
發佈與訂閱消息系統 在正式討論Apache Kafka (以下簡稱Kafka)之前,先來瞭解發佈與訂閱消息系統的概念, 並認識這個系統的重要性。數據(消息)的發送者(發佈者)不會直接把消息發送給接收 者,這是發佈與訂閱消息系統的一個特點。發佈者以某種方式對消息進行分類,接收者 (訂閱者)訂閱它們,以 ...
發佈與訂閱消息系統
在正式討論Apache Kafka (以下簡稱Kafka)之前,先來瞭解發佈與訂閱消息系統的概念, 並認識這個系統的重要性。數據(消息)的發送者(發佈者)不會直接把消息發送給接收 者,這是發佈與訂閱消息系統的一個特點。發佈者以某種方式對消息進行分類,接收者 (訂閱者)訂閱它們,以便接收特定類型的消息。發佈與訂閱系統一般會有一個 broker,也就是發佈消息的中心點。
發佈與訂閱消息系統的大部分應用場景都是從一個簡單的消息隊列或一個進程間通信開始的。比如電商系統中,包含會員模塊、訂單模塊、商品模塊、推薦模塊、配送物流模塊等,多個模塊(子系統)間涉及消息的傳遞。
最早的應用解決方案就是採用(子系統間)直連的方式,使得很多子系統交錯複雜。這種點對點的連接方式,形成網狀的連接,弊端很多,不一一贅述。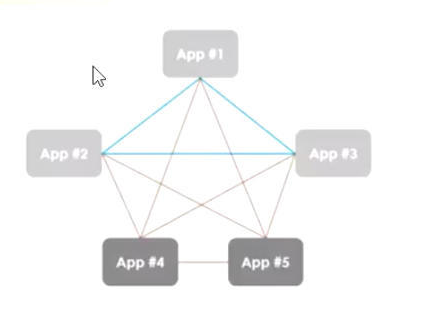
後來,為瞭解決子系統間直連交錯的問題,出現了隊列系統。下圖所示的架構包含了 3 個獨立的發佈與訂閱系統。

這種方式比直接使用點對點的連接要好得多,但這裡有太多重覆的地方。你的公司因此要為數據隊列維護多個系統,每個系統又有各自的缺陷和不足。而且,接下來可能會有更多的場景需要用到消息系統。 此時,你真正需要的是一個單一的集中式系統,它可以用來發佈通用類型的數據,其規模可以隨著公司業務的增長而增長。這時Kafka登場了。
Kafka登場
Kafka就是為瞭解決上述問題而設計的一款基於發佈與訂閱的消息系統。它一般被稱為 “分散式提交日誌”或者“分散式流平臺”。文件系統或資料庫提交日誌用來提供所有事務 的持久記錄 , 通過重放這些日誌可以重建系統的狀態。同樣地, Kafka 的數據是按照 一定順序持久化保存的,可以按需讀取 。 此外, Kafka 的數據分佈在整個系統里,具備數據故障保護和性能伸縮能力。
消息和批次
Kafka的數據單元被稱為消息。如果你在使用 Kafka之前已經有資料庫使用經驗,那麼可 以把消息看成是資料庫里的一個“數據行”或一條“記錄”。消息由位元組數組組成,所以 對於 Kafka來說,消息里的數據沒有特別的格式或含義。消息可以有一個可選的元數據, 也就是鍵(key)。鍵也是一個位元組數組,與消息一樣,對於 Kafka來說也沒有特殊的含義。 當消息以一種可控的方式寫入不同的分區時,會用到鍵。最簡單的例子就是為鍵生成一個一致 性散列值,然後使用散列值對主題分區數進行取模,為消息選取分區 。這樣可 以保證具有 相同鍵的消息總是被寫到相同的分區上。
為了提高效率,消息被分批次寫入 Kafka。 批次就是一組消息,這些消息屬於同一個主題 和分區。如果每一個消息都單獨穿行於網路,會導致大量的網路開銷,把消息分成批次傳 輸可以減少網路開銷。不過,這要在時間延遲和吞吐量之間作出權衡;批次越大,單位時間內處理的消息就越多,單個消息的傳輸時間就越長。批次數據會被壓縮,這樣可以提升 數據的傳輸和存儲能力,但要做更多的計算處理。
主題(topic)和分區(partition)
