
Linux作為多任務系統,當一個進程生成的數據傳輸到另一個進程時,或數據由多個進程共用時,或進程必須彼此等待時,或需要協調資源的使用時,應用程式必須彼此通信。 一、控制機制 1、競態條件 幾個進程在訪問資源時彼此干擾的情況通常稱之為競態條件(race condition)。在對分散式應用編程時,這種 ...
Linux作為多任務系統,當一個進程生成的數據傳輸到另一個進程時,或數據由多個進程共用時,或進程必須彼此等待時,或需要協調資源的使用時,應用程式必須彼此通信。
一、控制機制
1、競態條件
幾個進程在訪問資源時彼此干擾的情況通常稱之為競態條件(race condition)。在對分散式應用編程時,這種情況是一個主要的問題,因為競態條件無法通過系統的試錯法檢測。只有徹底研究源代碼(深入瞭解各種可能發生的代碼路徑)並通過敏銳的直覺,才能找到並消除競態條件。
2、臨界區
對於競態條件,其問題的本質是進程的執行在不應該的地方被中斷,從而導致進程工作得不正確。對於此問題的解決方案不一定要求臨界區不能中斷,只要沒有其他進程進入臨界區,那麼在臨界區中執行的程式是可以中斷的。確保幾個進程不能同時改變共用值的禁止條件稱為互斥。
大多數系統採用的方案是信號量(semaphore)的使用。信號量是由E. W. Dijkstra在1965年設計的。實質上,最初的信號量是受保護的特別變數,能夠表示為正負整數,初始值為1。它有兩個標準操作(up和down),這兩個操作分別用於控制關鍵代碼範圍的進入和退出,且假定相互競爭的進程訪問信號量機會均等。
在一個進程想要進入關鍵代碼時,它調用down函數。這會將信號量的值減1,即將其設置為0,然後執行危險代碼段(此時若有其他進程想進入該代碼段調用down操作則會等待進入關鍵代碼的進程完成操作)。在執行完操作之後,調用up函數將信號量的值加1,即重置為初始值。
信號量在用戶層可以正常工作,原則上也可以用於解決內核內部的各種鎖問題。但事實並非如此:性能是內核最首先的一個目標,雖然信號量初看起來容易實現,但其開銷對內核來說過大,這也是內核中提供了許多不同的鎖和同步機制的原因。
二、內核鎖機制
在多處理器系統上,如果幾個處理器同時處於核心態,理論上它們可以同時訪問一個數據結構,剛好引發了競態條件。因此,在第一個SMP功能的內核版本中,對該問題的處理是每次只允許一個處理器處於核心態,但這樣效率不高。現在,內核使用了由鎖組成的細粒度網路,用以明確保護各數據結構(如果處理器A在操作數據結構X,則處理器B可以執行任何其他的內核操作,但不能操作X)。
內核提供了各種鎖選項,分別優化不同的內核數據使用模式:
原子操作:這些是最簡單的鎖操作。它們保證簡單的操作,諸如計數器加1之類,可以不中斷地原子執行,即使操作由幾個彙編語句組成,也可以保證;
自旋鎖:這些是最常用的鎖選項,它們用於短期保護某段代碼,以防止其他處理器的訪問,在內核等待自旋鎖釋放時,會重覆檢查是否能獲取鎖,而不會進入睡眠狀態(忙等待),如果等待時間較長,則效率顯然不高;
信號量:這些是用經典方法實現的,在等待信號量釋放時,內核進入睡眠狀態,直至被喚醒,喚醒後,內核才重新嘗試獲取信號量,互斥量是信號量的特例,互斥量保護的臨界區,每次只能有一個用戶進入;
讀者/寫者鎖:這些鎖會區分對數據結構的兩種不同類型的訪問,任意數目的處理器都可以對數據結構進行併發讀訪問,但只有一個處理器能進行寫訪問(在進行寫訪問時,讀訪問是無法進行的)。
1、對整數的原子操作
內核定義了atomic_t數據類型,用作對整數計數器的原子操作的基礎。從內核的角度看,這些操作相當於一條彙編語句。
為使得內核中平臺獨立的部分能夠使用原子操作,用於操縱atomic_t類型變數的操作必須由特定於體繫結構的代碼提供(因為內核將標準類型進行了封裝,原子變數只能藉助於ATOMIC_INIT巨集初始化,不能用普通運算符處理)。
內核為SMP系統提供了local_t數據類型。該類型允許在單個CPU上的原子操作。為修改此類型變數,內核提供了基本上與atomic_t數據類型相同的一組函數,只是將atomic替換為local。
2、自旋鎖
自旋鎖用於保護短的代碼段,其中只包含少量C語句,會很快執行完畢。大多數內核數據結構都有自身的自旋鎖,在處理結構中的關鍵成員時,必須獲得相應的自旋鎖。
自旋鎖通過spinlock_t數據結構實現,基本上可使用spin_lock和spin_unlock操縱。(自旋鎖的實現與體繫結構相關,幾乎全是彙編語言)
自旋鎖工作情況:
- 如果內核中其他地方尚未獲得lock,則由當前處理器獲取。其他處理器不能再進入lock保護的代碼範圍;
- 如果lock已經由另一個處理器獲得,spin_lock進入一個無限迴圈,重覆地檢查lock是否已經由spin_unlock釋放(自旋鎖因此得名)。如果已經釋放,則獲得lock,併進入臨界區。
自旋鎖使用註意:
- 如果獲得鎖之後不釋放,系統將變得不可用,所有的處理器(包括獲得鎖的在內),遲早需要進入鎖對應的臨界區,它們會進入無限迴圈等待鎖釋放,但等不到,便產生了死鎖;
- 自旋鎖決不應該長期持有,因為所有等待鎖釋放的處理器都處於不可用狀態,無法用於其他工作;
- 內核進入到由自旋鎖保護的臨界區時,就停用內核搶占,在啟用了內核搶占的單處理器內核中,spin_lock(基本上)等價於preempt_disable,而spin_unlock則等價於preempt_enable。
3、信號量
內核使用的信號量定義如下(用戶空間信號量的實現有所不同):
1 struct semaphore { 2 atomic_t count; //count指定了可以同時處於信號量保護的臨界區中進程的數目 3 int sleepers; //sleepers指定了等待允許進入臨界區的進程的數目 4 wait_queue_head_t wait; //wait用於實現一個隊列,保存所有在該信號量上睡眠的進程的task_struct 5 };
與自旋鎖相比,信號量適合於保護更長的臨界區,以防止並行訪問。它們不應該用於保護較短的代碼範圍,因為競爭信號量時需要使進程睡眠和再次喚醒,代價很高。
大多數情況下,不需要使用信號量的所有功能,只是將其用作互斥量,這是一種二值信號量。
信號量工作情況:
- 在進入臨界區時,用down對使用計數器減1,在計數器為0時,其他進程不能進入臨界區;
- 在試圖用down獲取已經分配的信號量時,當前進程進入睡眠,並放置在與該信號量關聯的等待隊列上,同時,該進程被置於TASK_UNINTERRUPTIBLE狀態,在等待進入臨界區的過程中無法接收信號,如果信號量沒有分配,則該進程可以立即獲得信號量併進入到臨界區,而不會進入睡眠;
- 在退出臨界區時,必須調用up,該常式負責喚醒在信號量睡眠的某個進程,該進程然後允許進入臨界區,而所有其他等待的進程繼續睡眠。
除了只能用於內核的互斥量之外,Linux也提供了futex(快速用戶空間互斥量,fast userspacemutex),由核心態和用戶狀態組合而成,為用戶空間進程提供了互斥量功能。
4、RCU機制
RCU(read-copy-update)是一個同步機制,該機制記錄了指向共用數據結構的指針的所有使用者。在該結構將要改變時,則首先創建一個副本(或一個新的實例),在副本中修改。在所有進行讀訪問的使用者結束對舊副本的讀取之後,指針可以替換為指向新的、修改後副本的指針(允許讀寫併發進行,但不對寫訪問之間的相互干擾提供保護)。使用RCU要求如下:
- 對共用資源的訪問在大部分時間應該是只讀的,寫訪問應該相對很少;
- 在RCU保護的代碼範圍內,內核不能進入睡眠狀態;
- 受保護資源必須通過指針訪問。
RCU可以保護一般指針,也可以保護雙鏈表。以一般指針為例,假定指針ptr指向一個被RCU保護的數據結構,直接反引用指針是禁止的,首先必須調用rcu_dereference(ptr),然後反引用返回的結果,此外,反引用指針並使用其結果的代碼,需要用rcu_read_lock和rcu_read_unlock調用保護起來。對於雙向鏈表,內核也是以RCU機製為基礎,提供了標準函數進行保護。此外由struct hlist_head和struct hlist_node組成的散列表也可以通過RCU保護。
5、記憶體和優化屏障
儘管鎖足以確保原子性,但對編譯器和處理器優化過的代碼,鎖不能永遠保證時序正確。與競態條件相比,這個問題不僅影響SMP系統,也影響單處理器電腦。
內核提供了下麵幾個函數,可阻止處理器和編譯器進行代碼重排。
mb()、rmb()、wmb()將硬體記憶體屏障插入到代碼流程中。rmb()是讀訪問記憶體屏障。它保證在屏障之後發出的任何讀取操作執行之前,屏障之前發出的所有讀取操作都已經完成。wmb適用於寫訪問,語義與rmb類似。讀者應該能猜到,mb()合併了二者的語義。
barrier插入一個優化屏障。該指令告知編譯器,保存在CPU寄存器中、在屏障之前有效的所有記憶體地址,在屏障之後都將失效。本質上,這意味著編譯器在屏障之前發出的讀寫請求完成之前,不會處理屏障之後的任何讀寫請求。
但CPU仍然可以重排時序!
