
Coprocessor簡介 (1)實現目的 (2)靈感來源 靈感來源於Bigtable的協處理器,包含如下特性: (3)提供介面 (4)應用範圍 Endpoint服務端實現 在傳統關係型資料庫裡面,可以隨時的對某列進行求和sum,但是目前HBase目前所提供的介面,直接求和是比較困難的,所以先編寫好 ...
Coprocessor簡介
(1)實現目的
- HBase無法輕易建立“二級索引”;
- 執行求和、計數、排序等操作比較困難,必須通過MapReduce/Spark實現,對於簡單的統計或聚合計算時,可能會因為網路與IO開銷大而帶來性能問題。
(2)靈感來源
靈感來源於Bigtable的協處理器,包含如下特性:
- 每個表伺服器的任意子表都可以運行代碼;
- 客戶端能夠直接訪問數據表的行,多行讀寫會自動分片成多個並行的RPC調用。
(3)提供介面
- RegionObserver:提供客戶端的數據操縱事件鉤子:Get、Put、Delete、Scan等;
- WALObserver:提供WAL相關操作鉤子;
- MasterObserver:提供DDL-類型的操作鉤子。如創建、刪除、修改數據表等;
- Endpoint:終端是動態RPC插件的介面,它的實現代碼被安裝在伺服器端,能夠通過HBase RPC調用喚醒。
(4)應用範圍
- 通過使用RegionObserver介面可以實現二級索引的創建和維護;
- 通過使用Endpoint介面,在對數據進行簡單排序和sum,count等統計操作時,能夠極大提高性能。
Endpoint服務端實現
在傳統關係型資料庫裡面,可以隨時的對某列進行求和sum,但是目前HBase目前所提供的介面,直接求和是比較困難的,所以先編寫好服務端代碼,並載入到對應的Table上,載入協處理器有幾種方法,可以通過HTableDescriptor的addCoprocessor方法直接載入,同理也可以通過removeCoprocessor方法卸載協處理器。
Endpoint協處理器類似傳統資料庫的存儲過程,客戶端調用Endpoint協處理器執行一段Server端代碼,並將Server端代碼的結果返回給Client進一步處理,最常見的用法就是進行聚合操作。舉個例子說明:如果沒有協處理器,當用戶需要找出一張表中的最大數據即max聚合操作,必須進行全表掃描,客戶端代碼遍歷掃描結果並執行求max操作,這樣的方法無法利用底層集群的併發能力,而將所有計算都集中到Client端統一執行, 效率非常低。但是使用Coprocessor,用戶將求max的代碼部署到HBase Server端,HBase將利用底層Cluster的多個節點並行執行求max的操作即在每個Region範圍內執行求最大值邏輯,將每個Region的最大值在Region Server端計算出,僅僅將該max值返回給客戶端。客戶端進一步將多個Region的max進一步處理而找到其中的max,這樣整體執行效率提高很多。但是一定要註意的是Coprocessor一定要寫正確,否則導致RegionServer宕機。
Protobuf定義
如前所述,客戶端和服務端之間需要進行RPC通信,所以兩者間需要確定介面,當前版本的HBase的協處理器是通過Google Protobuf協議來實現數據交換的,所以需要通過Protobuf來定義介面。
如下所示:
option java_package = "com.my.hbase.protobuf.generated"; option java_outer_classname = "AggregateProtos"; option java_generic_services = true; option java_generate_equals_and_hash = true; option optimize_for = SPEED; import "Client.proto"; message AggregateRequest { required string interpreter_class_name = 1; required Scan scan = 2; optional bytes interpreter_specific_bytes = 3; } message AggregateResponse { repeated bytes first_part = 1; optional bytes second_part = 2; } service AggregateService { rpc GetMax (AggregateRequest) returns (AggregateResponse); rpc GetMin (AggregateRequest) returns (AggregateResponse); rpc GetSum (AggregateRequest) returns (AggregateResponse); rpc GetRowNum (AggregateRequest) returns (AggregateResponse); rpc GetAvg (AggregateRequest) returns (AggregateResponse); rpc GetStd (AggregateRequest) returns (AggregateResponse); rpc GetMedian (AggregateRequest) returns (AggregateResponse); }
