
[toc] 這篇文章主要講 map 的賦值、刪除、查詢、擴容的具體執行過程,仍然是從底層的角度展開。結合源碼,看完本文一定會徹底明白 map 底層原理。 我要說明的是,這裡對 map 的基本用法涉及比較少,我相信可以通過閱讀其他入門書籍瞭解。本文的內容比較深入,但是由於我畫了各種圖,我相信很容易看懂 ...
目錄
這篇文章主要講 map 的賦值、刪除、查詢、擴容的具體執行過程,仍然是從底層的角度展開。結合源碼,看完本文一定會徹底明白 map 底層原理。
我要說明的是,這裡對 map 的基本用法涉及比較少,我相信可以通過閱讀其他入門書籍瞭解。本文的內容比較深入,但是由於我畫了各種圖,我相信很容易看懂。
什麼是 map
維基百科里這樣定義 map:
In computer science, an associative array, map, symbol table, or dictionary is an abstract data type composed of a collection of (key, value) pairs, such that each possible key appears at most once in the collection.
簡單說明一下:在電腦科學里,被稱為相關數組、map、符號表或者字典,是由一組 <key, value> 對組成的抽象數據結構,並且同一個 key 只會出現一次。
有兩個關鍵點:map 是由 key-value 對組成的;key 只會出現一次。
和 map 相關的操作主要是:
- 增加一個 k-v 對 —— Add or insert;
- 刪除一個 k-v 對 —— Remove or delete;
- 修改某個 k 對應的 v —— Reassign;
- 查詢某個 k 對應的 v —— Lookup;
簡單說就是最基本的 增刪查改。
map 的設計也被稱為 “The dictionary problem”,它的任務是設計一種數據結構用來維護一個集合的數據,並且可以同時對集合進行增刪查改的操作。最主要的數據結構有兩種:哈希查找表(Hash table)、搜索樹(Search tree)。
哈希查找表用一個哈希函數將 key 分配到不同的桶(bucket,也就是數組的不同 index)。這樣,開銷主要在哈希函數的計算以及數組的常數訪問時間。在很多場景下,哈希查找表的性能很高。
哈希查找表一般會存在“碰撞”的問題,就是說不同的 key 被哈希到了同一個 bucket。一般有兩種應對方法:鏈表法和開放地址法。鏈表法將一個 bucket 實現成一個鏈表,落在同一個 bucket 中的 key 都會插入這個鏈表。開放地址法則是碰撞發生後,通過一定的規律,在數組的後面挑選“空位”,用來放置新的 key。
搜索樹法一般採用自平衡搜索樹,包括:AVL 樹,紅黑樹。面試時經常會被問到,甚至被要求手寫紅黑樹代碼,很多時候,面試官自己都寫不上來,非常過分。
自平衡搜索樹法的最差搜索效率是 O(logN),而哈希查找表最差是 O(N)。當然,哈希查找表的平均查找效率是 O(1),如果哈希函數設計的很好,最壞的情況基本不會出現。還有一點,遍歷自平衡搜索樹,返回的 key 序列,一般會按照從小到大的順序;而哈希查找表則是亂序的。
為什麼要用 map
從 Go 語言官方博客摘錄一段話:
One of the most useful data structures in computer science is the hash table. Many hash table implementations exist with varying properties, but in general they offer fast lookups, adds, and deletes. Go provides a built-in map type that implements a hash table.
hash table 是電腦數據結構中一個最重要的設計。大部分 hash table 都實現了快速查找、添加、刪除的功能。Go 語言內置的 map 實現了上述所有功能。
很難想象寫一個程式不使用 map,以至於在回答為什麼要用 map 這個問題上犯了難。
所以,到底為什麼要用 map 呢?因為它太強大了,各種增刪查改的操作效率非常高。
map 的底層如何實現
首先聲明我用的 Go 版本:
go version go1.9.2 darwin/amd64前面說了 map 實現的幾種方案,Go 語言採用的是哈希查找表,並且使用鏈表解決哈希衝突。
接下來我們要探索 map 的核心原理,一窺它的內部結構。
map 記憶體模型
在源碼中,表示 map 的結構體是 hmap,它是 hashmap 的“縮寫”:
// A header for a Go map.
type hmap struct {
// 元素個數,調用 len(map) 時,直接返回此值
count int
flags uint8
// buckets 的對數 log_2
B uint8
// overflow 的 bucket 近似數
noverflow uint16
// 計算 key 的哈希的時候會傳入哈希函數
hash0 uint32
// 指向 buckets 數組,大小為 2^B
// 如果元素個數為0,就為 nil
buckets unsafe.Pointer
// 擴容的時候,buckets 長度會是 oldbuckets 的兩倍
oldbuckets unsafe.Pointer
// 指示擴容進度,小於此地址的 buckets 遷移完成
nevacuate uintptr
extra *mapextra // optional fields
}說明一下,B 是 buckets 數組的長度的對數,也就是說 buckets 數組的長度就是 2^B。bucket 裡面存儲了 key 和 value,後面會再講。
buckets 是一個指針,最終它指向的是一個結構體:
type bmap struct {
tophash [bucketCnt]uint8
}但這隻是錶面(src/runtime/hashmap.go)的結構,編譯期間會給它加料,動態地創建一個新的結構:
type bmap struct {
topbits [8]uint8
keys [8]keytype
values [8]valuetype
pad uintptr
overflow uintptr
}bmap 就是我們常說的“桶”,桶裡面會最多裝 8 個 key,這些 key 之所以會落入同一個桶,是因為它們經過哈希計算後,哈希結果是“一類”的。在桶內,又會根據 key 計算出來的 hash 值的高 8 位來決定 key 到底落入桶內的哪個位置(一個桶內最多有8個位置)。
來一個整體的圖:
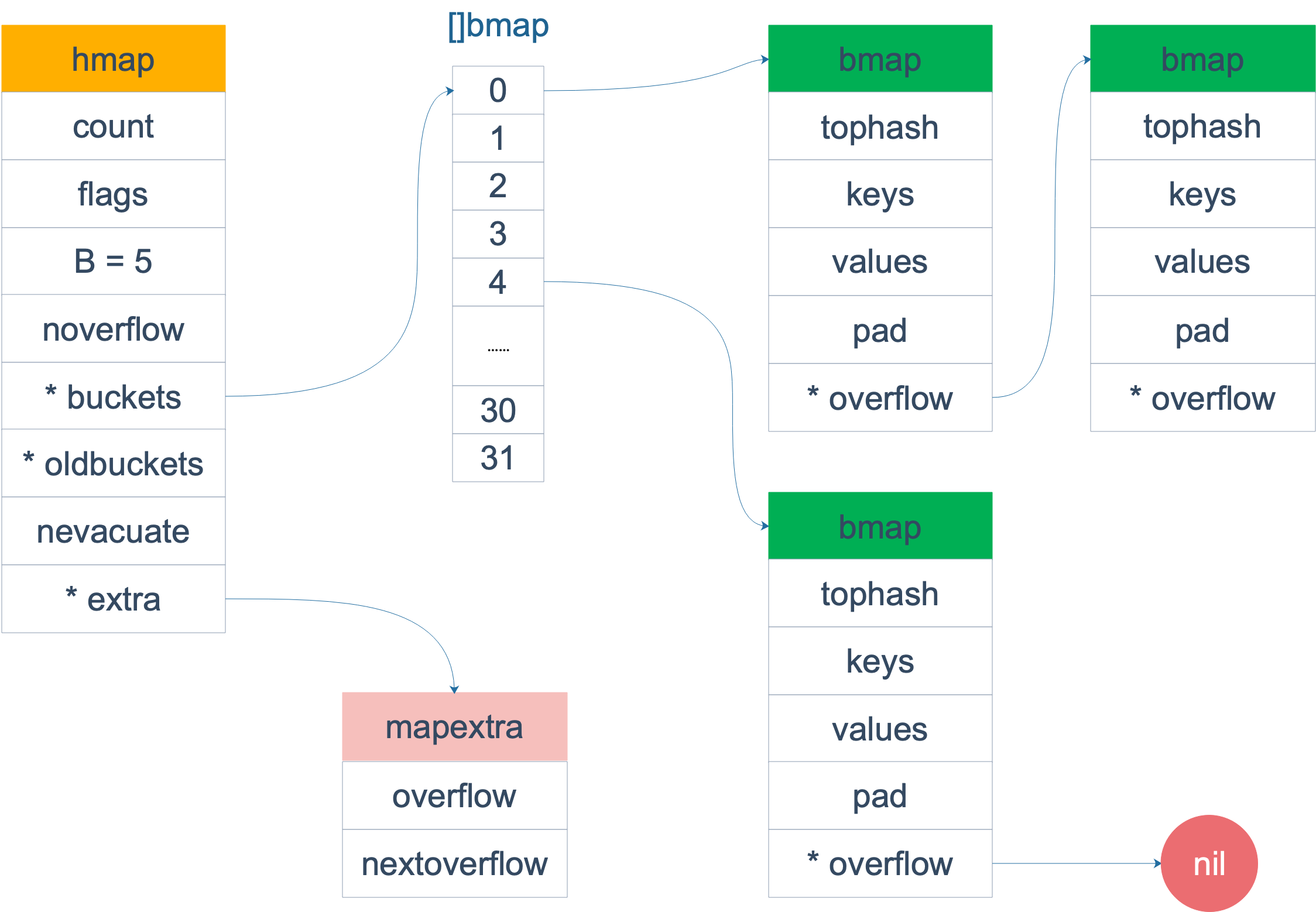
當 map 的 key 和 value 都不是指針,並且 size 都小於 128 位元組的情況下,會把 bmap 標記為不含指針,這樣可以避免 gc 時掃描整個 hmap。但是,我們看 bmap 其實有一個 overflow 的欄位,是指針類型的,破壞了 bmap 不含指針的設想,這時會把 overflow 移動到 extra 欄位來。
type mapextra struct {
// overflow[0] contains overflow buckets for hmap.buckets.
// overflow[1] contains overflow buckets for hmap.oldbuckets.
overflow [2]*[]*bmap
// nextOverflow 包含空閑的 overflow bucket,這是預分配的 bucket
nextOverflow *bmap
}bmap 是存放 k-v 的地方,我們把視角拉近,仔細看 bmap 的內部組成。

上圖就是 bucket 的記憶體模型,HOB Hash 指的就是 top hash。 註意到 key 和 value 是各自放在一起的,並不是 key/value/key/value/... 這樣的形式。源碼里說明這樣的好處是在某些情況下可以省略掉 padding 欄位,節省記憶體空間。
例如,有這樣一個類型的 map:
map[int64]int8如果按照 key/value/key/value/... 這樣的模式存儲,那在每一個 key/value 對之後都要額外 padding 7 個位元組;而將所有的 key,value 分別綁定到一起,這種形式 key/key/.../value/value/...,則只需要在最後添加 padding。
每個 bucket 設計成最多只能放 8 個 key-value 對,如果有第 9 個 key-value 落入當前的 bucket,那就需要再構建一個 bucket ,通過 overflow 指針連接起來。
創建 map
從語法層面上來說,創建 map 很簡單:
ageMp := make(map[string]int)
// 指定 map 長度
ageMp := make(map[string]int, 8)
// ageMp 為 nil,不能向其添加元素,會直接panic
var ageMp map[string]int通過彙編語言可以看到,實際上底層調用的是 makemap 函數,主要做的工作就是初始化 hmap 結構體的各種欄位,例如計算 B 的大小,設置哈希種子 hash0 等等。
func makemap(t *maptype, hint int64, h *hmap, bucket unsafe.Pointer) *hmap {
// 省略各種條件檢查...
