初始編碼 ASCII最開始為7位,一共128字元。最後確定8位,一共256個字元,最左邊的為拓展位,為以後的開發做準備。 ASCII碼的最左邊的一位為0。 基本換算:8位(bit) = 1位元組(byte) 1024byte = 1 KB 1024KB = 1MB 1024MB = 1GB 1024G ...
初始編碼
ASCII最開始為7位,一共128字元。最後確定8位,一共256個字元,最左邊的為拓展位,為以後的開發做準備。
ASCII碼的最左邊的一位為0。
基本換算:8位(bit) = 1位元組(byte)
1024byte = 1 KB
1024KB = 1MB
1024MB = 1GB
1024GB = 1TB
電腦的傳輸還有存儲實際上都是以二進位的形式進行的。
Unicode:美國最初是使用ASCII編碼,後來為瞭解決全球化的文字問題,創建了萬國碼(Unicode)
開端:
一個中文最初給兩個位元組(16位)來表示,後來發現中文就將近十萬字,不夠,所以之後Unicode用4個位元組(32位)來表示一個中文。
一個英文給四個位元組(32位)來表示。
升級後:
UTF-8:
一個中文用3個位元組(24位)表示
一個英文用1個位元組(8位)表示
一個歐洲文字用2個位元組(16位)表示
國內使用編碼:
GBK:
一個中文用2個位元組(16位)表示
一個英文用1個位元組(8位)表示
(1)各個編碼之間的二進位是不能互相是別的,會產生亂碼
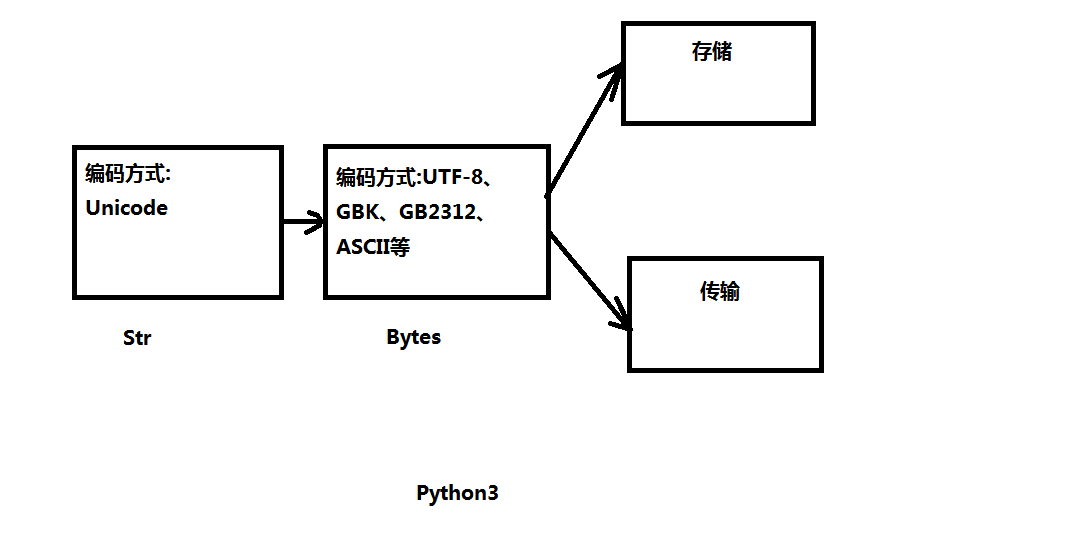
(2)Unicode 的字元要用4個位元組(32位)來表示,占用了太多記憶體。因此文件的儲存、傳輸不能是Unicode類型,只能是UTF-8、UTF-16、GBK、GB2312、ASCII等類型
UTF-8和GBK的轉變要藉助Unicode
(3)在Python3中str在記憶體中是用Unicode存儲的
而bytes類型是以(UTF-8、GB2312等編碼)
對於英文:
str的表現形式:
s = 'abc'
str的編碼方式:
以Unicode的01010101形式
bytes的表現形式:
b_s = b'abc'
bytes的編碼方式:
以UTF-8、GBK等的01010101形式
對於中文:
str的表現形式:
s = '中國'
str的編碼方式:
以Unicode的01010101形式
bytes的表現形式:
以UTF-8的b'\xe4\xb8\xad\xe5\x9b\xbd'形式
bytes的編碼方式:
以UTF-8、GBK等的01010101形式
編碼(將str->bytes):
中文:
s1= '中國' s2 = s1.encode('utf-8') print(s2) #b'\xe4\xb8\xad\xe5\x9b\xbd' s2 = s1.encode('gbk') print(s2) #b'\xd6\xd0\xb9\xfa'
英文:
s1 = 'abc' s2 = s1.encode('utf-8') print(s2) #b'abc' s2 = s1.encode('gbk') print(s2) #b'abc'
解碼(將bytes->str):
b = b'\xe4\xb8\xad\xe5\x9b\xbd' s = b.decode('utf-8') print(s) #中國
b = b'abc' s = b.decode('utf-8') print(s) #abc
其他:
1.Python2和Python3的區別:
Python2 Python3
<1>.print 可以加括弧,也可以不加括弧
print('abc') print('abc')
print 'abc'
<2>.xrange()生成器 range()
range()
<3>.raw_input() input()
2.