可以看到這裡定義7個聚合服務RPC,名字分別叫做GetMax、GetMin、GetSum等,本文通過GetSum進行舉例,其他的聚合RPC也是類似的內部實現。RPC有一個入口參數,用消息AggregateRequest表示;RPC的返回值用消息AggregateResponse表示。Service是一個抽象概念,RPC的Server端可以看作一個用來提供服務的Service。在HBase Coprocessor中Service就是Server端需要提供的Endpoint Coprocessor服務,主要用來給HBase的Client提供服務。AggregateService.java是由Protobuf軟體通過終端命令“protoc filename.proto--java_out=OUT_DIR”自動生成的,其作用是將.proto文件定義的消息結構以及服務轉換成對應介面的RPC實現,其中包括如何構建request消息和response響應以及消息包含的內容的處理方式,並且將AggregateService包裝成一個抽象類,具體的服務以類的方法的形式提供。AggregateService.java定義Client端與Server端通信的協議,代碼中包含請求信息結構AggregateRequest、響應信息結構AggregateResponse、提供的服務種類AggregateService,其中AggregateRequest中的interpreter_class_name指的是column interpreter的類名,此類的作用在於將數據格式從存儲類型解析成所需類型。
服務端的架構
首先,Endpoint Coprocessor是一個Protobuf Service的實現,因此需要它必須繼承某個ProtobufService。我們在前面已經通過proto文件定義Service,命名為AggregateService,因此Server端代碼需要重載該類,其次作為HBase的協處理器,Endpoint 還必須實現HBase定義的協處理器協議,用Java的介面來定義。具體來說就是CoprocessorService和Coprocessor,這些HBase介面負責將協處理器和HBase 的RegionServer等實例聯繫起來以便協同工作。Coprocessor介面定義兩個介面函數:start和stop。
載入Coprocessor之後Region打開的時候被RegionServer自動載入,並會調用器start 介面完成初始化工作。一般情況該介面函數僅僅需要將協處理器的運行上下文環境變數CoprocessorEnvironment保存到本地即可。
CoprocessorEnvironment保存協處理器的運行環境,每個協處理器都是在一個RegionServer進程內運行並隸屬於某個Region。通過該變數獲取Region的實例等 HBase運行時環境對象。
Coprocessor介面還定義stop()介面函數,該函數在Region被關閉時調用,用來進行協處理器的清理工作。本文里我們沒有進行任何清理工作,因此該函數什麼也不幹。
我們的協處理器還需要實現CoprocessorService介面。該介面僅僅定義一個介面函數 getService()。我們僅需要將本實例返回即可。HBase的Region Server在接收到客戶端的調用請求時,將調用該介面獲取實現RPCService的實例,因此本函數一般情況下就是返回自身實例即可。
完成以上三個介面函數之後,Endpoint的框架代碼就已完成。每個Endpoint協處理器都必須實現這些框架代碼而且寫法雷同。
Server端的代碼就是一個Protobuf RPC的Service實現,即通過Protobuf提供的某種服務。其開發內容主要包括:
- 實現Coprocessor的基本框架代碼
- 實現服務的RPC具體代碼
Endpoint 協處理的基本框架
Endpoint 是一個Server端Service的具體實現,其實現有一些框架代碼,這些框架代碼與具體的業務需求邏輯無關。僅僅是為了和HBase運行時環境協同工作而必須遵循和完成的一些粘合代碼。因此多數情況下僅僅需要從一個例子程式拷貝過來併進行命名修改即可。不過我們還是完整地對這些粘合代碼進行粗略的講解以便更好地理解代碼。
public Service getService() { return this; } public void start(CoprocessorEnvironment env) throws IOException { if(env instanceof RegionCoprocessorEnvironment) { this.env = (RegionCoprocessorEnvironment)env; } else { throw new CoprocessorException("Must be loaded on a table region!"); } } public void stop(CoprocessorEnvironment env) throws IOException { }
