
JVM記憶體模型 java虛擬機在執行java程式的過程中會把它所管理的記憶體劃分為不同的若幹個不同的的數據區域,這些區域都有各自的用途,以及創建和銷毀的時間,有的區域隨著虛擬機的進程的啟動而存在,有些區域依賴用戶線程的啟動和結束而創建和銷毀,java虛擬機所管理的記憶體將會包括以下幾個運行時數據區域 J ...
JVM記憶體模型
java虛擬機在執行java程式的過程中會把它所管理的記憶體劃分為不同的若幹個不同的的數據區域,這些區域都有各自的用途,以及創建和銷毀的時間,有的區域隨著虛擬機的進程的啟動而存在,有些區域依賴用戶線程的啟動和結束而創建和銷毀,java虛擬機所管理的記憶體將會包括以下幾個運行時數據區域
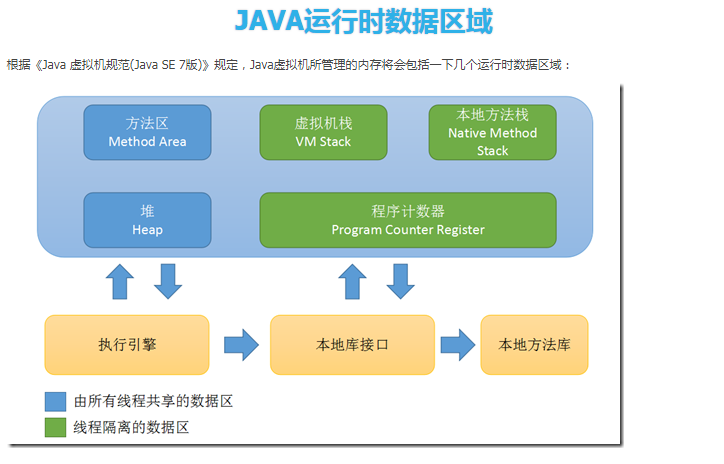
JVM分為堆區和棧區,還有方法區,初始化對象放在堆裡面,引用放在棧裡面,class類信息常量池(static常量和static變數)等放在方法區
- 方法區:主要是存儲類信息,常量池(static常量和static變數),編譯後的代碼(位元組碼)等數據
- 堆:初始化的對象,成員變數(那種非static的變數),所有的對象實例和數組都要在堆上分配
- 棧:棧的結構是棧幀組成的,調用一個方法就壓入一針,針上面存儲著局部變數表,操作數棧,方法出口等信息,局部變數表存放的是8大基礎類型加上一個應用類型,所以還是一個指向地址的指針
- 本地方法棧:主要為native方法進行服務
- 程式計數器:記錄當前線程執行的行號
java記憶體分配
- 基礎數據類型直接在棧空間分配
- 引用數據類型,需要new關鍵字來創建即在棧空間分配一個地址空間,又在堆空間分配對象的類變數
- 方法的形式參數,直接在棧空間分配,當方法調用完成後從棧空間回收
- 方法的引用參數,在棧空間分配一個地址空間,並指向並指向堆空間的對象區,當方法調用完成後從棧空間回收,堆空空間區域等待GC回收
- 方法調用時傳入的實際參數,先在棧空間分配,在方法調用完成後從棧空間釋放
- 局部變數NEW出來時,在棧空間和堆空間分配空間,當局部變數生命周期後,棧空間立刻回收,堆空間等待GC會後
- 字元串常量在DATA區域分配,this在堆空間分配
- 數組即在棧空間分配數組名稱,又在堆空間分配數組的實際大小
GC的兩種判定方法
引用計數法
給對象添加一個引用計數器,每當有一個地方引用它時,計數器值就加1;當引用失效時,計數器值就減1;任何時刻計數器為0的對象就是不可能再被使用的。
引用計數演算法原理簡單,實現容易,但是缺點是不能解決對象間迴圈引用問題,可能會造成記憶體泄漏。
可達性分析演算法
