
生產者是如何生產消息 如何創建生產者 發送消息到Kafka 生產者配置 分區 ...
Kafka系列2:深入理解Kafka消費者
上篇聊了Kafka概況,包含了Kafka的基本概念、設計原理,以及設計核心。本篇單獨聊聊Kafka的生產者,包括如下內容:
- 生產者是如何生產消息
- 如何創建生產者
- 發送消息到Kafka
- 生產者配置
- 分區
生產者是如何生產消息的
首先來看一下Kafka生產者組件圖
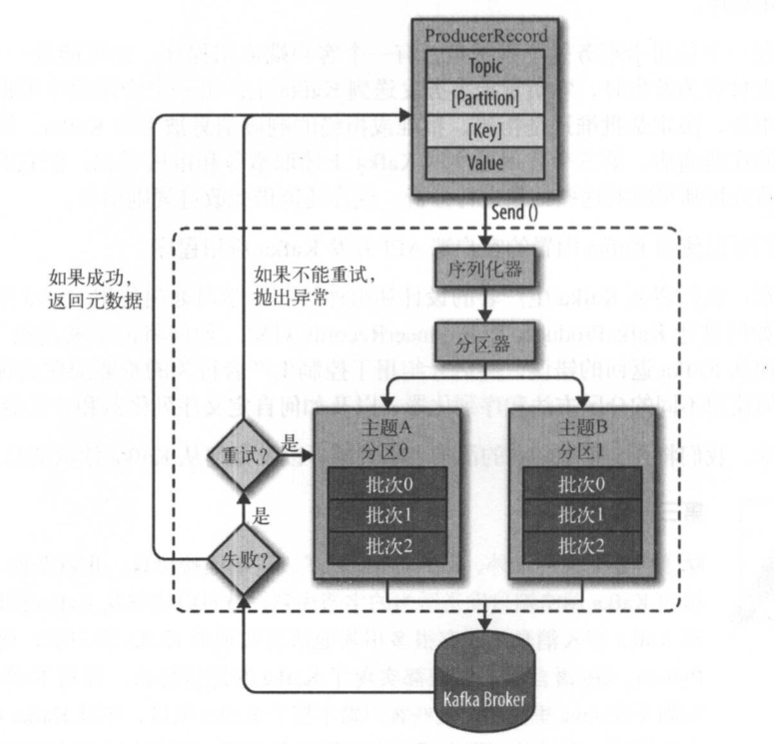
如何創建生產者
屬性設置
在創建生產者對象的時候,要設置一些屬性,有三個屬性是必選的:
-
bootstrap.servers:指定Broker的地址清單,地址格式為host:port。清單里不需要包含所有的Broker地址,生產者會從給定的Broker里查找到其他Broker的信息;不過建議至少要提供兩個Broker的信息保證容錯。
-
key.serializer:指定鍵的序列化器。Broker希望接收到的消息的鍵和值都是位元組數組。這個屬性必須被設置為一個實現了org.apache.kafka.common.serialization.Serializer介面的類,生產者會使用這個類把鍵對象序列化成位元組數組。Kafka客戶端預設提供了ByteArraySerializer、StringSerializer和IntegerSerializer,因此一般不需要實現自定義的序列化器。需要註意的是,key.serializer屬性是必須設置的,即使只發送值內容。
-
value.serializer:指定值的序列化器。如果鍵和值都是字元串,可以使用與key.serializer一樣的序列化器,否則需要使用不同的序列化器。
項目依賴
以maven項目為例,要使用Kafka客戶端,需要引入kafka-clients依賴:
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>2.2.0</version>
</dependency>
樣例
一個簡單的創建Kafka生產者的代碼樣例如下:
Properties props = new Properties();
props.put("bootstrap.servers", "producer1:9092");
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
/*創建生產者*/
Producer<String, String> producer = new KafkaProducer<>(props);
for (int i = 0; i < 10; i++) {
ProducerRecord<String, String> record = new ProducerRecord<>(topicName, "k" + i, "v" + i);
/* 發送消息*/
producer.send(record);
}
/*關閉生產者*/
producer.close();
這個樣例中只配置了必須的這三個屬性,其他都使用了預設的配置。
發送消息Kafka
實例化生產者對象後,接下來就可以開始發送消息了。發送消息主要有三種方式:
- 發送並忘記(fire-and-forget):把消息發送給伺服器,但並不關心消息是否正常到達,也就是上面樣例中的方式。大多數情況下,消息會正常到達,這可以由Kafka的高可用性和自動重發機制來保證。不過有時候也會丟失消息。
- 同步發送:使用send()方法發送消息,它會返回一個Future對象,調用get()方法進行等待,我們就可以知道消息是否發送成功。
- 非同步發送:調用send()方法時,同時指定一個回調函數,伺服器在返迴響應時調用該函數。
發送並忘記
這是最簡單的消息發送方式,只發送不管發送結果,代碼樣例如下:
ProducerRecord<String, String> record = new ProducerRecord<>("Topic", "k", "v"); // 1
try {
producer.send(record); // 2
} catch (Exception e) {
e.printStackTrace(); // 3
