
1. 內容大綱 1. 自定義模塊 2. 模塊是什麼? 3. 為什麼要有模塊? 什麼是腳本? 4. 模塊的分類 5. import的使用 第一次導入模塊執行三件事 被導入模塊有獨立的名稱空間 為模塊起別名 導入多個模塊 6. from ... import ... from ... import .. ...
內容大綱
- 自定義模塊
- 模塊是什麼?
- 為什麼要有模塊?
- 什麼是腳本?
- 模塊的分類
- import的使用
- 第一次導入模塊執行三件事
- 被導入模塊有獨立的名稱空間
- 為模塊起別名
- 導入多個模塊
- from ... import ...
- from ... import ...的使用
- from ... import ... 與import對比
- 一行導入多個
- from ... import *
- 模塊迴圈導入的問題
- py文件的兩種功能
- 模塊的搜索路徑
- json pickle 模塊
- hashlib模塊
具體內容
自定義模塊:自定義模塊名不能與內置模塊名重名。
模塊是什麼?
將20萬行代碼全部放在一個py文件中?為什麼不行?
- 代碼太多,讀取代碼耗時太長.
2. 代碼不容易維護.
將相同的功能封裝到一個文件中,這個存儲著很多常用的功能的py文件,就是模塊。 模塊就是文件,存放一堆常用的函數,誰用誰拿。一個函數就是一個功能,把一些常用的函數放在一個py文件中,這個文件就稱之為模塊。模塊就是一些常用功能的集合體。
模塊就是一個py文件,是常用的相似功能的集合.
- 代碼太多,讀取代碼耗時太長.
為什麼要使用模塊?
- 拿來主義,提高開發效率.
便於管理維護.
- 什麼是腳本?
- 腳本就是py文件,長期保存代碼的文件.
模塊的分類:
內置模塊,也叫做標準庫。此類模塊就是python解釋器給你提供的,比如我們之前見過的time模塊,os模塊。標準庫的模塊非常多(200多個,每個模塊又有很多功能)
第三方模塊,第三方庫。一些python大神寫的非常好用的模塊,必須通過pip install 指令安裝的模塊,比如BeautfulSoup, Django,等等。大概有6000多個。
自定義模塊,我們自己在項目中定義的一些模塊。自己寫的一個py文件。定義一個模塊其實很簡單就是寫一個文件,裡面寫一些代碼(變數,函數)即可
# xxx.py (自定義模塊) #print('from the xxx.py') name = '太白金星' def read1(): print('xxx模塊:',name) def read2(): print('xxx模塊') read1() def change(): global name name = 'barry' print(name)
import的使用: 註意:引用模塊寫在最上面,不要寫在函數里。
import 模塊 先要怎麼樣?
import xxx 執行一次xxx這個模塊裡面的所有代碼
模塊可以包含可執行的語句和函數的定義,這些語句的目的是初始化模塊,它們只在模塊名第一次遇到導入import語句時才執行。
import語句是可以在程式中的任意位置使用的,且針對同一個模塊import多次,為了防止你重覆導入,python的優化手段是:第一次引用某個模塊,會將這個模塊裡面的所有代碼載入到記憶體,只要你的程式沒有結束,接下來你在引用多少次,它會先從記憶體中尋找有沒有此模塊,如果已經載入到記憶體,就不在重覆載入。後續的import語句僅是對已經載入到記憶體中的模塊對象增加了一次引用,不會重新執行模塊內的語句。
第一次導入模塊執行三件事
***在記憶體中創建一個以被導入模塊名命名的名稱空間.(一個py文件有一個名稱空間)
執行此名稱空間所有的可執行代碼(將xxx.py文件中所有的變數與值的對應關係載入到這個名稱空間).
