
ElkStack介紹 對於日誌來說,最常見的需求就是收集、存儲、查詢、展示,開源社區正好有相對應的開源項目:logstash(收集)、elasticsearch(存儲+搜索)、kibana(展示),我們將這三個組合起來的技術稱之為ELKStack,所以說ELKStack指的是Elasticsearc ...
ElkStack介紹
對於日誌來說,最常見的需求就是收集、存儲、查詢、展示,開源社區正好有相對應的開源項目:logstash(收集)、elasticsearch(存儲+搜索)、kibana(展示),我們將這三個組合起來的技術稱之為ELKStack,所以說ELKStack指的是Elasticsearch、Logstash、Kibana技術棧的結合
Elasticsearch
什麼是全文檢索和lucene?
基於java環境,基於Lucene之上包裝一層外殼
Lucene是一個java的搜索引擎庫,操作非常繁瑣
全文檢索和倒排索引:
數據裡裡的標題:
1.老男孩教育 1
2.老男孩教育linux學院 1 1 1
3.老男孩教育python學院 1 1
4.老男孩教育DBA 1 1
5.老男孩教育oldzhang 1
ES內部分詞,評分,倒排索引:
老男孩 1 2 3 4 5
教育 1 2 3 4 5
學院 2 3
linux 2
python 3
DBA 4
用戶輸入:
老男孩學院
linux老男孩學院DBA
Elasticsearch應用場景
1.搜索: 電商,百科,app搜索
2.高亮顯示: github
3.分析和數據挖掘: ELK
Elasticsearch特點
1.高性能,天然分散式
2.對運維友好,不需要會java語言,開箱即用
3.功能豐富
Elasticsearch在電商搜索的實現
mysql:
skuid name
1 狗糧100kg
2 貓糧50kg
3 貓罐頭200g
ES:
聚合運算之後得到SKUID:
拿到ID之後,mysql就只需要簡單地where查詢即可
mysql:
select xx from xxx where skuid 1
ES安裝啟動(最好同步時間)
0.停止其他軟體
systemctl stop docker
iptables -nL
iptables -F
iptables -X
iptables -Z
iptables -nL
查看索引
curl -s 127.0.0.1:9200/_cat/indices1.下載軟體
mkdir /data/soft
[root@db-01 /data/soft]# ll -h
total 268M
-rw-r--r-- 1 root root 109M Feb 25 2019 elasticsearch-6.6.0.rpm
-rw-r--r-- 1 root root 159M Sep 2 16:35 jdk-8u102-linux-x64.rpm2.安裝jdk
rpm -ivh jdk-8u102-linux-x64.rpm
[root@db-01 /data/soft]# java -version
openjdk version "1.8.0_212"
OpenJDK Runtime Environment (build 1.8.0_212-b04)
OpenJDK 64-Bit Server VM (build 25.212-b04, mixed mode)3.安裝ES
rpm -ivh elasticsearch-6.6.0.rpm4.檢查
systemctl daemon-reload
systemctl enable elasticsearch.service
systemctl start elasticsearch.service
netstat -lntup|grep 9200
[root@db01 /data/soft]# curl 127.0.0.1:9200
{
"name" : "pRG0qLR",
"cluster_name" : "elasticsearch",
"cluster_uuid" : "mNuJSe07QM61IOxecnanZg",
"version" : {
"number" : "6.6.0",
"build_flavor" : "default",
"build_type" : "rpm",
"build_hash" : "a9861f4",
"build_date" : "2019-01-24T11:27:09.439740Z",
"build_snapshot" : false,