// 找到一個 B,使得 map 的裝載因數在正常範圍內
B := uint8(0)
for ; overLoadFactor(hint, B); B++ {
}
// 初始化 hash table
// 如果 B 等於 0,那麼 buckets 就會在賦值的時候再分配
// 如果長度比較大,分配記憶體會花費長一點
buckets := bucket
var extra *mapextra
if B != 0 {
var nextOverflow *bmap
buckets, nextOverflow = makeBucketArray(t, B)
if nextOverflow != nil {
extra = new(mapextra)
extra.nextOverflow = nextOverflow
}
}
// 初始化 hamp
if h == nil {
h = (*hmap)(newobject(t.hmap))
}
h.count = 0
h.B = B
h.extra = extra
h.flags = 0
h.hash0 = fastrand()
h.buckets = buckets
h.oldbuckets = nil
h.nevacuate = 0
h.noverflow = 0
return h
}註意,這個函數返回的結果:*hmap,它是一個指針,而我們之前講過的 makeslice 函數返回的是 Slice 結構體:
func makeslice(et *_type, len, cap int) slice回顧一下 slice 的結構體定義:
// runtime/slice.go
type slice struct {
array unsafe.Pointer // 元素指針
len int // 長度
cap int // 容量
}結構體內部包含底層的數據指針。
makemap 和 makeslice 的區別,帶來一個不同點:當 map 和 slice 作為函數參數時,在函數參數內部對 map 的操作會影響 map 自身;而對 slice 卻不會(之前講 slice 的文章里有講過)。
主要原因:一個是指針(*hmap),一個是結構體(slice)。Go 語言中的函數傳參都是值傳遞,在函數內部,參數會被 copy 到本地。*hmap指針 copy 完之後,仍然指向同一個 map,因此函數內部對 map 的操作會影響實參。而 slice 被 copy 後,會成為一個新的 slice,對它進行的操作不會影響到實參。
哈希函數
map 的一個關鍵點在於,哈希函數的選擇。在程式啟動時,會檢測 cpu 是否支持 aes,如果支持,則使用 aes hash,否則使用 memhash。這是在函數 alginit() 中完成,位於路徑:src/runtime/alg.go 下。
hash 函數,有加密型和非加密型。
加密型的一般用於加密數據、數字摘要等,典型代表就是 md5、sha1、sha256、aes256 這種;
非加密型的一般就是查找。在 map 的應用場景中,用的是查找。
選擇 hash 函數主要考察的是兩點:性能、碰撞概率。
之前我們講過,表示類型的結構體:
type _type struct {
size uintptr
ptrdata uintptr // size of memory prefix holding all pointers
hash uint32
tflag tflag
align uint8
fieldalign uint8
kind uint8
alg *typeAlg
gcdata *byte
str nameOff
ptrToThis typeOff
}其中 alg 欄位就和哈希相關,它是指向如下結構體的指針:
// src/runtime/alg.go
type typeAlg struct {
// (ptr to object, seed) -> hash
hash func(unsafe.Pointer, uintptr) uintptr
// (ptr to object A, ptr to object B) -> ==?
equal func(unsafe.Pointer, unsafe.Pointer) bool
}typeAlg 包含兩個函數,hash 函數計算類型的哈希值,而 equal 函數則計算兩個類型是否“哈希相等”。
對於 string 類型,它的 hash、equal 函數如下:
func strhash(a unsafe.Pointer, h uintptr) uintptr {
x := (*stringStruct)(a)
return memhash(x.str, h, uintptr(x.len))
}
func strequal(p, q unsafe.Pointer) bool {
return *(*string)(p) == *(*string)(q)
}根據 key 的類型,_type 結構體的 alg 欄位會被設置對應類型的 hash 和 equal 函數。
key 定位過程
key 經過哈希計算後得到哈希值,共 64 個 bit 位(64位機,32位機就不討論了,現在主流都是64位機),計算它到底要落在哪個桶時,只會用到最後 B 個 bit 位。還記得前面提到過的 B 嗎?如果 B = 5,那麼桶的數量,也就是 buckets 數組的長度是 2^5 = 32。
例如,現在有一個 key 經過哈希函數計算後,得到的哈希結果是:
10010111 | 000011110110110010001111001010100010010110010101010 │ 01010用最後的 5 個 bit 位,也就是 01010,值為 10,也就是 10 號桶。這個操作實際上就是取餘操作,但是取餘開銷太大,所以代碼實現上用的位操作代替。
再用哈希值的高 8 位,找到此 key 在 bucket 中的位置,這是在尋找已有的 key。最開始桶內還沒有 key,新加入的 key 會找到第一個空位,放入。
buckets 編號就是桶編號,當兩個不同的 key 落在同一個桶中,也就是發生了哈希衝突。衝突的解決手段是用鏈表法:在 bucket 中,從前往後找到第一個空位。這樣,在查找某個 key 時,先找到對應的桶,再去遍歷 bucket 中的 key。
這裡參考曹大 github 博客里的一張圖,原圖是 ascii 圖,geek 味十足,可以從參考資料找到曹大的博客,推薦大家去看看。
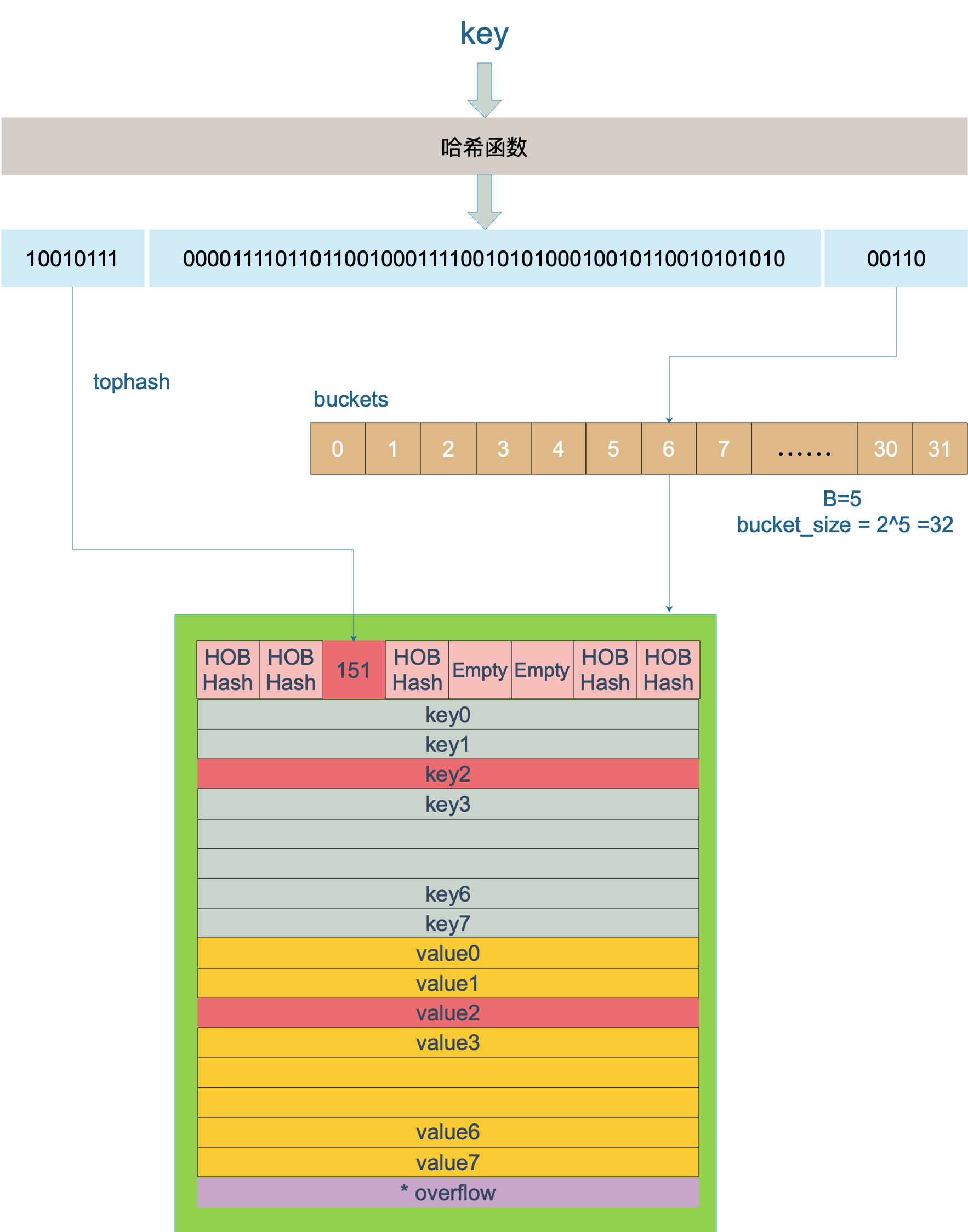
上圖中,假定 B = 5,所以 bucket 總數就是 2^5 = 32。首先計算出待查找 key 的哈希,使用低 5 位 00110,找到對應的 6 號 bucket,使用高 8 位 10010111,對應十進位 151,在 6 號 bucket 中尋找 tophash 值(HOB hash)為 151 的 key,找到了 2 號槽位,這樣整個查找過程就結束了。
如果在 bucket 中沒找到,並且 overflow 不為空,還要繼續去 overflow bucket 中尋找,直到找到或是所有的 key 槽位都找遍了,包括所有的 overflow bucket。
我們來看下源碼吧,哈哈!通過彙編語言可以看到,查找某個 key 的底層函數是 mapacess 系列函數,函數的作用類似,區別在下一節會講到。這裡我們直接看 mapacess1 函數:
func mapaccess1(t *maptype, h *hmap, key unsafe.Pointer) unsafe.Pointer {
// ……
// 如果 h 什麼都沒有,返回零值
if h == nil || h.count == 0 {
return unsafe.Pointer(&zeroVal[0])
}
// 寫和讀衝突
if h.flags&hashWriting != 0 {
throw("concurrent map read and map write")
}
// 不同類型 key 使用的 hash 演算法在編譯期確定
alg := t.key.alg
// 計算哈希值,並且加入 hash0 引入隨機性
hash := alg.hash(key, uintptr(h.hash0))
// 比如 B=5,那 m 就是31,二進位是全 1
// 求 bucket num 時,將 hash 與 m 相與,
// 達到 bucket num 由 hash 的低 8 位決定的效果
m := uintptr(1)<<h.B - 1
// b 就是 bucket 的地址
b := (*bmap)(add(h.buckets, (hash&m)*uintptr(t.bucketsize)))
// oldbuckets 不為 nil,說明發生了擴容
if c := h.oldbuckets; c != nil {
// 如果不是同 size 擴容(看後面擴容的內容)
// 對應條件 1 的解決方案
if !h.sameSizeGrow() {
// 新 bucket 數量是老的 2 倍
m >>= 1
}
// 求出 key 在老的 map 中的 bucket 位置
oldb := (*bmap)(add(c, (hash&m)*uintptr(t.bucketsize)))
// 如果 oldb 沒有搬遷到新的 bucket
// 那就在老的 bucket 中尋找
if !evacuated(oldb) {
b = oldb
}
}
// 計算出高 8 位的 hash
// 相當於右移 56 位,只取高8位
top := uint8(hash >> (sys.PtrSize*8 - 8))
// 增加一個 minTopHash
if top < minTopHash {
top += minTopHash
}
for {
// 遍歷 8 個 bucket
for i := uintptr(0); i < bucketCnt; i++ {
// tophash 不匹配,繼續
if b.tophash[i] != top {
continue
}
// tophash 匹配,定位到 key 的位置
k := add(unsafe.Pointer(b), dataOffset+i*uintptr(t.keysize))
// key 是指針
if t.indirectkey {
// 解引用
k = *((*unsafe.Pointer)(k))
}
// 如果 key 相等
if alg.equal(key, k) {
// 定位到 value 的位置
v := add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.keysize)+i*uintptr(t.valuesize))
// value 解引用
