
1.簡介 HashMap是基於哈希表的Map介面的實現,用來存放鍵值對(Entry<Key,Value>),並提供可選的映射操作。使用put(Key,Value)存儲對象到HashMap中,使用get(Key)從hashMap中獲取對象。 2.底層結構 HashMap的底層是由數組加鏈表實現的,因為 ...
1.簡介
HashMap是基於哈希表的Map介面的實現,用來存放鍵值對(Entry<Key,Value>),並提供可選的映射操作。使用put(Key,Value)存儲對象到HashMap中,使用get(Key)從hashMap中獲取對象。
2.底層結構
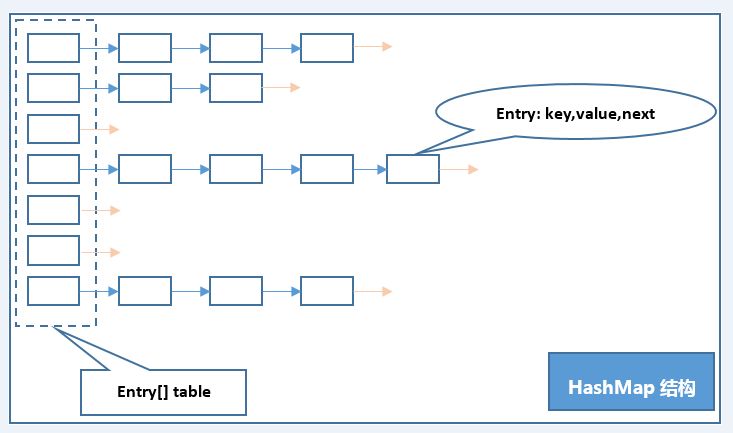
HashMap的底層是由數組加鏈表實現的,因為對鏈表頭部進行增刪操作,所以也稱為棧式鏈結構。鏈表由 Entry<Key,Value>對象作為結點,我們把存儲該鏈表的數組位置稱之為桶,那麼桶數量就等於數組的長度。存放數據時時通過key的hashCode來計算hash,得到的hash作為數組的索引(也就是桶位置)存放對象,當hashCode相同時,則稱之為哈希衝突,也可稱為“碰撞”。此時通過“拉鏈法”解決衝突。
//Entry源碼
static class Node<K,V> implements Map.Entry<K,V> { final int hash; final K key; V value; Node<K,V> next; Node(int hash, K key, V value, Node<K,V> next) { this.hash = hash; this.key = key; this.value = value; this.next = next; } public final K getKey() { return key; } public final V getValue() { return value; } public final String toString() { return key + "=" + value; }
補充:在jdk1.8版本之後,在解決哈希衝突時有了較大的變化,當鏈表長度大於閾值(預設為8)時,將鏈表轉化為紅黑樹,以減少搜索時間。
3.原理分析
下麵由存取數據的過程進行原理分析:
(1) put(key,value)
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
從這裡我們可以看出hash方法對Key調用HashCode()方法,將得到的哈希值高16位不變,高16位與低16位進行異或運算。這樣的目的是通過對哈希值的擾動,儘可能減少碰撞的發生。
此時的哈希值還不能作為數組的索引來存放數據,最後還會對擾動後的hash與(數組長度-1)進行取模運算,即(n - 1) & hash 這裡n為數組長度,假設n為16 那麼(n-1)的二進位為1111,將之與hash進行與位運算,1111截取hash後四位,並保證只是截取操作,截取後的hash與截取前的hash後四位相同,這就保證最後得到的hash能作為索引使數據在數組長度內儘可能均勻分佈,減少碰撞,這種方式和hash%n取餘的結果差不多又不太一樣,通俗點將,取模操作要求n-1的二進位是111...都是1這種形式,也就必須要求n的值必須為2的次冪,這也解釋了為什麼HashMap規定數組的長度必須是2的次冪的原因。
重覆上述:使用put方法傳遞 Entry<Key,Value>時,會對Key計算hash索引,先判斷數組table[hash]是否為null,若為null 則入 Entry<Key,Value>,若不為空,就說明發生了碰撞,此時要存入的Entry對象的Key和桶中的Entry對象的Key的hash相同,但是它們可能並不相等,所以會調用equals方法將要存入的Key與桶中的Key一一比對,若均不相等,則存入 Entry(頭插入法),如果相等,會覆蓋原來的Entry.這種解決碰撞的方式就是前面所說的“拉鏈法”。
通過對存儲過程的原理分析,那獲取數據就簡單了,在調用get(Key)方法時,同樣計算Key的hash,通過計算好的hash找到桶位置,然後遍歷鏈表通過key.equals方法直到找到Value值。
常見問題
(1)關於擴容:
loadfactor: 預設0.75f,代表桶填充程度,loadFactor越趨近於1,那麼數組中存放的數據(entry)也就越多,也就越密,也就是會讓鏈表的長度增加,導致查找元素效率低,loadFactor越趨近於0,數組的利用率越低,存放的數據會很分散。loadFactor的預設值為0.75f是官方給出的一個比較好的臨界值。
capacity: 數組長度,必須為2的次冪,預設為16。hashMap構造中可指定初始長度,會通過一個演算法轉化成2的次冪
threshold: threshold = capacity * loadFactor,當entry的數量>=threshold的時候,那麼就要考慮對數組的擴容了,這個的意思就是 衡量數組是否需要擴增的一個標準,擴容後,會重新對所有數據進行重新計算,重新存放,這個過程叫做rehash。
//HashMap保證數組長度為2的次冪的演算法
static final int tableSizeFor(int cap) { int n = cap - 1; n |= n >>> 1; n |= n >>> 2; n |= n >>> 4; n |= n >>> 8; n |= n >>> 16; return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
}
(2)HashMap與HashTable主要區別為不支持同步和允許null作為key和value,所以如果你想要保證線程安全,可以使用ConcurrentHashMap代替而不是線程安全的HashTable,因為HashTable基本已經被淘汰。
(3)如果兩個線程都發現HashMap需要調整大小,它們會同時嘗試調整大小,在這個過程中,存儲在鏈表中的元素次序會反過來,因為移動到新的桶位置的時候,hashMap並不會將元素放在尾部,而是放在頭部,這是為了避免尾部遍歷,如果條件競爭發生,會發生死迴圈.(註:jdk1.8已經解決了死迴圈的問題。)
(4)key多用String的原因:String是final的,並且重寫了hashMap和equals方法,不可變可以防止鍵的改變,重寫那兩個方法可以減少碰撞的幾率.

