
第一個爬蟲程式——豆瓣新書信息爬取。主要用到 soup 的 find 和 find_all 方法。 ...
本文記錄了我學習的第一個爬蟲程式的過程。根據《Python數據分析入門》一書中的提示和代碼,對自己的知識進行查漏補缺。
在上爬蟲程式之前補充一個知識點:User-Agent。它是Http協議中的一部分,屬於頭域的組成部分,User Agent也簡稱UA。它是一個特殊字元串頭,是一種向訪問網站提供你所使用的瀏覽器類型及版本、操作系統及版本、瀏覽器內核、等信息的標識。通過這個標識,用戶所訪問的網站可以顯示不同的排版從而為用戶提供更好的體驗或者進行信息統計;例如用不同的設備訪問同一個網頁,它的排版就會不一樣,這都是網頁根據訪問者的UA來判斷的。
電腦瀏覽器上可以通過右擊網頁空白處——檢查元素——Network——單擊一個元素(如果沒有就刷新一下網站頁面)——下拉找到User-Agent。
例如本機的UA為:Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.121 Safari/537.36
網站伺服器有時會通過識別UA的方式來阻止機器人(如requests)入侵,故我們需要在爬蟲程式里對自己的UA進行偽裝。偽裝的具體步驟看下文。
這次爬蟲的目標是豆瓣新書速遞頁面的信息,url為https://book.douban.com/latest。可簡單分為請求數據、解析數據、根據標簽提取數據、進一步提取數據和“漂亮的”列印五個步驟。
一、請求數據
import requests from bs4 import BeautifulSoup #請求數據 url = 'http://book.douban.com/latest' headers = {'User-Agent':"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.121 Safari/537.36"} data = requests.get(url,headers=headers) #暫不輸入print(data.text)
- 導入requests庫和BeautifulSoup庫。BeautifulSoup庫是一個靈活又方便的網頁解析庫,處理高效,支持多種解析器。bs4為BeautifulSoup四代的簡稱。
- 在這裡進行UA的偽裝:在requests.get函數中可指定headers參數,指定headers為 {'User-Agent':"UA信息……"}。