if t.indirectvalue {
v = *((*unsafe.Pointer)(v))
}
return v
}
}
// bucket 找完(還沒找到),繼續到 overflow bucket 里找
b = b.overflow(t)
// overflow bucket 也找完了,說明沒有目標 key
// 返回零值
if b == nil {
return unsafe.Pointer(&zeroVal[0])
}
}
}函數返回 h[key] 的指針,如果 h 中沒有此 key,那就會返回一個 key 相應類型的零值,不會返回 nil。
代碼整體比較直接,沒什麼難懂的地方。跟著上面的註釋一步步理解就好了。
這裡,說一下定位 key 和 value 的方法以及整個迴圈的寫法。
// key 定位公式
k := add(unsafe.Pointer(b), dataOffset+i*uintptr(t.keysize))
// value 定位公式
v := add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.keysize)+i*uintptr(t.valuesize))b 是 bmap 的地址,這裡 bmap 還是源碼里定義的結構體,只包含一個 tophash 數組,經編譯器擴充之後的結構體才包含 key,value,overflow 這些欄位。dataOffset 是 key 相對於 bmap 起始地址的偏移:
dataOffset = unsafe.Offsetof(struct {
b bmap
v int64
}{}.v)因此 bucket 里 key 的起始地址就是 unsafe.Pointer(b)+dataOffset。第 i 個 key 的地址就要在此基礎上跨過 i 個 key 的大小;而我們又知道,value 的地址是在所有 key 之後,因此第 i 個 value 的地址還需要加上所有 key 的偏移。理解了這些,上面 key 和 value 的定位公式就很好理解了。
再說整個大迴圈的寫法,最外層是一個無限迴圈,通過
b = b.overflow(t)遍歷所有的 bucket,這相當於是一個 bucket 鏈表。
當定位到一個具體的 bucket 時,裡層迴圈就是遍歷這個 bucket 里所有的 cell,或者說所有的槽位,也就是 bucketCnt=8 個槽位。整個迴圈過程:
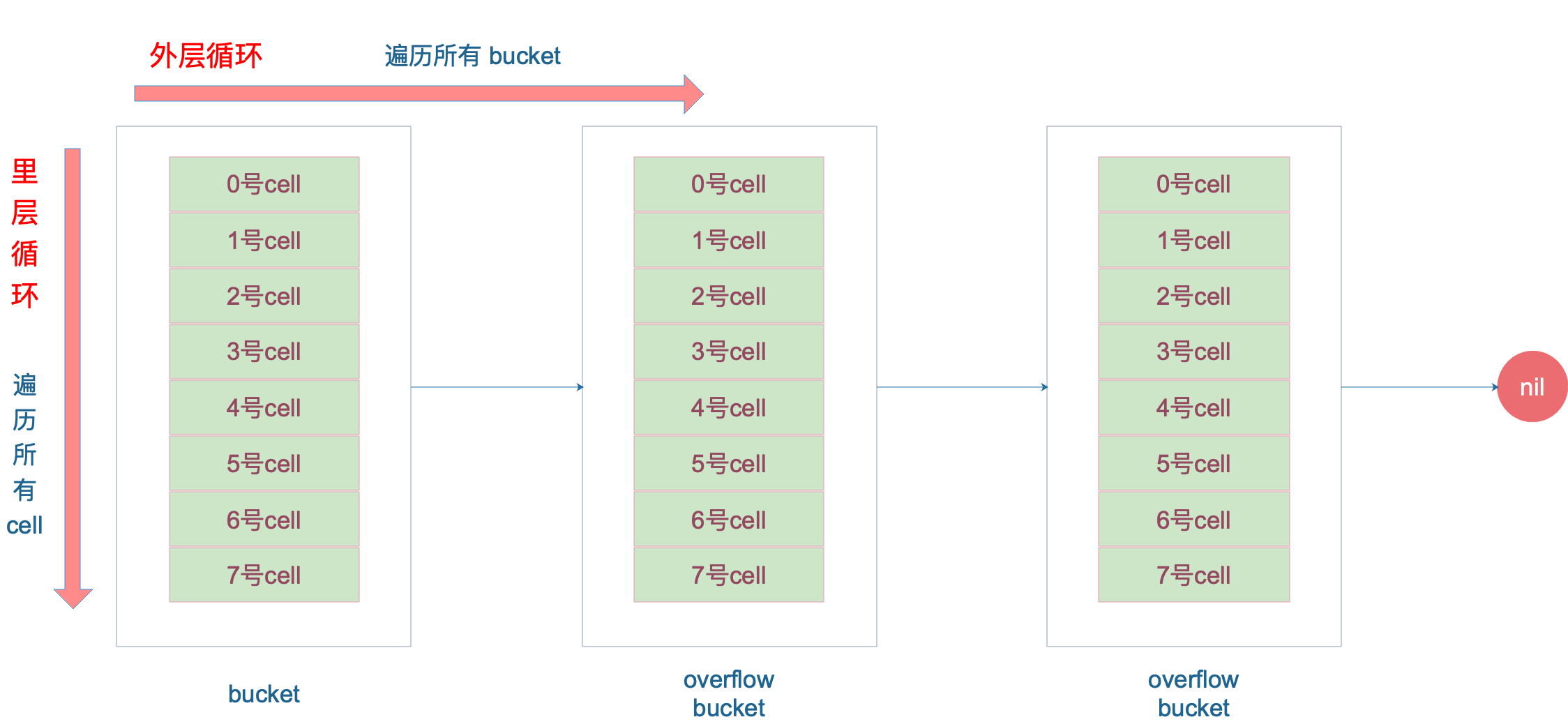
再說一下 minTopHash,當一個 cell 的 tophash 值小於 minTopHash 時,標誌這個 cell 的遷移狀態。因為這個狀態值是放在 tophash 數組裡,為了和正常的哈希值區分開,會給 key 計算出來的哈希值一個增量:minTopHash。這樣就能區分正常的 top hash 值和表示狀態的哈希值。
下麵的這幾種狀態就表徵了 bucket 的情況:
// 空的 cell,也是初始時 bucket 的狀態
empty = 0
// 空的 cell,表示 cell 已經被遷移到新的 bucket
evacuatedEmpty = 1
// key,value 已經搬遷完畢,但是 key 都在新 bucket 前半部分,
// 後面擴容部分會再講到。
evacuatedX = 2
// 同上,key 在後半部分
evacuatedY = 3
// tophash 的最小正常值
minTopHash = 4源碼里判斷這個 bucket 是否已經搬遷完畢,用到的函數:
func evacuated(b *bmap) bool {
h := b.tophash[0]
return h > empty && h < minTopHash
}只取了 tophash 數組的第一個值,判斷它是否在 0-4 之間。對比上面的常量,當 top hash 是 evacuatedEmpty、evacuatedX、evacuatedY 這三個值之一,說明此 bucket 中的 key 全部被搬遷到了新 bucket。
map 的兩種 get 操作
Go 語言中讀取 map 有兩種語法:帶 comma 和 不帶 comma。當要查詢的 key 不在 map 里,帶 comma 的用法會返回一個 bool 型變數提示 key 是否在 map 中;而不帶 comma 的語句則會返回一個 value 類型的零值。如果 value 是 int 型就會返回 0,如果 value 是 string 類型,就會返回空字元串。
package main
import "fmt"
func main() {
ageMap := make(map[string]int)
ageMap["qcrao"] = 18
// 不帶 comma 用法
age1 := ageMap["stefno"]
fmt.Println(age1)
// 帶 comma 用法
age2, ok := ageMap["stefno"]
fmt.Println(age2, ok)
}運行結果:
0
0 false以前一直覺得好神奇,怎麼實現的?這其實是編譯器在背後做的工作:分析代碼後,將兩種語法對應到底層兩個不同的函數。
// src/runtime/hashmap.go
func mapaccess1(t *maptype, h *hmap, key unsafe.Pointer) unsafe.Pointer
func mapaccess2(t *maptype, h *hmap, key unsafe.Pointer) (unsafe.Pointer, bool)源碼里,函數命名不拘小節,直接帶上尾碼 1,2,完全不理會《代碼大全》里的那一套命名的做法。從上面兩個函數的聲明也可以看出差別了,mapaccess2 函數返回值多了一個 bool 型變數,兩者的代碼也是完全一樣的,只是在返回值後面多加了一個 false 或者 true。
另外,根據 key 的不同類型,編譯器還會將查找、插入、刪除的函數用更具體的函數替換,以優化效率:
| key 類型 | 查找 |
|---|---|
| uint32 | mapaccess1_fast32(t maptype, h hmap, key uint32) unsafe.Pointer |
| uint32 | mapaccess2_fast32(t maptype, h hmap, key uint32) (unsafe.Pointer, bool) |
| uint64 | mapaccess1_fast64(t maptype, h hmap, key uint64) unsafe.Pointer |
| uint64 | mapaccess2_fast64(t maptype, h hmap, key uint64) (unsafe.Pointer, bool) |
| string | mapaccess1_faststr(t maptype, h hmap, ky string) unsafe.Pointer |
| string | mapaccess2_faststr(t maptype, h hmap, ky string) (unsafe.Pointer, bool) |
這些函數的參數類型直接是具體的 uint32、unt64、string,在函數內部由於提前知曉了 key 的類型,所以記憶體佈局是很清楚的,因此能節省很多操作,提高效率。
上面這些函數都是在文件 src/runtime/hashmap_fast.go 里。
如何進行擴容
使用哈希表的目的就是要快速查找到目標 key,然而,隨著向 map 中添加的 key 越來越多,key 發生碰撞的概率也越來越大。bucket 中的 8 個 cell 會被逐漸塞滿,查找、插入、刪除 key 的效率也會越來越低。最理想的情況是一個 bucket 只裝一個 key,這樣,就能達到 O(1) 的效率,但這樣空間消耗太大,用空間換時間的代價太高。
Go 語言採用一個 bucket 里裝載 8 個 key,定位到某個 bucket 後,還需要再定位到具體的 key,這實際上又用了時間換空間。
當然,這樣做,要有一個度,不然所有的 key 都落在了同一個 bucket 里,直接退化成了鏈表,各種操作的效率直接降為 O(n),是不行的。
因此,需要有一個指標來衡量前面描述的情況,這就是裝載因數。Go 源碼里這樣定義 裝載因數:
loadFactor := count / (2^B)count 就是 map 的元素個數,2^B 表示 bucket 數量。
再來說觸發 map 擴容的時機:在向 map 插入新 key 的時候,會進行條件檢測,符合下麵這 2 個條件,就會觸發擴容:
- 裝載因數超過閾值,源碼里定義的閾值是 6.5。
- overflow 的 bucket 數量過多:當 B 小於 15,也就是 bucket 總數 2^B 小於 2^15 時,如果 overflow 的 bucket 數量超過 2^B;當 B >= 15,也就是 bucket 總數 2^B 大於等於 2^15,如果 overflow 的 bucket 數量超過 2^15。
通過彙編語言可以找到賦值操作對應源碼中的函數是 mapassign,對應擴容條件的源碼如下:
// src/runtime/hashmap.go/mapassign
// 觸發擴容時機
if !h.growing() && (overLoadFactor(int64(h.count), h.B) || tooManyOverflowBuckets(h.noverflow, h.B)) {
hashGrow(t, h)
}
// 裝載因數超過 6.5
func overLoadFactor(count int64, B uint8) bool {
return count >= bucketCnt && float32(count) >= loadFactor*float32((uint64(1)<<B))
}
// overflow buckets 太多
func tooManyOverflowBuckets(noverflow uint16, B uint8) bool {
if B < 16 {
return noverflow >= uint16(1)<<B
}
return noverflow >= 1<<15
}解釋一下:
第 1 點:我們知道,每個 bucket 有 8 個空位,在沒有溢出,且所有的桶都裝滿了的情況下,裝載因數算出來的結果是 8。因此當裝載因數超過 6.5 時,表明很多 bucket 都快要裝滿了,查找效率和插入效率都變低了。在這個時候進行擴容是有必要的。