"lucene_version" : "7.6.0",
"minimum_wire_compatibility_version" : "5.6.0",
"minimum_index_compatibility_version" : "5.0.0"
},
"tagline" : "You Know, for Search"
}ES配置啟動
1.查看ES有哪些配置
[root@db01 ~]# rpm -qc elasticsearch
/etc/elasticsearch/elasticsearch.yml #ES的主配置文件
/etc/elasticsearch/jvm.options #jvm虛擬機配置
/etc/sysconfig/elasticsearch #預設一些系統配置參數
/usr/lib/sysctl.d/elasticsearch.conf #配置參數,不需要改動
/usr/lib/systemd/system/elasticsearch.service #system啟動文件2.自定義配置文件
cp /etc/elasticsearch/elasticsearch.yml /opt/
cat >/etc/elasticsearch/elasticsearch.yml<<EOF
node.name: node-1
path.data: /var/lib/elasticsearch
path.logs: /var/log/elasticsearch
bootstrap.memory_lock: true
network.host: 10.0.0.51,127.0.0.1
http.port: 9200
EOF3.重啟服務後發現報錯
systemctl restart elasticsearch.service4.解決記憶體鎖定失敗:
查看日誌發現提示記憶體鎖定失敗
[root@db01 ~]# tail -f /var/log/elasticsearch/elasticsearch.log
[2019-11-14T09:42:29,513][ERROR][o.e.b.Bootstrap ] [node-1] node validation exception
[1] bootstrap checks failed
[1]: memory locking requested for elasticsearch process but memory is not locked
解決方案:
systemctl edit elasticsearch
[Service]
LimitMEMLOCK=infinity
systemctl daemon-reload
systemctl restart elasticsearch.servicees跟mysql關係對比
| mysql | es |
|---|---|
| 庫 | 索引 |
| 表 | 類型 |
| 欄位 | 項 key |
| 行 | 文檔 |
es交互方式
三種交互方式
curl命令:
最繁瑣
最複雜
最容易出錯
不需要安裝任何軟體,只需要有curl命令
es-head插件:
查看數據方便
操作相對容易
需要node環境
kibana:
查看數據以及報表格式豐富
操作很簡單
需要java環境和安裝配置kibana
es-head插件安裝
==註意:需要修改配置文件添加允許跨域參數==
修改ES配置文件支持跨域
/etc/elasticsearch/elasticsearch.yml
http.cors.enabled: true
http.cors.allow-origin: "*"es-head 三種方式:
1.npm安裝方式
- 需要nodejs環境
- 需要連接國外源
2.docker安裝
3.google瀏覽器插件(不需要配置跨域也可以)
- 修改文件名為zip尾碼
- 解壓目錄
- 拓展程式-開發者模式-打開已解壓的目錄
- 連接地址修改為ES的IP地址
具體操作命令
Head插件在5.0以後安裝方式發生了改變,需要nodejs環境支持,或者直接使用別人封裝好的docker鏡像
插件官方地址
https://github.com/mobz/elasticsearch-head
使用docker部署elasticsearch-head
docker pull alivv/elasticsearch-head
docker run --name es-head -p 9100:9100 -dit elivv/elasticsearch-head
