
ZooKeeper技術的極少以及ZooKeeper集群的搭建 ...
本篇由鄙人學習ZooKeeper親自整理的一些資料
包括:ZooKeeper的介紹,我們要學習ZooKeeper的話,首先就要知道他是幹嘛的對吧.
其次教大家如何去安裝這個精巧的智慧品!
相信你能研究到ZooKeeper一定也會對Linux有一定瞭解了吧!
下麵的介紹內容全部經過精心整理,內容會很枯燥,但是一定要堅持看一遍,大概心中有個印象,要接下來的學習裡面,根本不會理解是做什麼的!!理論的東西也是非常重要的,因為學習是個沉澱的過程...
start...
ZooKeeper原理篇
一、 ZooKeeper 簡介
顧名思義 zookeeper 就是動物園管理員,他是用來管 hadoop(大象)、Hive(蜜蜂)、pig(小
豬)的管理員, Apache Hbase 和 Apache Solr 的分散式集群都用到了 zookeeper;Zookeeper:
是一個分散式的、開源的程式協調服務,是 hadoop 項目下的一個子項目。它提供的主要功能包括:配置管理、名字服務、分散式鎖、集群管理
二、ZooKeeper的作用
1.1配置管理
在我們的應用中除了代碼外,還有一些就是各種配置。比如資料庫連接等。一般我們都
是使用配置文件的方式,在代碼中引入這些配置文件。當我們只有一種配置,只有一臺服務
器,並且不經常修改的時候,使用配置文件是一個很好的做法,但是如果我們配置非常多,
有很多伺服器都需要這個配置,這時使用配置文件就不是個好主意了。這個時候往往需要尋
找一種集中管理配置的方法,我們在這個集中的地方修改了配置,所有對這個配置感興趣的
都可以獲得變更。Zookeeper 就是這種服務,它使用 Zab 這種一致性協議來提供一致性。現
在有很多開源項目使用 Zookeeper 來維護配置,比如在 HBase 中,客戶端就是連接一個
Zookeeper,獲得必要的 HBase 集群的配置信息,然後才可以進一步操作。還有在開源的消
息隊列 Kafka 中,也使用 Zookeeper來維護 broker 的信息。在 Alibaba 開源的 SOA 框架 Dubbo中也廣泛的使用 Zookeeper 管理一些配置來實現服務治理
1.2名字服務
名字服務這個就很好理解了。比如為了通過網路訪問一個系統,我們得知道對方的 IP
地址,但是 IP 地址對人非常不友好,這個時候我們就需要使用功能變數名稱來訪問。但是電腦是
不能是功能變數名稱的。怎麼辦呢?如果我們每台機器里都備有一份功能變數名稱到 IP 地址的映射,這個倒
是能解決一部分問題,但是如果功能變數名稱對應的 IP 發生變化了又該怎麼辦呢?於是我們有了
DNS 這個東西。我們只需要訪問一個大家熟知的(known)的點,它就會告訴你這個功能變數名稱對應
的 IP 是什麼。在我們的應用中也會存在很多這類問題,特別是在我們的服務特別多的時候,
如果我們在本地保存服務的地址的時候將非常不方便,但是如果我們只需要訪問一個大家都
熟知的訪問點,這裡提供統一的入口,那麼維護起來將方便得多了。
1.3分散式鎖
其實在第一篇文章中已經介紹了 Zookeeper 是一個分散式協調服務。這樣我們就可以利
用 Zookeeper 來協調多個分散式進程之間的活動。比如在一個分散式環境中,為了提高可靠
性,我們的集群的每台伺服器上都部署著同樣的服務。但是,一件事情如果集群中的每個服
務器都進行的話,那相互之間就要協調,編程起來將非常複雜。而如果我們只讓一個服務進
行操作,那又存在單點。通常還有一種做法就是使用分散式鎖,在某個時刻只讓一個服務去
幹活,當這台服務出問題的時候鎖釋放,立即 fail over 到另外的服務。這在很多分散式系統
中都是這麼做,這種設計有一個更好聽的名字叫 Leader Election(leader 選舉)。比如 HBase
的 Master 就是採用這種機制。但要註意的是分散式鎖跟同一個進程的鎖還是有區別的,所
以使用的時候要比同一個進程里的鎖更謹慎的使用。