第 2 點:是對第 1 點的補充。就是說在裝載因數比較小的情況下,這時候 map 的查找和插入效率也很低,而第 1 點識別不出來這種情況。錶面現象就是計算裝載因數的分子比較小,即 map 里元素總數少,但是 bucket 數量多(真實分配的 bucket 數量多,包括大量的 overflow bucket)。
不難想像造成這種情況的原因:不停地插入、刪除元素。先插入很多元素,導致創建了很多 bucket,但是裝載因數達不到第 1 點的臨界值,未觸發擴容來緩解這種情況。之後,刪除元素降低元素總數量,再插入很多元素,導致創建很多的 overflow bucket,但就是不會觸犯第 1 點的規定,你能拿我怎麼辦?overflow bucket 數量太多,導致 key 會很分散,查找插入效率低得嚇人,因此出台第 2 點規定。這就像是一座空城,房子很多,但是住戶很少,都分散了,找起人來很困難。
對於命中條件 1,2 的限制,都會發生擴容。但是擴容的策略並不相同,畢竟兩種條件應對的場景不同。
對於條件 1,元素太多,而 bucket 數量太少,很簡單:將 B 加 1,bucket 最大數量(2^B)直接變成原來 bucket 數量的 2 倍。於是,就有新老 bucket 了。註意,這時候元素都在老 bucket 里,還沒遷移到新的 bucket 來。而且,新 bucket 只是最大數量變為原來最大數量(2^B)的 2 倍(2^B * 2)。
對於條件 2,其實元素沒那麼多,但是 overflow bucket 數特別多,說明很多 bucket 都沒裝滿。解決辦法就是開闢一個新 bucket 空間,將老 bucket 中的元素移動到新 bucket,使得同一個 bucket 中的 key 排列地更緊密。這樣,原來,在 overflow bucket 中的 key 可以移動到 bucket 中來。結果是節省空間,提高 bucket 利用率,map 的查找和插入效率自然就會提升。
對於條件 2 的解決方案,曹大的博客里還提出了一個極端的情況:如果插入 map 的 key 哈希都一樣,就會落到同一個 bucket 里,超過 8 個就會產生 overflow bucket,結果也會造成 overflow bucket 數過多。移動元素其實解決不了問題,因為這時整個哈希表已經退化成了一個鏈表,操作效率變成了 O(n)。
再來看一下擴容具體是怎麼做的。由於 map 擴容需要將原有的 key/value 重新搬遷到新的記憶體地址,如果有大量的 key/value 需要搬遷,會非常影響性能。因此 Go map 的擴容採取了一種稱為“漸進式”地方式,原有的 key 並不會一次性搬遷完畢,每次最多只會搬遷 2 個 bucket。
上面說的 hashGrow() 函數實際上並沒有真正地“搬遷”,它只是分配好了新的 buckets,並將老的 buckets 掛到了 oldbuckets 欄位上。真正搬遷 buckets 的動作在 growWork() 函數中,而調用 growWork() 函數的動作是在 mapassign 和 mapdelete 函數中。也就是插入或修改、刪除 key 的時候,都會嘗試進行搬遷 buckets 的工作。先檢查 oldbuckets 是否搬遷完畢,具體來說就是檢查 oldbuckets 是否為 nil。
我們先看 hashGrow() 函數所做的工作,再來看具體的搬遷 buckets 是如何進行的。
func hashGrow(t *maptype, h *hmap) {
// B+1 相當於是原來 2 倍的空間
bigger := uint8(1)
// 對應條件 2
if !overLoadFactor(int64(h.count), h.B) {
// 進行等量的記憶體擴容,所以 B 不變
bigger = 0
h.flags |= sameSizeGrow
}
// 將老 buckets 掛到 buckets 上
oldbuckets := h.buckets
// 申請新的 buckets 空間
newbuckets, nextOverflow := makeBucketArray(t, h.B+bigger)
flags := h.flags &^ (iterator | oldIterator)
if h.flags&iterator != 0 {
flags |= oldIterator
}
// 提交 grow 的動作
h.B += bigger
h.flags = flags
h.oldbuckets = oldbuckets
h.buckets = newbuckets
// 搬遷進度為 0
h.nevacuate = 0
// overflow buckets 數為 0
h.noverflow = 0
// ……
}主要是申請到了新的 buckets 空間,把相關的標誌位都進行了處理:例如標誌 nevacuate 被置為 0, 表示當前搬遷進度為 0。
值得一說的是對 h.flags 的處理:
flags := h.flags &^ (iterator | oldIterator)
if h.flags&iterator != 0 {
flags |= oldIterator
}這裡得先說下運算符:&^。這叫按位置 0運算符。例如:
x = 01010011
y = 01010100
z = x &^ y = 00000011如果 y bit 位為 1,那麼結果 z 對應 bit 位就為 0,否則 z 對應 bit 位就和 x 對應 bit 位的值相同。
所以上面那段對 flags 一頓操作的代碼的意思是:先把 h.flags 中 iterator 和 oldIterator 對應位清 0,然後如果發現 iterator 位為 1,那就把它轉接到 oldIterator 位,使得 oldIterator 標誌位變成 1。潛臺詞就是:buckets 現在掛到了 oldBuckets 名下了,對應的標誌位也轉接過去吧。
幾個標誌位如下:
// 可能有迭代器使用 buckets
iterator = 1
// 可能有迭代器使用 oldbuckets
oldIterator = 2
// 有協程正在向 map 中寫入 key
hashWriting = 4
// 等量擴容(對應條件 2)
sameSizeGrow = 8再來看看真正執行搬遷工作的 growWork() 函數。
func growWork(t *maptype, h *hmap, bucket uintptr) {
// 確認搬遷老的 bucket 對應正在使用的 bucket
evacuate(t, h, bucket&h.oldbucketmask())
// 再搬遷一個 bucket,以加快搬遷進程
if h.growing() {
evacuate(t, h, h.nevacuate)
}
}h.growing() 函數非常簡單:
func (h *hmap) growing() bool {
return h.oldbuckets != nil
}如果 oldbuckets 不為空,說明還沒有搬遷完畢,還得繼續搬。
bucket&h.oldbucketmask() 這行代碼,如源碼註釋里說的,是為了確認搬遷的 bucket 是我們正在使用的 bucket。oldbucketmask() 函數返回擴容前的 map 的 bucketmask。
所謂的 bucketmask,作用就是將 key 計算出來的哈希值與 bucketmask 相與,得到的結果就是 key 應該落入的桶。比如 B = 5,那麼 bucketmask 的低 5 位是 11111,其餘位是 0,hash 值與其相與的意思是,只有 hash 值的低 5 位決策 key 到底落入哪個 bucket。
接下來,我們集中所有的精力在搬遷的關鍵函數 evacuate。源碼貼在下麵,不要緊張,我會加上大面積的註釋,通過註釋絕對是能看懂的。之後,我會再對搬遷過程作詳細說明。
源碼如下:
func evacuate(t *maptype, h *hmap, oldbucket uintptr) {
// 定位老的 bucket 地址
b := (*bmap)(add(h.oldbuckets, oldbucket*uintptr(t.bucketsize)))
// 結果是 2^B,如 B = 5,結果為32
newbit := h.noldbuckets()
// key 的哈希函數
alg := t.key.alg
// 如果 b 沒有被搬遷過
if !evacuated(b) {
var (
// 表示bucket 移動的目標地址
x, y *bmap
// 指向 x,y 中的 key/val
xi, yi int
// 指向 x,y 中的 key
xk, yk unsafe.Pointer
// 指向 x,y 中的 value
xv, yv unsafe.Pointer
)
// 預設是等 size 擴容,前後 bucket 序號不變
// 使用 x 來進行搬遷
x = (*bmap)(add(h.buckets, oldbucket*uintptr(t.bucketsize)))
xi = 0
xk = add(unsafe.Pointer(x), dataOffset)
xv = add(xk, bucketCnt*uintptr(t.keysize))、
// 如果不是等 size 擴容,前後 bucket 序號有變
// 使用 y 來進行搬遷
if !h.sameSizeGrow() {
// y 代表的 bucket 序號增加了 2^B
y = (*bmap)(add(h.buckets, (oldbucket+newbit)*uintptr(t.bucketsize)))
yi = 0
yk = add(unsafe.Pointer(y), dataOffset)
yv = add(yk, bucketCnt*uintptr(t.keysize))
}
// 遍歷所有的 bucket,包括 overflow buckets
// b 是老的 bucket 地址
for ; b != nil; b = b.overflow(t) {
k := add(unsafe.Pointer(b), dataOffset)
v := add(k, bucketCnt*uintptr(t.keysize))
// 遍歷 bucket 中的所有 cell
for i := 0; i < bucketCnt; i, k, v = i+1, add(k, uintptr(t.keysize)), add(v, uintptr(t.valuesize)) {
// 當前 cell 的 top hash 值
top := b.tophash[i]
// 如果 cell 為空,即沒有 key
if top == empty {
// 那就標誌它被"搬遷"過
b.tophash[i] = evacuatedEmpty
// 繼續下個 cell
continue
}