傳統安裝使用nodejs編譯安裝elasticsearch-head
cd /opt/
wget https://nodejs.org/dist/v12.13.0/node-v12.13.0-linux-x64.tar.xz
tar xf node-v12.13.0-linux-x64.tar.xz
mv node-v12.13.0-linux-x64 node
vim /etc/profile
PATH=$PATH:/opt/node/bin
source profile
npm -v
node -v
git clone git://github.com/mobz/elasticsearch-head.git
unzip elasticsearch-head-master.zip
cd elasticsearch-head-master
npm install -g cnpm --registry=https://registry.npm.taobao.org
cnpm install
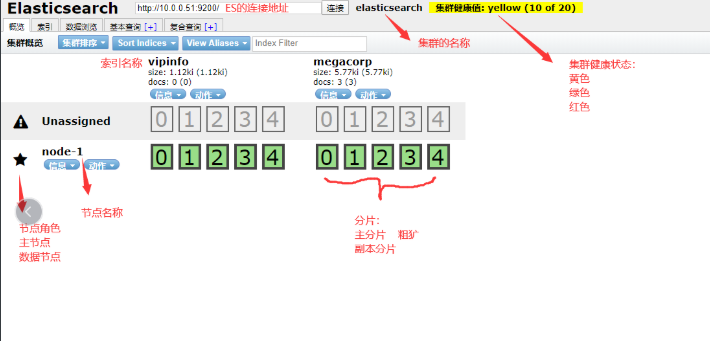
npm run start &es-head界面(10.0.0.51:9100,連接10.0.0.1:9200)
kibana與ES交互
1.安裝kibana
rpm -ivh kibana-6.6.0-x86_64.rpm2.配置kibana(跟es裝在同一臺機器上)
[root@db-01 /data/soft]# grep "^[a-Z]" /etc/kibana/kibana.yml
server.port: 5601
server.host: "10.0.0.51"
elasticsearch.hosts: ["http://localhost:9200"]
kibana.index: ".kibana"3.啟動kibana
systemctl start kibana
systemctl status kibana -l #查看狀態4.操作ES
Dev Tools kibana界面(10.0.0.51:5601)
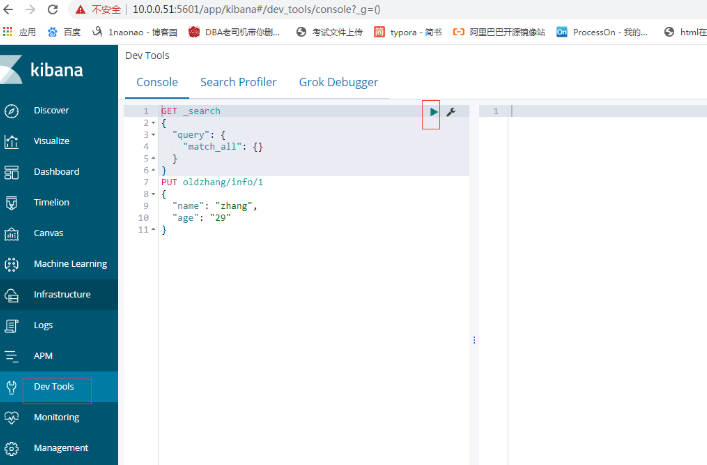
插入數據(處理問題)
1.使用自定義的ID
PUT oldzhang/info/1
{
"name": "zhang",
"age": "29"
}
2.使用隨機ID
POST oldzhang/info/
{
"name": "zhang",
"age": "29",
"pet": "xiaoqi"
}
3.和mysql對應關係建議單獨列一個欄位(解決延時問題)
POST oldzhang/info/
{
"uid": "1",
"name": "ya",
"age": "29"
}查詢數據
1.簡單查詢
GET /oldzhang/_search
GET /oldzhang/_search/1
2.單個條件查詢
GET /oldzhang/_search
{
"query" : {
"term" : { "job" : "it" }
}
}
3.多個條件查詢
GET /oldzhang/_search
{
"query" : {
"bool": {
"must": [
{"match": {"pet": "xiao10"}},
{"match": {"name": "yaz"}}
],
"filter": {
"range": {
"age": {
"gte": 27,
"lte": 30
}
}
}
}
}
}
}
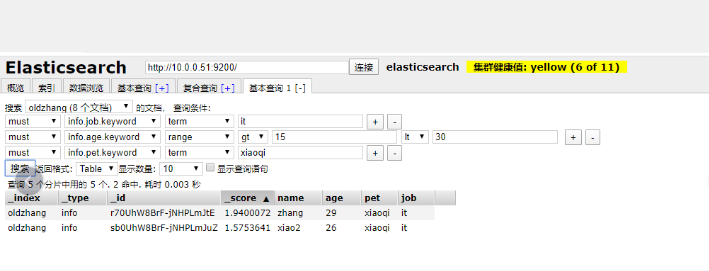
4.查詢方式
- curl命令
- es-head 基礎查詢多個條件
- es-head 左側欄位查詢
- kibana dev-tools 命令查詢
- kibana 索引查詢更新數據
GET oldzhang/info/1
PUT oldzhang/info/1
{
"name": "zhang",
"age": "30",
"job": "it"
}
POST oldzhang/info/1
{
"name": "zhang",
"age": "30",
"job": "it"
}刪除數據
1.刪除指定ID的數據
DELETE oldzhang/info/1
2.刪除符合條件的數據
POST oldzhang/_delete_by_query
{
"query" : {
"match":{
"age":"29"
}
}
}
3.刪除索引
DELETE oldzhang
4.!!!警告!!!