- 使用data = requests.get(url,headers=headers)獲取到網頁上的所有數據。
二、解析數據
#解析數據 soup = BeautifulSoup(data.text, 'lxml') #暫不輸出print(soup)
- 在這裡將網頁數據data轉化為了 BeautifulSoup 對象,並將這個對象命名為 soup。
- lxml是一個HTML解析器。
三、根據標簽提取數據
- 針對 BeautifulSoup 對象,先檢查元素,觀察網頁。
- “註意:這裡選擇檢查元素後,將滑鼠指針直接移動到右側,即可看到這部分代碼對應的網頁內容。而相反地,想通過網頁內容定位代碼時,可以單機檢查元素後左上角的小箭頭標誌。然後在網頁中選中想要的數據,如此即可在右側自動跳轉到對應代碼。”
- 通過觀察,發現圖書的內容分別包管在左右“虛構類”和“非虛構類”兩個標簽下。
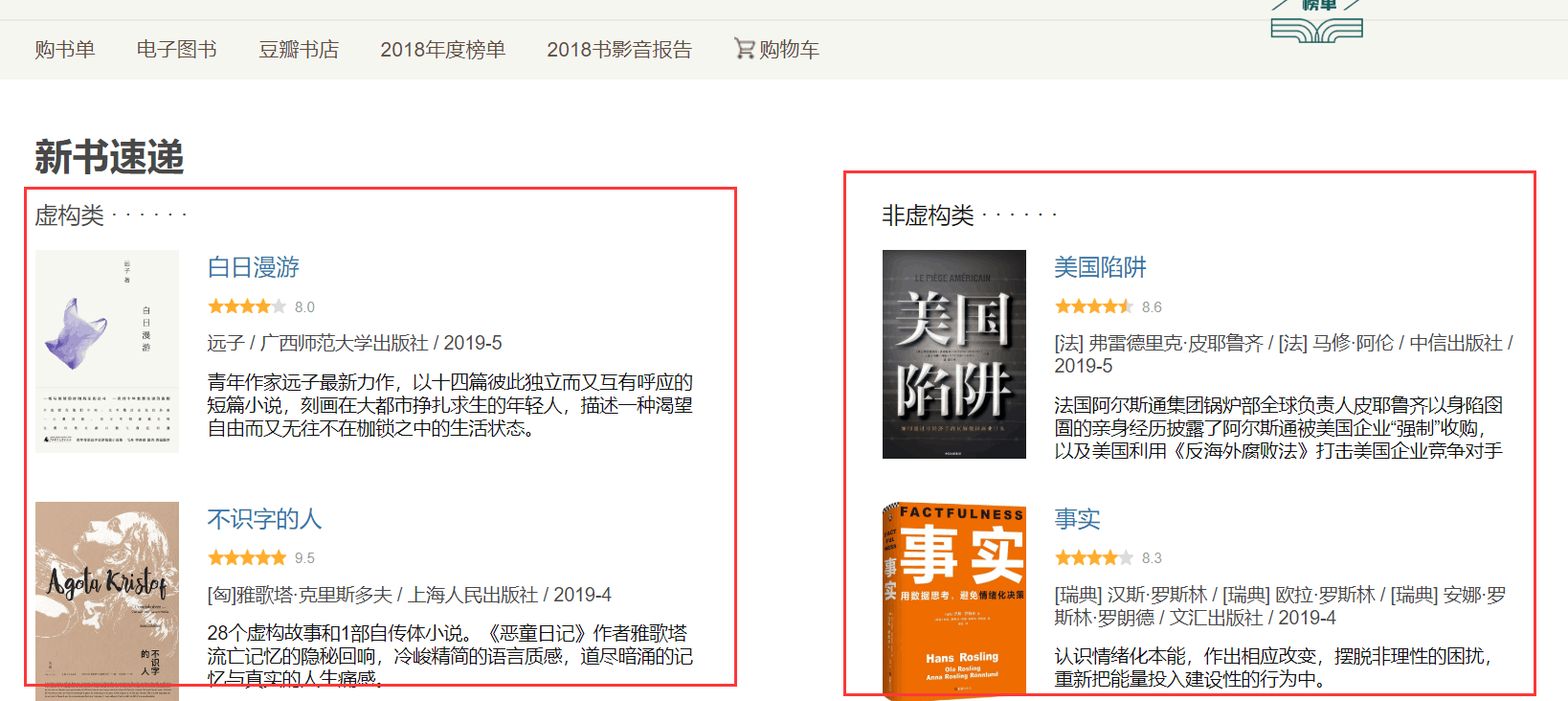
-
對應在網頁源代碼中的表現是
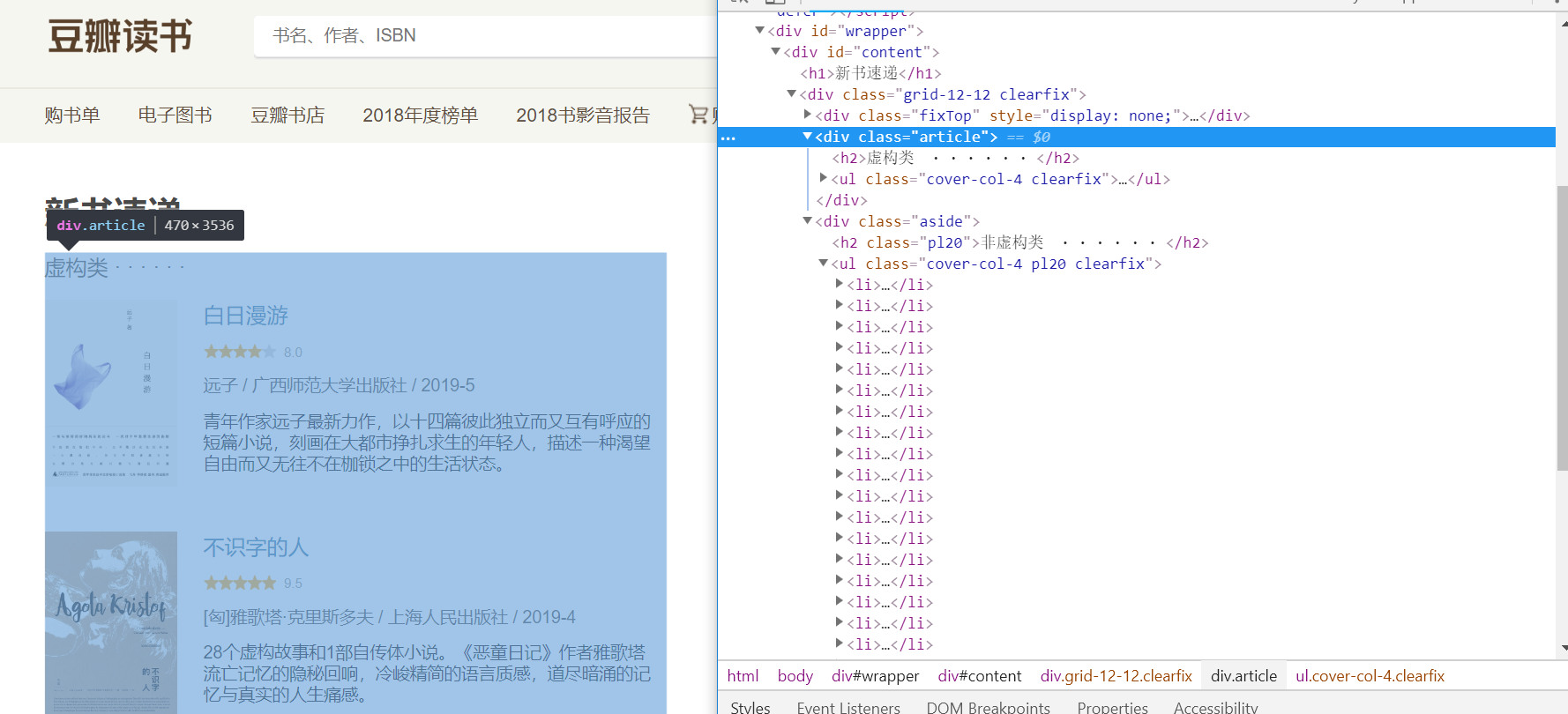
- 仔細觀察可以發現 <div class="article"> 這一個標簽目錄包含了所有的虛構類圖書信息;而對應的 <div class="aside"> 包含了所有非虛構類的圖書信息。也就是我們只需要這兩部分的內容,那我們按照標簽提取它們。上代碼。
#觀察到網頁上的書籍按左右兩邊分佈,按照標簽分別提取 books_left = soup.find('ul',{'class':'cover-col-4 clearfix'}) #這一步的find,查找所有標簽為ul,類class為cover-col-4 clearfix的第一個內容 books_left = books_left.find_all('li') #這裡的find_all再次查找,查找上一步結果里標簽為li的內容 books_right = soup.find('ul',{'class':'cover-col-4 pl20 clearfix'})#為L不為1 books_right = books_right.find_all('li') books = list(books_left) + list(books_right) ''' find()查找第一個匹配結果出現的地方,find_all()找到所有匹配結果出現的地方。