這個演算法的基本思路就是通過一系列的稱為“GC Roots”的對象作為起始點,從這些節點開始向下搜索,搜索所走過的路徑稱為引用鏈(Reference Chain),當一個對象到GC Roots沒有任何引用鏈相連,用圖論的話來說,就是從GC Roots到這個對象不可達時,則證明此對象是不可用的。
如下圖所示,對象object 5、object 6、object 7雖然互相有關聯,但是它們到GC Roots是不可達的,所以它們將會被判定為是可回收的對象。

在java語言中,可作為GC Roots的對象包括下麵幾種:
- 虛擬機棧棧幀中本地變數表中引用的對象。
- 方法區中常量引用的對象
- 方法區中類靜態屬性引用的對象
GC的三種收集演算法
標記清除
最基礎的收集演算法是“標記-清除”(Mark-Sweep)演算法,如同它的名字一樣,演算法分為“標記”和“清除”兩個階段:首先標記出所有需要回收的對象,在標記完成後統一回收所有被標記的對象。
之所以說它是最基礎的收集演算法,是因為後續的收集演算法都是基於這種思路並對其不足進行改進而得到的。它的主要不足有兩個:一個是效率問題,標記和清除兩個過程的效率都不高;另一個是空間問題,標記清除之後會產生大量不連續的記憶體碎片,空間碎片太多可能會導致以後在程式運行過程中需要分配較大對象時,無法找到足夠的連續記憶體而不得不提前觸發另一次垃圾收集動作。
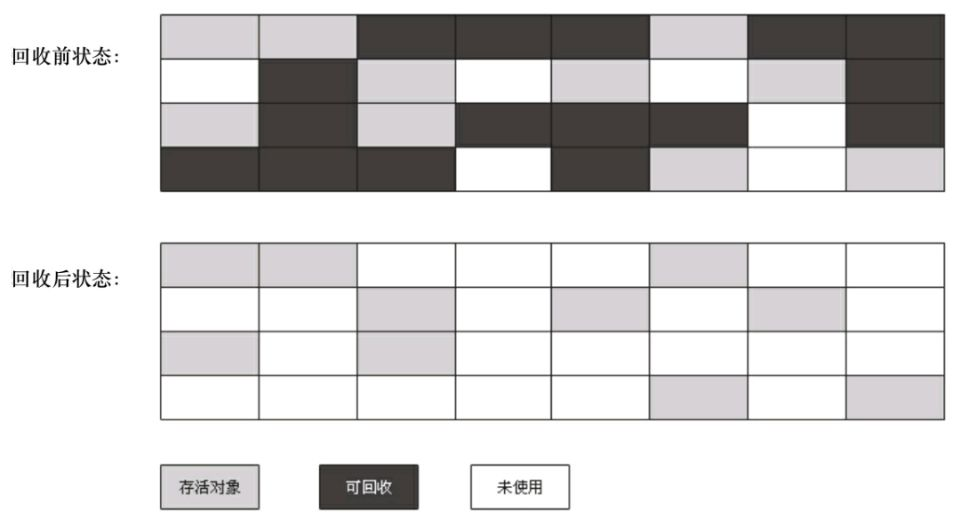
複製演算法
現在虛擬機都採用這種方法來回收新生代,將記憶體中新生代分為Eden和兩塊較小的Survivor空間,每次使用Eden和其中一塊Survivor。當回收時,將Eden和Survivor中還存活的對象一次性的複製到另外一塊Survivor空間上,最後清理掉Eden和用過的Survivor空間。Eden區和Survivor區的大小比值為8:1
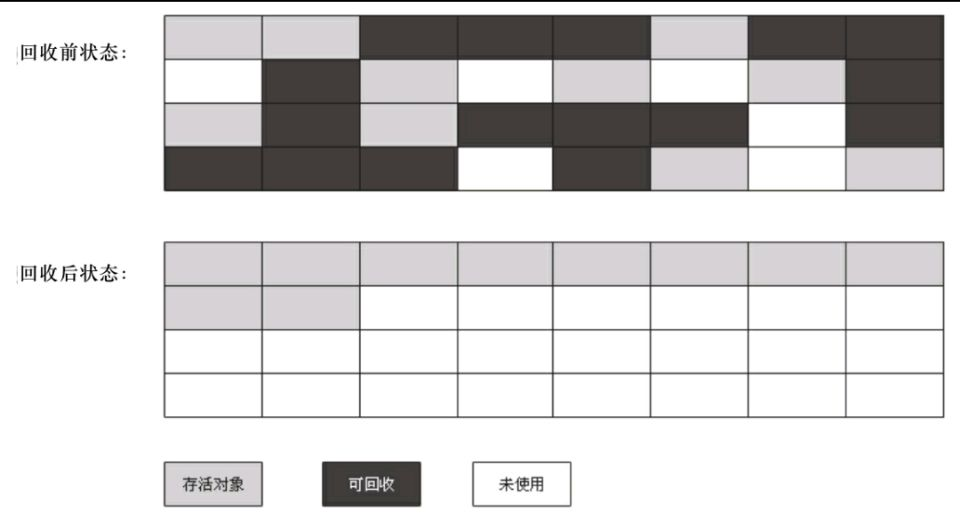
標記整理
根據老年代的特點,出現了一種標記整理演算法,同標記清除演算法一樣,但是後續步驟不是直接可回收對象進行清理,而是讓所有存活對象向一端移動,然後直接清理掉端邊界以外的記憶體。
GC收集器
串列收集器:串列收集器使用一個單獨的線程進行收集,GC時服務有停頓時間
並行收集器:回收中使用多線程來來執行
CMS收集器:基於標記清除演算法實現的,經過多次標記才會被清除。
G1收集器:從整體來看是基於“標記整理演算法”來實現的收集器,從局部(兩個Region之間)上來看是基於“複製演算法”來實現的。CMS是一種以最短停頓時間為目標的收集器,響應優先選擇CMS,吞吐量高選擇G1


