
前言: 前面幾篇文章為大家介紹了DML以及DDL語句的使用方法,本篇文章將主要講述常用的查詢語法。其實MySQL官網給出了多個示例資料庫供大家實用查詢,下麵我們以最常用的員工示例資料庫為準,詳細介紹各自常用的查詢語法。 1.員工示例資料庫導入 官方文檔員工示例資料庫介紹及下載鏈接: "https:/ ...
前言:
前面幾篇文章為大家介紹了DML以及DDL語句的使用方法,本篇文章將主要講述常用的查詢語法。其實MySQL官網給出了多個示例資料庫供大家實用查詢,下麵我們以最常用的員工示例資料庫為準,詳細介紹各自常用的查詢語法。
1.員工示例資料庫導入
官方文檔員工示例資料庫介紹及下載鏈接:
https://dev.mysql.com/doc/employee/en/employees-installation.html
同樣的,為了方便大家,我這裡將員工庫的資料庫備份分享給大家,大家也可以下載我這份數據,然後再解壓導入進你們本地庫就可以了。
鏈接: https://pan.baidu.com/s/13s1OH-3DepN-rpejys76Ww
密碼: 2xqx
下載解壓後,直接導入即可,如鏈接失效可後臺聯繫我。
如果你導入完成,就可以看到下麵這6張表了,這就是我們接下來練習查詢語法要用的表哦。

為了讓大家對示例資料庫更瞭解,這裡給出此資料庫各表之間的關係圖:
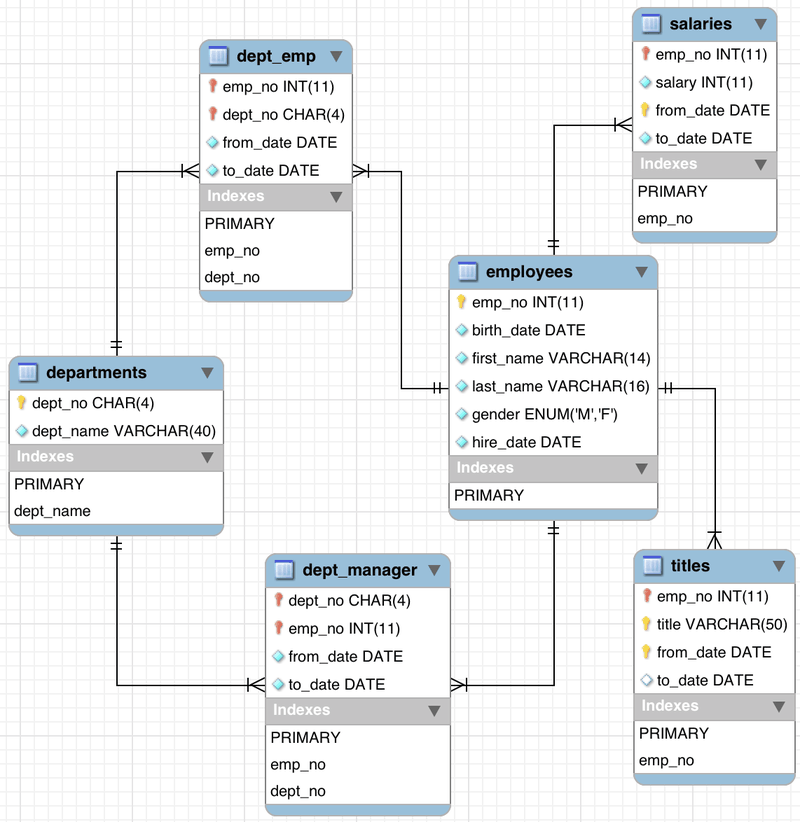
簡單介紹下這6張表:
departments:部門表,記錄的是9個部門的部門編號和部門名稱。dept_emp:部門員工表,記錄各部門員工數據,員工id和部門id,起始時間和結束時間(註:9999-01-01的意思就是仍在該部門就職)。dept_manager:部門經理表,同第二張表結構差不多,記錄每個部門的每個經理的任職時期。employees:員工信息表,記錄員工信息,員工編號emp_no是唯一鍵值。salaries:薪資表,記錄每個員工每段時期的薪資。titles:職稱表,記錄每個員工每段時期的職位名稱。
2.模糊查詢
#查找名字以L開頭的員工信息
SELECT * FROM employees WHERE first_name LIKE 'L%';3.排序
#按部門編號排序
mysql> SELECT * FROM departments ORDER BY dept_no;
+---------+--------------------+
| dept_no | dept_name |
+---------+--------------------+
| d001 | Marketing |
| d002 | Finance |
| d003 | Human Resources |
| d004 | Production |
| d005 | Development |
| d006 | Quality Management |
| d007 | Sales |
| d008 | Research |
| d009 | Customer Service |
+---------+--------------------+
9 rows in set (0.00 sec)
總結:
order by排序預設按asc升序來排列
也可指定desc降序排列4.限制多少行
#取前5行
mysql> SELECT * FROM employees LIMIT 5;
+--------+------------+------------+-----------+--------+------------+
| emp_no | birth_date | first_name | last_name | gender | hire_date |
+--------+------------+------------+-----------+--------+------------+
| 10001 | 1953-09-02 | Georgi | Facello | M | 1986-06-26 |
| 10002 | 1964-06-02 | Bezalel | Simmel | F | 1985-11-21 |
| 10003 | 1959-12-03 | Parto | Bamford | M | 1986-08-28 |
| 10004 | 1954-05-01 | Chirstian | Koblick | M | 1986-12-01 |
| 10005 | 1955-01-21 | Kyoichi | Maliniak | M | 1989-09-12 |
