
上一篇學習了多線程的一些基礎知識:多線程的基本概念,及創建和操作多線程。內容相對簡單,但多線程的知識肯定不會這麼簡單,否則我們也不需要花這麼多心思去學習,因為多線程中容易出現線程安全問題。 那麼什麼是線程安全呢,定義如下: 當多個線程訪問同一個對象時,如果不用考慮這些線程在運行時環境下的調度和交替運 ...
上一篇學習了多線程的一些基礎知識:多線程的基本概念,及創建和操作多線程。內容相對簡單,但多線程的知識肯定不會這麼簡單,否則我們也不需要花這麼多心思去學習,因為多線程中容易出現線程安全問題。
那麼什麼是線程安全呢,定義如下:
當多個線程訪問同一個對象時,如果不用考慮這些線程在運行時環境下的調度和交替運行,也不需要進行額外的同步,或者在調用方進行任何其他的協調操作,調用這個對象的行為都可以獲取正確的結果,那這個對象是線程安全的。
簡單的理解就是在多線程情況下代碼的運行結果與預期的正確結果不一致,而產生線程安全的問題一般是由是主記憶體和工作記憶體數據不一致性和重排序導致的。
要理解這些的必須先理解java的記憶體模型。
一 Java記憶體模型
在併發編程領域,有兩個關鍵問題:線程之間的通信和同步
1.1 通信與同步
線程通信是指線程之間以何種機制來交換信息,在命令式編程中,線程之間的通信機制有兩種共用記憶體和消息傳遞,
在共用記憶體的併發模型里,線程之間共用程式的公共狀態,線程之間通過寫-讀記憶體中的公共狀態來隱式進行通信,典型的共用記憶體通信方式就是通過共用對象進行通信。
在消息傳遞的併發模型里,線程之間沒有公共狀態,線程之間必須通過明確的發送消息來顯式進行通信,在java中典型的消息傳遞方式就是wait()和notify()。
線程同步是指程式用於控制不同線程之間操作發生相對順序的機制。在共用記憶體併發模型里,同步是顯式進行的。程式員必須顯式指定某個方法或某段代碼需要線上程之間互斥執行。在消息傳遞的併發模型里,由於消息的發送必須在消息的接收之前,因此同步是隱式進行的。
java記憶體模型是共用記憶體的併發模型,線程之間主要通過讀-寫共用變數來完成隱式通信。如果不能理解Java的共用記憶體模型在編寫併發程式時一定會遇到各種各樣關於記憶體可見性的問題。
1.2 java記憶體模型(JMM)
CPU的處理速度和主存的讀寫速度不是一個量級的,為了平衡這種巨大的差距,每個CPU都會有緩存。因此,共用變數會先放在主存中,每個線程都有屬於自己的工作記憶體,並且會把位於主存中的共用變數拷貝到自己的工作記憶體,之後的讀寫操作均使用位於工作記憶體的變數副本,併在某個時刻將工作記憶體的變數副本寫回到主存中去。JMM就從抽象層次定義了這種方式,並且JMM決定了一個線程對共用變數的寫入何時對其他線程是可見的。
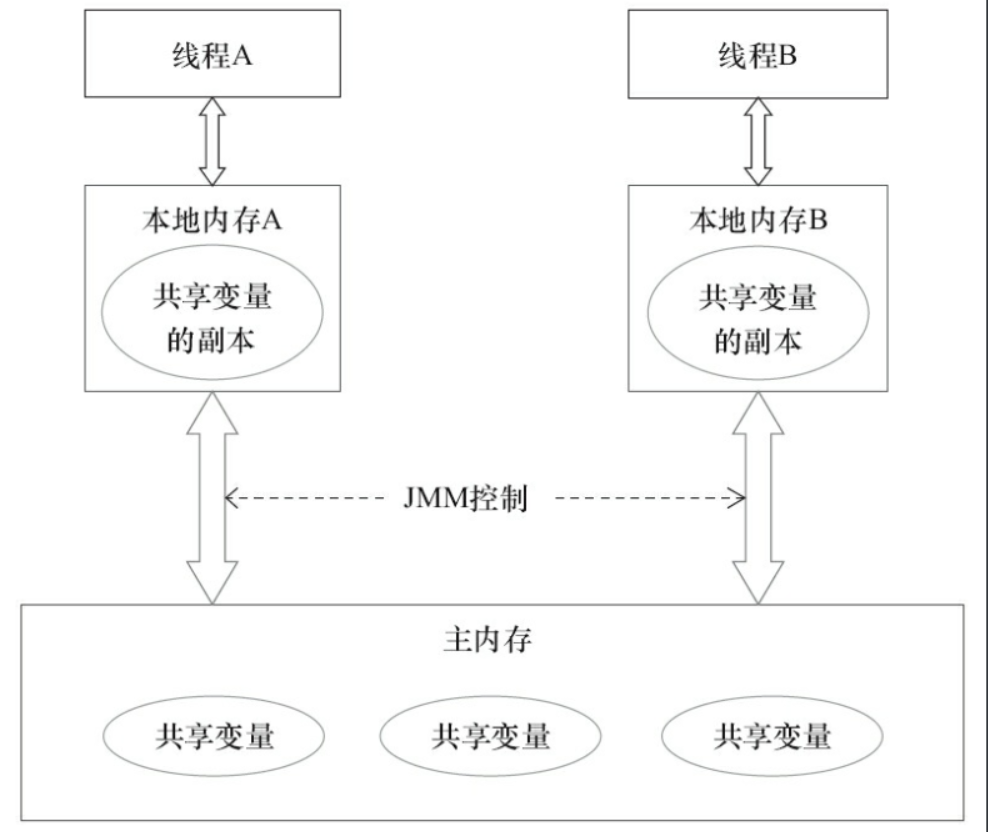
如圖為JMM抽象示意圖,線程A和線程B之間要完成通信的話,要經歷如下兩步:
-
線程A從主記憶體中將共用變數讀入線程A的工作記憶體後併進行操作,之後將數據重新寫回到主記憶體中;
-
線程B從主存中讀取最新的共用變數
