
目標網站:古詩文網 登錄界面顯示: 打開控制台工具,輸入賬號密碼,在ALL欄目中進行抓包 數據如下: 登錄請求的url和請求方式 登錄所需參數 參數分析: __VIEWSTATE和__VIEWSTATEGENERATOR可以在登錄界面獲取,code為驗證碼,email為賬號,pwd為密碼,from為 ...
目標網站:古詩文網
登錄界面顯示:
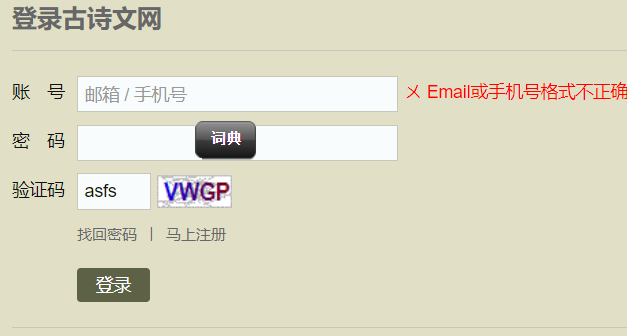
打開控制台工具,輸入賬號密碼,在ALL欄目中進行抓包
數據如下:
登錄請求的url和請求方式
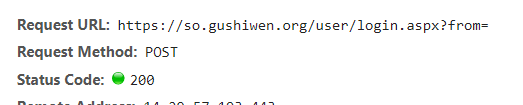
登錄所需參數
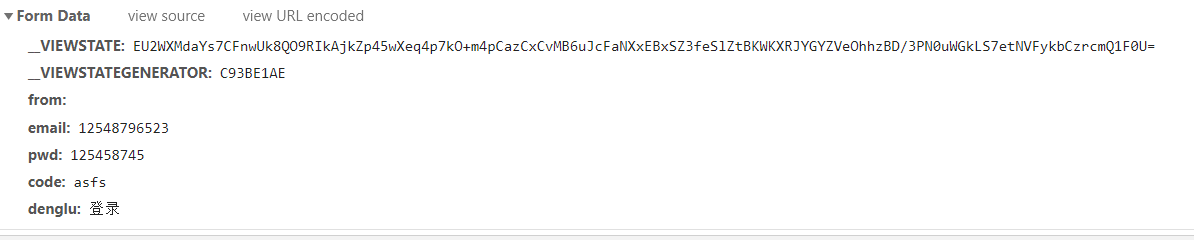
參數分析:
__VIEWSTATE和__VIEWSTATEGENERATOR可以在登錄界面獲取,code為驗證碼,email為賬號,pwd為密碼,from為空,denglu為固定參數
分析__VIEWSTATE和__VIEWSTATEGENERATOR


可通過解析登錄界面獲取
整體代碼如下:
# 引入各種庫 import requests from lxml import etree import pytesseract from PIL import Image from io import BytesIO # 會話保持 s = requests.session() headers = { 'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.97 Safari/537.36' } # 登錄界面路由 login_url = 'https://so.gushiwen.org/user/login.aspx?from=' r = s.post(login_url,headers=headers) res = etree.HTML(r.text) # 獲取登錄參數 __VIEWSTATE = res.xpath('//input[@id="__VIEWSTATE"]/@value')[0] __VIEWSTATEGENERATOR = res.xpath('//input[@id="__VIEWSTATEGENERATOR"]/@value')[0] # 獲取驗證碼 codeimage = s.get('https://so.gushiwen.org/RandCode.ashx') # 識別驗證碼 def get_code(data): img = Image.open(BytesIO(data)) img = img.convert('L') captcha = pytesseract.image_to_string(img) print(captcha) img.close() return captcha # 構造登錄參數 formdata = { '__VIEWSTATE': __VIEWSTATE, '__VIEWSTATEGENERATOR': __VIEWSTATEGENERATOR, 'from': '', 'email': '你的賬號', 'pwd': '你的密碼', 'code': get_code(codeimage.content), 'denglu': '登錄' } # 模擬登錄 res = s.post(login_url,headers=headers,data=formdata) # 判斷是否登錄成功,成功的話會跳轉到個人中心 if '我的收藏' in res.text: print('登陸成功') else: print('登陸失敗')
控制台輸出:

註意:文章賬號秘密是錯誤的,讀者可以自己申請賬號,
爬蟲的開始需使用
s = requests.session()
來使會話維持,否則請求的驗證碼與登錄時不同步,
驗證碼識別有成功率,不一定一次成功。
python系列教程:
鏈接:https://pan.baidu.com/s/10eUCb1tD9GPuua5h_ERjHA
提取碼:h0td