1.4集群管理
在分散式的集群中,經常會由於各種原因,比如硬體故障,軟體故障,網路問題,有些
節點會進進出出。有新的節點加入進來,也有老的節點退出集群。這個時候,集群中其他機
器需要感知到這種變化,然後根據這種變化做出對應的決策。比如我們是一個分散式存儲系
統,有一個中央控制節點負責存儲的分配,當有新的存儲進來的時候我們要根據現在集群目
前的狀態來分配存儲節點。這個時候我們就需要動態感知到集群目前的狀態。還有,比如一
個分散式的 SOA 架構中,服務是一個集群提供的,當消費者訪問某個服務時,就需要採用
某種機制發現現在有哪些節點可以提供該服務(這也稱之為服務發現,比如 Alibaba 開源的
SOA 框架 Dubbo 就採用了 Zookeeper 作為服務發現的底層機制)。還有開源的 Kafka 隊列就
採用了 Zookeeper 作為 Cosnumer 的上下線管理。
三、ZooKeeper存儲結構
下麵用圖文的形式在表示下:
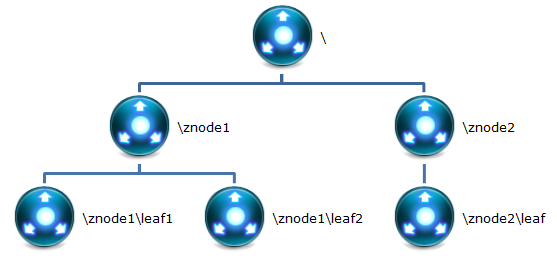
1 Znode
在 Zookeeper 中,znode 是一個跟 Unix 文件系統路徑相似的節點,可以往這個節點存儲
或獲取數據。
Zookeeper 底層是一套數據結構。這個存儲結構是一個樹形結構,其上的每一個節點,
我們稱之為“znode”
zookeeper 中的數據是按照“樹”結構進行存儲的。而且 znode 節點還分為 4 中不同的類
型。
每一個 znode 預設能夠存儲 1MB 的數據(對於記錄狀態性質的數據來說,夠了)
可以使用 zkCli 命令,登錄到 zookeeper 上,並通過 ls、create、delete、get、set 等命令
操作這些 znode 節點
2 Znode節點類型
(1)PERSISTENT 持久化節點:所謂持久化節點,是指在節點創建後,就會一直存在,訴我誒的保存到了Hard Disk硬碟當中,直到有刪除的操作來主動清除這個節點。苟澤不會因為創建該節點的客戶端會話失效而消失
(2)PERSISTENT_SEQUENTIAL 持久化順序節點:這類節點的基本特性和上面的節PERSISTENT類型一致。額外的特性是,在ZK中,每個節點會為他的第一季子節點維護一份時序,會記錄每個子節點的創建的先後順序。基於這個特性,在創建子節點的時候,可以設置這個屬性,那麼在創建節點的過程中,ZK會自動給節點名加上一個數字的尾碼,作為新的節點名。這個數字尾碼的範圍是整數型的最大值,樹的每個分支的尾碼都會重新開始計算,也就是從0開始,。在創建節點的時候只需要傳入節點“/leaf_",這樣之後,zookeeper自動會給leaf_後面補充數字
(3)EPHEMERAL臨時節點:和持久節點不同的是,臨時節點的聲明周期和客戶端會話綁定。也就是說,如果客戶端的會話失效,退出本次的會話,那麼這個節點就會被清除掉。註意:這裡提到的是會話失效,而非連接斷開。另外,是不能在臨時節點下麵創建子節點的
這裡還需要註意的一件事,就是當你客戶端會話失效後,所產生的的節點也不是一下子就是小了,也需要過一段時間,大概是10秒鐘以內,可以嘗試,本機操作生成節點,在伺服器端用命令來查看當前的節點數目,會發現,客戶端已經stop,但是產生的節點還在。
(4)EPHEMERAL_SEQUENTIAL 臨時自動編號節點:此節點是屬於臨時節點,不過帶有順序,客戶端會話結束節點就消失
ZooKeeper環境搭建篇
考慮到大家初學者,肯定不會去裝好幾台虛擬機,所以我們就以單台虛擬機作為測試環境簡稱:偽集群
看不懂?沒關係,後面慢慢來跟著敲
首先準備環境:
Linux
--JDK
--ZooKeeper(ZooKeeper自己百度去下載一下就好了,我這裡用的為3.4.6版本)
1 單機環境安裝ZooKeeper
首選解壓的你ZooKeeper並複製到一個目錄上(並無大礙,解壓即可)
[root@localhost temp]# tar -zxf zookeeper-3.4.6.tar.gz