通過 模塊名. 的方式引用模塊裡面的內容(變數,函數名,類名等)。 ps:重覆導入會直接引用記憶體中已經載入好的結果
import xxx print(xxx.name) xxx.read1()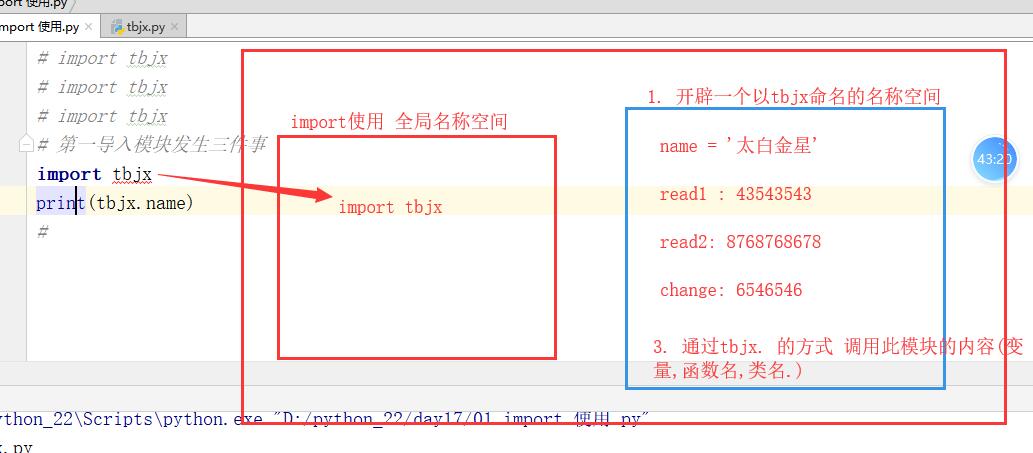
被導入模塊有獨立的名稱空間
***被導入模塊有獨立的名稱空間,它只能操作自己空間中的所有內容,不能操作導入該模塊的py文件中的內容。每個模塊都是一個獨立的全局名稱空間,用來定義這個模塊中的函數,把這個模塊的名稱空間當做全局名稱空間,這樣我們在編寫自己的模塊時,就不用擔心我們定義在自己模塊中全局變數在被導入時,會與使用者的全局變數衝突。 從基本概念來說, 一個名稱空間就是一個從名稱到對象的關係映射集合。 我們已經明確地知道, 模塊名稱是它們的屬性名稱中的一個重要部分。 例如string 模塊中的 atoi() 函數就是 string.atoi() 。給定一個模塊名之後, 只可能有一個模塊被導入到 Python 解釋器中, 所以在不同模塊間不會出現名稱交叉現象; 所以每個模塊都定義了它自己的唯一的名稱空間。 如果我在我自己的模塊 mymodule 里創建了一個 atoi() 函數, 那麼它的名字應該是 mymodule.atoi() 。 所以即使屬性之間有名稱衝突, 但它們的完整授權名稱(fullyqualified name)——通過句點屬性標識指定了各自的名稱空間 - 防止了名稱衝突的發生。 # import xxx name = 'alex' print(name) print(xxx.name) #結果: alex 太白金星 # import xxx def read1(): print(666) xxx.read1() #結果: xxx模塊: 太白金星 # import xxx name = '日天' xxx.change() #barry print(name) # 日天 print(xxx.name) # barry
為模塊起別名
**1 簡單,便捷,將長的模塊名改為短的模塊名
import xxx as m print(m.name) #結果: 太白金星2,有利於代碼的簡化.
# 原始寫法: result = input('請輸入') if result == 'mysql': import mysql1 mysql1.mysql() elif result == 'oracle': import oracle1 oracle1.oracle() # 起別名: result = input('請輸入') if result == 'mysql': import mysql1 as m elif result == 'oracle': import oracle1 as m ''' 後面還有很多''' m.db() # 統一介面,歸一化思想
導入多個模塊:多行導入,易於閱讀 ,易於編輯 ,易於搜索 ,易於維護。
import time, os, sys # 這樣寫不好 # 應該向以下這種寫法: import time import os import sys
from ... import ...
from ... import ...的使用
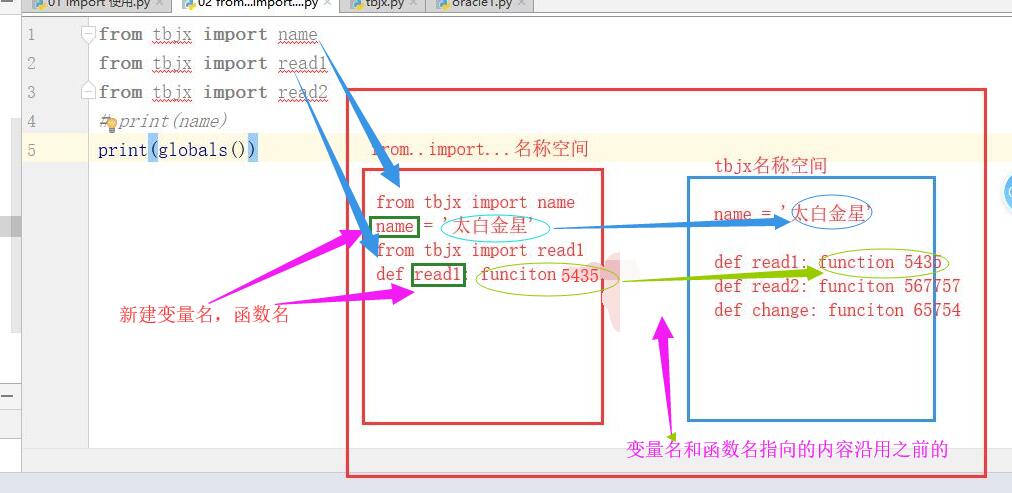
from xxx import name from xxx import read1 from xxx import read2 print(name)#太白金星 print(globals()) read1()#xxx模塊: 太白金星from ... import ... 與import對比