// 正常不會出現這種情況
// 未被搬遷的 cell 只可能是 empty 或是
// 正常的 top hash(大於 minTopHash)
if top < minTopHash {
throw("bad map state")
}
k2 := k
// 如果 key 是指針,則解引用
if t.indirectkey {
k2 = *((*unsafe.Pointer)(k2))
}
// 預設使用 X,等量擴容
useX := true
// 如果不是等量擴容
if !h.sameSizeGrow() {
// 計算 hash 值,和 key 第一次寫入時一樣
hash := alg.hash(k2, uintptr(h.hash0))
// 如果有協程正在遍歷 map
if h.flags&iterator != 0 {
// 如果出現 相同的 key 值,算出來的 hash 值不同
if !t.reflexivekey && !alg.equal(k2, k2) {
// 只有在 float 變數的 NaN() 情況下會出現
if top&1 != 0 {
// 第 B 位置 1
hash |= newbit
} else {
// 第 B 位置 0
hash &^= newbit
}
// 取高 8 位作為 top hash 值
top = uint8(hash >> (sys.PtrSize*8 - 8))
if top < minTopHash {
top += minTopHash
}
}
}
// 取決於新哈希值的 oldB+1 位是 0 還是 1
// 詳細看後面的文章
useX = hash&newbit == 0
}
// 如果 key 搬到 X 部分
if useX {
// 標誌老的 cell 的 top hash 值,表示搬移到 X 部分
b.tophash[i] = evacuatedX
// 如果 xi 等於 8,說明要溢出了
if xi == bucketCnt {
// 新建一個 bucket
newx := h.newoverflow(t, x)
x = newx
// xi 從 0 開始計數
xi = 0
// xk 表示 key 要移動到的位置
xk = add(unsafe.Pointer(x), dataOffset)
// xv 表示 value 要移動到的位置
xv = add(xk, bucketCnt*uintptr(t.keysize))
}
// 設置 top hash 值
x.tophash[xi] = top
// key 是指針
if t.indirectkey {
// 將原 key(是指針)複製到新位置
*(*unsafe.Pointer)(xk) = k2 // copy pointer
} else {
// 將原 key(是值)複製到新位置
typedmemmove(t.key, xk, k) // copy value
}
// value 是指針,操作同 key
if t.indirectvalue {
*(*unsafe.Pointer)(xv) = *(*unsafe.Pointer)(v)
} else {
typedmemmove(t.elem, xv, v)
}
// 定位到下一個 cell
xi++
xk = add(xk, uintptr(t.keysize))
xv = add(xv, uintptr(t.valuesize))
} else { // key 搬到 Y 部分,操作同 X 部分
// ……
// 省略了這部分,操作和 X 部分相同
}
}
}
// 如果沒有協程在使用老的 buckets,就把老 buckets 清除掉,幫助gc
if h.flags&oldIterator == 0 {
b = (*bmap)(add(h.oldbuckets, oldbucket*uintptr(t.bucketsize)))
// 只清除bucket 的 key,value 部分,保留 top hash 部分,指示搬遷狀態
if t.bucket.kind&kindNoPointers == 0 {
memclrHasPointers(add(unsafe.Pointer(b), dataOffset), uintptr(t.bucketsize)-dataOffset)
} else {
memclrNoHeapPointers(add(unsafe.Pointer(b), dataOffset), uintptr(t.bucketsize)-dataOffset)
}
}
}
// 更新搬遷進度
// 如果此次搬遷的 bucket 等於當前進度
if oldbucket == h.nevacuate {
// 進度加 1
h.nevacuate = oldbucket + 1
// Experiments suggest that 1024 is overkill by at least an order of magnitude.
// Put it in there as a safeguard anyway, to ensure O(1) behavior.
// 嘗試往後看 1024 個 bucket
stop := h.nevacuate + 1024
if stop > newbit {
stop = newbit
}
// 尋找沒有搬遷的 bucket
for h.nevacuate != stop && bucketEvacuated(t, h, h.nevacuate) {
h.nevacuate++
}
// 現在 h.nevacuate 之前的 bucket 都被搬遷完畢
// 所有的 buckets 搬遷完畢
if h.nevacuate == newbit {
// 清除老的 buckets
h.oldbuckets = nil
// 清除老的 overflow bucket
// 回憶一下:[0] 表示當前 overflow bucket
// [1] 表示 old overflow bucket
if h.extra != nil {
h.extra.overflow[1] = nil
}
// 清除正在擴容的標誌位
h.flags &^= sameSizeGrow
}
}
}evacuate 函數的代碼註釋非常清晰,對著代碼和註釋是很容易看懂整個的搬遷過程的,耐心點。
搬遷的目的就是將老的 buckets 搬遷到新的 buckets。而通過前面的說明我們知道,應對條件 1,新的 buckets 數量是之前的一倍,應對條件 2,新的 buckets 數量和之前相等。
對於條件 1,從老的 buckets 搬遷到新的 buckets,由於 bucktes 數量不變,因此可以按序號來搬,比如原來在 0 號 bucktes,到新的地方後,仍然放在 0 號 buckets。
對於條件 2,就沒這麼簡單了。要重新計算 key 的哈希,才能決定它到底落在哪個 bucket。例如,原來 B = 5,計算出 key 的哈希後,只用看它的低 5 位,就能決定它落在哪個 bucket。擴容後,B 變成了 6,因此需要多看一位,它的低 6 位決定 key 落在哪個 bucket。這稱為 rehash。

因此,某個 key 在搬遷前後 bucket 序號可能和原來相等,也可能是相比原來加上 2^B(原來的 B 值),取決於 hash 值 第 6 bit 位是 0 還是 1。
理解了上面 bucket 序號的變化,我們就可以回答另一個問題了:為什麼遍歷 map 是無序的?
map 在擴容後,會發生 key 的搬遷,原來落在同一個 bucket 中的 key,搬遷後,有些 key 就要遠走高飛了(bucket 序號加上了 2^B)。而遍歷的過程,就是按順序遍歷 bucket,同時按順序遍歷 bucket 中的 key。搬遷後,key 的位置發生了重大的變化,有些 key 飛上高枝,有些 key 則原地不動。這樣,遍歷 map 的結果就不可能按原來的順序了。
當然,如果我就一個 hard code 的 map,我也不會向 map 進行插入刪除的操作,按理說每次遍歷這樣的 map 都會返回一個固定順序的 key/value 序列吧。的確是這樣,但是 Go 杜絕了這種做法,因為這樣會給新手程式員帶來誤解,以為這是一定會發生的事情,在某些情況下,可能會釀成大錯。
當然,Go 做得更絕,當我們在遍歷 map 時,並不是固定地從 0 號 bucket 開始遍歷,每次都是從一個隨機值序號的 bucket 開始遍歷,並且是從這個 bucket 的一個隨機序號的 cell 開始遍歷。這樣,即使你是一個寫死的 map,僅僅只是遍歷它,也不太可能會返回一個固定序列的 key/value 對了。
多說一句,“迭代 map 的結果是無序的”這個特性是從 go 1.0 開始加入的。
再明確一個問題:如果擴容後,B 增加了 1,意味著 buckets 總數是原來的 2 倍,原來 1 號的桶“裂變”到兩個桶。
例如,原始 B = 2,1號 bucket 中有 2 個 key 的哈希值低 3 位分別為:010,110。由於原來 B = 2,所以低 2 位 10 決定它們落在 2 號桶,現在 B 變成 3,所以 010、110 分別落入 2、6 號桶。
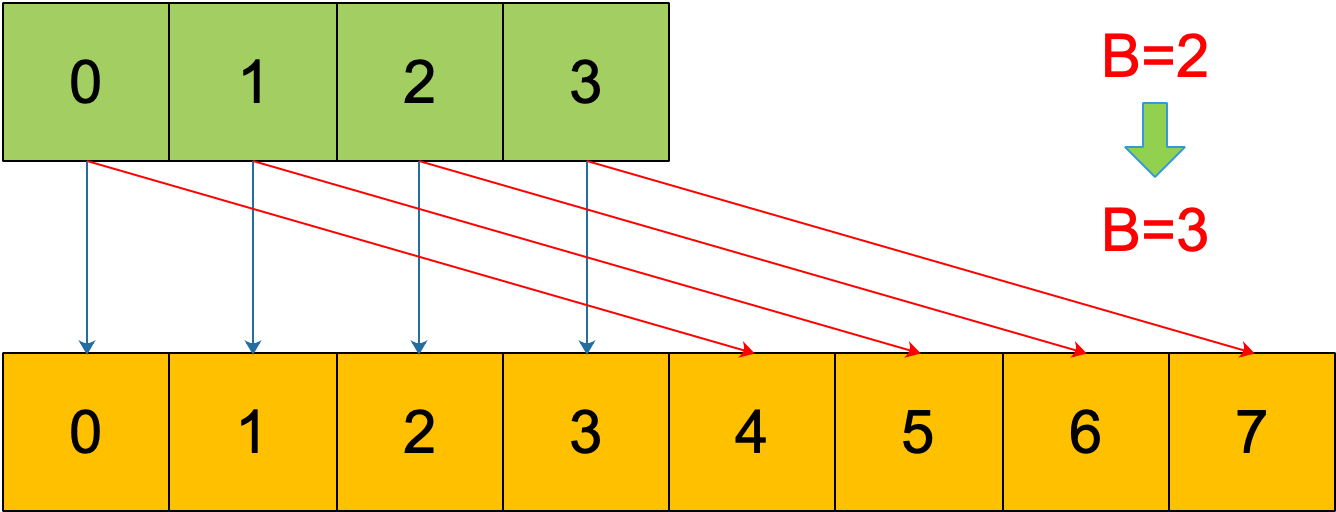
理解了這個,後面講 map 迭代的時候會用到。
再來講搬遷函數中的幾個關鍵點:
evacuate 函數每次只完成一個 bucket 的搬遷工作,因此要遍歷完此 bucket 的所有的 cell,將有值的 cell copy 到新的地方。bucket 還會鏈接 overflow bucket,它們同樣需要搬遷。因此會有 2 層迴圈,外層遍歷 bucket 和 overflow bucket,內層遍歷 bucket 的所有 cell。這樣的迴圈在 map 的源碼里到處都是,要理解透了。
源碼里提到 X, Y part,其實就是我們說的如果是擴容到原來的 2 倍,桶的數量是原來的 2 倍,前一半桶被稱為 X part,後一半桶被稱為 Y part。一個 bucket 中的 key 可能會分裂落到 2 個桶,一個位於 X part,一個位於 Y part。所以在搬遷一個 cell 之前,需要知道這個 cell 中的 key 是落到哪個 Part。很簡單,重新計算 cell 中 key 的 hash,並向前“多看”一位,決定落入哪個 Part,這個前面也說得很詳細了。
有一個特殊情況是:有一種 key,每次對它計算 hash,得到的結果都不一樣。這個 key 就是 math.NaN() 的結果,它的含義是 not a number,類型是 float64。當它作為 map 的 key,在搬遷的時候,會遇到一個問題:再次計算它的哈希值和它當初插入 map 時的計算出來的哈希值不一樣!