= 是賦值
is 是比較記憶體地址
== 比較值是否相等
id(內容)
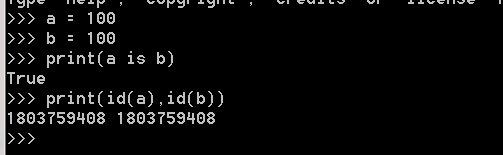
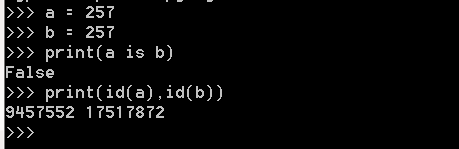
3.小數據池
在Python中數字和字元串存在著小數據池,它的作用是在一個數據範圍內節省記憶體空間,共用一個記憶體地址
list、dict、set、tuple沒有小數據池這一概念
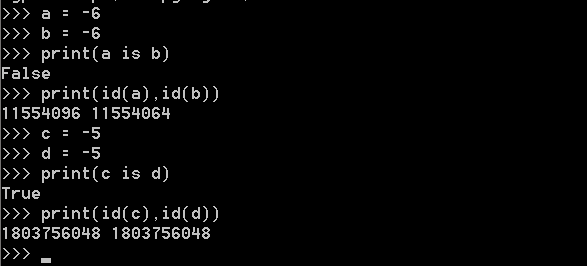
int:
只要數值在範圍(-5 - 256),它們都共用一個相同的記憶體地址
例1:
例2:
例3:
str:
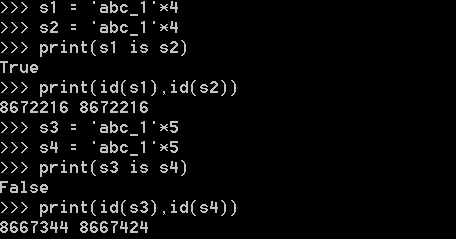
<1>.當字元串長度為0或1時預設使用小數據池,當長度大於1時且沒有含有特殊字元(包括加減乘除)時也將使用小數據池


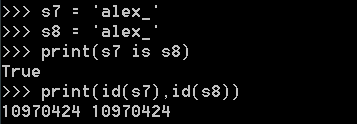
<2>.一個字元串長度小於等於20用的還是同一個記憶體地址,長度大於20以後用的是2個記憶體地址
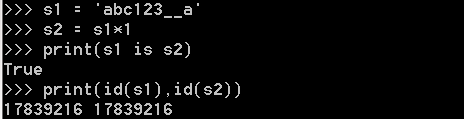
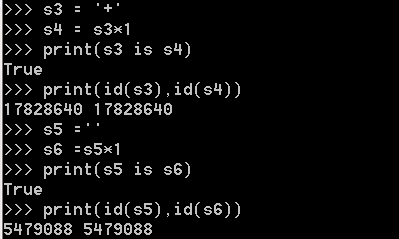
當乘數為1時:
僅含字元串、數字、下劃線,預設使用小數據池:
含其他字元,長度<=1時,預設使用小數據池
含其他字元,長度>1時,預設使用小數據池
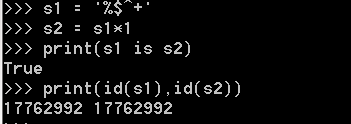
當乘數大於1時:
字元長度小於等於20將使用小數據池