1:如果同一臺伺服器上安裝有多個MongoDB實例,telegraf.conf 中關於 MongoDB 如何配置?配置數據在【INPUT PLUGINS的[[inputs.mongodb]]】部分。 單個實例配置 錯誤的多實例配置(例如兩個實例); 重啟服務,查看服務狀態,提示錯誤信息如下; 正確的 ...
1:如果同一臺伺服器上安裝有多個MongoDB實例,telegraf.conf 中關於 MongoDB 如何配置?配置數據在【INPUT PLUGINS的[[inputs.mongodb]]】部分。
單個實例配置
servers = ["mongodb://UID:[email protected]:27218"]
錯誤的多實例配置(例如兩個實例);
servers = ["mongodb://UID:[email protected]:27218"] servers = ["mongodb://UID:[email protected]:27213"]
重啟服務,查看服務狀態,提示錯誤信息如下;
Failed to start The plugin-driven server agent for reporting metrics into InfluxDB.

正確的配置應該為;
servers = ["mongodb://UID:[email protected]:27213","mongodb://UID:[email protected]:27218"]
2.配置Grafana 告警規則後,發現只是告警一次,後面恢復後再報警一次。即異常持續期間沒有一直告警。
解決辦法,這個設置其實在【Alterting】--》【Notification channels】-->【Send reminders】

例如以下的設置可以理解為,每5分鐘觸發一下告警信息。

3.告警檢查顯示沒有數據。

這個時候有兩種原因
(1)收集監控項的代理程式有問題 ;
(2)或者是代理程式沒問題,是彙報數據不及時的問題。
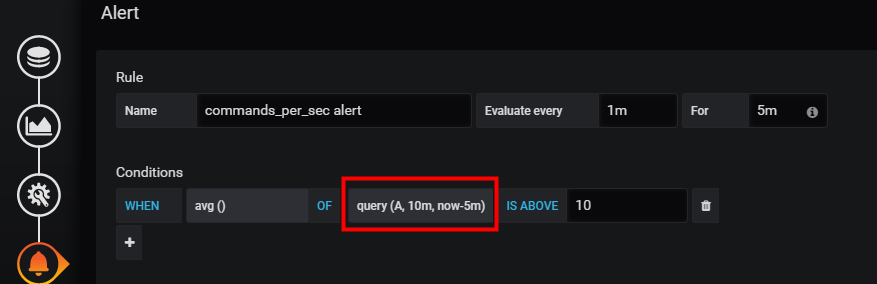
針對第二問題,我們可以調整代理程式執行頻率;如果實時性要求不是很高,還可以調整告警規則檢查數據的時間範圍。
例如,我們可以從檢查 過去5分鐘到過去1分鐘內的數據,調整為過去10分鐘到過去5分鐘內的數據。對應的設置如下:
調整前;

調整後
4.隨著需要監控的子項的增多,收集時間必然增多,需要調整運行周期。
否則,報錯信息如下;
telegraf[2908]: 2019-03-01T02:40:46Z E! Error in plugin [inputs.mysql]: took longer to collect than collection interval (10s)
解決方案:調整 telegraf.conf 文件中 [agent] 部分的interval參數。
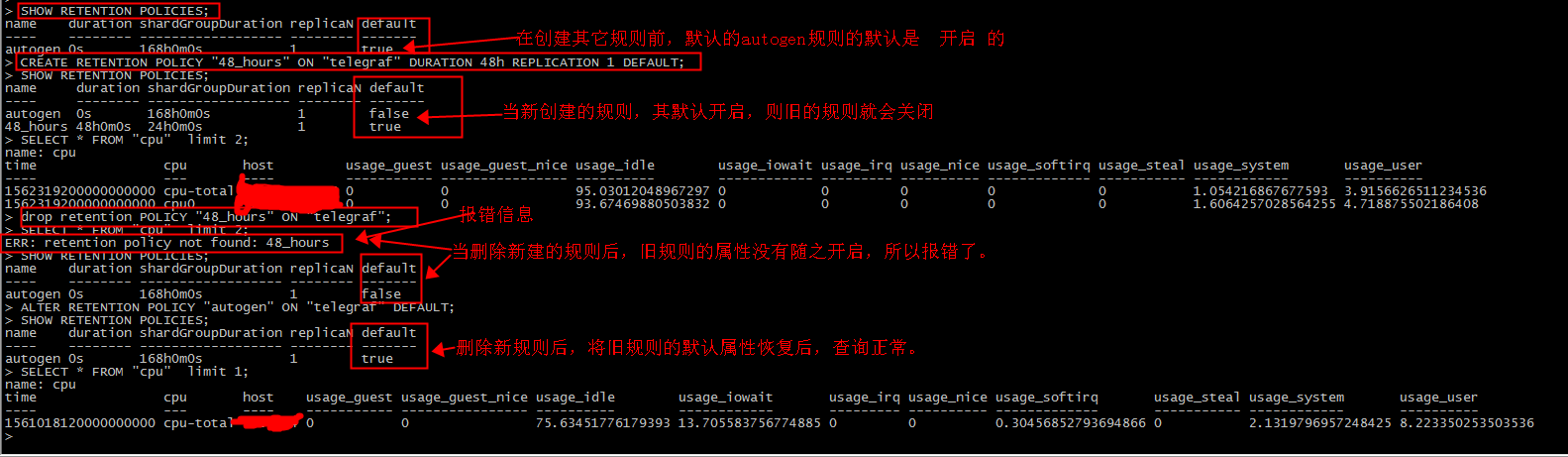
5.InfluxDB 既有的規則不建議刪除,刪除後查詢寫入都報錯。
例如我們創建瞭如下一個規則:
CREATE RETENTION POLICY "48_hours" ON "telegraf" DURATION 48h REPLICATION 1 DEFAULT;
然後執行刪除命令
drop retention POLICY "48_hours" ON "telegraf";
查詢數據,提示以下錯誤;
ERR: retention policy not found: 48_hours
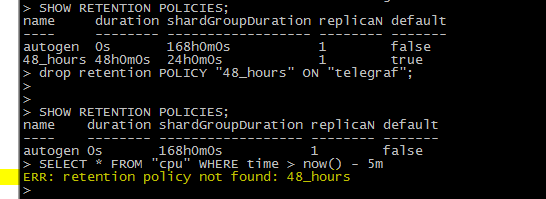
查看各個telegraf收集器,也開始報錯了。

基礎知識

| 欄位 | 解釋說明 |
| name | 名稱, 此示例名稱為autogen |
| duration | 持續時間, 0代表無限制 |
| shardGroupDuration | shardGroup的存儲時間, shardGroup是InfluxDB的一個基本存儲結構, 應該大於這個時間的數據在查詢效率上應該有所降低 |
| replicaN | 全稱是REPLICATION, 副本個數 |
| default | 是否是預設策略 |
解決方案;
新建的策略為預設策略,刪除後沒有了預設策略,要將一個策略設置為預設策略。
本例是將原來的autogen策略恢復為true,下麵是完整的測試過程。