Endpoint協處理器真正的業務代碼都在每一個RPC函數的具體實現中。
在本文中,我們的Endpoint協處理器僅提供一個RPC函數即getSUM。我將分別介紹編寫該函數的幾個主要工作:瞭解函數的定義,參數列表;處理入口參數;實現業務邏輯;設置返回參數。
public void getSum(RpcController controller, AggregateRequest request, RpcCallbackdone) { AggregateResponse response = null; RegionScanner scanner = null; long sum = 0L; try { ColumnInterpreter ignored = this.constructColumnInterpreterFromRequest(request); Object sumVal = null; Scan scan = ProtobufUtil.toScan(request.getScan()); scanner = this.env.getRegion().getScanner(scan); byte[] colFamily = scan.getFamilies()[0]; NavigableSet qualifiers = (NavigableSet) scan.getFamilyMap().get(colFamily); byte[] qualifier = null; if (qualifiers != null && !qualifiers.isEmpty()) { qualifier = (byte[]) qualifiers.pollFirst(); } ArrayList results = new ArrayList(); boolean hasMoreRows = false; do { hasMoreRows = scanner.next(results); int listSize = results.size(); for (int i = 0; i < listSize; ++i) { //取出列值 Object temp = ignored.getValue(colFamily, qualifier, (Cell) results.get(i)); if (temp != null) { sumVal = ignored.add(sumVal, ignored.castToReturnType(temp)); } } results.clear(); } while (hasMoreRows); if (sumVal != null) { response = AggregateResponse.newBuilder().addFirstPart( ignored.getProtoForPromotedType(sumVal).toByteString()).build(); } } catch (IOException var27) { ResponseConverter.setControllerException(controller, var27); } finally { if (scanner != null) { try { scanner.close(); } catch (IOException var26) { ; } } } log.debug("Sum from this region is " + this.env.getRegion().getRegionInfo().getRegionNameAsString() + ": " + sum); done.run(response); }
Endpoint類比於資料庫的存儲過程,其觸發服務端的基於Region的同步運行再將各個結果在客戶端搜集後歸併計算。特點類似於傳統的MapReduce框架,服務端Map客戶端Reduce。
Endpoint客戶端實現
HBase提供客戶端Java包org.apache.hadoop.hbase.client.HTable,提供以下三種方法來調用協處理器提供的服務:
- coprocessorService(byte[])
- coprocessorService(Class, byte[], byte[],Batch.Call),
- coprocessorService(Class, byte[], byte[],Batch.Call, Batch.Callback)
該方法採用rowkey指定Region。這是因為HBase客戶端很少會直接操作Region,一般不需要知道Region的名字;況且在HBase中Region名會隨時改變,所以用rowkey來指定Region是最合理的方式。使用rowkey可以指定唯一的一個Region,如果給定的Rowkey並不存在,只要在某個Region的rowkey範圍內依然用來指定該Region。比如Region 1處理[row1, row100]這個區間內的數據,則rowkey=row1就由Region 1來負責處理,換句話說我們可以用row1來指定Region 1,無論rowkey等於”row1”的記錄是否存在。CoprocessorService方法返回類型為CoprocessorRpcChannel的對象,該 RPC通道連接到由rowkey指定的Region上面,通過此通道可以調用該Region上面部署的協處理器RPC。