一般用find()找到BeautifulSoup對象內任何第一個標簽入口。 '''
- 最後一句將兩個圖書信息快,存儲到一個列表內,方便後續統一操作。
四、進一步提取,獲取所需信息
#對每一個圖書區塊進行相同的操作,獲取圖書信息 img_urls = [] titles = [] ratings = [] authors = [] details = [] for book in books: #圖書封面圖片url地址 img_url = book.find_all('a')[0].find('img').get('src') #[0]指提取第一個a標簽的內容 img_urls.append(img_url) #圖書標題 title = book.find_all('a')[1].get_text() #get_text()方法:用來獲取標簽裡面的文本內容,在括弧裡面加"strip=True"可以去除文本前後多餘的空格 titles.append(title) #print(title) #評價星級 rating = book.find('p',{'class':'rating'}).get_text(strip=True) #rating = rating.replace('\n','').replace(' ',''),這一步的效果等同於在get_text裡加上參數strip ratings.append(rating) #作者及出版信息 author = book.find('p',{'class':'color-gray'}).get_text() author = author.replace('\n','').replace(' ','') authors.append(author) #圖書簡介 detail = book.find_all('p')[2].get_text() #存疑!!detail = book.find('p',{'class':'detail'}).get_text() 報錯:'NoneType' object has no attribute 'get_text' detail = detail.replace('\n','').replace(' ','') details.append(detail)