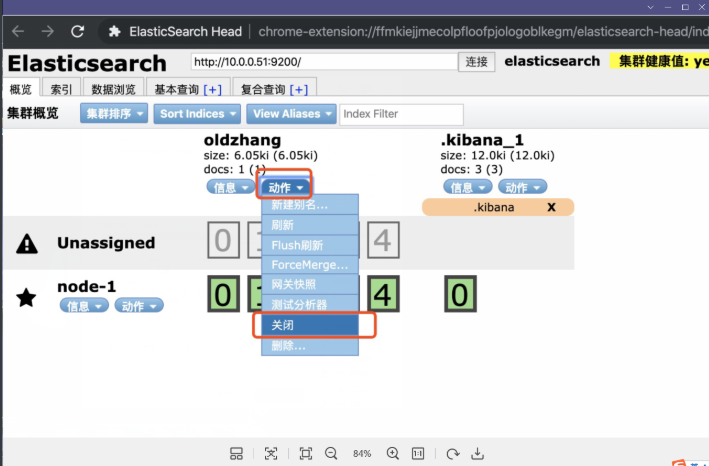
儘量不要在命令行或者Kibana里刪除,因為沒有任何警告
建議使用es-head刪除
生產環境可以先把索引關閉掉,如果一段時間沒人訪問了再刪除工作中刪除ES索引流程
1.先關閉需要刪除的索引
2.如果有業務在用,開發回來找你
3.業務遷移完成後,再次關閉
4.假如關閉之後等了一個星期還沒有人來找你
5.寫郵件給領導,交代清楚所有流程,等回覆
6.刪除之前備份一份,然後刪除
刪除索引推薦(變灰)
集群的相關名詞
1.集群健康狀態
綠色: 所有數據都完整,並且副本數滿足
黃色: 所有數據都完整,但是有的索引副本數不滿足
紅色: 有的數據不完整
2.節點類型
主節點: 負責調度數據分配到哪個節點
數據節點: 負責處理落到自己身上的數據
預設: 主節點同時也是數據節點
3.數據分片
主分片: 實際存儲的數據,負責讀寫,粗框的是主分片
副本分片: 主分片的副本,提供讀,同步主分片,細框的是副本分片
4.副本:
主分片的備份,副本數量可以自定義部署es集群
1.安裝java
rpm -ivh jdk-8u102-linux-x64.rpm
2.安裝ES
rpm -ivh elasticsearch-6.6.0.rpm
3.配置ES配置文件
配置記憶體鎖定:
systemctl edit elasticsearch.service
[Service]
LimitMEMLOCK=infinity
集群配置文件:
b01配置文件:
cat > /etc/elasticsearch/elasticsearch.yml <<EOF
cluster.name: linux5
node.name: node-1
path.data: /var/lib/elasticsearch
path.logs: /var/log/elasticsearch
bootstrap.memory_lock: true
network.host: 10.0.0.51,127.0.0.1
http.port: 9200
discovery.zen.ping.unicast.hosts: ["10.0.0.51", "10.0.0.52"]
discovery.zen.minimum_master_nodes: 1
EOF
==================================================================
db02配置文件:
cat> /etc/elasticsearch/elasticsearch.yml <<EOF
cluster.name: linux5
node.name: node-2
path.data: /var/lib/elasticsearch
path.logs: /var/log/elasticsearch
bootstrap.memory_lock: true
network.host: 10.0.0.52,127.0.0.1
http.port: 9200
discovery.zen.ping.unicast.hosts: ["10.0.0.51", "10.0.0.52"]
discovery.zen.minimum_master_nodes: 1
EOF
4.啟動
systemctl daemon-reload
systemctl restart elasticsearch
5.查看日誌
tail -f /var/log/elasticsearch/linux5.log
6.ES-head查看是否有2個節點es集群相關註意
註意事項:
1.插入和讀取數據在任意節點都可以執行,效果一樣
2.es-head可以連接集群內任一臺服務
3.主節點負責讀寫
如果主分片所在的節點壞掉了,副本分片會升為主分片
4.主節點負責調度
如果主節點壞掉了,數據節點會自動升為主節點查看集群各種信息
GET _cat/nodes
GET _cat/health
GET _cat/master
GET _cat/fielddata
GET _cat/indices
GET _cat/shards
GET _cat/shards/oldzhang擴容第三台機器
1.安裝java
rpm -ivh jdk-8u102-linux-x64.rpm2.安裝ES
rpm -ivh elasticsearch-6.6.0.rpm3.配置記憶體鎖定
systemctl edit elasticsearch.service
[Service]
LimitMEMLOCK=infinity4.db03集群配置文件
cat > /etc/elasticsearch/elasticsearch.yml <<EOF
cluster.name: linux5
node.name: node-3
path.data: /var/lib/elasticsearch
path.logs: /var/log/elasticsearch
bootstrap.memory_lock: true
network.host: 10.0.0.53,127.0.0.1
http.port: 9200
discovery.zen.ping.unicast.hosts: ["10.0.0.51", "10.0.0.53"]
