
python記錄點 文件編碼 Unicode使用最少2個位元組(1個位元組=1BYTE=8bit=一個長度為8的二進位數) 來表示字母和符號等,有時候是4個位元組。 UTF-8是對Unicode編碼的壓縮和優化,最大的特點是它採用了變長的編碼方式,他不再是最少使用2個位元組,而是將所有的字元進行分類。asc ...
python記錄點
文件編碼
Unicode使用最少2個位元組(1個位元組=1BYTE=8bit=一個長度為8的二進位數) 來表示字母和符號等,有時候是4個位元組。
UTF-8是對Unicode編碼的壓縮和優化,最大的特點是它採用了變長的編碼方式,他不再是最少使用2個位元組,而是將所有的字元進行分類。ascii碼中的內容用1個位元組保存、歐洲的字元用2個位元組保存,東亞的字元用3個位元組保存…
-
不同編碼之間的關係
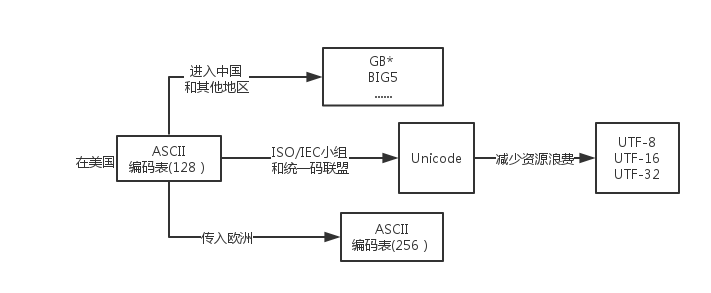
python2中文件的預設編碼為ASCII,在文件中含有中文的時候就會報錯,這時,我們需要是設置一下文件的預設編碼,如下:
#!/usr/bin/env python
# -*- coding: UTF-8 -*- # 指定python文件編碼方式
在python3中,文件的預設編碼為UTF-8,已經不存在這個問題。
迴圈
for i in range(1, 10, 2): # 1-10 2是步長 i是變數 #[1, 3, 5, 7, 9] break #退出迴圈 continus #跳過當次迴圈 exit() #退出程式
# __author: Administrator # date: 2016/8/22 name = 'weijie' age = 32 job = 'developer ' salary = 5000.00if salary.isdigit(): #長的像不像數字,比如200d , '200' salary = int(salary) # else: # #print() # exit("must input digit") #退出程式 msg = ''' --------- info of %s -------- Name: %s Age : %d Job : %s Salary: %f You will be retired in %s years -------- end ---------- ''' % (name, name, age, job, salary, 65-age) print(msg)