***from.. import 用起來更方便,在當前名稱空間中,直接使用名字就可以了,無需加首碼:xxx.
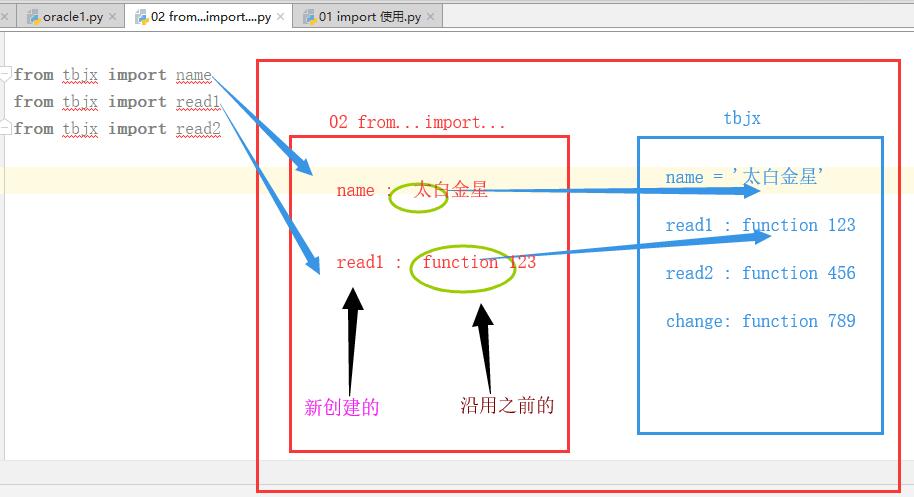
from xxx import name print(name)from...import 容易與當前執行文件中的名字產生衝突.
# 容易產生衝突,後者將前者覆蓋。執行文件有與模塊同名的變數或者函數名,會有覆蓋效果 name = 'alex' from xxx import name print(name)#太白金星當前位置直接使用read1和read2,執行時,仍然以xxx.py文件全局名稱空間
***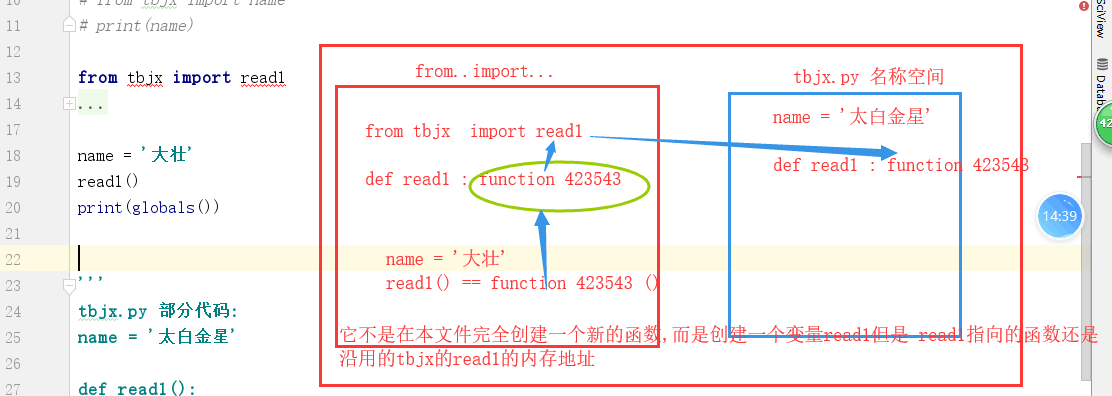
# from xxx import read1 def read1(): print(666) read1()#666 # from xxx import read1 name = '大壯' read1()#xxx模塊: 太白金星 print(globals()) # from xxx import change name = 'Alex' print(name) # 'Alex' change() # 'barry' from xxx import name print(name)#barry from xxx import change name = 'Alex' print(name) # 'Alex' change() # 'barry' print(name) # 'Alex'
一行導入多個
from tbjx import name,read1,read2 # 這樣不好 from tbjx import name from tbjx import read1from ... import *
把xxx.py中所有的不是以下劃線(_)開頭的名字都導入到當前位置,大部分情況下我們的python程式不應該使用這種導入方式,因為*你不知道你導入什麼名字,很有可能會覆蓋掉你之前已經定義的名字。而且可讀性極其的差。一般千萬別麽這寫,必須要將這個模塊中的所有名字全部記住.但是可以配合一個變數使用
# xxx.py __all__ = ['name', 'read1'] # 配合*使用 註:沒寫到__all__中的變數,可以單獨引用 name = '太白金星' def read1(): print('tbjx模塊:', name) def read2(): print('tbjx模塊') read1() def change(): global name name = 'barry' print(name)
模塊迴圈導入的問題:模塊迴圈/嵌套導入拋出異常的根本原因是由於在python中模塊被導入一次之後,就不會重新導入,只會在第一次導入時執行模塊內代碼。在我們的項目中應該儘量避免出現迴圈/嵌套導入,如果出現多個模塊都需要共用的數據,可以將共用的數據集中存放到某一個地方。當程式出現了迴圈/嵌套導入後的異常分析、解決方法如下(瞭解,以後儘量避免)
#創建一個m1.py print('正在導入m1') from m2 import y x='m1' #創建一個m2.py print('正在導入m2') from m1 import x y='m2' #創建一個run.py import m1 #測試一 執行run.py會拋出異常 正在導入m1 正在導入m2 Traceback (most recent call last): File "/Users/linhaifeng/PycharmProjects/pro01/1 aaaa練習目錄/aa.py", line 1, in <module> import m1 File "/Users/linhaifeng/PycharmProjects/pro01/1 aaaa練習目錄/m1.py", line 2, in <module> from m2 import y File "/Users/linhaifeng/PycharmProjects/pro01/1 aaaa練習目錄/m2.py", line 2, in <module> from m1 import x ImportError: cannot import name 'x' #測試一結果分析 先執行run.py--->執行import m1,開始導入m1並運行其內部代碼--->列印內容"正在導入m1"--->執行from m2 import y 開始導入m2並運行其內部代碼--->列印內容“正在導入m2”--->執行from m1 import x,由於m1已經被導入過了,所以不會重新導入,所以直接去m1中拿x,然而x此時並沒有存在於m1中,所以報錯 #測試二:執行文件不等於導入文件,比如執行m1.py不等於導入了m1 直接執行m1.py拋出異常 正在導入m1 正在導入m2 正在導入m1 Traceback (most recent call last): File "/Users/linhaifeng/PycharmProjects/pro01/1 aaaa練習目錄/m1.py", line 2, in <module> from m2 import y File "/Users/linhaifeng/PycharmProjects/pro01/1 aaaa練習目錄/m2.py", line 2, in <module> from m1 import x File "/Users/linhaifeng/PycharmProjects/pro01/1 aaaa練習目錄/m1.py", line 2, in <module> from m2 import y ImportError: cannot import name 'y' #測試二分析 執行m1.py,列印“正在導入m1”,執行from m2 import y ,導入m2進而執行m2.py內部代碼--->列印"正在導入m2",執行from m1 import x,此時m1是第一次被導入,執行m1.py並不等於導入了m1,於是開始導入m1並執行其內部代碼--->列印"正在導入m1",執行from m1 import y,由於m1已經被導入過了,所以無需繼續導入而直接問m2要y,然而y此時並沒有存在於m2中所以報 # 解決方法: 方法一:導入語句放到最後 #m1.py print('正在導入m1') x='m1' from m2 import y #m2.py print('正在導入m2') y='m2' from m1 import x 方法二:導入語句放到函數中 #m1.py print('正在導入m1') def f1(): from m2 import y print(x,y) x = 'm1' # f1() #m2.py print('正在導入m2') def f2(): from m1 import x print(x,y y = 'm2' #run.py import m1 m1.f1()py文件的兩種功能:
自己使用, 當做腳本,一個文件就是整個程式,用來被執行
被別人引用 ,當做模塊使用,文件中存放著一堆功能,用來被導入使用
python為我們內置了全局變數__name__ #用來控制.py文件在不同的應用場景下執行不同的邏輯 print(__name__) 當tbjx.py做腳本: __name__ == __main__ 返回True 當tbjx.py做模塊被別人引用時: __name__ == xxx(模塊名) # __name__ 根據文件的扮演的角色(腳本,模塊)不同而得到不同的結果 1, 模塊需要調試時,加上 if __name__ == '__main__': change() # 測試代碼 if __name__ == '__main__': change() 2, 作為項目的啟動文件需要用.
- 模塊的搜索路徑
***
- 模塊的搜索路徑
#import abc abc也是一個內置模塊
# python 解釋器會自動將一些內置內容(內置函數,內置模塊等等)載入到記憶體中
import sys
print(sys.modules) # 內置內容(內置函數,內置模塊等等)
print(sys.path)
#['D:\\python_22\\day17', 'C:\\Python\\Python36\\python36.zip', 'C:\\Python\\Python36\\DLLs', 'C:\\Python\\Python36\\lib', 'C:\\Python\\Python36', 'C:\\Python\\Python36\\lib\\site-packages']
# 'D:\\python_22\\day17' 路徑是當前執行文件的相對路徑
#要想導入dz.py模塊: 記憶體中沒有,內置模塊也沒有,這兩個你左右不了,但是sys.path你可以操作.
import sys
sys.path.append(r'D:\python_22\day16') # sys.path 會自動將你的 當前目錄的路徑載入到列表中. D:\python_22\day16 是dz.py的相對路徑
import dz
# 如果你想要引用你自定義的模塊:
要不你就將這個模塊放到當前目錄下麵,要不你就手動添加到sys.path
模塊的查找順序:
Python中引用模塊是按照一定的規則以及順序去尋找的,這個查詢順序為:先從記憶體中已經載入的模塊進行尋找,找不到再從內置模塊中尋找,內置模塊如果也沒有,最後去sys.path中路徑包含的模塊中尋找。它只會按照這個順序從這些指定的地方去尋找,如果最終都沒有找到,那麼就會報錯。
註意的是:我們自定義的模塊名不應該與系統內置模塊重名
json pickle 模塊
序列化模塊: 將一種數據結構(list,tuple,dict ....)轉化成特殊的序列。並且這個特殊的序列還可以反解回去。它的主要用途:文件讀寫數據,網路傳輸數據。json pickle shelve
為什麼存在序列化?
數據 ----> bytes
只有字元串類型和bytes可以互換.
dict,list..... -------> str <--------> bytes
數據存儲在文件中,str(bytes類型)形式存儲,比如字典.
數據通過網路傳輸(bytes類型),str 不能還原回去.