smb_mb()、smp_rmb()、smp_wmb()相當於上述的硬體記憶體屏障,但只用於SMP系統。它們在單處理器系統上產生的是軟體屏障。
read_barrier_depends()是一種特殊形式的讀訪問屏障,它會考慮讀操作之間的依賴性。如果屏障之後的讀請求,依賴於屏障之前執行的讀請求的數據,那麼編譯器和硬體都不能重排這些請求。
6、讀者/寫者鎖
通常,任意數目的進程都可以併發讀取數據結構,而寫訪問只能限於一個進程。因此內核提供了額外的信號量和自旋鎖版本,分別稱之為讀者/寫者信號量和讀者/寫者自旋鎖。
讀者/寫者自旋鎖定義為rwlock_t數據類型。必鬚根據讀寫訪問,以不同的方法獲取鎖。
進程對臨界區進行讀訪問時,在進入和離開時需要分別執行read_lock和read_unlock,內核會允許任意數目的讀進程併發訪問臨界區;
write_lock和write_unlock用於寫訪問。內核保證只有一個寫進程(此時沒有讀進程)能夠處於臨界區中。
讀/寫信號量的用法類似。所用的數據結構是struct rw_semaphore,down_read和up_read用於獲取對臨界區的讀訪問。寫訪問藉助於down_write和up_write進行。
7、大內核鎖
大內核鎖(big kernel lock)可以鎖定整個內核,確保沒有處理器在核心態並行運行(已經過時啦)。使用lock_kernel可鎖定整個內核,對應的解鎖使用unlock_kernel。SMP系統和啟用了內核搶占的單處理器系統如果設置了配置選項PREEMPT_BKL,則允許搶占大內核鎖。
8、互斥量
儘管信號量可用於實現互斥量的功能,信號量的通用性導致的開銷通常是不必要的。因此,內核包含了一個專用互斥量的獨立實現,它們不依賴信號量。內核包含互斥量的兩種實現:一種是經典的互斥量,另一種是用來解決優先順序反轉問題的實時互斥量。
(1)經典的互斥量
經典互斥量的基本數據結構定義如下:
1 struct mutex { 2 /* 1: 未鎖定, 0: 鎖定, 負值:鎖定,可能有等待者 */ 3 atomic_t count; 4 spinlock_t wait_lock; 5 struct list_head wait_list; 6 };
如果互斥量未鎖定,則count為1。鎖定分為兩種情況:如果只有一個進程在使用互斥量,則count設置為0。如果互斥量被鎖定,而且有進程在等待互斥量解鎖(在解鎖時需要喚醒等待進程),則count為負值。這種特殊處理有助於加快代碼的執行速度,因為在通常情況下,不會有進程在互斥量上等待。
定義新的互斥量:
- 靜態互斥量可以在編譯時通過使用DEFINE_MUTEX產生(與DECLARE_MUTEX區分,後者是基於信號量的互斥量);
- mutex_init在運行時動態初始化一個新的互斥量;
- mutex_lock和mutex_unlock分別用於鎖定和解鎖互斥量。
(2)實時互斥量
實時互斥量是內核支持的另一種形式的互斥量,需要在編譯時通過配置選項CONFIG_RT_MUTEX顯式啟用。與普通的互斥量相比,它們實現了優先順序繼承(priority inheritance),該特性可用於解決(或在最低限度上緩解)優先順序反轉的影響。
對於優先順序反轉問題,可以通過優先順序繼承解決。如果高優先順序進程阻塞在互斥量上,該互斥量當前由低優先順序進程持有,那麼低優先順序進程的優先順序會臨時提高到高優先順序進程的優先順序。
實時互斥量的定義非常接近於普通互斥量:
1 struct rt_mutex { 2 spinlock_t wait_lock; 3 struct plist_head wait_list; 4 struct task_struct *owner; 5 };
互斥量的所有者通過owner指定,wait_lock提供實際的保護,所有等待的進程都在wait_list中排隊。與普通互斥量相比,決定性的改變是等待列表中的進程按優先順序排序。在等待列表改變時,內核可相應地校正鎖持有者的優先順序。這需要到調度器的一個介面,可由函數rt_mutex_setprio提供。該函數更新動態優先順序task_struct->prio,而普通優先順序task_struct->normal_priority不變。
