併發編程之無鎖 6.2 CAS與volatile 源碼之LongAdder 6.8 Unsafe 6.2 CAS與volatile 其中的關鍵是compareAndSet,它的簡稱就是CAS(也有Compare And Swap的說法),它必須是原子操作。註意其實CAS的底層是lock cmpxch ...
併發編程之無鎖
6.2 CAS與volatile

其中的關鍵是compareAndSet,它的簡稱就是CAS(也有Compare And Swap的說法),它必須是原子操作。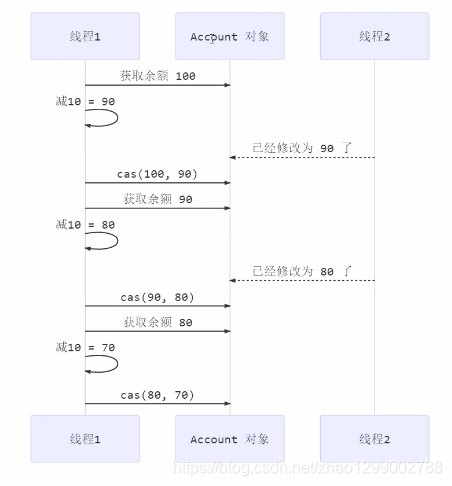
註意
其實CAS的底層是lock cmpxchg指令(X86架構),在單核CPU和多核CPU下都能夠保證【比較-交換】的原子性。
- 在多核狀態下,某個核執行到帶lock的指令時,CPU會讓匯流排鎖住,當這個核把此指令執行完畢,再開啟匯流排。這個過程中不會被線程的調度機制所打斷,保證了多個線程對記憶體操作的準確性,是原子的。
volatile
獲取共用變數時,為了保證變數的可見性,需要使用volatile修飾。
它可以用來修飾成員變數和靜態成員變數,他可以避免線程從自己的工作緩存中查找變數的值,必須到主存中獲取它的值,線程操作volatile變數都是直接操作主存。即一個線程對volatile變數的修改,對另一個線程可見。
註意 :
volatile僅僅保證了共用變數的可見性,讓其它線程能夠看到最新值,但不能解決指令交錯問題(不能保證原子性)
CAS必須藉助volatile才能讀取到共用變數的最新值來實現【比較並交換】的效果
為什麼無鎖效率高 - 無鎖情況下,即使重試失敗,線程始終在高速運行,沒有停歇,而synchronized會讓線程在沒有獲得鎖的時候,發生上下文切換,進入阻塞。打個比喻
- 線程就好像高速跑道上的賽車,高速運行時,速度超快,一旦發生上下文切換,就好比賽車要減速、熄火,等被喚醒又得重新打火、啟動、加速…恢復到高速運行,代價比較大
- 但無鎖情況下,因為線程要保存運行,需要額外CPU的支持,CPU在這裡就好比高速跑道,沒有額外的跑道,線程想高速運行也無從談起,雖然不會進入阻塞,但由於沒有分到時間片,任然會進入可運行狀態,還是會導致上下文切換。
CAS的特點
結合CAS和volatile可以實現無鎖併發,適用於線程數少、多核CPU的場景下。 - CAS是基於樂觀鎖的思想 :最客觀的估計,不怕別的線程來修改共用變數,就算改了也沒關係,我吃虧點再重試。
- synchronized是基於悲觀鎖的思想 :最悲觀的估計,提防著其他線程來修改共用變數,我上了鎖你們都別想改,我改完瞭解開鎖,你們才有機會。
- CAS體現的是無鎖併發、無阻塞併發
- 因為沒有使用synchronized,所以線程不會陷入阻塞,這是效率提升的因素之一
- 但如果競爭激烈,可以想到重試必然頻繁發生,反而效率會受影響
package com.example.demo;
import java.util.ArrayList;
import java.util.List;
import java.util.concurrent.atomic.AtomicLong;
import java.util.concurrent.atomic.LongAdder;
import java.util.function.Consumer;
import java.util.function.Supplier;
public class Test4 {