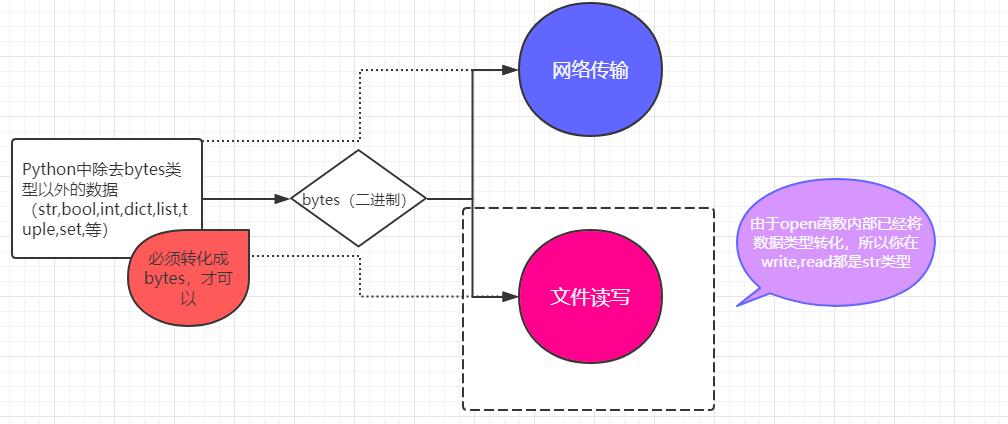
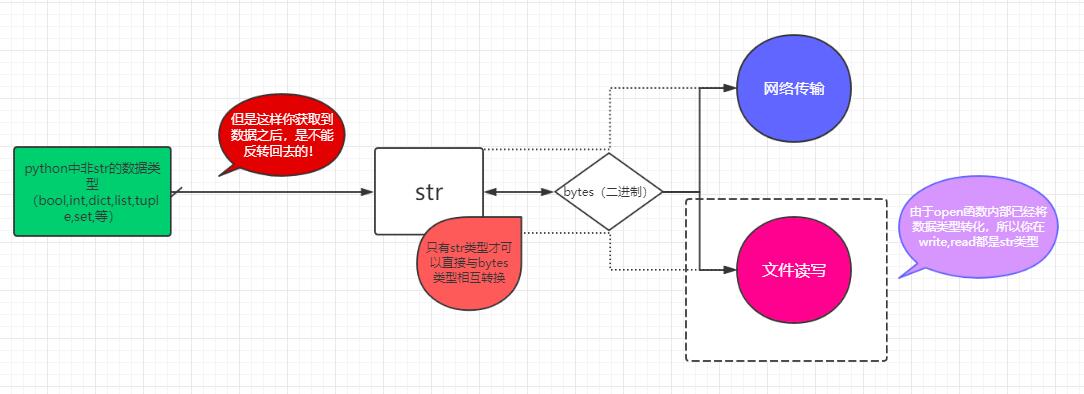
特殊的字元串:將一種數據結構(如字典、列表)等轉換成一個特殊的序列(字元串或者bytes)的過程就叫做序列化。如果你寫入文件中的字元串是一個序列化後的特殊的字元串,那麼當你從文件中讀取出來,是可以轉化回原數據結構的。
序列化模塊:
json模塊 : (重點)
不同語言都遵循的一種數據轉化格式,即不同語言都使用的特殊字元串。(比如Python的一個列表[1, 2, 3]利用json轉化成特殊的字元串,然後在編碼成bytes發送給php的開發者,php的開發者就可以解碼成特殊的字元串,然後在反解成原數組(列表): [1, 2, 3])
json序列化只支持部分Python數據結構:dict,list, tuple,str,int, float,True,False,None
json模塊是將滿足條件的數據結構轉化成特殊的字元串,並且也可以反序列化還原回去。序列化模塊總共只有兩種用法,要不就是用於網路傳輸的中間環節,要不就是文件存儲的中間環節,所以json模塊總共就有兩對四個方法:
用於網路傳輸:dumps、loads
用於文件寫讀:dump、load
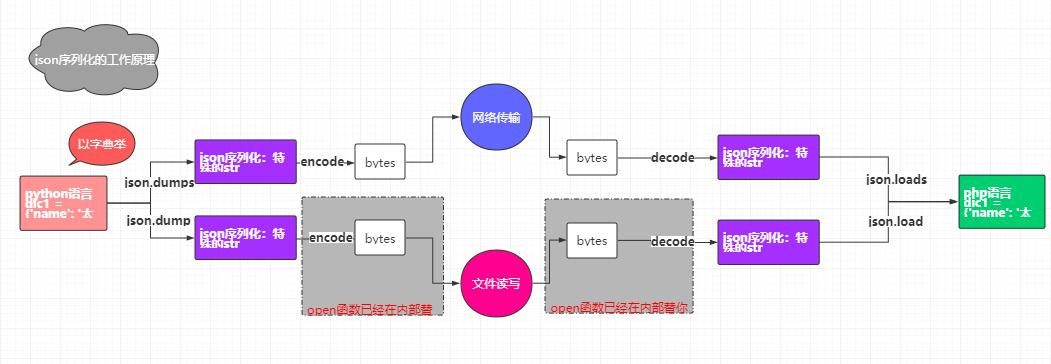
dumps loads 主要用於網路傳輸,但是也可以讀寫文件,但一般用dump,load讀寫文件
import json
dic = {'username': '太白', 'password': 123,'status': True}
# 轉化成特殊的字元串
st = json.dumps(dic)
print(st,type(st))#{"username": "\u592a\u767d", "password": 123, "status": true} <class 'str'>
st = json.dumps(dic,ensure_ascii=False) #不使用ASCII,使用Unicode,可以顯示中文
print(st,type(st))#{"username": "太白", "password": 123, "status": true} <class 'str'>
#註意,json轉換完的字元串類型的字典中的字元串是由""表示的
#反轉回去
dic1 = json.loads(st)
print(dic1,type(dic1))#{'username': '太白', 'password': 123, 'status': True} <class 'dict'>
# 寫入文件
l1 = [1, 2, 3, {'name': 'alex'}]#也可以處理嵌套的數據類型
# 轉化成特殊的字元串寫入文件
with open('json文件',encoding='utf-8',mode='w') as f1:
st = json.dumps(l1) #先轉化成特殊的字元串
f1.write(st)
# 讀取出來還原回去
with open('json文件',encoding='utf-8') as f2:
st = f2.read()
l1 = json.loads(st)
print(l1,type(l1))#[1, 2, 3, {'name': 'alex'}] <class 'list'>
# 特殊的參數:
ensure_ascii:,當它為True的時候,所有非ASCII碼字元顯示為\uXXXX序列,只需在dump時將ensure_ascii設置為False即可,此時存入json的中文即可正常顯示。 separators:分隔符,實際上是(item_separator, dict_separator)的一個元組,預設的就是(‘,’,’:’);這表示dictionary內keys之間用“,”隔開,而KEY和value之間用“:”隔開。 sort_keys:將數據根據keys的值進行排序。 剩下的自己看源碼研究
dump load 只能用於寫入文件,只能寫入一個數據結構
import json
l1 = [1, 2, 3, {'name': 'alex'}]
with open('json文件1.json',encoding='utf-8',mode='w') as f1: # json文件也是文件,就是專門存儲json字元串的文件。
json.dump(l1,f1) # dump方法接收一個文件句柄,直接將l1轉換成json字元串寫入文件
# 讀取數據
with open('json文件1.json',encoding='utf-8') as f2:
l1 = json.load(f2)# load方法接收一個文件句柄,直接將文件中的json字元串轉換成數據結構返回
print(l1,type(l1))#[1, 2, 3, {'name': 'alex'}] <class 'list'>
# 一次寫入文件多個數據怎麼做?
# 錯誤示例:
dic1 = {'username': 'alex'}
dic2 = {'username': '太白'}
dic3 = {'username': '大壯'}
# 寫入數據
with open('json文件1',encoding='utf-8',mode='w') as f1:
json.dump(dic1,f1)
json.dump(dic2,f1)
json.dump(dic3,f1)
# 讀取數據
with open('json文件1',encoding='utf-8') as f1:
print(json.load(f1))#報錯
print(json.load(f1))#報錯
print(json.load(f1))#報錯
# 正確寫法: 用 dumps loads
dic1 = {'username': 'alex'}
dic2 = {'username': '太白'}
dic3 = {'username': '大壯'}
with open('json文件1',encoding='utf-8',mode='w') as f1:
f1.write(json.dumps(dic1) + '\n')
f1.write(json.dumps(dic2) + '\n')
f1.write(json.dumps(dic3) + '\n')
with open('json文件1',encoding='utf-8') as f1:
for i in f1:
print(json.loads(i))
#結果:
{'username': 'alex'}
{'username': '太白'}
{'username': '大壯'}
pickle模塊:
只能是Python語言遵循的一種數據轉化格式,只能在python語言中使用。
支持Python所有的數據類型,包括實例化對象。pickle模塊是將Python所有的數據結構以及對象等轉化成bytes類型,然後還可以反序列化還原回去。
- 用於網路傳輸:dumps、loads
- 用於文件寫讀:dump、load

l1 = [1, 2, 3, {'name': 'alex'}]
dumps loads 只能用於網路傳輸,不能寫入文件
import pickle
st = pickle.dumps(l1)
print(st) # bytes類型 b'\x80\x03]q\x00(K\x01K\x02K\x03}q\x01X\x04\x00\x00\x00nameq\x02X\x04\x00\x00\x00alexq\x03se.'
l2 = pickle.loads(st)
print(l2,type(l2))#[1, 2, 3, {'name': 'alex'}] <class 'list'>
# 還可以序列化對象
import pickle
def func():
print(666)
ret = pickle.dumps(func)
print(ret,type(ret)) # b'\x80\x03c__main__\nfunc\nq\x00.' <class 'bytes'>
f1 = pickle.loads(ret) # f1得到 func函數的記憶體地址
f1() # 執行func函數
dump load 直接寫入文件,可以一次寫入多個數據
#pickle序列化存儲多個數據到一個文件中
import pickle
dic1 = {'name':'oldboy1'}
dic2 = {'name':'oldboy2'}
dic3 = {'name':'oldboy3'}
f = open('pick多數據',mode='wb')
pickle.dump(dic1,f)
pickle.dump(dic2,f)
pickle.dump(dic3,f)
f.close()
import pickle
f = open('pick多數據',mode='rb')
print(pickle.load(f))
print(pickle.load(f))
print(pickle.load(f))
f.close()
#結果:
{'name': 'oldboy1'}
{'name': 'oldboy2'}
{'name': 'oldboy3'}
#或者:
f = open('pick多數據',mode='rb')
while True:
try:
print(pickle.load(f))
except EOFError:
break
f.close()
#結果:
{'name': 'oldboy1'}
{'name': 'oldboy2'}
{'name': 'oldboy3'}
#可以序列化對象(寫入函數名)
import pickle
def func():
print('in func')
f = open('pick對象',mode='wb')
pickle.dump(func,f) #註意參數順序 函數名func,文件句柄
f.close()
f = open('pick對象', mode='rb')
ret = pickle.load(f)
print(ret)#<function func at 0x0000020F2F9C1E18> 記憶體地址
ret()#in funchashlib模塊
摘要演算法,也叫做加密演算法,或者是哈希演算法,散列演算法等等,它通過一個函數,把任意長度的數據按照一定規則轉換為一個固定長度的數據串(通常用16進位的字元串表示)。
hashlib模塊就相當於一個演算法的集合,這裡麵包含著很多的加密演算法. MD5, sha1 sha256 sha512......
