
1.關係型資料庫的特點 基於關係代數理論: 缺點:表結構不直觀,實現複雜,速度慢 優點:健壯性高、社區龐大,在一些情況下人們發現健壯性,並不是要求那麼高,因而產生了十分流行的非關係型資料庫,如Redis,Memcached等。 2.資料庫表關係 下麵以Product表和Category進行舉例,Ca ...
基於關係代數理論:
缺點:表結構不直觀,實現複雜,速度慢
優點:健壯性高、社區龐大,在一些情況下人們發現健壯性,並不是要求那麼高,因而產生了十分流行的非關係型資料庫,如Redis,Memcached等。
2.資料庫表關係
下麵以Product表和Category進行舉例,Category表的主鍵為Product的外鍵,Category被稱為主鍵表,Product被成為外鍵表,在關係型資料庫中,有外鍵後數據的健壯性會提高。
使用資料庫:MySQL5.5
Category表:

Product表:
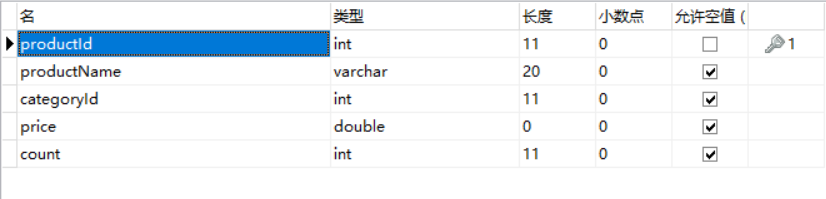
Product表數據:
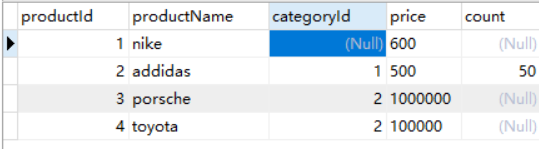
Category表數據:
3.join和group by
3.1 使用join
1 select * from product JOIN category 2 select * from product,category 3 --以上兩種寫法沒有區別都會做笛卡爾積
執行結果:
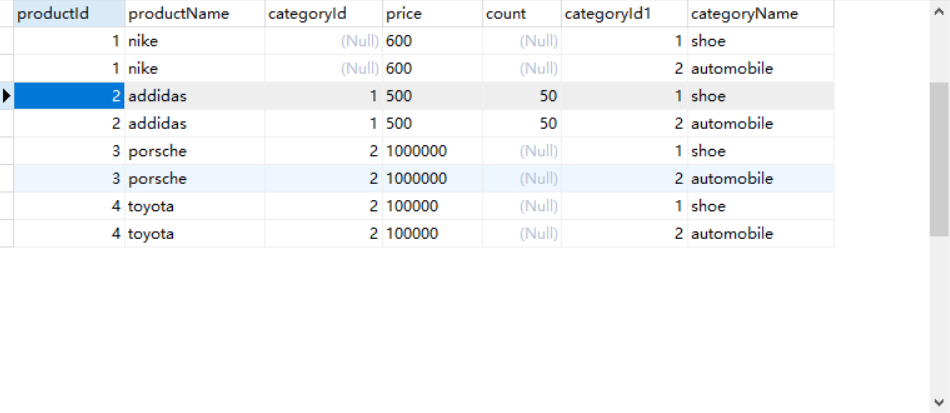

總共查出8條數據,實際上相當於做了一個笛卡爾積,product表四條記錄,category表兩條記錄,最後結果就是8條記錄。
3.2 使用join on(內連接)
使用join on就可以加上條件只把相等的記錄展示出來。
1 SELECT * from product p JOIN category c ON p.categoryId = c.categoryId
執行結果:


使用內連接,資料庫不會去做笛卡爾積再去選擇,這樣效率是非常低下的,比如阿迪達斯那條記錄,資料庫會去category表中去找到id等於1的記錄,我們可以看到nike是沒有categoryId,所以沒有被顯示出來,如果想要被顯示出來,我們就要用外連接,left join(左外連接)
3.3 使用left join(左連接,以左表為主)
1 SELECT * from product p LEFT JOIN category c ON p.categoryId = c.categoryId
我們可以看到結果,nike位置上的categoryId為空,資料庫就會放兩個null進來,而內連接並不會顯示null。
執行結果:


3.4 使用group by
查詢每個類別下麵有幾個產品:
1 SELECT c.categoryId, COUNT(*) FROM category c LEFT JOIN product p on p.categoryId = c.categoryId 2 GROUP BY categoryId
使用group by方法之後,只能select分組這個欄位和一些聚合函數,有一些工具不會報錯,有一一些工具如果select其他欄位就會報錯。
執行結果:


對categoryId和categoryName進行分類
可以同時查出categoryId和categoryName.將nike的categoryId,對於兩個表共同擁有的欄位(categoryId)一定要標註出是哪個表的欄位。
1 SELECT c.categoryId,c.categoryName, COUNT(*) FROM category c LEFT JOIN product p on p.categoryId = c.categoryId 2 GROUP BY c.categoryId, c.categoryName
運行結果:

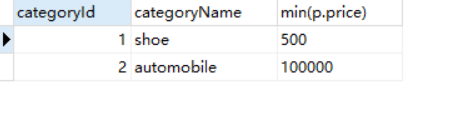
找出每個分類下最便宜商品的價格:
1 SELECT c.categoryId, c.categoryName, min(p.price) FROM category c join product p on c.categoryId = p.categoryId 2 GROUP BY c.categoryId, c.categoryName
運行結果:最便宜的鞋子是500,最便宜的車是100000