Kafka 的悄息通過 主題進行分類。主題就好比資料庫的表,或者文件系統里的文件夾。主題可以被分為若幹個分區 , 一個分區就是一個提交日誌。消息以追加的方式寫入分區,然後以先入先出的順序讀取。要註意,由於一個主題一般包含幾個分區,因此無法在整個主題範圍內保證消息的順序,但可以保證消息在單個分區內的順序。下圖 所示的主題有 4 個分區,消息被迫加寫入每個分區的尾部。 Kaflca通過分區來實現數據冗餘和伸縮性。分區可以分佈在不同的伺服器上,也就是說, 一個主題可以橫跨多個伺服器,以此來提供比 單個伺服器更強大的性能。

我們通常會使用流這個詞來描繪Kafka這類系統對數據。很多時候,人們把一個主題的數據看成一個流,不管它有多少個分區。流是一組從生產者移動到消費者的數據。當我們討 論流式處理時,一般都是這樣描述消息的。 Kaflca Streams、 Apache Samza 和 Storm 這些框 架以實時的方式處理消息,也就是所謂的流式處理。我們可以將流式處理與離線處理進行比較,比如 Hadoop 就是被設計用於在稍後某個時刻處理大量的數據。
生產者和消費者
Kafka 的客戶端就是 Kafka 系統的用戶,它們被分為兩種基本類型 : 生產者和消費者。除此之外,還有其他高級客戶端 API——用於數據集成的 Kaflca Connect API 和用於流式處理 的 Kaflca Streams。這些高級客戶端 API 使用生產者和消費者作為內部組件,提供了高級的 功能。
生產者創建消息。在其他發佈與訂閱系統中,生產者可能被稱為發佈者或寫入者。一般情 況下,一個消息會被髮布到一個特定的主題(topic)上。生產者在預設情況下把消息均衡地分佈到主題的所有分區上,而並不關心特定消息會被寫到哪個分區。不過,在某些情況下,生產者會把消息直接寫到指定的分區。這通常是通過消息鍵和分區器來實現的,分區器為鍵生 成一個散列值,並將其映射到指定的分區上。這樣可以保證包含同一個鍵的消息會被寫到 同一個分區上。生產者也可以使用自定義的分區器,根據不同的業務規則將消息映射到分 區。下一章將詳細介紹生產者。
消費者讀取消息。在其他發佈與訂閱系統中,消費者可能被稱為訂閱者或讀者 。 消費者訂閱一個或多個主題,並按照消息生成的順序讀取它們。消費者通過檢查消息的偏移盤來區 分已經讀取過的消息。 偏移量是另一種元數據,它是一個不斷遞增的整數值,在創建消息 時, Kafka 會把它添加到消息里。在給定的分區里,每個悄息的偏移量都是唯 一 的。消費 者把每個分區最後讀取的悄息偏移量保存在 Zookeeper或 Kafka上,如果悄費者關閉或重 啟,它的讀取狀態不會丟失。
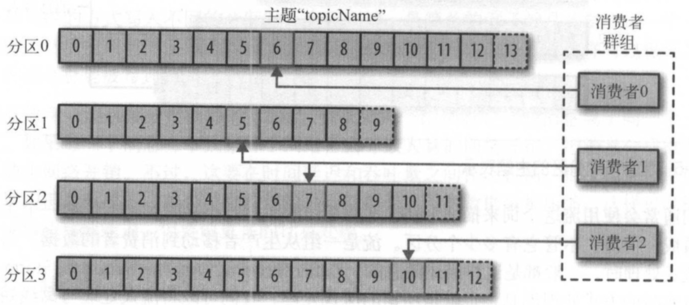
消費者是消費者群組的一部分,也就是說,會有一個或多個消費者共同讀取一個主題。 群組保證每個分區只能被一個消費者使用 。下圖所示的群組中,有 3 個消費者同時讀取一 個主題。其中的兩個消費者各自讀取一個分區,另外一個消費者讀取其他兩個分區。消費 者與分區之間的映射通常被稱為悄費者對分區的所有權關係 。
通過這種方式,消費者可以消費包含大量消息的主題。而且,如果一個消費者失效,群組 里的其他消費者可以接管失效悄費者的工作。第 4章將詳細介紹消費者和悄費者群組。
broker和集群
一個獨立的 Kafka伺服器被稱為 broker。 broker接收來自 生產者的消息,為消息設置偏移 量,並提交消息到磁碟保存。 broker 為消費者提供服務,對讀取分區的請求作出響應,返 回已經提交到磁碟上的消息。根據特定的硬體及其性能特征,單個 broker可以輕鬆處理數 千個分區以及每秒百萬級的消息量。
Broker可以看作是消息中間件處理節點,一個Kafka節點就是一個broker,一個或者多個Broker可以組成一個Kafka集群。