用途:
- 密碼加密: 不能以明文的形式存儲密碼,一般我們存儲密碼時都要以密文的形式.比如:太黑|e10adc3949ba59abbe56e057f20f883e
- 文件的校驗:文件一致性校驗
用法:
- 將bytes類型位元組 ---> 通過hashlib演算法 ---> 固定長度的16進位數字組成的字元串.
- 不同的bytes利用相同的演算法(MD5)轉化成的結果一定不同.
- 相同的bytes利用相同的演算法(MD5)轉化成的結果一定相同.
- hashlib演算法不可逆(MD5中國王曉雲破解了).
1.密碼加密:
# md5
s1 = 'kfdslfjasdlfgjsdlgkhsdafkshdafjksdfsdkfhjsdafj老fhdskafhsdkjfdsa男孩教育'
import hashlib
ret = hashlib.md5()
ret.update(s1.encode('utf-8'))
print(ret.hexdigest(),type(ret.hexdigest())) # 18f127c24462dd59287798ea5c0c0c2f <class 'str'>
# 相關練習
import hashlib
def MD5(pwd):
ret = hashlib.md5()
ret.update(pwd.encode('utf-8'))
return ret.hexdigest()
#登錄和註冊時密碼加密
def get_user_pwd(): #獲取用戶名,密碼
dic1 = {}
with open('register.text', encoding='utf-8', mode='r+') as f: # 讀寫模式,先讀後寫,讀並追加
for line in f:
if line != '\n':
line_list = line.strip().split('|')
dic1[line_list[0]] = line_list[1] # 如果有空行,列表元素為空,會報錯。
return dic1
def register(): #註冊
user_dict = get_user_pwd()
print(user_dict)
while 1:
username = input('請輸入用戶名:').strip()
password = input('請輸入密碼:').strip()
password_md5 = _md5_(password) # 對密碼加密
if username not in user_dict:
with open('register.text', encoding='utf-8', mode='a') as f:
f.write(f'\n{username}|{password_md5}')
print('註冊成功')
return True
else:
print('用戶名已經存在')
# register()
def login(): #登錄
user_dict1 = get_user_pwd()
count = 0
while count < 3:
username = input('請輸入用戶名:').strip()
password = input('請輸入密碼:').strip()
password_md5 = _md5_(password)
if username in user_dict1 and password_md5 == user_dict1[username]:
print('登陸成功')
return True
else:
print('用戶名或密碼錯誤')
count += 1
# login()
# 普通加密
# 123456: 18f127c24462dd59258898ea5c0c0c2f
# 000000: 18f127c24462dd59258898we5c0c0c2f
s2 = '19890425'
ret = hashlib.md5()
ret.update(s2.encode('utf-8'))
print(ret.hexdigest()) # 6e942d04cf7ceeeba09e3f2c7c03dc44
普通的md5加密,非常簡單,幾行代碼就可以了,但是這種加密級別是最低的,相對來說不很安全。雖然說hashlib加密是不可逆的加密方式,但也是可以破解的,那麼他是如何做的呢?你看網上好多MD5解密軟體,他們就是用最low的方式,空間換時間。他們會把常用的一些密碼比如:123456,111111,以及他們的md5的值做成對應關係,類似於字典,dic = {'e10adc3949ba59abbe56e057f20f883e': 123456},然後通過你的密文獲取對應的密碼。只要空間足夠大,那麼裡面容納的密碼會非常多,利用空間換取破解時間。 所以針對剛纔說的情況,我們有更安全的加密方式:加鹽。
# 加鹽
s2 = '19890425'
ret = hashlib.md5('太白金星'.encode('utf-8'))#'太白金星'就是固定的鹽
ret.update(s2.encode('utf-8'))
print(ret.hexdigest()) # 84c31bbb6f6f494fb12beeb7de4777e1
比如你在一家公司,公司會將你們所有的密碼在md5之前增加一個固定的鹽,這樣提高了密碼的安全性。但是如果黑客通過手段竊取到你這個固定的鹽之後,也是可以破解出來的。所以,我們還可以加動態的鹽。
# 動態的鹽
s2 = '19890425'
ret = hashlib.md5('太白金星'[::2].encode('utf-8')) #比如用戶名切片,針對於每個賬戶,每個賬戶的鹽都不一樣
ret.update(s2.encode('utf-8'))
