
該文為《 MySQL 實戰 45 講》的學習筆記,感謝查看,如有錯誤,歡迎指正 一、查詢和更新上的區別 這兩類索引在查詢能力上是沒差別的,主要考慮的是對更新性能的影響。建議儘量選擇普通索引。 1.1 MySQL 的查詢操作 普通索引 查找到第一個滿足條件的記錄後,繼續向後遍歷,直到第一個不滿足條件的 ...
該文為《 MySQL 實戰 45 講》的學習筆記,感謝查看,如有錯誤,歡迎指正
一、查詢和更新上的區別
這兩類索引在查詢能力上是沒差別的,主要考慮的是對更新性能的影響。建議儘量選擇普通索引。
1.1 MySQL 的查詢操作
- 普通索引
查找到第一個滿足條件的記錄後,繼續向後遍歷,直到第一個不滿足條件的記錄。 - 唯一索引
由於索引定義了唯一性,查找到第一個滿足條件的記錄後,直接停止繼續檢索。
普通索引會多檢索一次,幾乎沒有影響。因為 InnoDB 的數據是按照數據頁為單位進行讀寫的,需要讀取數據時,並不是直接從磁碟讀取記錄,而是先把數據頁讀到記憶體,再去數據頁中檢索。
一個數據頁預設 16 KB,對於整型欄位,一個數據頁可以放近千個 key,除非要讀取的數據在數據頁的最後一條記錄,就需要再讀一個數據頁,這種情況很少,對CPU的消耗基本可以忽略了。
因此說,在查詢數據方面,普通索引和唯一索引沒差別。
1.2 MySQL 的更新操作
更新操作並不是直接對磁碟中的數據進行更新,是先把數據頁從磁碟讀入記憶體,再更新數據頁。
- 普通索引
將數據頁從磁碟讀入記憶體,更新數據頁。 - 唯一索引
將數據頁從磁碟讀入記憶體,判斷是否唯一,再更新數據頁。
由於 MySQL 中有個 change buffer 的機制,會導致普通索引和唯一索引在更新上有一定的區別。
change buffer的作用是為了降低IO 操作,避免系統負載過高。change buffer將數據寫入數據頁的過程,叫做merge。
如果需要更新的數據頁在記憶體中時,會直接更新數據頁;如果數據不在記憶體中,會先將更新操作記入change buffer,當下一次讀取數據頁時,順帶merge到數據頁中,change buffer也有定期merge策略。資料庫正常關閉的過程中,也會觸發merge。
對於唯一索引,更新前需要判斷數據是否唯一(不能和表中數據重覆),如果數據頁在記憶體中,就可以直接判斷並且更新,如果不在記憶體中,就需要去磁碟中讀出來,判斷一下是否唯一,是的話就更新。change buffer是用不到的。即使數據頁不在記憶體中,還是要讀出來。
change buffer 用的是 buffer pool 里的記憶體,因此不能無限增大。change buffer 的大小,可以通過參數 innodb_change_buffer_max_size 來動態設置。這個參數設置為 50 的時候,表示 change buffer 的大小最多只能占用 buffer pool 的 50%。
結論:唯一索引用不了change buffer,只有普通索引可以用。
二、change buffer 和 redo log的區別
2.1 change buffer 的適用場景
change buffer 的作用是降低更新操作的頻率,緩存更新操作。這樣會有一個缺點,就是更新不及時,對於讀操作比較頻繁的表,不建議使用 change buffer。
因為更新操作剛記錄進change buffer中,就讀取了該表,數據頁被讀到了記憶體中,數據馬上就merge到數據頁中了。這樣不僅不會降低性能消耗,反而會增加維護change buffer的成本。
適用於寫多讀少的表。