有時候客戶端需要調用多個 Region上的同一個協處理器,比如需要統計整個Table的sum,在這種情況下,需要所有的Region都參與進來,分別統計自身Region內部的sum並返回客戶端,最終客戶端將所有Region的返回結果彙總,就可以得到整張表的sum。
這意味著該客戶端同時和多個Region進行批處理交互。一個可行的方法是,收集每個 Region的startkey,然後迴圈調用第一種coprocessorService方法:用每一個Region的startkey 作為入口參數,獲得RPC通道創建stub對象,進而逐一調用每個Region上的協處理器RPC。這種做法需要寫很多的代碼,為此HBase提供兩種更加簡單的 coprocessorService方法來處理多個Region的協處理器調用。先來看第一種方法 coprocessorService(Class, byte[],byte[],Batch.Call)
該方法有 4 個入口參數。第一個參數是實現RPC的Service 類,即前文中的AggregateService類。通過它,HBase就可以找到相應的部署在Region上的協處理器,一個Region上可以部署多個協處理器,客戶端必須通過指定Service類來區分究竟需要調用哪個協處理器提供的服務。
要調用哪些Region上的服務則由startkey和endkey來確定,通過 rowkey範圍即可確定多個 Region。為此,coprocessorService方法的第二個和第三個參數分別是 startkey和endkey,凡是落在[startkey,endkey]區間內的Region都會參與本次調用。
第四個參數是介面類Batch.Call。它定義瞭如何調用協處理器,用戶通過重載該介面的call()方法來實現客戶端的邏輯。在call()方法內,可以調用RPC,並對返回值進行任意處理。即前文代碼清單1中所做的事情。coprocessorService將負責對每個 Region調用這個call()方法。
coprocessorService方法的返回值是一個Map類型的集合。該集合的key是Region名字,value是Batch.Call.call方法的返回值。該集合可以看作是所有Region的協處理器 RPC 返回的結果集。客戶端代碼可以遍歷該集合對所有的結果進行彙總處理。
這種coprocessorService方法的大體工作流程如下。首先它分析startkey和 endkey,找到該區間內的所有Region,假設存放在regionList中。然後,遍歷regionList,為每一個Region調用Batch.Call,在該介面內,用戶定義具體的RPC調用邏輯。最後coprocessorService將所有Batch.Call.call()的返回值加入結果集合併返回。
coprocessorService的第三種方法比第二個方法多了一個參數callback。coprocessorService第二個方法內部使用HBase自帶的預設callback,該預設 callback將每個Region的返回結果都添加到一個Map類型的結果集中,並將該集合作為coprocessorService方法的返回值。
HBase 提供第三種coprocessorService方法允許用戶定義callback行為,coprocessorService 會為每一個RPC返回結果調用該callback,用戶可以在callback 中執行需要的邏輯,比如執行sum累加。用第二種方法的情況下,每個Region協處理器RPC的返回結果先放入一個列表,所有的 Region 都返回後,用戶代碼再從該列表中取出每一個結果進行累加;用第三種方法,直接在callback中進行累加,省掉了創建結果集合和遍歷該集合的開銷,效率會更高一些。
因此我們只需要額外定義一個callback即可,callback是一個Batch.Callback介面類,用戶需要重載其update方法。
public S sum(final HTable table, final ColumnInterpreter<R, S, P, Q, T> ci,final Scan scan)throws Throwable { final AggregateRequest requestArg = validateArgAndGetPB(scan, ci, false); class SumCallBack implements Batch.Callback { S sumVal = null; public S getSumResult() { return sumVal; } @Override public synchronized void update(byte[] region, byte[] row, S result) { sumVal = ci.add(sumVal, result); }} SumCallBack sumCallBack = new