public static void main(String[] args) {
demo(
() -> new AtomicLong(0),
(adder) -> adder.getAndIncrement()
);
demo(
() -> new LongAdder(),
(adder) -> adder.increment()
);
}
/**
*
* @param adderSupplier : () -> 結果 提供累加器對象
* @param action : (參數) -> void 執行累加操作
* @param <T>
*/
private static <T> void demo(Supplier<T> adderSupplier, Consumer<T> action) {
T adder = adderSupplier.get();
List<Thread> threadList = new ArrayList<>();
// 4個線程,每人累加50萬
for (int i = 0; i < 4; i++) {
threadList.add(new Thread(() -> {
for (int j = 0; j < 500000; j++) {
action.accept(adder);
}
}));
}
long start = System.nanoTime();
threadList.forEach(t -> t.start());
long end = System.nanoTime();
System.out.println(adder + " cost : " + (end - start));
}
}
package com.example.demo;
import java.util.ArrayList;
import java.util.List;
import java.util.function.BiConsumer;
import java.util.function.Consumer;
import java.util.function.Function;
import java.util.function.Supplier;
public class Test3 {
public static void main(String[] args) {
}
/**
* 參數1,提供數組,可以是線程不安全數組或線程安全數組
* 參數2,獲取數組長度的方法
* 參數3,自增方法,回傳array,index
* 參數4,列印數組的方法
*
* @param arraySupplier : 提供者 無中生有 () -> 結果
* @param lengthFun : 函數 一個參數一個結果 (參數) -> 結果 ,BiFunction(參數1,參數2) -> 結果
* @param putConsumer : 消費者 (參數1,參數2) -> void
* @param printConsumer : 消費者 (參數) -> void
* @param <T>
*/
private static <T> void demo(
Supplier<T> arraySupplier,
Function<T, Integer> lengthFun,
BiConsumer<T, Integer> putConsumer,
Consumer<T> printConsumer
) {