- 代碼看似有一些複雜,但實質上主要還是使用了 find 和 find_all 兩個解析工具。
- 仔細分析檢查元素中的源代碼和對應的網頁元素,可輕鬆找到網頁顯示內容的一行、兩行代碼。我們就用 find 和 find_all 去對這一兩行進行操作。
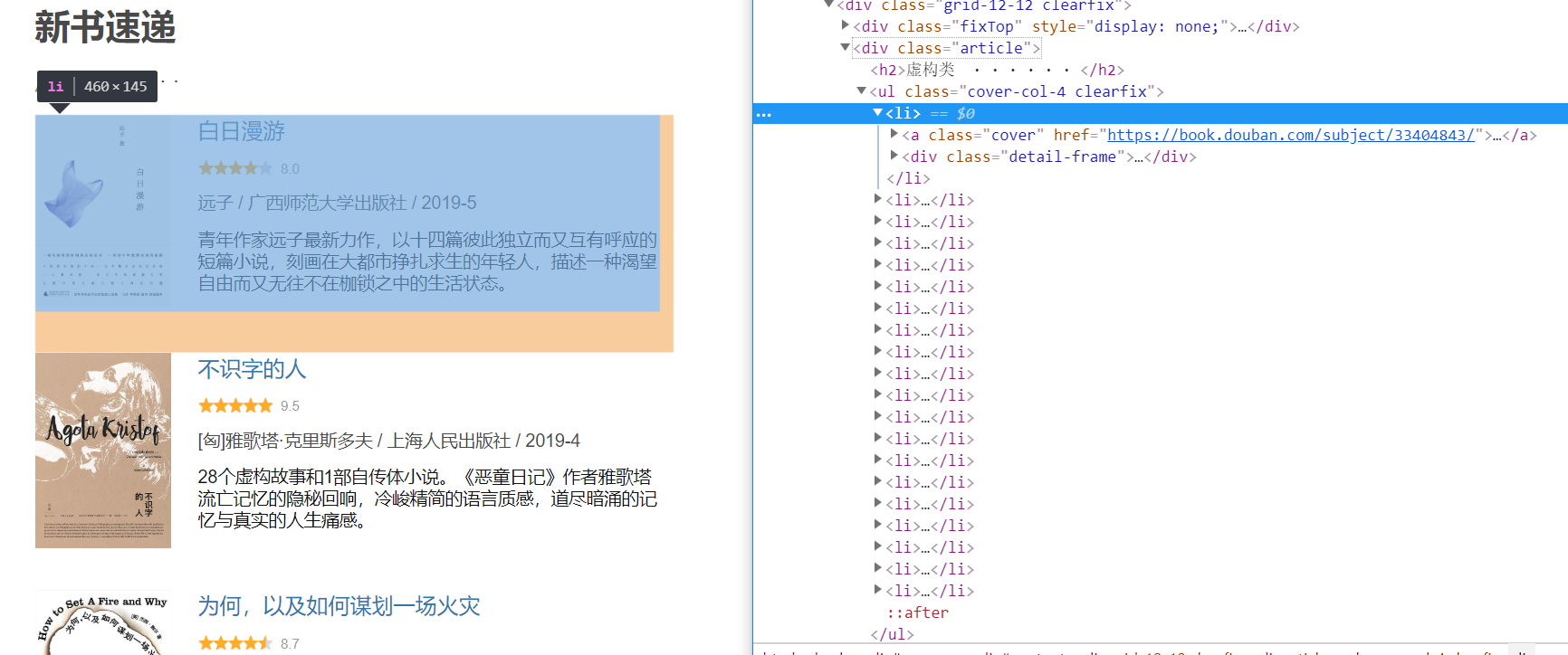





- 舉例說明獲取圖書封面圖面的 url 地址的方法
img_url = book.find_all('a')[0].find('img').get('src') img_urls.append(img_url)
"可以看出圖片地址在此‘信息塊’的第一個 a 標簽內,通過 find_all('a') 找到所有 a 標簽,再通過索引 [0] 提取第一個 a 標簽的內容,觀察可發現,URL在此 a 標簽下的 img 標簽內。同樣的方法,定位到此 img 標簽。應用 find 返回對象的 get 方法,獲取 src 對應的值,即為要找到的 URL 地址。將此圖書的 URL 加入事先準備好的 img_urls 列表內,方便進一步的利用與存取操作。"
- get_text()
此方法可以去除 find 返回對象內的 html 標簽,返回純文本。在括弧裡面加 "strip=True" 可以去除文本前後多餘的空格,效果同replace(' ','')和replace('\n','')。
五、“漂亮的”列印
- 代碼最後得到的是五個裝滿了信息的列表,我們利用 zip 函數,將每個列表裡的數據一一對應輸出。
for a,b,c,d,e in list(zip(img_urls,titles,ratings,authors,details)): print("封面圖片鏈接:{0}\n書名:{1} 評分:{2}\n作者及出版信息:{3}\n簡介:{4}\n\n".format(a,b,c,d,e))
- 得到的部分列印結果如下↓,還可以,還是挺“漂亮的”哈哈。
封面圖片鏈接:https://img3.doubanio.com/view/subject/m/public/s32289202.jpg 書名:白日漫游 評分:8.0 作者及出版信息:遠子/廣西師範大學出版社/2019-5 簡介:青年作家遠子最新力作,以十四篇彼此獨立而又互有呼應的短篇小說,刻畫在大都市掙扎求生的年輕人,描述一種渴望自由而又無往不在枷鎖之中的生活狀態。 