SumCallBack(); table.coprocessorService(AggregateService.class, scan.getStartRow(), scan.getStopRow(), new Batch.Call<AggregateService, S>() { @Override public S call(AggregateService instance) throws IOException { ServerRpcController controller = new ServerRpcController(); BlockingRpcCallback<AggregateResponse> rpcCallback = new BlockingRpcCallback<AggregateResponse>(); //RPC 調用 instance.getSum(controller, requestArg, rpcCallback); AggregateResponse response = rpcCallback.get(); if (controller.failedOnException()) { throw controller.getFailedOn(); } if (response.getFirstPartCount() == 0) { return null; } ByteString b = response.getFirstPart(0); T t = ProtobufUtil.getParsedGenericInstance(ci.getClass(), 4, b); S s = ci.getPromotedValueFromProto(t); return s; } }, sumCallBack); return sumCallBack.getSumResult();
Observer實現二級索引
Observer類似於傳統資料庫中的觸發器,當發生某些事件的時候這類協處理器會被 Server 端調用。Observer Coprocessor是一些散佈在HBase Server端代碼的 hook鉤子, 在固定的事件發生時被調用。比如:put操作之前有鉤子函數prePut,該函數在pu 操作執 行前會被Region Server調用;在put操作之後則有postPut 鉤子函數。
RegionObserver工作原理
RegionObserver提供客戶端的數據操縱事件鉤子,Get、Put、Delete、Scan,使用此功能能夠解決主表以及多個索引表之間數據一致性的問題
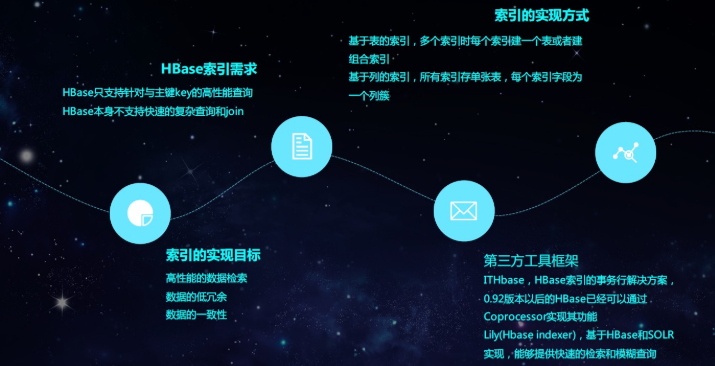
- 客戶端發出put請求;
- 該請求被分派給合適的RegionServer和Region;
- coprocessorHost攔截該請求,然後在該表上登記的每個 RegionObserver 上調用prePut();
- 如果沒有被preGet()攔截,該請求繼續送到 region,然後進行處理;
- Region產生的結果再次被CoprocessorHost攔截,調用postGet();
- 假如沒有postGet()攔截該響應,最終結果被返回給客戶端;

如上圖所示,HBase可以根據rowkey很快的檢索到數據,但是如果根據column檢索數據,首先要根據rowkey減小範圍,再通過列過濾器去過濾出數據,如果使用二級索引,可以先查基於column的索引表,獲取到rowkey後再快速的檢索到數據。
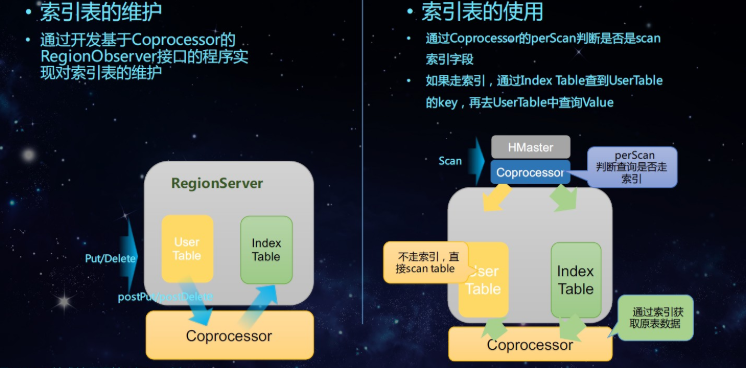
如圖所示首先繼承BaseRegionObserver類,重寫postPut,postDelete方法,在postPut方法體內中寫Put索引表數據的代碼,在postDelete方法裡面寫Delete索引表數據,這樣可以保持數據的一致性。
在Scan表的時候首先判斷是否先查索引表,如果不查索引直接scan主表,如果走索引表通過索引表獲取主表的rowkey再去查主表。
使用Elastic Search建立二級索引也是一樣。
我們在同一個主機集群上同時建立了HBase集群和Elastic Search集群,存儲到HBase的數據必須實時地同步到Elastic Search。而恰好HBase和Elastic Search都沒有更新的概念,我們的需求可以簡化為兩步:
- 當一個新的Put操作產生時,將Put數據轉化為json,索引到ElasticSearch,並把RowKey作為新文檔的ID;
- 當一個新的Delete操作產生時獲取Delete數據的rowkey刪除Elastic Search中對應的ID。
協處理的主要應用場景
- Observer允許集群在正常的客戶端操作過程中可以有不同的行為表現;
- Endpoint允許擴展集群的能力,對客戶端應用開放新的運算命令;
- Observer類似於RDBMS的觸發器,主要在服務端工作;
- Endpoint類似於RDBMS的存儲過程,主要在服務端工作;
- Observer可以實現許可權管理、優先順序設置、監控、ddl控制、二級索引等功能;
- Endpoint可以實現min、max、avg、sum、distinct、group by等功能。