+--------+------------+------------+-----------+--------+------------+
5 rows in set (0.00 sec)
mysql> SELECT * FROM employees ORDER BY hire_date desc LIMIT 5;
+--------+------------+------------+-----------+--------+------------+
| emp_no | birth_date | first_name | last_name | gender | hire_date |
+--------+------------+------------+-----------+--------+------------+
| 463807 | 1964-06-12 | Bikash | Covnot | M | 2000-01-28 |
| 428377 | 1957-05-09 | Yucai | Gerlach | M | 2000-01-23 |
| 499553 | 1954-05-06 | Hideyuki | Delgrande | F | 2000-01-22 |
| 222965 | 1959-08-07 | Volkmar | Perko | F | 2000-01-13 |
| 47291 | 1960-09-09 | Ulf | Flexer | M | 2000-01-12 |
+--------+------------+------------+-----------+--------+------------+
5 rows in set (0.11 sec)
總結:
limit限定顯示前多少行,可與order by聯合使用5.聚合函數
#查找某員工薪水總和
SELECT SUM(salary) FROM salaries WHERE emp_no = 10001;
#統計歷史上各個部門所擁有的員工數量,並降序排序
mysql> SELECT dept_no, COUNT(*) AS emp_sum FROM dept_emp GROUP BY dept_no ORDER BY emp_sum DESC;
+---------+---------+
| dept_no | emp_sum |
+---------+---------+
| d005 | 85707 |
| d004 | 73485 |
| d007 | 52245 |
| d009 | 23580 |
| d008 | 21126 |
| d001 | 20211 |
| d006 | 20117 |
| d003 | 17786 |
| d002 | 17346 |
+---------+---------+
9 rows in set (0.07 sec)6.JOIN
#可以試下下麵3個語句執行結果的不同
SELECT *
FROM salaries INNER JOIN dept_emp
ON salaries.emp_no = dept_emp.emp_no
WHERE salaries.emp_no = 10010;
SELECT *
FROM salaries LEFT JOIN dept_emp
ON salaries.emp_no = dept_emp.emp_no
WHERE salaries.emp_no = 10010;
SELECT *
FROM salaries RIGHT JOIN dept_emp
ON salaries.emp_no = dept_emp.emp_no
WHERE salaries.emp_no = 10010;
總結:
a left join b a表全,用b表去匹配a表
LEFT JOIN 關鍵字會從左表 (a) 那裡返回所有的行,即使在右表 (b) 中沒有匹配的行,匹配不到的列用NULL代替
a right join b b表全,用a表去匹配b表
RIGHT JOIN 關鍵字會右表 (b) 那裡返回所有的行,即使在左表 (a) 中沒有匹配的行,匹配不到的列用NULL代替
inner join 與join 效果一樣
在表中存在至少一個匹配時,INNER JOIN 關鍵字返回行總結:
推薦大家在本地導入這個示例資料庫,其實這個資料庫是練習查詢語法的好素材。對於我們日常學習或工作中,用的最多的應該就是查詢語句了,個人以為寫查詢SQL沒有技巧,只有多加練習才能快速寫出能解決需求的SQL。