封面圖片鏈接:https://img1.doubanio.com/view/subject/m/public/s32281237.jpg 書名:不識字的人 評分:9.5 作者及出版信息:[匈]雅歌塔·克裡斯多夫/上海人民出版社/2019-4 簡介:28個虛構故事和1部自傳體小說。《惡童日記》作者雅歌塔流亡記憶的隱秘迴響,冷峻精簡的語言質感,道盡暗涌的記憶與真實的人生痛感。 封面圖片鏈接:https://img1.doubanio.com/view/subject/m/public/s32305167.jpg 書名:為何,以及如何謀劃一場火災 評分:8.7 作者及出版信息:[美]傑西·鮑爾(JesseBall)/中信出版集團/2019-4 簡介:露西婭的父親死了,母親進了精神病院,她和姑媽住在別人的車庫裡。她又一次被學校勒令退學……在新學校,她遇到一個神秘組織,一群可以改變生活的人。 封面圖片鏈接:https://img3.doubanio.com/view/subject/m/public/s32304855.jpg 書名:呼嘯山莊 評分:9.2 作者及出版信息:【英】愛米麗·勃朗特/浙江文藝出版社/2019-5 簡介:呼嘯山莊裡的三代恩怨。愛米麗·勃朗特名著新版。 封面圖片鏈接:https://img1.doubanio.com/view/subject/m/public/s32323469.jpg 書名:苔 評分:8.6 作者及出版信息:周愷/楚塵文化/中信出版集團/2019-5 簡介:一個晚清家族,一齣袍哥傳奇,一場歷史風暴,一曲時代輓歌。在“三千年未有之大變局”下,再現了蜀中各個階層的人物命運。 封面圖片鏈接:https://img1.doubanio.com/view/subject/m/public/s32295228.jpg 書名:推理時鐘 評分:8.6 作者及出版信息:[日]貴志祐介/新星出版社/2019-5-1 簡介:貴志祐介的推理短篇小說集,共分為四個短篇,主要描寫了偵探榎本與犯罪者的頭腦戰。本格密室推理佳作,在日本年度推理榜單上屢次上榜。
總結:上述代碼的主要工作就是,先將網頁數據轉化為 soup 對象,再運用 soup 對象的一些方法逐步獲取需要的數據。常用方法具體可參考 bs4 官方文檔。本文所寫的是最基礎最簡單的爬蟲,筆者感覺如果想自己的爬蟲水平更進一步,一定要熟悉 bs4 的方法,多瞭解HTML、JS等方面的知識,爬蟲所需瞭解它們的程度不深,但必須對其有所涉及。任重而道遠!