broker是集群的組成部分。每個集群都有一個 broker 同時充當了集群控制器的角色(自動 從集群的活躍成員中選舉出來)。控制器負責管理工作,包括將分區分配給 broker和監控 broker. 在集群中, 一個分區從屬於一個 broker, i亥 broker被稱為分區的首領。一個分區 可以分配給多個 broker,這個時候會發生分區複製(見下圖)。這種複製機製為分區提供 了消息冗餘,如果有一個 broker失效,其他 broker可以接管領導權。不過,相關的消費者 和生產者都要重新連接到新的首領。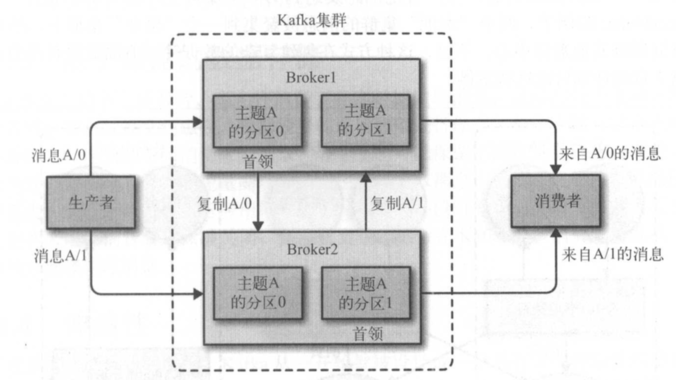
保留消息(在一定期限內)是 Kafka的一個重要特性。 Kafka broker預設的消息保留策略 是這樣的:要麼保留一段時間(比如 7天),要麼保留到消息達到一定大小的位元組數(比 如 1GB)。當消息數量達到這些上限時,舊消息就會過期井被刪除,所以在任何時刻, 可 用消息的總量都不會超過配置參數所指定的大小。主題可以配置自己的保留策略,可以將 悄息保留到不再使用它們為止。例如,用於跟蹤用戶活動的數據可能需要保留幾天,而應 用程式的度量指標可能只需要保留幾個小時。可以通過配置把主題當作 緊湊型日誌, 只有 最後一個帶有特定鍵的消息會被保留下來。這種情況對於變更日誌類型的數據來說比較適 用,因為人們只關心最後時刻發生的那個變更。
為什麼選擇 Kafka
多個生產者
Kafka 可以無縫地支持多個生產者,不管客戶端在使用單個 主題還是多個主題。所以它很 適合用來從多個前端系統收集數據,並以統一的格式對外提供數據。例如, 一個包含了 多 個微服務的網站,可以為頁面視圖創建一個單獨的主題,所有服務都以相同的消息格式向 該主題寫入數據。消費者應用程式會獲得統一的頁面視圖,而無需協調來自不同生產者的 數據流。
多個消費者
除了支持多個生產者外, Kafka也支持多個消費者從一個單獨的消息流上讀取數據,而且 消費者之間直不影響。這與其他隊列系統不同,其他隊列系統的消息一旦被一個客戶端讀 取,其他客戶端就無法再讀取它。另外,多個消費者可以組成一個群組,它們共用一個消息流,並保證整個群組對每個給定的消息只處理一次。
基於磁碟的數據存儲
Kafka不僅支持多個消費者,還允許消費者非實時地讀取消息,這要歸功於 Kafka的數據 保留特性。?肖息被提交到磁碟,根據設置的保留規則進行保存。每個主題可以設置單獨的 保留規則,以便滿足不同消費者的需求,各個主題可以保留不同數量的消息。消費者可能 會因為處理速度慢或突發的流量高峰導致無陸及時讀取消息,而持久化數據可以保證數據 不會丟失。?肖費者可以在進行應用程式維護時離線一小段時間,而無需擔心消息丟失或堵 塞在生產者端。 消費者可以被關閉,但消息會繼續保留在 Kafka里。消費者可以從上次中 斷的地方繼續處理消息。
伸縮性
為了能夠輕鬆處理大量數據, Kafka 從一開始就被設計成一個具有靈活伸縮性的系統。用 戶在開發階段可以先使用單個 broker,再擴展到包含 3 個 broker 的小型開發集群,然後隨 著數據鹽不斷增長,部署到生產環境的集群可能包含上百個 broker。對線上集群進行擴展 絲毫不影響整體系統的可用性。也就是說, 一個包含多個 broker的集群,即使個別 broker 失效,仍然可以持續地為客戶提供服務。要提高集群的容錯能力,需要配置較高的複製系 數。
高性能
上面提到的所有特性,讓 Kafka成為了一個高性能的發佈與訂閱消息系統。通過橫向擴展 生產者、消費者和 broker, Kafka可以輕鬆處理巨大的消息流。在處理大量數據的同時, 它還能保證亞秒級的消息延遲。