2.2 change buffer 和 redo log 區別
我們舉一個例子用來理解 redo log 和 change buffer。我們執行以下 SQL 語句:
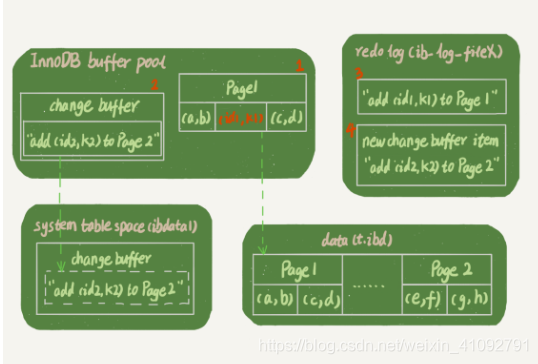
mysql> insert into t(id,k) values(id1,k1),(id2,k2);假設,(id1,k1) 在數據頁 Page 1 中,(id2,k2) 在數據頁 Page 2 中。並且 Page 1 在記憶體中,Page 2 不在記憶體中。
執行過程如下:
- 直接向 Page 1 中寫入
(id1,k1); - 在
change buffer中記下"向 Page 2 中寫入(id2,k2)"這條信息; - 將以上兩個動作記入redo log。
做完上面這些,事務就可以完成了。執行這條更新語句的成本很低,就是寫了兩處記憶體,然後寫了一處磁碟(兩次操作合在一起寫了一次磁碟),而且還是順序寫的。
這條更新語句,涉及了四個部分:記憶體、redo log(ib_log_fileX)、 數據表空間(t.ibd)、系統表空間(ibdata1)。
如果要讀數據的話,過程是怎樣的?
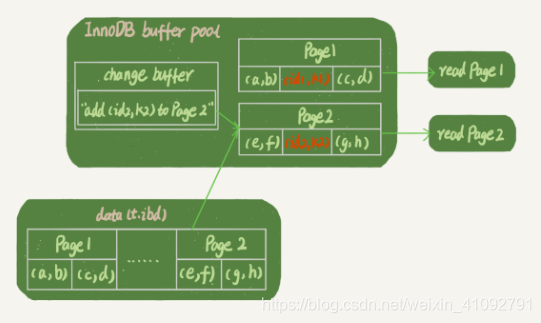
mysql> select * from t where k in (k1, k2);假設讀操作在更新後不久,此時記憶體中還有 Page 1,沒有 Page 2,那麼讀操作就和 redo log 以及 ibdata1 無關了。
- 從記憶體中獲取到 Page 1 上的最新數據
(id1,k1); - 將數據頁 Page 2 讀入記憶體,執行
merge操作,此時記憶體中的 Page 2 也有最新數據(id2,k2);
需要註意的是:
- redo log中的數據,可能還沒有 flush 到磁碟,磁碟中的 Page 1 和 Page 2 中並沒有最新數據,但我們依然可以拿到最新數據(記憶體中的 Page 1 就是最新的,Page 2 雖然不是最新的,但是從磁碟讀到記憶體中後,執行了
merge操作,記憶體中的 Page 2 就是最新的了。) - 如果此時 MySQL 異常宕機了,比如伺服器異常掉電,change buffer 中的數據會不會丟?
change buffer中的數據分為兩部分,一部分是已經merge到ibdata1中的數據,這部分數據已經持久化,不會丟失。另一部分數據,還在change buffer中,沒有merge到ibdata1,分 3 種情況:
(1)change buffer 寫入數據到記憶體,redo log 也已經寫入(ib-log-filex),但是未commit,binlog中也沒有fsync到磁碟,這部分數據會丟失;
(2)change buffer 寫入數據到記憶體,redo log 也已經寫入(ib-log-filex),但是未commit,binlog 已寫入到磁碟,這部分不會多丟失,異常重啟後會先從 binlog 恢復 redo log,再從 redo log 恢復 change buffer;
(3)change buffer 寫入數據到記憶體,redo log 和 binlog 都已經fsync,直接從redo log 恢復,不會丟失。
redo log 主要節省的是隨機寫磁碟的 IO 消耗(轉成順序寫),而 change buffer 主要節省的則是隨機讀磁碟的 IO 消耗
感謝閱讀,有興趣的小伙伴可以關註我的微信公眾號DevOps探索之旅,大家一起學習進步