java的記憶體模型內容還有很多,推薦看這篇文章:https://blog.csdn.net/suifeng3051/article/details/52611310
1.3 可見性和競爭現象
當對象和變數存儲到電腦的各個記憶體區域時,必然會面臨一些問題,其中最主要的兩個問題是:
-
共用對象對各個線程的可見性
-
共用對象的競爭現象
共用對象的可見性
當多個線程同時操作同一個共用對象時,如果沒有合理的使用volatile和synchronization關鍵字,一個線程對共用對象的更新有可能導致其它線程不可見。
一個CPU中的線程讀取主存數據到CPU緩存,然後對共用對象做了更改,但CPU緩存中的更改後的對象還沒有flush到主存,此時線程對共用對象的更改對其它CPU中的線程是不可見的。最終就是每個線程最終都會拷貝共用對象,而且拷貝的對象位於不同的CPU緩存中。
要解決共用對象可見性這個問題,我們可以使用volatile關鍵字,volatile 關鍵字可以保證變數會直接從主存讀取,而對變數的更新也會直接寫到主存,這個後面會詳講。
競爭現象
如果多個線程共用一個對象,如果它們同時修改這個共用對象,這就產生了競爭現象。
線程A和線程B共用一個對象obj。假設線程A從主存讀取Obj.count變數到自己的CPU緩存,同時,線程B也讀取了Obj.count變數到它的CPU緩存,並且這兩個線程都對Obj.count做了加1操作。此時,Obj.count加1操作被執行了兩次,不過都在不同的CPU緩存中。
要解決競爭現象我們可以使用synchronized代碼塊。synchronized代碼塊可以保證同一個時刻只能有一個線程進入代碼競爭區,synchronized代碼塊也能保證代碼塊中所有變數都將會從主存中讀,當線程退出代碼塊時,對所有變數的更新將會flush到主存,不管這些變數是不是volatile類型的。
二 重排序
指令重排序是指編譯器和處理器為了提高性能對指令進行重新排序,重排序一般有以下三種:

-
-
指令級並行的重排序:如果不存在數據依賴性,處理器可以改變語句對應機器指令的執行順序。
-
記憶體系統的重排序:處理器使用緩存和讀寫緩衝區,這使得載入和存儲操作看上去可能是在亂序執行。
1屬於編譯器重排序,而2和3統稱為處理器重排序。這些重排序會導致線程安全的問題,JMM確保在不同的編譯器和不同的處理器平臺之上,通過插入特定類型的Memory Barrier來禁止特定類型的編譯器重排序和處理器重排序,為上層提供一致的記憶體可見性保證。
那麼什麼情況下一定不會重排序呢?編譯器和處理器不會改變存在數據依賴性關係的兩個操作的執行順序,即不會重排序,這裡有個數據依賴性概念是什麼意思呢?看如下代碼:
int a = 1;//A int b = 2;//B int c = a + b;//c
這段代碼中A和B沒有任何關係,改變A和B的執行順序,不會對結果產生影響,這裡就可以對A和B進行指令重排序,因為不管是先執行A或者B都對結果沒有影響,這個時候就說這兩個操作不存在數據依賴性,數據依賴性是指如果兩個操作訪問同一個變數,且這兩個操作有一個為寫操作,此時這兩個操作就存在數據依賴性,如果我們對變數a進行了寫操作,後又進行了讀取操作,那麼這兩個操作就是有數據依賴性,這個時候就不能進行指令重排序,這個很好理解,因為如果重排序的話會影響結果。