discovery.zen.minimum_master_nodes: 1
EOF5.啟動
systemctl daemon-reload
systemctl restart elasticsearch集群註意事項
集群配置文件
1同一個集群的所有成員,集群名稱要一樣
2.節點名稱每個主機都不一樣
3.選舉相關參數,所有可能成為master的節點數/2+1=集群的大多數
註意1:發現節點參數不需要把集群內所有的機器IP都加上
只需要包含集群內任意一個IP和自己的IP就可以
discovery.zen.ping.unicast.hosts: ["10.0.0.51","10.0.0.53"]
註意2: 集群選舉相關的參數需要設置為集群節點數的大多數
discovery.zen.minimum_master_nodes: 2
註意3: 預設創建索引為1副本5分片
註意4: 數據分配的時候會出現2中顏色
紫色: 正在遷移
黃色: 正在複製
綠色: 正常
註意5: 3節點的時候
0副本一臺都不能壞
1副本的極限情況下可以壞2台: 1台1台的壞,不能同時壞2台
2副本的情況,發現節點數為1,可以同時壞2台
註意6:集群指令可以在集群內任意一個節點執行
通訊埠防火請要放行
9200 9300
監控狀態不能只監控顏色(穩定狀態下,監控顏色和節點數)動態修改最小發現節點數(臨時,出問題時動態改不了)
GET _cluster/settings
PUT _cluster/settings
{
"transient": {
"discovery.zen.minimum_master_nodes": 2
}
}自定義副本分片和索引
索引為2副本3分片
索引為0副本5分片
註意:
索引一旦建立完成,分片數就不可以修改了
但是副本數可以隨時修改
命令:
1.創建索引的時候就自定義副本和分片
PUT /yayayaay/
{
"settings": {
"number_of_shards": 3,
"number_of_replicas": 0
}
}
2.修改單個索引的副本數(壞兩台,其他索引丟數據)
PUT /oldzhang/_settings/
{
"settings": {
"number_of_replicas": 0
}
}
3.修改所有的索引的副本數
PUT /_all/_settings/
{
"settings": {
"number_of_replicas": 0
}
}
工作如何設置:
2個節點: 預設就可以
3個節點: 重要的數據,2副本 不重要的預設
日誌收集: 1副本3分片 監控
監控註意,不能只監控集群狀態
1.監控節點數
2.監控集群狀態
3.2者任意一個發生改變了都報警
監控命令: curl -s 127.0.0.1:9200/_cat/
GET _cat/nodes
GET _cat/healt增強插件x-pack監控功能
前提:同步時間,集群有警告,不影響集群
monitoring-->點一下藍色圖標 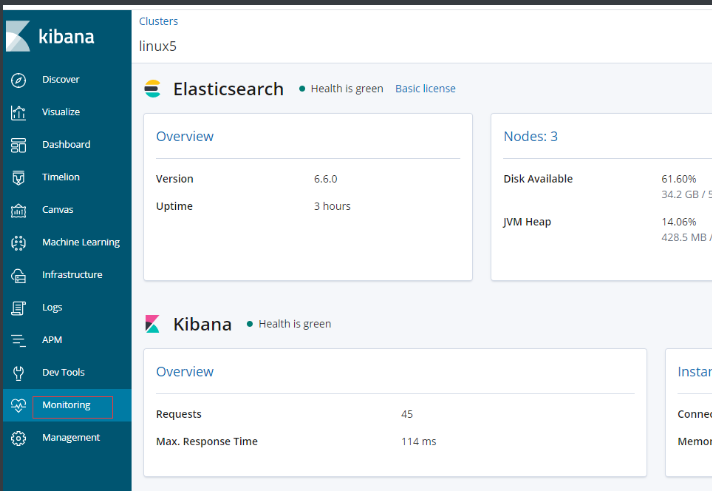
優化
1.記憶體
不要超過32G
48記憶體
系統留一半: 24G
自己留一半: 24G
8G 12G 16G 24G 30G
當前業務量 4G
先給 8G
滿了之後先別急的加記憶體,詢問開發和老大,是不是我們的使用問題
加到 12G
滿了之後先彆著急加記憶體,詢問開發和老大,是不是使用的問題
加16G 20G 24G 所有記憶體一半
要給老大打招呼,我們已經用到系統的一半記憶體了
官方建議不要超過30G,要考慮加機器了
2.硬碟的優化
RAID0 ssd
利用了ES集群本身的高可用優勢來彌補ssd硬碟和raid0的風險
兼顧速度和安全,比較費錢
3.代碼的優化
4.升級大版本
4.升級大版本
- 更新很多新功能
- 性能都會得到大幅提升
- 提前測試好
- 升級的風險
- 數據丟失的風險
- 功能的改變,代碼需要修改
- 滾動升級
5.必殺技
加機器 money$$$$$$集群發現相關參數
#跨機房調大點
discovery.zen.fd.ping_timeout: 120s
discovery.zen.fd.ping_retries: 6
discovery.zen.fd.ping_interval: 30s
超時時間為120s
重試次數為6次
每次間隔30秒 中文分詞
未分詞的情況:
1.插入測試數據
curl -XPOST http://localhost:9200/index/_create/1 -H 'Content-Type:application/json' -d'
{"content":"美國留給伊拉克的是個爛攤子嗎"}
'
curl -XPOST http://localhost:9200/index/_create/2 -H 'Content-Type:application/json' -d'
{"content":"公安部:各地校車將享最高路權"}
'
curl -XPOST http://localhost:9200/index/_create/3 -H 'Content-Type:application/json' -d'
{"content":"中韓漁警衝突調查:韓警平均每天扣1艘中國漁船"}
'