9、近似的per_CPU計數器
如果系統安裝有大量CPU,計數器可能成為瓶頸:每次只有一個CPU可以修改其值;所有其他CPU都必須等待操作結束,才能再次訪問計數器。如果計數器頻繁訪問,則會嚴重影響系統性能。
對某些計數器,沒有必要時時瞭解其準確的數值。這種計數器的近似值與準確值,作用上沒什麼差別,可以利用這種情況,引入per-CPU計數器,加速SMP系統上計數器的操作。如圖1所示,計數器的準確值存儲在記憶體中某處,準確值所在記憶體位置之後是一個數組,每個數組項對應於系統中的一個CPU。

圖1 近似per-CPU計數器的數據結構
如果一個處理器想要修改計數器的值(加上或減去某個值n),它不會直接修改計數器的值,因為這需要防止其他的CPU訪問計數器(這是一個費時的操作)。相反,所需的修改將保存到與計數器相關的數組中特定於當前CPU的數組項。(舉例:,如果計數器應該加3,那麼數組中對應的數組項為+3。如果同一個CPU在其他時間需要從計數器減去某個值(假定是5),它也不會對計數器直接操作,而是操作數組中特定於CPU的項:將3減去5,新值為-2。任何處理器讀取計數器值時,都不是完全準確的。如果原值為15,在經過前述的操作之後應該是13,但仍然是15。如果只需要大致瞭解計數器的值,13也算得上是15的一個比較好的近似了。)
如果某個特定於CPU的數組元素修改後的絕對值超出某個閾值,則認為這種修改有問題,將隨之修改計數器的值(這種改變很少發生)。在這種情況下,內核需要確保通過適當的鎖機制來保護這次訪問。
只要計數器改變適度,這種方案中讀操作得到的平均值會相當接近於計數器的準確值。
per-CPU計數器如下:
1 struct percpu_counter { 2 spinlock_t lock; 3 long count; 4 long *counters; 5 };
count是計數器的準確值,lock是一個自旋鎖,用於在需要準確值時保護計數器。counters數組中各數組項是特定於CPU的,該數組緩存了對計數器的操作。
10、鎖競爭與細粒度鎖
Linux在多CPU系統上的可伸縮性已經成為一個非常重要的目標。在對內核代碼設計鎖規則時,特別需要考慮這個問題。鎖需要滿足下麵兩個目的(不過二者通常很難同時實現):
必須防止對代碼的併發訪問,否則將導致失敗;
對性能的影響必須儘可能小。
對於內核頻繁使用的數據,同時滿足這兩個要求是非常複雜的,如果一整個數據結構都由一個鎖保護,那麼在內核的某個部分需要獲取鎖的時候,該鎖已經被系統的其他部分獲取的概率很高,這種情況下會出現較多的鎖競爭(lock contention),該鎖也會成為內核的一個熱點。對此,將數據結構標識為各個獨立的部分,使用多個鎖來保護,這種解決方案稱為細粒度鎖。
細粒度鎖在較大的電腦上對提高可伸縮性很有好處,但也有兩個弊端:
獲取多個鎖會增加操作的開銷,特別是在較小的SMP電腦上;
在通過多個鎖保護一個數據結構時,很自然會出現一個操作需要同時訪問兩個受保護區域的情形,因而需要同時持有多個鎖,這要求必須遵守某種鎖定次序,必須按序獲取和釋放鎖,否則,仍然會導致死鎖。
三、System V進程間通信
Linux使用System V(SysV)引入的機制,來支持用戶進程的進程間通信和同步。
1、System V機制
System V UNIX的3種進程間通信(IPC)機制(信號量、消息隊列、共用記憶體),都使用了全系統範圍的資源,可以由幾個進程同時共用。
在各個獨立進程能夠訪問SysV IPC對象之前,IPC對象必須在系統內唯一標識。為此,每種IPC結構在創建時分配了一個號碼,稱為魔數。凡知道這個魔數的各個程式,都能夠訪問對應的結構。如果獨立的應用程式需要彼此通信,則通常需要將該魔數永久地編譯到程式中。
在訪問IPC對象時,系統採用了基於文件訪問許可權的一個許可權系統。每個IPC對象都有一個用戶ID和一個組ID,依賴於產生IPC對象的程式在何種UID/GID之下運行。讀寫許可權在初始化時分配。類似於普通的文件,這些控制了3種不同用戶類別的訪問:所有者、組、其他。