你可能想到了,這樣帶來的一個後果是,這個 key 是永遠不會被 Get 操作獲取的!當我使用 m[math.NaN()] 語句的時候,是查不出來結果的。這個 key 只有在遍歷整個 map 的時候,才有機會現身。所以,可以向一個 map 插入任意數量的 math.NaN() 作為 key。
當搬遷碰到 math.NaN() 的 key 時,只通過 tophash 的最低位決定分配到 X part 還是 Y part(如果擴容後是原來 buckets 數量的 2 倍)。如果 tophash 的最低位是 0 ,分配到 X part;如果是 1 ,則分配到 Y part。
這是通過 tophash 值與新算出來的哈希值進行運算得到的:
if top&1 != 0 {
// top hash 最低位為 1
// 新算出來的 hash 值的 B 位置 1
hash |= newbit
} else {
// 新算出來的 hash 值的 B 位置 0
hash &^= newbit
}
// hash 值的 B 位為 0,則搬遷到 x part
// 當 B = 5時,newbit = 32,二進位低 6 位為 10 0000
useX = hash&newbit == 0其實這樣的 key 我隨便搬遷到哪個 bucket 都行,當然,還是要搬遷到上面裂變那張圖中的兩個 bucket 中去。但這樣做是有好處的,在後面講 map 迭代的時候會再詳細解釋,暫時知道是這樣分配的就行。
確定了要搬遷到的目標 bucket 後,搬遷操作就比較好進行了。將源 key/value 值 copy 到目的地相應的位置。
設置 key 在原始 buckets 的 tophash 為 evacuatedX 或是 evacuatedY,表示已經搬遷到了新 map 的 x part 或是 y part。新 map 的 tophash 則正常取 key 哈希值的高 8 位。
下麵通過圖來巨集觀地看一下擴容前後的變化。
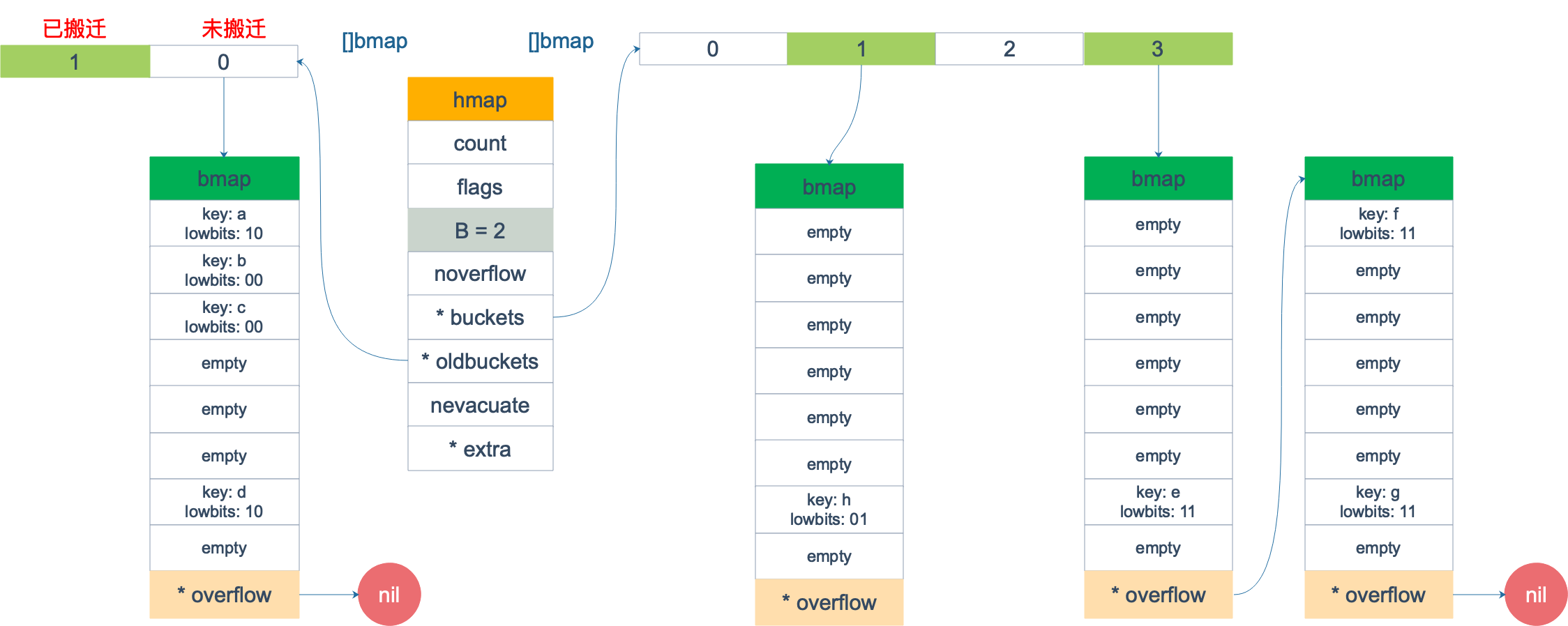
擴容前,B = 2,共有 4 個 buckets,lowbits 表示 hash 值的低位。假設我們不關註其他 buckets 情況,專註在 2 號 bucket。並且假設 overflow 太多,觸發了等量擴容(對應於前面的條件 2)。
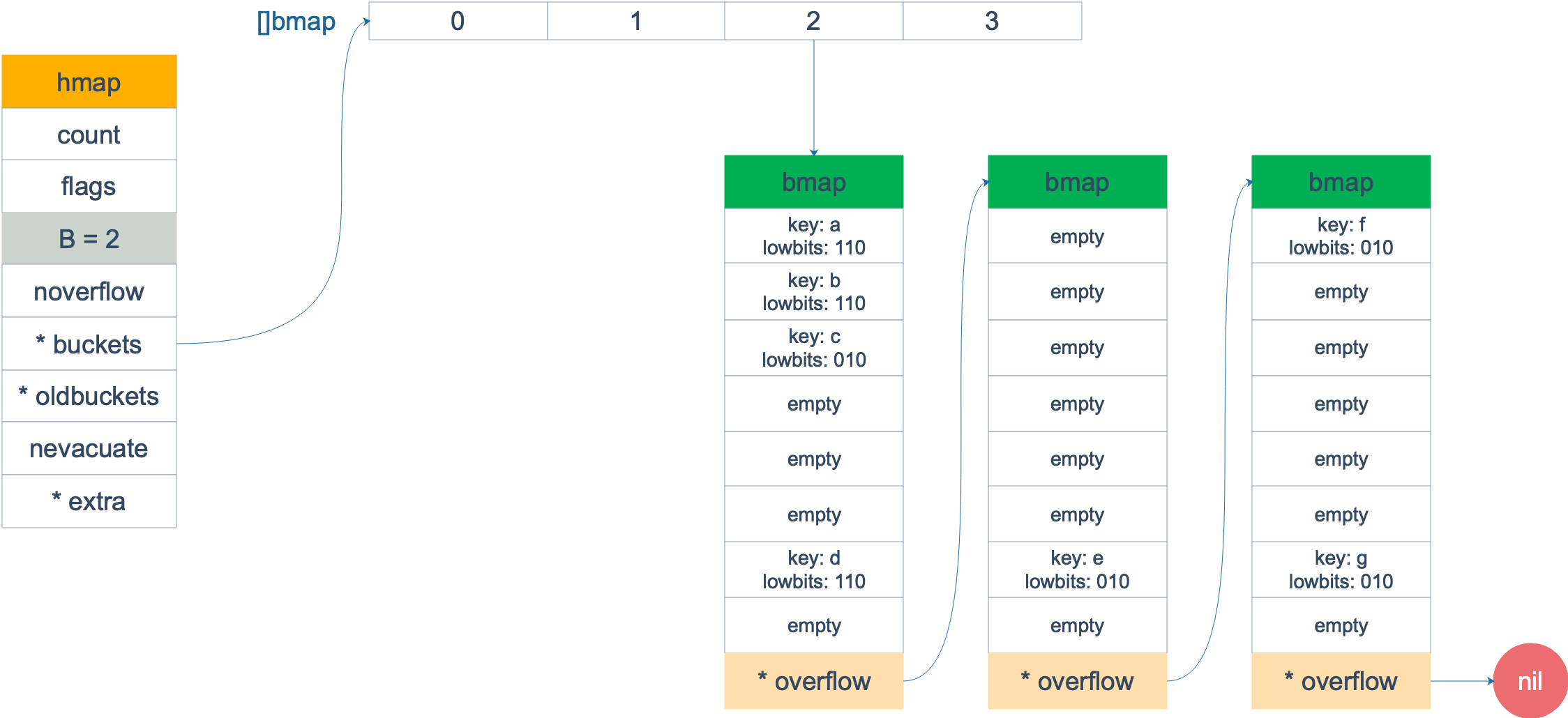
擴容完成後,overflow bucket 消失了,key 都集中到了一個 bucket,更為緊湊了,提高了查找的效率。