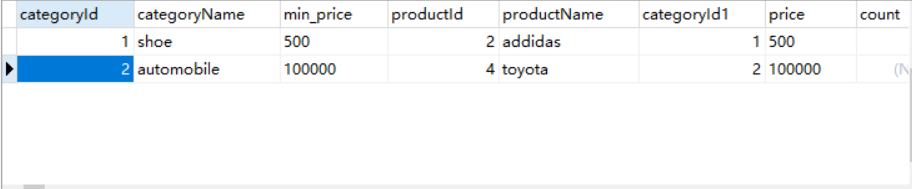
查詢每個分類最便宜商品的價格以及商品名稱:
這裡需要做子查詢,對這個sql進行分析,首先我們上一步已經查詢出,每個分類下麵最便宜的商品的價格,我們將product表和這個結果進行左連接,之後我們在根據商品中的價格與最便宜的價格是否相等,就能篩選出每個分類中最便宜的商品信息。
1 SELECT * FROM (SELECT c.categoryId, c.categoryName, MIN(p.price) min_price FROM category c join product p on c.categoryId = p.categoryId 2 GROUP BY c.categoryId, c.categoryName) as cat_min, product p WHERE cat_min.min_price = p.price
運行結果:

4.事務
ACID
Atomicity(原子性)
Consistency(一致性)
Isolation(隔離性)
Durability(持久性)
5.事務的隔離級別
Read uncommitted (未提交讀)
讀未提交,即能夠讀取到沒有被提交的數據,所以很明顯這個級別的隔離機制無法解決臟讀、不可重覆讀、幻讀中的任何一種,因此很少使用
Read_Committed(提交讀)
讀已提交,即能夠讀到那些已經提交的數據,自然能夠防止臟讀,但是無法限制不可重覆讀和幻讀,可以使用for update,讓其他事務不可以去讀這個表,就可以防止其他事務去修改count的值。
REPEATABLE_READ(可重覆讀,mysql預設事務隔離級別)
重覆讀取,repeatable解決的只是在單個事務中重覆讀取數據的一致,其他事務可以更改該事務select之後的數據,這樣就解決了臟讀、不可重覆讀的問題,但是幻讀的問題還是無法解決
SERLALIZABLE(串列化)
串列化,最高的事務隔離級別,不管多少事務,挨個運行完一個事務的所有子事務之後才可以執行另外一個事務裡面的所有子事務,這樣就解決了臟讀、不可重覆讀和幻讀的問題了
6. 併發下事務會產生的問題
1、臟讀
所謂臟讀,就是指事務A讀到了事務B還沒有提交的數據,比如銀行取錢,事務A開啟事務,此時切換到事務B,事務B開啟事務-->取走100元,此時切換回事務A,事務A讀取的肯定是資料庫裡面的原始數據,因為事務B取走了100塊錢,並沒有提交,資料庫裡面的賬務餘額肯定還是原始餘額,這就是臟讀。
2、不可重覆讀
所謂不可重覆讀,就是指在一個事務裡面讀取了兩次某個數據,讀出來的數據不一致。還是以銀行取錢為例,事務A開啟事務-->查出銀行卡餘額為1000元,此時切換到事務B事務B開啟事務-->事務B取走100元-->提交,資料庫裡面餘額變為900元,此時切換回事務A,事務A再查一次查出賬戶餘額為900元,這樣對事務A而言,在同一個事務內兩次讀取賬戶餘額數據不一致,這就是不可重覆讀。
3、幻讀
所謂幻讀,就是指在一個事務裡面的操作中發現了未被操作的數據。比如學生信息,事務A開啟事務-->修改所有學生當天簽到狀況為false,此時切換到事務B,事務B開啟事務-->事務B插入了一條學生數據,此時切換回事務A,事務A提交的時候發現了一條自己沒有修改過的數據,這就是幻讀,就好像發生了幻覺一樣。幻讀出現的前提是併發的事務中有事務發生了插入、刪除操作。
通過一下sql可以查出資料庫的事務隔離級別:
1 select @@tx_isolation
執行結果:資料庫的預設隔離級別


接下來測試一下資料庫的事務隔離級別:
首先在product表中添加一個count欄位

並且將阿迪達斯的數量設置為50,模擬用戶搶購。
1 SET SESSION TRANSACTION ISOLATION LEVEL READ COMMITTED 2 3 BEGIN;SET AUTOCOMMIT = 0;SELECT count FROM product where productId = 2; 4 5 SELECT count FROM product where productId = 2; 6 7 UPDATE product SET count = 49 WHERE productId= 2;
使用for update非常耗費資源,使用樂觀鎖更節省資源。
樂觀鎖的使用:
1 SELECT count FROM product WHERE productId = 2; 2 UPDATE product SET count = 47 WHERE productId = 2 AND count = 48;
如果返回0行就代表失敗,就會返回用戶夠買失敗。讀取數據,記錄Timestamp,需要自己加一個Timestamp.
檢查和提交要在同一行中執行。
樂觀鎖的應用場景:買家不是很多,不會造成很多衝突用樂觀鎖非常好,衝突多的時候要用,很可能count存在伺服器記憶體當中(分散式鎖),因為資料庫在硬碟當中非常慢。
7. 資料庫例題
下列方法中,哪個不可以用來程式調優。 B
A、改善數據訪問方式以提升緩存命中率
B、使用多線程的方式提高I/O密集型操作的效率(I/O密集型訪問,多線程效果並不太起作用)
C、利用資料庫連接池替代直接的資料庫訪問
D、使用迭代替代遞歸
E、合併多個線程調用批量發送(減少等待時間)
F、共用冗餘數據提高訪問效率