curl -XPOST http://localhost:9200/index/_create/4 -H 'Content-Type:application/json' -d'
{"content":"中國駐洛杉磯領事館遭亞裔男子槍擊 嫌犯已自首"}
'
2.檢測
curl -XPOST http://localhost:9200/index/_search -H 'Content-Type:application/json' -d'
{
"query" : { "match" : { "content" : "中國" }},
"highlight" : {
"pre_tags" : ["<tag1>", "<tag2>"],
"post_tags" : ["</tag1>", "</tag2>"],
"fields" : {
"content" : {}
}
}
}
'
分詞配置
1.配置中文分詞器
cd /usr/share/elasticsearch
./bin/elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v6.6.0/elasticsearch-analysis-ik-6.6.0.zip
2.創建索引
curl -XPUT http://localhost:9200/news
3.創建模板
curl -XPOST http://localhost:9200/news/text/_mapping -H 'Content-Type:application/json' -d'
{
"properties": {
"content": {
"type": "text",
"analyzer": "ik_max_word",
"search_analyzer": "ik_smart"
}
}
}'
4.插入測試數據
POST /news/text/1
{"content":"美國留給伊拉克的是個爛攤子嗎"}
POST /news/text/2
{"content":"公安部:各地校車將享最高路權"}
POST /news/text/3
{"content":"中韓漁警衝突調查:韓警平均每天扣1艘中國漁船"}
POST /news/text/4
{"content":"中國駐洛杉磯領事館遭亞裔男子槍擊 嫌犯已自首"}
5.再次查詢數據發現已經能識別中文了
POST /news/_search
{
"query" : { "match" : { "content" : "張亞" }},
"highlight" : {
"pre_tags" : ["<tag1>", "<tag2>"],
"post_tags" : ["</tag1>", "</tag2>"],
"fields" : {
"content" : {}
}
}
}
中文分詞
未分詞的情況
1.插入測試數據
POST /news/txt/1
{"content":"美國留給伊拉克的是個爛攤子嗎"}
POST /news/txt/2
{"content":"公安部:各地校車將享最高路權"}
POST /news/txt/3
{"content":"中韓漁警衝突調查:韓警平均每天扣1艘中國漁船"}
POST /news/txt/4
{"content":"中國駐洛杉磯領事館遭亞裔男子槍擊 嫌犯已自首"}
2.檢測
POST /news/_search
{
"query" : { "match" : { "content" : "中國" }},
"highlight" : {
"pre_tags" : ["<tag1>", "<tag2>"],
"post_tags" : ["</tag1>", "</tag2>"],
"fields" : {
"content" : {}
}
}
}分詞配置
0.前提條件
- 所有的ES節點都需要安裝
- 所有的ES都需要重啟才能生效
1.配置中文分詞器
cd /usr/share/elasticsearch
./bin/elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v6.6.0/elasticsearch-analysis-ik-6.6.0.zip
本地文件安裝
/usr/share/elasticsearch/bin/elasticsearch-plugin install file:///XXX/elasticsearch-analysis-ik-6.6.0.zip
重啟
2.創建索引
PUT /news1
3.創建模板
POST /news1/text/_mapping
{
"properties": {
"content": {
"type": "text",
"analyzer": "ik_max_word",
"search_analyzer": "ik_smart"
}
}
}
ik_smart:粗略的分詞
ik_max_word:比較精細的分詞
4.插入測試數據
POST /news1/text/1
{"content":"美國留給伊拉克的是個爛攤子嗎"}
POST /news1/text/2
{"content":"公安部:各地校車將享最高路權"}
POST /news1/text/3
{"content":"中韓漁警衝突調查:韓警平均每天扣1艘中國漁船"}
POST /news1/text/4