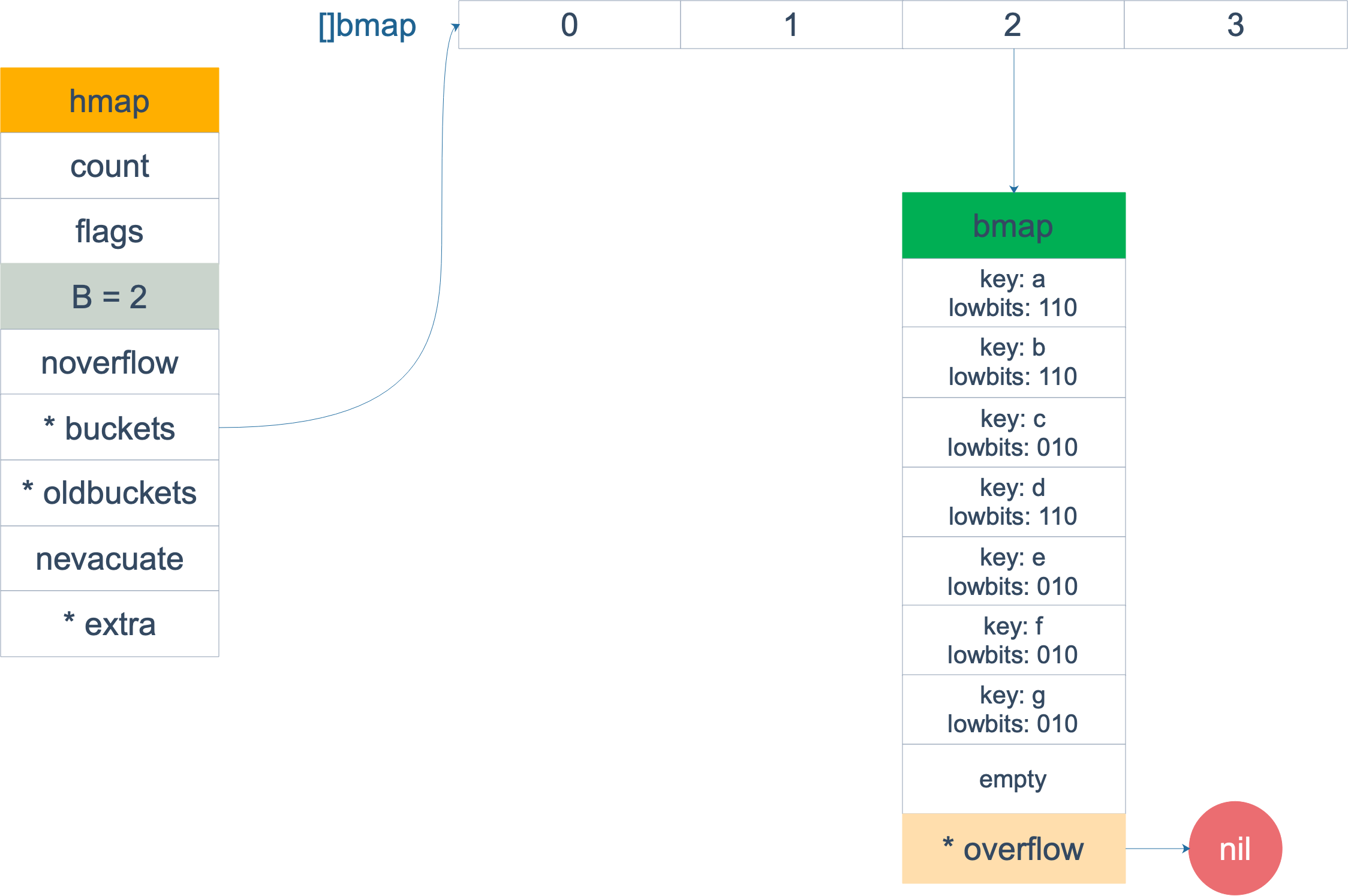
假設觸發了 2 倍的擴容,那麼擴容完成後,老 buckets 中的 key 分裂到了 2 個 新的 bucket。一個在 x part,一個在 y 的 part。依據是 hash 的 lowbits。新 map 中 0-3 稱為 x part,4-7 稱為 y part。
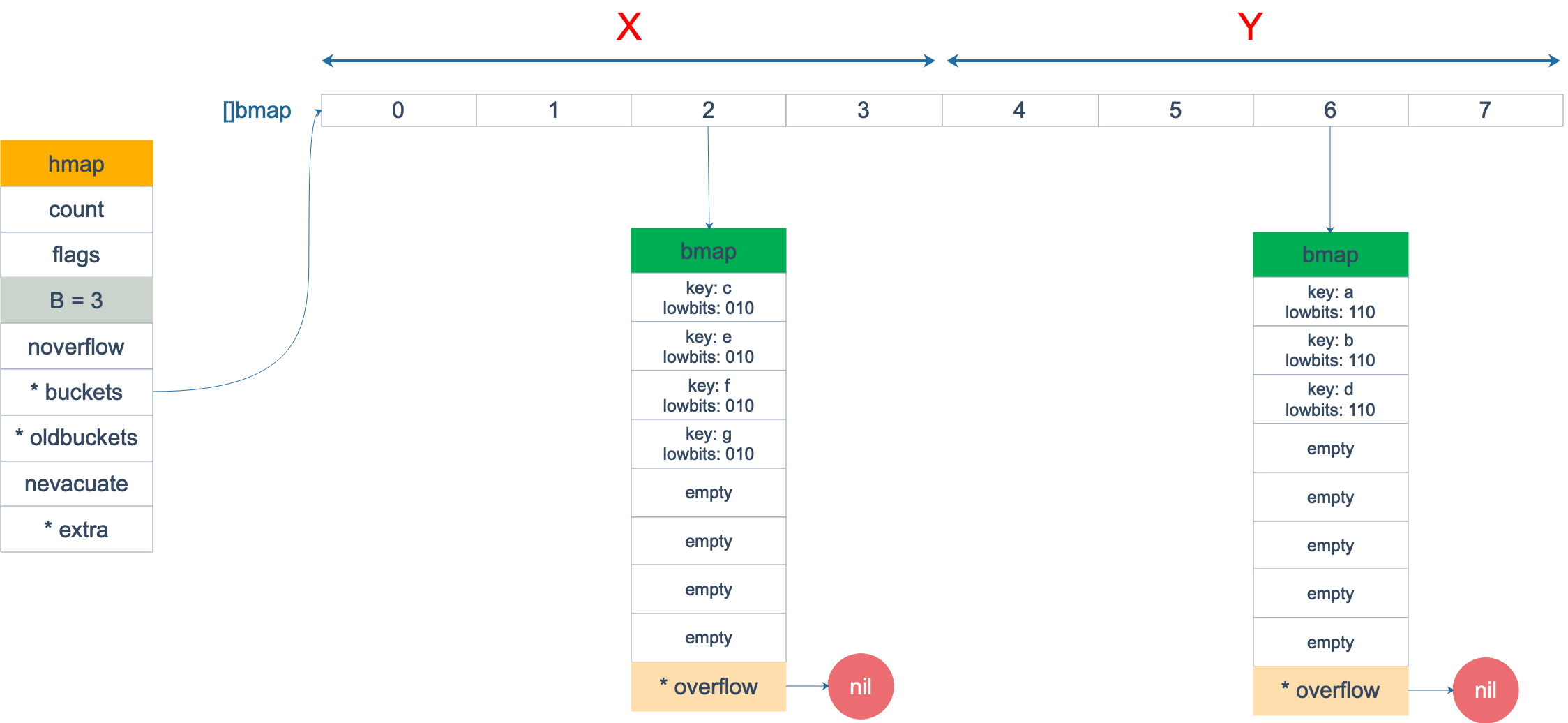
註意,上面的兩張圖忽略了其他 buckets 的搬遷情況,表示所有的 bucket 都搬遷完畢後的情形。實際上,我們知道,搬遷是一個“漸進”的過程,並不會一下子就全部搬遷完畢。所以在搬遷過程中,oldbuckets 指針還會指向原來老的 []bmap,並且已經搬遷完畢的 key 的 tophash 值會是一個狀態值,表示 key 的搬遷去向。
map 的遍歷
本來 map 的遍歷過程比較簡單:遍歷所有的 bucket 以及它後面掛的 overflow bucket,然後挨個遍歷 bucket 中的所有 cell。每個 bucket 中包含 8 個 cell,從有 key 的 cell 中取出 key 和 value,這個過程就完成了。
但是,現實並沒有這麼簡單。還記得前面講過的擴容過程嗎?擴容過程不是一個原子的操作,它每次最多只搬運 2 個 bucket,所以如果觸發了擴容操作,那麼在很長時間里,map 的狀態都是處於一個中間態:有些 bucket 已經搬遷到新家,而有些 bucket 還待在老地方。
因此,遍歷如果發生在擴容的過程中,就會涉及到遍歷新老 bucket 的過程,這是難點所在。
我先寫一個簡單的代碼樣例,假裝不知道遍歷過程具體調用的是什麼函數:
package main
import "fmt"
func main() {
ageMp := make(map[string]int)
ageMp["qcrao"] = 18
for name, age := range ageMp {
fmt.Println(name, age)
}
}執行命令:
go tool compile -S main.go得到彙編命令。這裡就不逐行講解了,可以去看之前的幾篇文章,說得很詳細。
關鍵的幾行彙編代碼如下:
// ......
0x0124 00292 (test16.go:9) CALL runtime.mapiterinit(SB)
// ......