[root@localhost temp]# cp zookeeper-3.4.6 /usr/local/zookeeper -r
1.1ZooKeeper的目錄結構
bin:防止運行腳本和工具腳本,如果是Linux環境還會有zookeeper的運行日誌zookeeper.out
conf:zookeeper預設讀取配置的目錄,裡面會有預設的配置文件
contrib:zookeeper的擴展功能
dist-maven:zookeeper的mavnen打包目錄
docs:zookeeper相關的文檔
lib:zookeeper核心jar
recipes:zookeeper分散式相關的jar包
src:zookeeper源碼
1.2配置ZooKeeper
註意:*大概掃一眼整個步驟字後再來做!!以免你懂得*
Zookeeper在啟動的時候預設去他的conf目錄下查找一個名稱為zoo.crf的配置文件,
在zookeeper應用目錄中有子目錄conf,其中配置文件模板:zoo_sample.cfg
我們可以cp zoo_sample.cfg zoo.cfg 這樣就複製了一份所需要的zoo.cfg,
因為zookeeper啟動需要用到配置文件為conf/zoo.cfg,
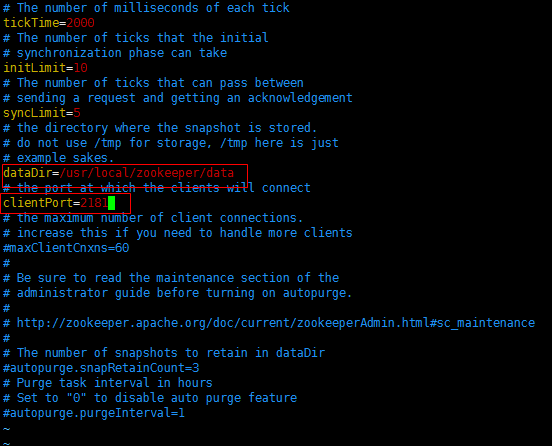
接下來修改文件zoo.cfg 設置數據緩存路徑dataDir
數據緩存目錄我們可以隨意創建,我這裡邊就創建到了zookeeper的子目錄中data
clientPort為zookeeper的監聽埠,可以隨意改動所需要且沒有被占用的埠,一般預設即可
1.3 啟動ZooKeeper
沒錯就是這麼簡單,你現在已經可以啟動ZooKeeper啦!
啟動文件在Zookeeper的bin目錄下麵
預設載入配置文件(zoo.cfg): ./zkServer.sh start:預設回去conf目錄下載入zoo.cfg配置文件
指定載入配置文件: ./zkServer.sh start 配置文件的路徑,這樣就不會使用預設的conf/zoo.cfg.
註意:我們下邊要安裝集群,那麼首先要關閉這個ZooKeeper,否則占用埠!
./zkServer.sh stop關閉即可
2 ZooKeeper集群環境搭建(偽集群)
前方高能:首先我們又要來瞭解下原理性的東西了!!
2.1 Zookeeper集群中的角色
共分為下麵的三大類
領導者、學習者、客戶端


2.2設計的目的
1.最終一致性:client不論連接到哪個Server,展示給它的都是同一個視圖,這是Zookeeper最重要的特性
2.可靠性:具有簡單、簡裝、良好的性能,如果消息m被髮送到一臺伺服器並接受,那麼它將被所有的伺服器接受
3.實時性:Zookeeper保證客戶端將在一個時間間隔範圍內獲得伺服器的更新信息,或者伺服器試失效的信息。但由於網路延時等原因,Zookeeper不能保證兩個客戶端能同時得到剛剛更新的數據,如果需要最新數據,應該i在讀取數據之前調用sync()介面
4.等待無關(wait-free):慢的或者失效的client不得干預快速的client的請求,使得每個client都能有效的等待
5.原子性:額更新只能成功或者失敗,沒有中間狀態
6.順序性:包括全局有序和偏序兩種:全局有序是指如果在一臺伺服器上消息a在消息b發佈前,則在所有Server上消息a都將在消息b前輩發佈:偏序是指如果一個消息b在消息a後被同一個發送者發佈,a必將排在b前面,
2.3集群安裝
我們本次安裝的集群是偽集群,也就是在一臺Linux上搭建,根真實的集群的原理都是一樣的,性能好的話,有三台伺服器,也可以在不同的伺服器上進行實驗!
使用3個Zookeeper應用搭建一個偽集群。應用部署的位置是:ip地址。伺服器監聽的埠分別為:
2181、2182、2183.投票選舉埠分別為1881/3881、1883/3883、1883/3883
2.3.1準備步驟
還是要提醒:先大略的看完所有步驟,然後在繼續你的操作!!