}
這段代碼要註意幾點:
- 生產者的send()方法將ProducerRecord對象作為參數,樣例里用到的ProducerRecord構造函數需要目標主題的名字和要發送的鍵和值對象,它們都是字元串。鍵和值對象的類型都必須與序列化器和生產者對象相匹配。
- 使用生產者的send()方法發送ProducerRecord對象。消息會先被放進緩衝區,然後使用單獨的線程發送到伺服器端。send()方法會返回一個包含RecordMetadata的Future對象,不過此處不關註返回了什麼。
- 發送消息時,生產者可能會出現一些執行異常,序列化消息失敗異常、緩衝區超出異常、超時異常,或者發送線程被中斷異常。
同步發送
在上一種發送方式中已經解釋過同步發送和只發送的區別,以下是最簡單的同步發送方式的代碼樣例,對比可以看到區別:
ProducerRecord<String, String> record = new ProducerRecord<>("Topic", "k", "v");
try {
producer.send(record).get;
} catch (Exception e) {
e.printStackTrace();
}
可以看到,二者的區別就在於是否接收發送結果。同步發送會接收send()方法的返回值,即一個Future對象,通過調用Future對象的get()方法來等待Kafka響應。如果伺服器返回錯誤,則get()方法就會拋出異常。如果沒有發生錯誤,我們會得到一個RecordMetadata對象,可以用它來獲取消息的偏移量。
非同步發送消息
對於吞吐量要求比較高的應用來說,又要同時保證服務的可靠性,發送並忘記方式可靠性較低,但同步發送方式又會降低吞吐量,這就需要非同步發送消息的方式了。大多數時候,生產者並不需要等待響應,只需要在遇到消息發送失敗時,拋出異常、記錄錯誤日誌,或者把消息寫入“錯誤日誌”文件便於以後分析。代碼樣例如下:
ProducerRecord<String, String> record = new ProducerRecord<>("Topic", "k", "v");
// 非同步發送消息,並監聽回調
producer.send(record, new Callback() { // 1
@Override
public void onCompletion(RecordMetadata metadata, Exception exception) { // 2
if (exception != null) {
// 進行異常處理
} else {
System.out.printf("topic=%s, partition=%d, offset=%s \n", metadata.topic(), metadata.partition(), metadata.offset());
}
}
});
- 從上面代碼可以看到,為了使用回調,只需要實現一個org.apache.kafka.clients.producer.Callback介面即可,這個介面只有一個onComplete方法。
- 如果Kafka返回錯誤,onComplete方法會拋出一個非空異常。在調用send()方法的時候會傳入這個callback對象,根據發送的結果決定調用異常處理方法還是發送結果處理方法。
生產者配置
在創建生產者的時候,介紹了三個必須的屬性,本節再一一介紹下其他的生產者屬性:
acks
acks 參數指定了必須要有多少個分區副本收到消息,生產者才會認為消息寫入是成功的:
- acks=0 : 消息發送出去就認為已經成功了,不會等待任何來自伺服器的響應;
- acks=1 : 只要集群的首領節點收到消息,生產者就會收到一個來自伺服器成功響應;
- acks=all :只有當所有參與複製的節點全部收到消息時,生產者才會收到一個來自伺服器的成功響應。
buffer.memory
該參數用來設置生產者記憶體緩衝區的大小生產者用它緩衝要發送到伺服器的消息。如果程式發送消息的速度超過了發送到伺服器的速度,會導致生產者緩衝區空間不足,這時候調用send()方法要麼被阻塞,要麼拋出異常。
compression.type