{"content":"中國駐洛杉磯領事館遭亞裔男子槍擊 嫌犯已自首"}
5.再次查詢數據發現已經能識別中文了
POST /news1/_search
{
"query" : { "match" : { "content" : "中國" }},
"highlight" : {
"pre_tags" : ["<tag1>", "<tag2>"],
"post_tags" : ["</tag1>", "</tag2>"],
"fields" : {
"content" : {}
}
}
}重新查數據的原理圖
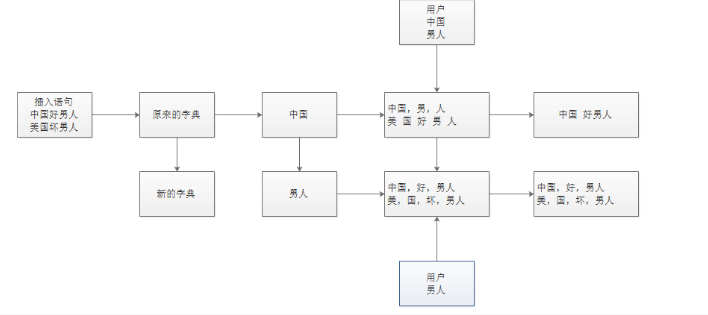
安裝報錯總結
1.集群內所有的機器沒有全部都安裝插件
2.執行完命令不看提示,安裝失敗了不知道
3.創建的索引和搜索的索引名稱不是一個
4.創建模版之前要先單獨創建索引
5.安裝包上傳不完整導致安裝失敗
6.ES節點配置不統一
7.修改完沒有全部重啟
8.字典也一樣
手動更新字典
1.創建字典
vi /etc/elasticsearch/analysis-ik/main.dic
2.把字典發送到集群內所有的機器
scp main.dic 10.0.0.52:/etc/elasticsearch/analysis-ik/
3.重啟所有的ES節點!!!
systemctl restart elasticsearch
4.更新索引的數據
POST /news2/text/5
{"content":"昨天胖虎很囂張,讓張亞請他吃飯"}
5.搜索測試
POST /news2/_search
{
"query" : { "match" : { "content" : "胖虎" }},
"highlight" : {
"pre_tags" : ["<tag1>", "<tag2>"],
"post_tags" : ["</tag1>", "</tag2>"],
"fields" : {
"content" : {}
}
}
}
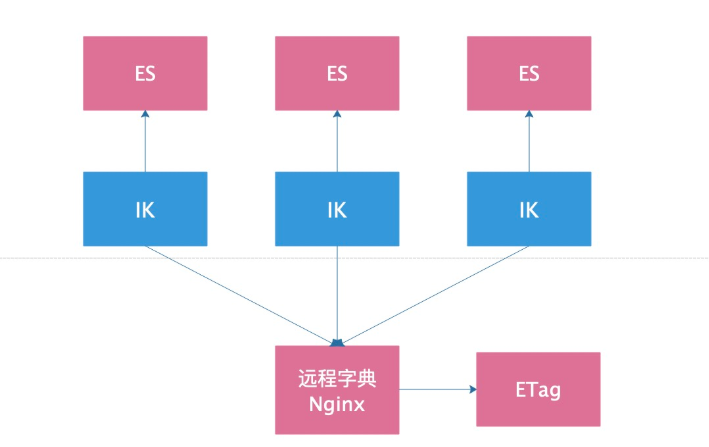
熱更新中文分詞庫
原理圖(F12>>>>ETag會改變)
1.安裝nginx
[root@db01 ~]# cat /etc/yum.repos.d/nginx.repo
[nginx-stable]
name=nginx stable repo
baseurl=http://nginx.org/packages/centos/$releasever/$basearch/
gpgcheck=1
enabled=1
gpgkey=https://nginx.org/keys/nginx_signing.key
module_hotfixes=true
[nginx-mainline]
name=nginx mainline repo
baseurl=http://nginx.org/packages/mainline/centos/$releasever/$basearch/
gpgcheck=1
enabled=0
gpgkey=https://nginx.org/keys/nginx_signing.key
module_hotfixes=true
yum makecache fast
yum -y install nginx
2.配置nginx
[root@db01 nginx]# cat /etc/nginx/conf.d/default.conf
server {
listen 80;
server_name localhost;
#access_log /var/log/nginx/host.access.log main;
location / {
root /usr/share/nginx/html/;
charset utf-8;
autoindex on;
autoindex_localtime on;
autoindex_exact_size off;
}
}
nginx -t
systemctl start nginx
3.寫字典
[root@db01 nginx]# cat /usr/share/nginx/html/my.txt
我
中國
日本
打發
臺灣
小日本
伊朗
時間
滾蛋
王總
4.配置es的中文分詞器插件
vim /etc/elasticsearch/analysis-ik/IKAnalyzer.cfg.xml
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IK Analyzer 擴展配置</comment>
<!--用戶可以在這裡配置自己的擴展字典 -->
<entry key="ext_dict"></entry>
<!--用戶可以在這裡配置自己的擴展停止詞字典-->
<entry key="ext_stopwords"></entry>
<!--用戶可以在這裡配置遠程擴展字典 -->
<entry key="remote_ext_dict">http://10.0.0.51/my.txt</entry>
<!--用戶可以在這裡配置遠程擴展停止詞字典-->
<!-- <entry key="remote_ext_stopwords">words_location</entry> -->
</properties>