print(ret.hexdigest()) # 84c31bbb6f6f494fb12beeb7de4777e1
# sha系列 金融類,安全類.用這個級別.
hahslib模塊是一個演算法集合,他裡面包含很多種加密演算法,剛纔我們說的MD5演算法是比較常用的一種加密演算法,一般的企業用MD5就夠用了。但是對安全要求比較高的企業,比如金融行業,MD5加密的方式就不夠了,得需要加密方式更高的,比如sha系列,sha1,sha224,sha512等等,數字越大,加密的方法越複雜,安全性越高,越不容易破解,但是效率就會越慢。
s2 = '198fdsl;fdsklgfjsdlgdsjlfkjsdalfksjdal90425'
ret = hashlib.sha3_512()
ret.update(s2.encode('utf-8'))
print(ret.hexdigest()) # 4d623c6701995c989f400f7e7eef0c4fd4ff15194751f5cb7fb812c7d42a7406ca0349ea3447d245ca29b48a941e2f2f66579fb090babb73eb2b446391a8e102
#也可加鹽
ret = hashlib.sha384(b'asfdsa')
ret.update('taibaijinxing'.encode('utf-8'))
print(ret.hexdigest())
# 也可以加動態的鹽
ret = hashlib.sha384(b'asfdsa'[::2])
ret.update('taibaijinxing'.encode('utf-8'))
print(ret.hexdigest())
2.文件的校驗
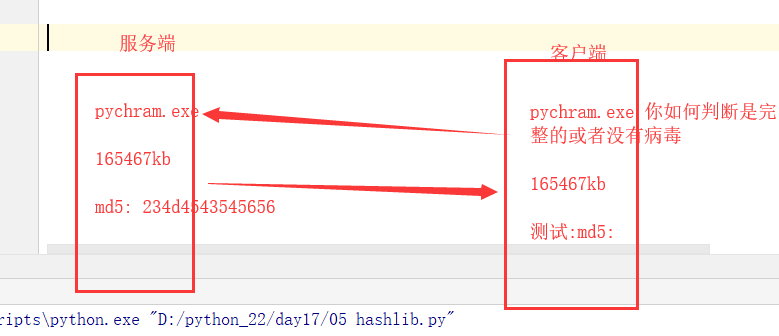
linux中一切皆文件: 文本文件,非文本文件(我們普通的文件,是文件,視頻,音頻,圖片,以及應用程式等都是文件 )
無論你下載的視頻,還是軟體(國外的軟體),往往都會有一個md5值,往往都帶有一個MD5或者shax值,當我們下載完成這個應用程式時你要是對比大小根本看不出什麼問題,你應該對比他們的md5值,如果兩個md5值相同,就證明這個應用程式是安全的,如果你下載的這個文件的MD5值與服務端給你提供的不同,那麼就證明你這個應用程式肯定是植入病毒了(文件損壞的幾率很低),那麼你就應該趕緊刪除,不應該安裝此應用程式。
#官網下載pycharm
sha256 : 6217ce726fc8ccd48ec76e9f92d15feecd20422c30367c6dc8c222ab352a3ec6 *pycharm-professional-2019.1.2.exe
#直接全部update(類比文件)
s1 = '我叫太白金星 今年18歲'
ret = hashlib.sha256()
ret.update(s1.encode('utf-8'))
print(ret.hexdigest()) # 54fab159ad8f0bfc5df726a70332f111c2c54d31849fb1e4dc1fcc176e9e4cdc
#分段update(類比文件)
ret = hashlib.sha256()
ret.update('我叫'.encode('utf-8'))
ret.update('太白金星'.encode('utf-8'))
ret.update(' 今年'.encode('utf-8'))
ret.update('18歲'.encode('utf-8'))
print(ret.hexdigest()) # 54fab159ad8f0bfc5df726a70332f111c2c54d31849fb1e4dc1fcc176e9e4cdc
#結果相同
# low版校驗:
def file_md5(path):
ret = hashlib.sha256()
with open(path,mode='rb') as f1: #以rb方式讀取
b1 = f1.read() #文件過大會撐爆記憶體
ret.update(b1)
return ret.hexdigest()
result = file_md5('pycharm-professional-2019.1.2.exe')
print(result) # 6217ce726fc8ccd48ec76e9f92d15feecd20422c30367c6dc8c222ab352a3ec6
#上面這樣寫有一個問題,類似我們文件的改的操作,有什麼問題?如果文件過大,全部讀取出來直接就會撐爆記憶體的,所以我們要分段讀取,那麼分段讀取怎麼做呢?
# 高大上版:
def file_check(file_path):
with open(file_path,mode='rb') as f1:
sha256 = hashlib.sha256()
while 1:
content = f1.read(1024)
if content:
sha256.update(content)
else:
return sha256.hexdigest()
print(file_check('pycharm-professional-2019.1.1.exe'))
總結
import 三件事, import的名字如果調用? 模塊名.的方式調用.
from ... import ... 容易產生衝突,獨立的空間.
__name__問題模塊的搜索路徑
記憶體 內置 sys.path
序列化模塊:
- json最最常用(兩對四個方法就行) 一定要掌握
- pickle(兩對四個方法就行) 儘量掌握
hashlib
- 密碼的加密 ,文件的校驗