要創建一個授予所有可能訪問許可權的信號量(所有者、組、其他用戶都有讀寫許可權),則必須指定標誌0666。
2、信號量
(1)使用System V信號量
System V的信號量不再當作是用於支持原子執行預定義操作的簡單類型變數,它是指一整套信號量,可以允許幾個操作同時進行(用戶看上去是原子的)。也可以請求只有一個信號量的信號量集合,並定義函數模擬原始信號量的簡單操作。
(2)數據結構
內核使用了幾個數據結構來描述所有註冊信號量的當前狀態,並建立了一種網狀結構。它們不僅負責管理信號量及其特征(值、讀寫許可權,等等),還負責通過等待列表將信號量與等待進程關聯起來。
初始的預設的IPC命名空間通過ipc_namespace的靜態實例init_ipc_ns實現。每個命名空間都包含如下信息:
1 struct ipc_namespace { 2 ... 3 struct ipc_ids *ids[3]; 4 /* 資源限制 */ 5 ... 6 }
這裡略去了與監視資源消耗和設置資源限制相關的很多數據結構成員(比如共用記憶體頁的最大數目、共用記憶體段的最大長度、消息隊列的最大數目等)。數組ids的每個元素對應於一種IPC機制:信號量、消息隊列、共用記憶體(按順序),每個數組項指向一個struct ipc_ids的實例,用於跟蹤各類別現存的IPC對象。為防止對每個類別都需要查找對應的正確數組索引,內核提供了輔助函數msg_ids、shm_ids和sem_ids。
struct ipc_ids定義如下:
1 struct ipc_ids { 2 int in_use; //保存了當前使用中IPC對象的數目 3 unsigned short seq; //seq和seq_max用於連續產生用戶空間IPC ID(不等同於序號) 4 unsigned short seq_max; 5 struct rw_semaphore rw_mutex; //一個內核信號量,用於實現信號量操作,避免用戶空間中的競態條件 6 struct idr ipcs_idr; 7 };
每個IPC對象都由kern_ipc_perm的一個實例表示,每個對象都有一個內核內部ID,ipcs_idr用於將ID關聯到指向對應的kern_ipc_perm實例的指針。使用中IPC對象的數目可能動態地增長和縮減,內核提供了一個類似於基數樹的標準數據結構用於管理該信息。
1 struct kern_ipc_perm 2 { 3 int id; 4 key_t key; //保存了用戶程式用來標識信號量的魔數 5 uid_t uid; //指所有者的用戶ID 6 gid_t gid; //指所有者的組ID 7 uid_t cuid; //保存了產生信號量的進程的用戶ID 8 gid_t cgid; //保存了產生信號量的進程的組ID 9 mode_t mode; //保存了位掩碼,指定了所有者、組、其他用戶的訪問許可權 10 unsigned long seq; //分配IPC對象時使用的序號 11 };
該結構不僅可用於信號量,還可以用於其他的IPC機制。該結構不足以保存信號量所需的所有信息,各進程的task_struct實例中有一個與IPC相關的成員:
1 struct task_struct { 2 ... 3 #ifdef CONFIG_SYSVIPC 4 /* ipc相關 */ 5 struct sysv_sem sysvsem; 6 #endif 7 ... 8 };
只有設置了配置選項CONFIG_SYSVIPC時,SysV相關代碼才會編譯到內核中。sysv_sem數據結構封裝了一個成員struct sem_undo_list *undo_list用於撤銷信號量(用於崩潰進程修改了信號量狀態的情況)。
sem_queue是另一個數據結構,用於將信號量與睡眠進程關聯起來,該進程想要執行信號量操作,但目前不允許執行。
