們的key採用了uid+實體id的維度,value為是否點過贊。根據uid+實體id進行exist操作(緩存沒命中則找不到key,命中的話會返回true或false表明是否點過贊),查詢結果更新緩存。
但是很快發現了一些問題:由於緩存命中率低(同一個人再次訪問同一個feed才會命中,這種情況比較少見),造成hbase壓力過大。不過因為查詢hbase使用exist操作,不需要讀取數據,所以響應時間很短,成功率基本沒有受影響。同時分析了當時的緩存用量的增長趨勢,發現CB容量可能扛不住。
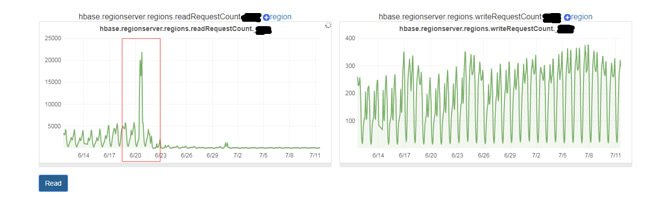
階段三:key的優化
採用實體id+shard方式存儲(shard=uid%factor ,實體id維度的變種)
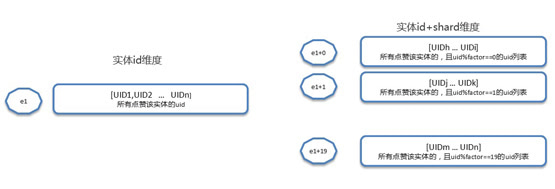
緩存中key使用實體id+shard的方式,value是點過贊的用戶列表。穿透到hbase後,根據實體id查詢出所有給該實體id點過贊的uid,然後分shard更新緩存,沒有數據的shard也要更新上標識。這種方案需要考慮shard個數,在空間和時間上取一個平衡。shard數越大,浪費的CB空間越多,但是每次查詢結果集越小。
下麵用一個例子來解釋兩種方案:實體id為e1,factor=20。
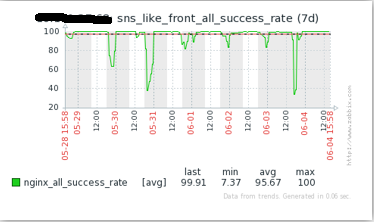
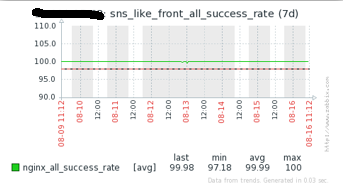
優化後的效果如下圖,可見成功率相對趨於穩定,且緩存命中率已經高於了99%。

至此優化告一段落了,在這個案例中,有個事情是值得思考的:怎樣才能獲得更高的命中率呢?我們的答案是誰重覆的次數多,以誰為維度緩存。某一個用戶可能瀏覽的feed個數是有限的幾十個或者幾百個,而某個feed可以被幾百萬甚至幾千萬的用戶看到。很明顯實體重覆次數多,所以我們是以實體id為維度(key)來存儲。
七、案例2: 投票系統緩存優化
項目背景:投票計數器緩存結構,一個投票可以簡單理解為vid(投票id)+多個oid(選項),需要如下緩存,用做計數器。

此次優化主要是針對某熱門綜藝活動暴露出來的問題。該活動的投票分多個渠道(4個),每個渠道對應一個投票,同時還有一個彙總的投票,每個渠道的選項數是70個。每次業務查詢投票介面,各渠道帶過來的投票vid都是自己渠道的投票vid,後端需要查詢子渠道投票和彙總投票信息,整合之後返回給App端上。
計數器讀寫模型如下:

之所以每個選項都是一個key,是因為這裡考慮到分散式併發操作,需要用到原子的incr操作來增加投票計數。該模式的問題是業務高峰期間對CB的OPS達到到1,400,000次/秒,CB物理機CPU報警。經排查監控分析,發現該綜藝活動查詢介面QPS有明顯變化,並且發現問題時候,大部分流量來自該介面。分析該介面相關代碼,發現如果選項過多,一次業務查詢,該段邏輯需要批量查300個左右的key,如果業務QPS達到5k(其實並不高),那麼CB的OPS將達到1,400,000次/秒左右,確認OPS增加是導致該問題的原因。
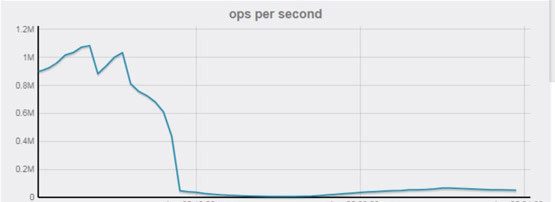
定位了原因,優化就很簡單了:用一個非同步task任務,每隔3s(具體時間間隔需根據業務情況確認)彙總一次所有CB的key,相當於業務的一次查詢請求,只需要讀一次CB的彙總key的操作,而寫請求基本不變(只多了每3秒一次的彙總操作,基本可以忽略),OPS大大降低,減輕物理機CPU壓力。
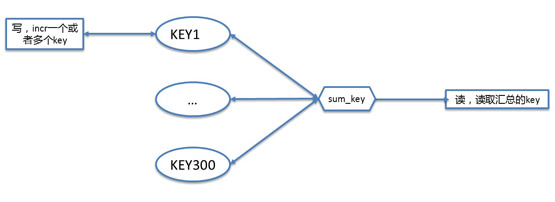
優化後效果非常明顯,對CB的OPS大幅降低:
八、案例3: CB客戶端SDK版本升級
項目背景:低版本SDK在CB集群rebalance完之後,需要重啟,否則可能會有很多超時情況,此為第一個原因。此外,某些後臺系統發現新擴容的worker機經常拋出如下異常,然後自動重連,並且不斷重覆這個過程,導致介面成功率下降。對比了新老機器的nginx、tomcat、代碼、jdk、能想到的linux系統參數、QPS、目標訪問數據等等,都是完全一致的,且夜間QPS低時候,該問題沒有那麼明顯。在找不到具體觸發該異常原因的情況下,由於異常是在CB的SDK中拋出來的(看起來像是讀取某個buffer時候越界),因此最直接的方法肯定是嘗試升級SDK。

最後我們的方案是將老版本的SDK 1.4.11 升級到 2.3.2。由於操作的都是線上系統,因此升級時需要考慮幾點:
(1)新老API相容問題;
(2)升級不能污染老數據,保證有問題可以回滾;
(3)由於新版本SDK提供了很多新功能,可以考慮順便優化緩存設計
最終我們根據兩個系統的不同情況,採用了兩種不同的升級策略:
系統A:緩存中的value都是string,可以跟CB 2.x中的StringDocument完美相容,所以直接在原來的CB集群上面操作上線。
系統B:緩存中的value類型比較多,如果直接線上上CB集群操作,風險較大,可能會造成數據被污染,且無法回滾,並且因為歷史原因線上集群中有一些ttl=0的臟數據,所以採用切換到臨時集群的方式:

九、其它註意事項
1.關於熱緩存中的數據,有兩種方式
需要根據具體業務來選擇:
方式1:用線上虛機熱數據,即挑選1~2台worker機切換到新CB,相當於一上來這幾台worker機的請求是100%到存儲上的,但是穿透完後會將數據種回緩存。待緩存命中率達到80%左右就可以繼續增加worker機,直到所有worker機都切換到新緩存上。這種方案的優點是簡單,缺點就是過程可能會有點慢,且切換過程中可能因為新、舊緩存不一致導致不同worker查出來的數據短暫不同步。
方式2:用作業熱緩存。根據指定的規則跑MapReduce作業(比如持久化數據是像我們一樣存在hbase中的),一次性把數據刷到緩存中,並且需要把刷存量數據期間產生的增量數據做一個特殊記錄,在刷完存量數據後再刷一遍增量的數據。這種方案的優點是過程比較快,缺點是複雜度高。
2.關於跨IDC數據同步的常用兩種方式
Couchbase本身就是集群,但通常所謂的集群指的是單一IDC內部的集群,由於機制的限制通常也不會推薦一個集群中存在跨IDC的CB實例。因此像我們這樣比較大型的、牽扯到多IDC的後臺系統,就需要考慮CB的跨IDC同步問題了。通常有兩種方案:
(1)使用CB自帶的XDCR,簡單快捷,對業務方透明,一致性有保障。比較推薦
(2)業務自己做同步數據。如使用kafka等消息服務來同步數據,即更新CB的worker機發送一條消息到kafka隊列,每個IDC都部署一臺consumer消費這條kafka消息,種自己本地IDC的CB緩存。這樣,相當於多個IDC之間的CB集群本身是獨立的,僅僅通過業務方自己的consumer來進行數據同步。該方式比較依賴消息服務,穩定性不是很高,一致性保障難度比較高,業務方需衡量。在早期的XDCR不是很穩定時我們曾有業務系統使用了這種方案,後續也逐步切換成了XDCR的方案。
3.關於遍歷所有key
CB不像Redis那樣有個keys(*)方法,可以用於遍歷所有緩存中的key。因此識別並清除CB中的臟數據(比如早期存了一些ttl=0的數據,後來又不用了)是一件比較難的事情。但是有一種替代方案:同步線上數據到離線CB集群(可以用XDCR),構建view,使用restful api分頁查詢,遍歷所有key。找到臟數據,刪除線上集群對應的key。註意該方式value必須是json。
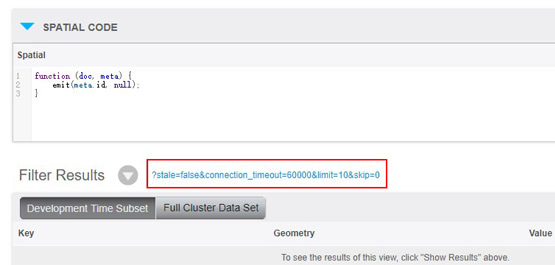
對於value為非json類型的數據,處理起來就很麻煩了。如果業務上有其它能夠用來索引key的方式,那麼可以採用這樣的業務上的數據來遍歷所有key。否則,只有像前文所述,申請一個新的CB集群->熱緩存->廢棄舊的CB集群。
4.開發運維的註意事項
還有一些開發的註意事項,再此一併分享一下:
(1)incr方法,要用String;
(2)ttl超過一個月,需要設置為絕對時間;
(3)新業務請用新版本client,功能更強大,bug更少,低版本坑太多
運維註意事項:
(1)最好裝一個ping工具監控worker機與CB集群之間的ping延時;
(2)訂閱報警,將問題解決在萌芽狀態;
(3)關註CB容量,CB使用記憶體要低於分配記憶體的75%,當bucket使用記憶體達到分配記憶體的75%時,由於記憶體不足,Couchbase會通過LRU演算法將部分數據從記憶體中踢出,只存儲在磁碟上,下一次讀取這部分數據時,再從磁碟取出並載入到記憶體。從磁碟取數據會使Couchbase的讀取性能降低。當bucket使用記憶體達到或接近分配記憶體的85%時,bucket可能會出現寫不進數據的情況,同時集群讀取性能受到較大影響。
十、總結
講了這麼多,最後總結一下對Couchbase緩存優化,其實一般就是指:
(1)提高緩存命中率:往往需要非常瞭解業務層面的用戶行為(如點贊系統須瞭解用戶如何刷feed)
(2)儘量減少OPS vs 一次獲取或寫入的數據量:取一個平衡
(3)優化緩存用量 vs 提高緩存命中率:取一個平衡
(4)業務複雜,空間不足:按照業務來拆分!
(5)節省空間:先考慮key的設計,再考慮使用protobuf等方式壓縮數據(較麻煩)。