0x01fb 00507 (test16.go:9) CALL runtime.mapiternext(SB)
0x0200 00512 (test16.go:9) MOVQ ""..autotmp_4+160(SP), AX
0x0208 00520 (test16.go:9) TESTQ AX, AX
0x020b 00523 (test16.go:9) JNE 302
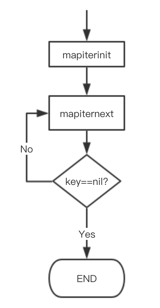
// ......這樣,關於 map 迭代,底層的函數調用關係一目瞭然。先是調用 mapiterinit 函數初始化迭代器,然後迴圈調用 mapiternext 函數進行 map 迭代。
迭代器的結構體定義:
type hiter struct {
// key 指針
key unsafe.Pointer
// value 指針
value unsafe.Pointer
// map 類型,包含如 key size 大小等
t *maptype
// map header
h *hmap
// 初始化時指向的 bucket
buckets unsafe.Pointer
// 當前遍歷到的 bmap
bptr *bmap
overflow [2]*[]*bmap
// 起始遍歷的 bucet 編號
startBucket uintptr
// 遍歷開始時 cell 的編號(每個 bucket 中有 8 個 cell)
offset uint8
// 是否從頭遍歷了
wrapped bool
// B 的大小
B uint8
// 指示當前 cell 序號
i uint8
// 指向當前的 bucket
bucket uintptr
// 因為擴容,需要檢查的 bucket
checkBucket uintptr
}mapiterinit 就是對 hiter 結構體里的欄位進行初始化賦值操作。
前面已經提到過,即使是對一個寫死的 map 進行遍歷,每次出來的結果也是無序的。下麵我們就可以近距離地觀察他們的實現了。
// 生成隨機數 r
r := uintptr(fastrand())
if h.B > 31-bucketCntBits {
r += uintptr(fastrand()) << 31
}
// 從哪個 bucket 開始遍歷
it.startBucket = r & (uintptr(1)<<h.B - 1)
// 從 bucket 的哪個 cell 開始遍歷
it.offset = uint8(r >> h.B & (bucketCnt - 1))例如,B = 2,那 uintptr(1)<<h.B - 1 結果就是 3,低 8 位為 0000 0011,將 r 與之相與,就可以得到一個 0~3 的 bucket 序號;bucketCnt - 1 等於 7,低 8 位為 0000 0111,將 r 右移 2 位後,與 7 相與,就可以得到一個 0~7 號的 cell。
於是,在 mapiternext 函數中就會從 it.startBucket 的 it.offset 號的 cell 開始遍歷,取出其中的 key 和 value,直到又回到起點 bucket,完成遍歷過程。
源碼部分比較好看懂,尤其是理解了前面註釋的幾段代碼後,再看這部分代碼就沒什麼壓力了。所以,接下來,我將通過圖形化的方式講解整個遍歷過程,希望能夠清晰易懂。
假設我們有下圖所示的一個 map,起始時 B = 1,有兩個 bucket,後來觸發了擴容(這裡不要深究擴容條件,只是一個設定),B 變成 2。並且, 1 號 bucket 中的內容搬遷到了新的 bucket,1 號裂變成 1 號和 3 號;0 號 bucket 暫未搬遷。老的 bucket 掛在在 *oldbuckets 指針上面,新的 bucket 則掛在 *buckets 指針上面。
這時,我們對此 map 進行遍歷。假設經過初始化後,startBucket = 3,offset = 2。於是,遍歷的起點將是 3 號 bucket 的 2 號 cell,下麵這張圖就是開始遍歷時的狀態:
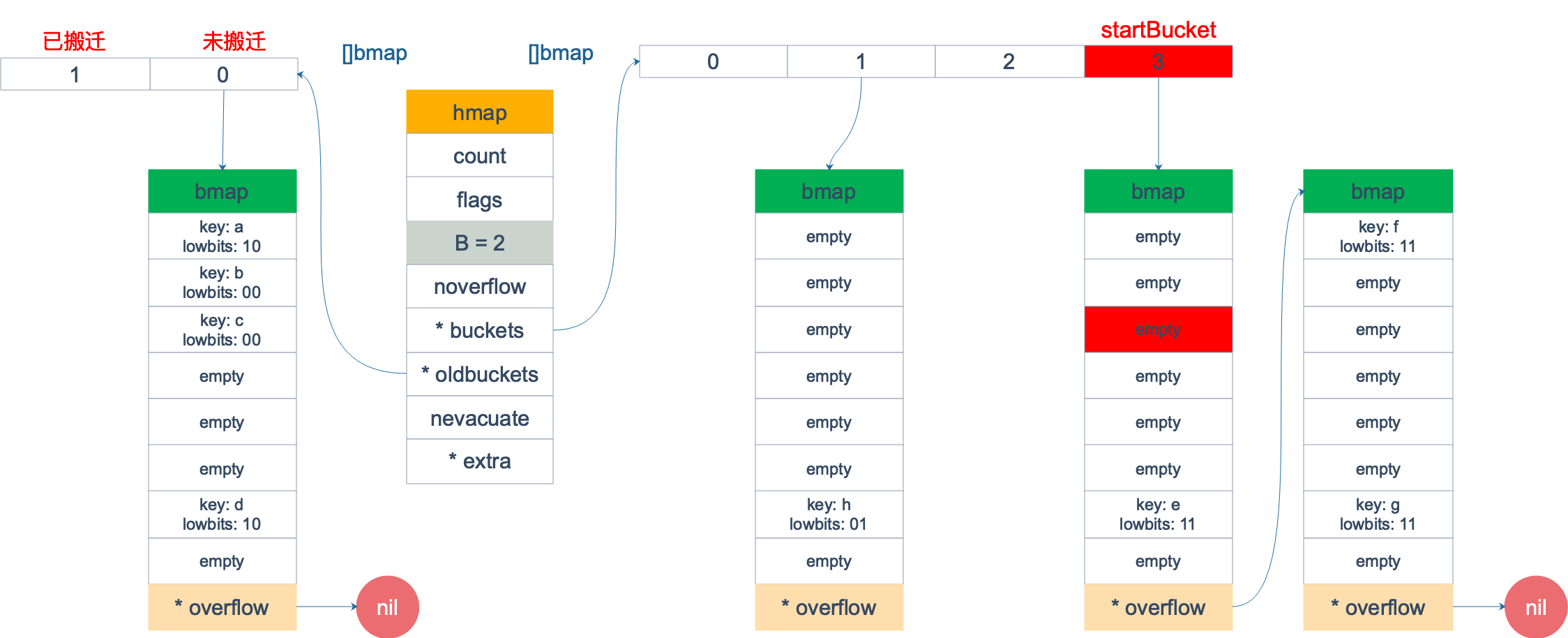
標紅的表示起始位置,bucket 遍歷順序為:3 -> 0 -> 1 -> 2。
因為 3 號 bucket 對應老的 1 號 bucket,因此先檢查老 1 號 bucket 是否已經被搬遷過。判斷方法就是:
func evacuated(b *bmap) bool {
h := b.tophash[0]
return h > empty && h < minTopHash
}如果 b.tophash[0] 的值在標誌值範圍內,即在 (0,4) 區間里,說明已經被搬遷過了。
empty = 0
evacuatedEmpty = 1
evacuatedX = 2
evacuatedY = 3
minTopHash = 4在本例中,老 1 號 bucket 已經被搬遷過了。所以它的 tophash[0] 值在 (0,4) 範圍內,因此只用遍歷新的 3 號 bucket。
依次遍歷 3 號 bucket 的 cell,這時候會找到第一個非空的 key:元素 e。到這裡,mapiternext 函數返回,這時我們的遍歷結果僅有一個元素:

由於返回的 key 不為空,所以會繼續調用 mapiternext 函數。
繼續從上次遍歷到的地方往後遍歷,從新 3 號 overflow bucket 中找到了元素 f 和 元素 g。
遍歷結果集也因此壯大:

新 3 號 bucket 遍歷完之後,回到了新 0 號 bucket。0 號 bucket 對應老的 0 號 bucket,經檢查,老 0 號 bucket 並未搬遷,因此對新 0 號 bucket 的遍歷就改為遍歷老 0 號 bucket。那是不是把老 0 號 bucket 中的所有 key 都取出來呢?
並沒有這麼簡單,回憶一下,老 0 號 bucket 在搬遷後將裂變成 2 個 bucket:新 0 號、新 2 號。而我們此時正在遍歷的只是新 0 號 bucket(註意,遍歷都是遍歷的 *bucket 指針,也就是所謂的新 buckets)。所以,我們只會取出老 0 號 bucket 中那些在裂變之後,分配到新 0 號 bucket 中的那些 key。
因此,lowbits == 00 的將進入遍歷結果集:

和之前的流程一樣,繼續遍歷新 1 號 bucket,發現老 1 號 bucket 已經搬遷,只用遍歷新 1 號 bucket 中現有的元素就可以了。結果集變成:

繼續遍歷新 2 號 bucket,它來自老 0 號 bucket,因此需要在老 0 號 bucket 中那些會裂變到新 2 號 bucket 中的 key,也就是 lowbit == 10 的那些 key。
這樣,遍歷結果集變成:

最後,繼續遍歷到新 3 號 bucket 時,發現所有的 bucket 都已經遍歷完畢,整個迭代過程執行完畢。
順便說一下,如果碰到 key 是 math.NaN() 這種的,處理方式類似。核心還是要看它被分裂後具體落入哪個 bucket。只不過只用看它 top hash 的最低位。如果 top hash 的最低位是 0 ,分配到 X part;如果是 1 ,則分配到 Y part。據此決定是否取出 key,放到遍歷結果集里。
map 遍歷的核心在於理解 2 倍擴容時,老 bucket 會分裂到 2 個新 bucket 中去。而遍歷操作,會按照新 bucket 的序號順序進行,碰到老 bucket 未搬遷的情況時,要在老 bucket 中找到將來要搬遷到新 bucket 來的 key。
map 的賦值
通過彙編語言可以看到,向 map 中插入或者修改 key,最終調用的是 mapassign 函數。
實際上插入或修改 key 的語法是一樣的,只不過前者操作的 key 在 map 中不存在,而後者操作的 key 存在 map 中。
mapassign 有一個系列的函數,根據 key 類型的不同,編譯器會將其優化為相應的“快速函數”。
| key 類型 | 插入 |
|---|---|
| uint32 | mapassign_fast32(t maptype, h hmap, key uint32) unsafe.Pointer |
| uint64 | mapassign_fast64(t maptype, h hmap, key uint64) unsafe.Pointer |
| string | mapassign_faststr(t maptype, h hmap, ky string) unsafe.Pointer |
我們只用研究最一般的賦值函數 mapassign。
整體來看,流程非常得簡單:對 key 計算 hash 值,根據 hash 值按照之前的流程,找到要賦值的位置(可能是插入新 key,也可能是更新老 key),對相應位置進行賦值。
源碼大體和之前講的類似,核心還是一個雙層迴圈,外層遍歷 bucket 和它的 overflow bucket,內層遍歷整個 bucket 的各個 cell。限於篇幅,這部分代碼的註釋我也不展示了,有興趣的可以去看,保證理解了這篇文章內容後,能夠看懂。
我這裡會針對這個過程提幾點重要的。
函數首先會檢查 map 的標誌位 flags。如果 flags 的寫標誌位此時被置 1 了,說明有其他協程在執行“寫”操作,進而導致程式 panic。這也說明瞭 map 對協程是不安全的。
通過前文我們知道擴容是漸進式的,如果 map 處在擴容的過程中,那麼當 key 定位到了某個 bucket 後,需要確保這個 bucket 對應的老 bucket 完成了遷移過程。即老 bucket 里的 key 都要遷移到新的 bucket 中來(分裂到 2 個新 bucket),才能在新的 bucket 中進行插入或者更新的操作。
上面說的操作是在函數靠前的位置進行的,只有進行完了這個搬遷操作後,我們才能放心地在新 bucket 里定位 key 要安置的地址,再進行之後的操作。
現在到了定位 key 應該放置的位置了,所謂找準自己的位置很重要。準備兩個指針,一個(inserti)指向 key 的 hash 值在 tophash 數組所處的位置,另一個(insertk)指向 cell 的位置(也就是 key 最終放置的地址),當然,對應 value 的位置就很容易定位出來了。這三者實際上都是關聯的,在 tophash 數組中的索引位置決定了 key 在整個 bucket 中的位置(共 8 個 key),而 value 的位置需要“跨過” 8 個 key 的長度。
在迴圈的過程中,inserti 和 insertk 分別指向第一個找到的空閑的 cell。如果之後在 map 沒有找到 key 的存在,也就是說原來 map 中沒有此 key,這意味著插入新 key。那最終 key 的安置地址就是第一次發現的“空位”(tophash 是 empty)。
如果這個 bucket 的 8 個 key 都已經放置滿了,那在跳出迴圈後,發現 inserti 和 insertk 都是空,這時候需要在 bucket 後面掛上 overflow bucket。當然,也有可能是在 overflow bucket 後面再掛上一個 overflow bucket。這就說明,太多 key hash 到了此 bucket。
在正式安置 key 之前,還要檢查 map 的狀態,看它是否需要進行擴容。如果滿足擴容的條件,就主動觸發一次擴容操作。
這之後,整個之前的查找定位 key 的過程,還得再重新走一次。因為擴容之後,key 的分佈都發生了變化。
最後,會更新 map 相關的值,如果是插入新 key,map 的元素數量欄位 count 值會加 1;在函數之初設置的 hashWriting 寫標誌出會清零。
另外,有一個重要的點要說一下。前面說的找到 key 的位置,進行賦值操作,實際上並不准確。我們看 mapassign 函數的原型就知道,函數並沒有傳入 value 值,所以賦值操作是什麼時候執行的呢?
func mapassign(t *maptype, h *hmap, key unsafe.Pointer) unsafe.Pointer答案還得從彙編語言中尋找。我直接揭曉答案,有興趣可以私下去研究一下。mapassign 函數返回的指針就是指向的 key 所對應的 value 值位置,有了地址,就很好操作賦值了。
map 的刪除
寫操作底層的執行函數是 mapdelete