1 struct sem_queue { 2 struct sem_queue * next; /* 隊列中下一項 */ 3 struct sem_queue ** prev; /* 隊列中的前一項,對於第一項有*(q->prev) == q */ 4 struct task_struct* sleeper; /* 睡眠的進程 */ 5 struct sem_undo * undo; /* 用於撤銷的結構 */ 6 int pid; /* 請求信號量操作的進程ID。 */ 7 int status; /* 操作的完成狀態 */ 8 struct sem_array * sma; /* 操作的信號量數組 */ 9 int id; /* 內部信號量ID */ 10 struct sembuf * sops; /* 待決操作數組 */ 11 int nsops; /* 操作數目 */ 12 int alter; /* 操作是否改變了數組? */ 13 };
系統中每個信號量集合,都對應於sem_array數據結構的一個實例,該實例用於管理集合中的所有信號量,sem_array結構如下:
1 struct sem_array { 2 struct kern_ipc_perm sem_perm; /* 許可權,參見ipc.h */ 3 time_t sem_otime; /* 最後一次信號量操作的時間 */ 4 time_t sem_ctime; /* 最後一次修改的時間 */ 5 struct sem *sem_base; /* 指向數組中第一個信號量的指針 */ 6 struct sem_queue *sem_pending; /* 需要處理的待決操作 */ 7 struct sem_queue **sem_pending_last; /* 上一個待決操作 */ 8 struct sem_undo *undo; /* 該數組上的撤銷請求 */ 9 unsigned long sem_nsems; /* 數組中信號量的數目 */ 10 };
圖2給出了所涉及的各個數據結構之間的相互關係。

圖2 信號量各數據結構之間的相互關係
kern_ipc_perm是用於管理IPC對象的數據結構的第一個成員,不僅對信號量是這樣,消息隊列和共用記憶體對象也是如此。
(3)實現系統調用
所有對信號量的操作都使用一個名為ipc的系統調用執行。該調用不僅用於信號量,也用於操作消息隊列和共用記憶體。其第一個參數用於將實際工作委托給其他函數。用於信號量的函數如下所示。
- SEMCTL執行信號量操作,並由sys_semctl實現;
- SEMGET讀取信號量ID,相關的實現由sys_semget提供;
- SEMOP和SEMTIMEDOP負責增加和減少信號量值,後者可以指定超時時間限制。
(4)許可權檢查
IPC對象的保護機制,與普通的基於文件的對象相同。訪問許可權可以分別對對象的所有者、所有者所在組和所有其他用戶指定(可能的許可權包括讀、寫、執行)。函數ipcperms負責檢查對任意IPC對象的某種操作是否有許可權進行。
3、消息隊列
進程之間通信的另一個方法是交換消息。這是使用消息隊列機制完成的,其實現基於System V模型。消息隊列的功能原理相對簡單,如圖3所示。

圖3 System V消息隊列的功能原理
產生消息並將其寫到隊列的進程通常稱之為發送者,而一個或多個其他進程(邏輯上稱之為接收者)則從隊列獲取信息。各個消息包含消息正文和一個(正)數,以便在消息隊列內實現幾種類型的消息。接收者可以根據該數字檢索消息(比如可以指定只接受編號1的消息,或接受編號不大於5的消息)。在消息已經讀取後,內核將其從隊列刪除。即使幾個進程在同一通道上監聽,每個消息仍然只能由一個進程讀取。
同一編號的消息按先進先出次序處理。放置在隊列開始的消息將首先讀取。但如果有選擇地讀取消息,則先進先出次序就不再適用。
消息隊列也是使用前述信號量哪些數據結構實現,起始點是當前命名空間的適當的ipc_ids實例。內部的ID號形式上關聯到kern_ipc_perm實例,在消息隊列的實現中,需要通過類型轉換獲得不同的數據類型(struct msg_queue)。該結構定義如下:
1 struct msg_queue { 2 struct kern_ipc_perm q_perm; 3 time_t q_stime; /* 上一次調用msgsnd發送消息的時間 */ 4 time_t q_rtime; /* 上一次調用msgrcv接收消息的時間 */ 5 time_t q_ctime; /* 上一次修改的時間 */ 6 unsigned long q_cbytes; /* 隊列上當前位元組數目 */ 7 unsigned long q_qnum; /* 隊列中的消息數目 */ 8 unsigned long q_qbytes; /* 隊列上最大位元組數目 */ 9 pid_t q_lspid; /* 上一次調用msgsnd的pid */ 10 pid_t q_lrpid; /* 上一次接收消息的pid */ 11 struct list_head q_messages; 12 struct list_head q_receivers; 13 struct list_head q_senders; 14 };
3個標準的內核鏈表用於管理睡眠的發送者(q_senders)、睡眠的接收者(q_receivers)和消息本身(q_messages)。各個鏈表都使用獨立的數據結構作為鏈表元素。
q_messages中的各個消息都封裝在一個msg_msg實例中。
1 struct msg_msg { 2 struct list_head m_list; 3 long m_type; //指定了消息類型,用於支持前文所述消息隊列中不同的消息類型。 4 int m_ts; /* 消息正文長度 */ 5 struct msg_msgseg* next; //如果保存超過一個記憶體頁的長消息,則需要next 6 /* 接下來是實際的消息 */ 7 };
結構中沒有指定存儲消息自身的欄位。因為每個消息都(至少)分配了一個記憶體頁,msg_msg實例則保存在該頁的起始處,剩餘的空間可用於存儲消息正文,如圖4所示。從記憶體頁的長度,減去msg_msg結構的長度,即可得到msg_msg頁中可用於消息正文的最大位元組數目。
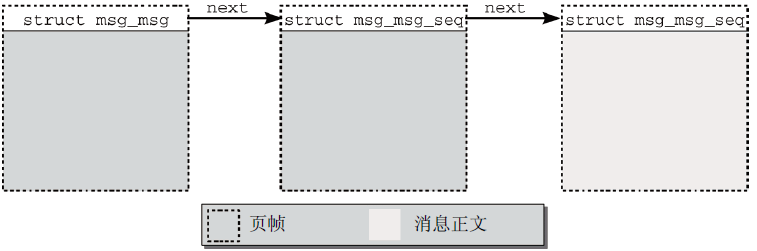
圖4 記憶體中IPC消息的管理
消息正文緊接著該數據結構的實例之後存儲。使用next,可以使消息分佈到任意數目的頁上。在通過消息隊列通信時,發送進程和接收進程都可以進入睡眠:如果消息隊列已經達到最大容量,則發送者在試圖寫入消息時會進入睡眠;如果隊列中沒有消息,那麼接收者在試圖獲取消息時會進入睡眠。
睡眠的發送者放置在msg_queue的q_senders鏈表中,鏈表元素使用下列數據結構:
1 struct msg_sender { 2 struct list_head list; //鏈表元素 3 struct task_struct* tsk; //指向對應進程的task_struct的指針 4 };
q_receivers鏈表中用於保存接收進程的數據結構要稍長一點。
1 struct msg_receiver { 2 struct list_head r_list; 3 struct task_struct *r_tsk; 4 int r_mode; 5 long r_msgtype; 6 long r_maxsize; 7 struct msg_msg *volatile r_msg; 8 };
其中不僅保存了指向對應進程的task_struct的指針,還包括了對預期消息的描述,以及指向msg_msg實例的一個指針(消息可用時,該指針指定了複製數據的目標地址)。
圖5是消息隊列所涉及數據結構之間的相互關係(忽略睡眠的發送進程鏈表)。
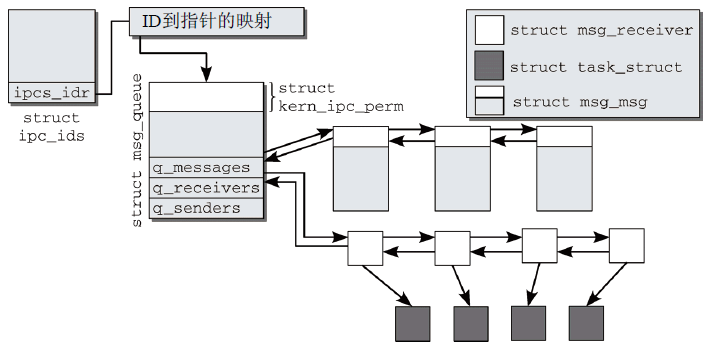
圖5 System V消息隊列的數據結構
4、共用記憶體
與信號量和消息隊列相比,共用記憶體沒有本質性的不同。
- 應用程式請求的IPC對象,可以通過魔數和當前命名空間的內核內部ID訪問;
- 對記憶體的訪問,可能受到許可權系統的限制;
- 可以使用系統調用分配與IPC對象關聯的記憶體,具備適當授權的所有進程,都可以訪問該記憶體。