List<Thread> threadList = new ArrayList<>();
T array = arraySupplier.get();
Integer length = lengthFun.apply(array);
for (int i = 0; i < length; i++) {
// 每個線程對數組做10000次操作
threadList.add(new Thread(() -> {
for (int j = 0; j < 10000; j++) {
putConsumer.accept(array, j % length);
}
}));
}
threadList.forEach(thread -> thread.start());
}
}
輸出
性能提升的原因很簡單,就是在有競爭時,設置多個累加單元,Thread-0累加 Cel【0】,而Thread-1累加Cell【1】。。。最後將結果彙總。這樣它們在累加時操作的不同的Cell變數,因此減少了CAS重試失敗,從而提高性能。
源碼之LongAdder
LongAdder類有幾個關鍵域
- 原理之偽共用
其中Cell即為累加單元
緩存與記憶體的速度比較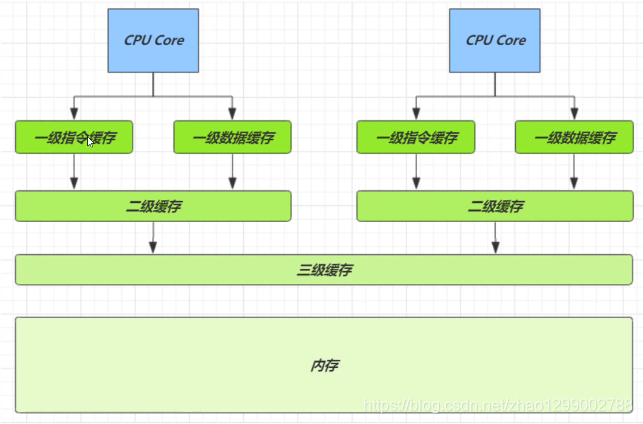

因為CPU與記憶體的速度差異很大,需要靠預讀數據至緩存來提升效率。
而緩存以緩存行為單位,每個緩存行對應著一塊記憶體,一般是64byte(8個long)
緩存的加入會造成數據副本的產生,即同一份數據會緩存在不同核心的緩存行中,CPU要保證數據的一致性,如果某個CPU核心更改了數據其它CPU核心對應的整個緩存行必須失效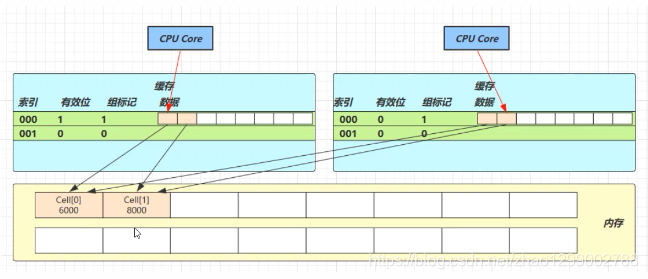
因為Cell是數組形式,在記憶體中是連續存儲的,一個Cell為24位元組(16位元組的對象頭和8位元組的value),因此緩存行可以存下2個的Cell對象。這樣問題來了 : - Core-0要修改Cell【0】
- Core-1要修改Cell【1】
無論誰修改成功,都會導致對方Core的緩存行失效,比如Core-0中Cell【0】=6000,Cell【1】=8000 要累加Cell【0】=6001,Cell【1】=8000,這時會讓Core-1的緩存行失效
@sun.misc.Contended用來解決這個問題,它的原理是在使用此註解的對象或欄位的前後各增加128位元組大小的padding,從而讓CPU將對象預讀至緩存時占用不同的緩存行,這樣,不會造成對方緩存行的失效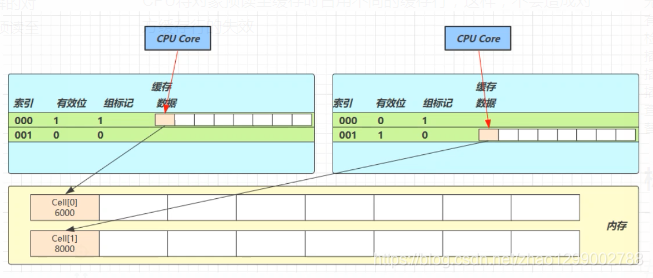
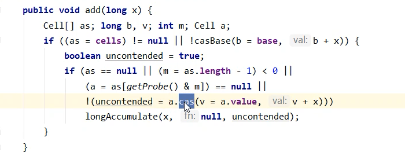
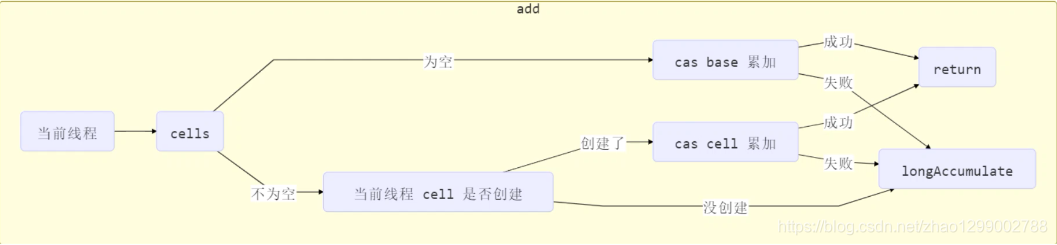

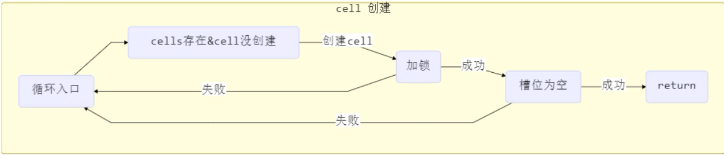
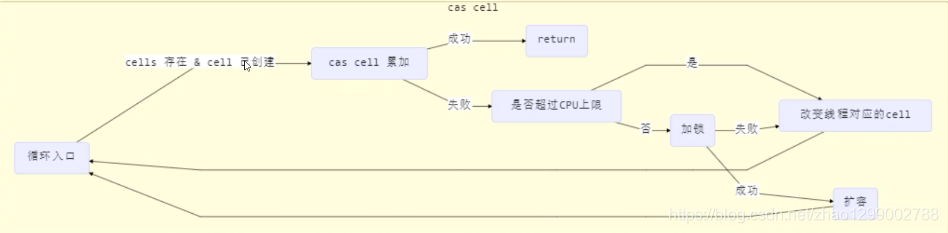
獲取最終結果通過sun方法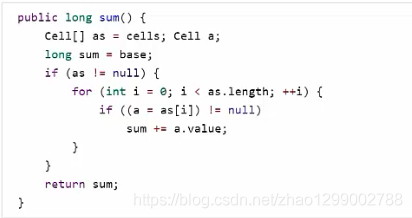
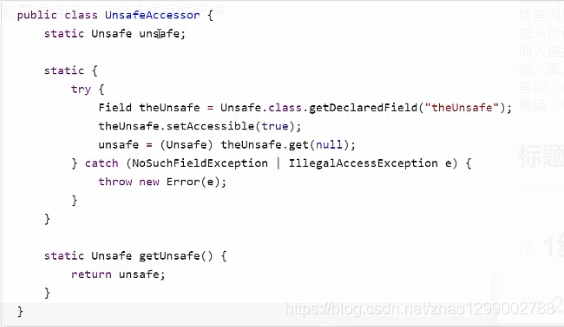
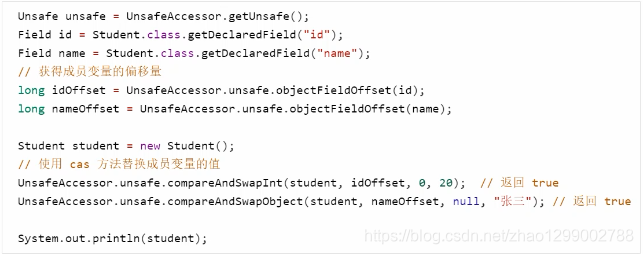
6.8 Unsafe
概述
Unsafe對象提供了非常底層的,操作記憶體、線程的方法,Unsafe對象不能直接調用,只能通過反射獲得