5.將修改好的IK配置文件複製到其他所有ES節點
scp /etc/elasticsearch/analysis-ik/IKAnalyzer.cfg.xml 10.0.0.53:/etc/elasticsearch/analysis-ik/
6.重啟所有的ES節點
systemctl restart elasticsearch
7.查看日誌里字典的詞有沒有載入出來
tail -f /var/log/elasticsearch/linux5.log
8.打開es日誌,然後更新字典內容,查看日誌里會不會自動載入
9.搜索測試驗證結果
POST /news2/text/6
{"content":"昨天胖虎很囂張,把班長打了一頓並讓班長請他吃飯"}
POST /news2/_search
{
"query" : { "match" : { "content" : "班長" }},
"highlight" : {
"pre_tags" : ["<tag1>", "<tag2>"],
"post_tags" : ["</tag1>", "</tag2>"],
"fields" : {
"content" : {}
}
}
}
測試是否更新
echo "武漢" >> /usr/share/nginx/html/my.txt
10.電商上架新產品流程(先更新字典,在插入數據)
- 先把新上架的商品的關鍵詞更新到詞典里
- 查看ES日誌,確認新詞被動態更新了
- 自己編寫一個測試索引,插入測試數據,然後查看搜索結果
- 確認沒有問題之後,在讓開發插入新商品的數據
- 測試備份恢復
0.前提條件
必須要有Node環境和npm軟體
nodejs
npm 1.nodejs環境安裝(註意路徑的存放)
cd /opt
weget https://nodejs.org/dist/v10.16.3/node-v10.16.3-linux-x64.tar.xz
tar xf node-v10.16.3-linux-x64.tar.xz
mv node-v12.13.0-linux-x64 node
echo "export PATH=/opt/node/bin:\$PATH" >> /etc/profile
source /etc/profile
[root@db-01 ~]# node -v
v10.16.3
[root@db-01 ~]# npm -v
6.9.02.指定使用國內淘寶npm源
npm install -g cnpm --registry=https://registry.npm.taobao.org3.安裝es-dump
cnpm install elasticdump -g4.備份命令
備份成可讀的json格式
elasticdump \
--input=http://10.0.0.51:9200/news2 \
--output=/data/news2.json \
--type=data
備份成壓縮格式(恢復先解壓gzip -d ,在恢復)
elasticdump \
--input=http://10.0.0.51:9200/news2 \
--output=$|gzip > /data/news2.json.gz
備份分詞器/mapping/數據一條龍服務(先恢復mapping表空間,在恢複數據)不同節點之間也可以備份恢復
elasticdump \
--input=http://10.0.0.51:9200/news2 \
--output=/data/news2_analyzer.json \
--type=analyzer
elasticdump \
--input=http://10.0.0.51:9200/news2 \
--output=/data/news2_mapping.json \
--type=mapping
elasticdump \
--input=http://10.0.0.51:9200/news2 \
--output=/data/news2.json \
--type=data5.恢覆命令
只恢複數據
elasticdump \
--input=/data/news2.json \
--output=http://10.0.0.51:9200/news2
恢復所有數據包含分詞器/mapping一條龍
elasticdump \
--input=/data/news2_analyzer.json \
--output=http://10.0.0.51:9200/news2 \
--type=analyzer
elasticdump \
--input=/data/news2_mapping.json \
--output=http://10.0.0.51:9200/news2 \
--type=mapping
elasticdump \
--input=/data/news2.json \
--output=http://10.0.0.51:9200/news2
--type=data批量備份
curl -s 127.0.0.1:9200/_cat/indices|awk '{print $3}'6.備份恢復註意
恢復的時候需要先解壓縮成json格式
恢復的時候,如果已經存在相同的數據,會被覆蓋掉
如果新增加的數據,則不影響,繼續保留