首先創建了一個文件夾,用於管理存放所有的偽集群 mkdir zookeeperCluster 然後解壓一個Zookeeper並複製到這個目錄 例如: tar -zxvf zookeeper-3.4-6 - C /usr/local/soft/zookeeperCluster 然後我們給它改一個名字 mv zookeeper-3.4.6 zookeeper01 也就是第一個Zookeeper2.3.1提供數據緩存目錄
我們在第一個Zookeeper01裡面創建這個 mkdir data
2.3.2修改配置文件zoo.cfg
首先到Zookeeper01的conf目錄 然後把zoo_sample.cfg改名為zoo.cfg mv zoo_sample.cfg zoo.cfg 然後進去編輯 vi zoo.cfg
*
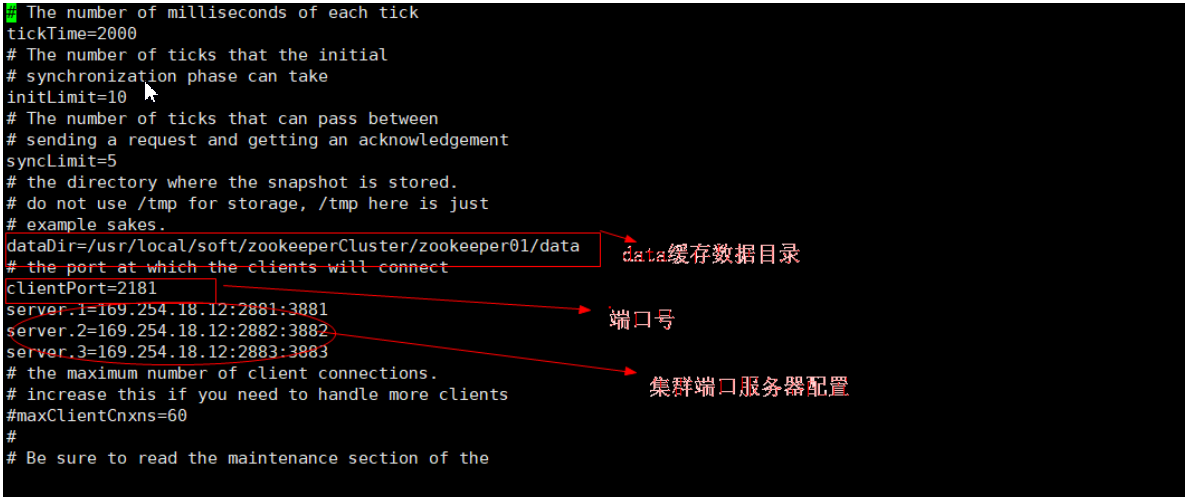
需要註意:當我們在修改配置文件 zoo.cfg 設置訪問、投票、選舉埠的時候 要如下這樣設置,相信你認真看完前邊的圖文會很清晰的知道思路的!
server.1=Zookeeper所在的ip地址:2881:3881
server.2=Zookeeper所在的ip地址:2882:3882
server.3=Zookeeper所在的ip地址:2883:3883
*
2.3.3 提供Zookeeper的唯一標識
在Zookeeper集群中,每個節點需要一個唯一標識。這個唯一標識要求是自然數,且唯一標識保存位置是:$dataDir/myid 。其中dataDir為配置文件zoo.cfg中配置參數的data數據緩存目錄
接下來,我們在data數據緩存目錄創建文件:myid touch myid 然後編輯這個文件添加一個標識數字比如:vi myid 比如這是在第一個Zookeeper裡面就那就添加一個 1。
簡化方式寫法:echo[唯一標識]>>myid . echo命令為回聲命令,系統會講命令發送的數據返回。“>>"為定位,代表系統回聲數據指定發送到什麼位置。此命令代表系統回聲數據發送到myid文件裡面。如果沒有這個文件則創建文件
例如:echo 1 >>myid
這樣第一個Zookeeper集群的第一個Zookeeper節點就已經配置完畢了,還剩其餘兩個,
那麼我們就可以直接複製Zookeeper01然後分別複製為Zookeeper02和Zookeeper03
2.3.4最終配置
之後我們分別進入Zookeeper01和Zookeeper02裡面的conf/zoo.cfg文件,然後進行編輯,我們只需要把clientPort埠號改變還有dataDir數據緩存地址改變為本集群節點即可,最後一步,在給這兩個集群分別創建一個Zookeeper的唯一標識,按照上面的方法,分別為 2 、3(這個其實是可以隨意的,只要別重覆即可)
2.3.5啟動ZooKeeper集群應用
分別進入zookeeper01、zookeeper02、zookeeper03的bin目錄,然後輸入
./zkServer.sh start啟動他們
ZooKeeper集群搭建後,至少需要啟動兩個集群節點應用才能提供服務。因需要選出主服務節點。啟動所有的ZooKeeper節點後,可以使用命令在bin目錄下,
./zkServer.sh status 來查看節點狀態
如下:
Mode:leader 主機
Model:follower -備用機
2.3.6 關閉ZooKeeper應用
還是在bin目錄下
./zkServer.sh stop
搭建完畢了,那麼你的ZooKeeper向你問候了嗎?