預設情況下,發送的消息不會被壓縮。它指定了消息被髮送給broker之前使用哪一種壓縮演算法進行壓縮,可選值有 snappy(占用CPU少,關註性能和網路帶寬時選用),gzip(占用CPU多,更高壓縮比,網路帶寬有限時選用),lz4。
retries
指定了生產者放消息發生錯誤後,消息重發的次數。如果達到設定值,生產者就會放棄重試並返回錯誤。
batch.size
當有多個消息需要被髮送到同一個分區時,生產者會把它們放在同一個批次里。該參數指定了一個批次可以使用的記憶體大小,按照位元組數計算。
linger.ms
該參數制定了生產者在發送批次之前等待更多消息加入批次的時間。KafkaProducer會在批次填滿或linger.ms達到上限時把批次發送出去。
client.id
客戶端 id,伺服器用來識別消息的來源。
max.in.flight.requests.per.connection
指定了生產者在收到伺服器響應之前可以發送多少個消息。它的值越高,就會占用越多的記憶體,不過也會提升吞吐量,把它設置為 1 可以保證消息是按照發送的順序寫入伺服器,即使發生了重試。
timeout.ms、request.timeout.ms和metadata.fetch.timeout.ms
- timeout.ms 指定了 borker 等待同步副本返回消息的確認時間;
- request.timeout.ms 指定了生產者在發送數據時等待伺服器返迴響應的時間;
- metadata.fetch.timeout.ms 指定了生產者在獲取元數據(比如分區首領是誰)時等待伺服器返迴響應的時間。
max.block.ms
該參數指定了在調用send()方法或使用partitionsFor()方法獲取元數據時生產者的阻塞時間。當生產者的發送緩衝區已滿,或者沒有可用的元數據時,這些方法會阻塞。在阻塞時間達到 max.block.ms 時,生產者會拋出超時異常。
max.request.size
該參數用於控制生產者發送的請求大小。它可以指發送的單個消息的最大值,也可以指單個請求里所有消息總的大小。例如,假設這個值為 1000K ,那麼可以發送的單個最大消息為 1000K ,或者生產者可以在單個請求里發送一個批次,該批次包含了 1000 個消息,每個消息大小為 1K。
receive.buffer.bytes和send.buffer.byte
這兩個參數分別指定 TCP socket 接收和發送數據包緩衝區的大小,-1 代表使用操作系統的預設值。
分區
分區器
上面在說明生產者發送消息方式的時候有如下一行代碼:
ProducerRecord<String, String> record = new ProducerRecord<>("Topic", "k", "v");
這裡指定了Kafka消息的目標主題、鍵和值。ProducerRecord對象包含了主題、鍵和值。鍵的作用是:
- 作為消息的附加信息;
- 用來決定消息被寫到主題的哪個分區,擁有相同鍵的消息將被寫到同一個分區。
鍵可以設置為預設的null,是不是null的區別在於:
- 如果鍵為null,那麼分區器使用輪詢演算法將消息均衡地分佈到各個分區上;
- 如果鍵不為null,那麼 分區器 會使用內置的散列演算法對鍵進行散列,然後分佈到各個分區上。
要註意的是,只有在不改變分區主題分區數量的情況下,鍵與分區之間的映射才能保持不變。
順序保證
Kafka可以保證同一個分區里的消息是有序的。考慮一種情況,如果retries為非零整數,同時max.in.flight.requests.per.connection為比1大的數如果某些場景要求消息是有序的,也即生產者在收到伺服器響應之前可以發送多個消息,且失敗會重試。那麼如果第一個批次消息寫入失敗,而第二個成功,Broker會重試寫入第一個批次,如果此時第一個批次寫入成功,那麼兩個批次的順序就反過來了。也即,要保證消息是有序的,消息是否寫入成功也是很關鍵的。那麼如何做呢?在對消息的順序要嚴格要求的情況下,可以將retries設置為大於0,max.in.flight.requests.per.connection設為1,這樣在生產者嘗試發送第一批消息時,就不會有其他的消息發送給Broker。當然這回嚴重影響生產者的吞吐量。
關註我的公眾號,獲取更多關於面試、技術的文章及福利資源。