這裡還有一個概念要理解:as-if-serial:不管怎麼重排序,單線程下的執行結果不能被改變。編譯器、runtime和處理器都必須遵守as-if-serial語義。
這裡也比較好理解,就是在單線程情況下,重排序不能影響執行結果,這樣程式員不必擔心單線程中重排序的問題干擾他們,也無需擔心記憶體可見性問題。
三 happens-before規則
我們知道處理器和編譯器會對指令進行重排序,但是如果要我們去瞭解底層的規則,那對我們來說負擔太大了,因此,JMM為程式員在上層提供了規則,這樣我們就可以根據規則去推論跨線程的記憶體可見性問題,而不用再去理解底層重排序的規則。
3.1 happens-before
我們無法就所有場景來規定某個線程修改的變數何時對其他線程可見,但是我們可以指定某些規則,這規則就是happens-before。
在JMM中,如果一個操作執行的結果需要對另一個操作可見,那麼這兩個操作之間必須存在happens-before關係。
因此,JMM可以通過happens-before關係向程式員提供跨線程的記憶體可見性保證(如果A線程的寫操作a與B線程的讀操作b之間存在happens-before關係,儘管a操作和b操作在不同的線程中執行,但JMM向程式員保證a操作將對b操作可見)。具體的定義為:
- 如果一個操作happens-before另一個操作,那麼第一個操作的執行結果將對第二個操作可見,而且第一個操作的執行順序排在第二個操作之前。
- 兩個操作之間存在happens-before關係,並不意味著Java平臺的具體實現必須要按照happens-before關係指定的順序來執行。如果重排序之後的執行結果,與按happens-before關係來執行的結果一致,那麼這種重排序並不非法(也就是說,JMM允許這種重排序)。
3.2 具體規則
具體的規則有8條:
-
程式次序規則:一個線程內,按照代碼順序,書寫在前面的操作先行發生於書寫在後面的操作。
-
鎖定規則:一個unLock操作先行發生於後面對同一個鎖額lock操作。
-
volatile變數規則:對一個變數的寫操作先行發生於後面對這個變數的讀操作。
-
傳遞規則:如果操作A先行發生於操作B,而操作B又先行發生於操作C,則可以得出操作A先行發生於操作C。
-
線程啟動規則:Thread對象的start()方法先行發生於此線程的每個一個動作。
-
線程中斷規則:對線程interrupt()方法的調用先行發生於被中斷線程的代碼檢測到中斷事件的發生。
-
線程終結規則:線程中所有的操作都先行發生於線程的終止檢測,我們可以通過Thread.join()方法結束、Thread.isAlive()的返回值手段檢測到線程已經終止執行。
-
對象終結規則:一個對象的初始化完成先行發生於他的finalize()方法的開始。
參考文章:
https://blog.csdn.net/suifeng3051/article/details/52611310