內核的實現採用了與信號量和消息隊列非常類似的概念,相關數據結構關係如圖6所示。
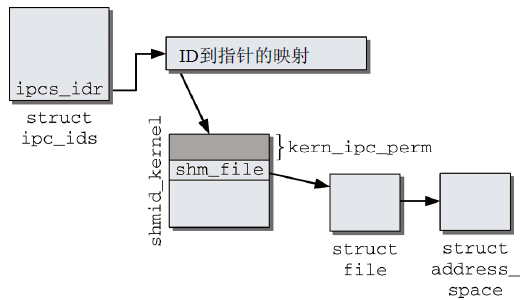
圖6 System V共用記憶體的數據結構
在smd_ids全局變數的entries數組中保存了kern_ipc_perm和shmid_kernel的組合,以便管理IPC對象的訪問許可權。對每個共用記憶體對象都創建一個偽文件,通過shm_file連接到shmid_kernel的實例。內核使用shm_file->f_mapping指針訪問地址空間對象(struct address_space),用於創建匿名映射。還需要設置所涉及各進程的頁表,使得各個進程都能夠訪問與該IPC對象相關的記憶體區域。
四、其他IPC機制
SysV IPC通常只對應用程式員有意義,但對shell的用戶,信號和管道更常用。
1、信號
與SysV機制相比,信號是一種比較原始的通信機制,其底層概念非常簡單,kill命令根據PID向進程發送信號。信號通過-s sig指定,是一個正整數,最大長度取決於處理器類型。
進程必須設置處理程式常式來處理信號。這些常式在信號發送到進程時調用(進程可以決定阻塞某些信號,但有幾個信號的行為無法修改,如SIGKILL)。如果沒有顯式設置處理程式常式,內核則使用預設的處理程式實現。(init進程屬於特例,內核會忽略發送給該進程的SIGKILL信號。)
(1)實現信號處理程式
sigaction系統調用用於設置新的處理程式。如果沒有為某個信號分配用戶定義的處理程式函數,內核會自動設置預定義函數,提供合理的標準操作來處理相應的情況。
sigaction類型中用於描述處理程式的欄位,其定義是平臺相關的,但在所有體繫結構上幾乎都相同。
1 struct sigaction { 2 __sighandler_t sa_handler; //一個指向內核在信號到達時調用的處理程式函數的指針 3 unsigned long sa_flags; //包含了額外的標誌,用於指定信號處理方式的一些約束 4 ... 5 sigset_t sa_mask; //包含了一個位掩碼,每個比特位對應於系統中的一個信號 6 };
信號處理程式的函數原型如下:
1 typedef void __signalfn_t(int); 2 typedef __signalfn_t __user *__sighandler_t;
其參數是信號的編號,因此可以使用同一個處理程式函數處理不同的信號。
信號處理程式使用sigaction系統調用設置,該調用將藉助用戶定義的處理程式函數替換SIGTERM的預設處理程式。
(2)實現信號管理
所有信號相關的數據都是藉助於鏈式數據結構管理的,其入口是task_struct結構,其中包含了各個與信號相關的欄位。
1 struct task_struct { 2 ... 3 /* 信號處理程式 */ 4 struct signal_struct *signal; 5 struct sighand_struct *sighand; 6 sigset_t blocked; 7 struct sigpending pending; 8 unsigned long sas_ss_sp; 9 size_t sas_ss_size; 10 ... 11 };
信號處理髮生在內核中,但設置的信號處理程式是在用戶狀態運行,通常,信號處理程式使用所述進程在用戶狀態下的棧。但POSIX強制要求提供一種選項,在專門用於信號處理的棧上運行信號處理程式,這個附加的棧(必須通過用戶應用程式顯式分配),其地址和長度分別保存在sas_ss_sp和sas_ss_size。
用於管理設置的信號處理程式的信息的sighand_struct如下所示:
1 struct sighand_struct { 2 atomic_t count; //保存了共用該結構實例的進程數目 3 struct k_sigaction action[_NSIG]; //保存設置的信號處理程式,_NSIG指定了可以處理的不同信號的數目 4 } ;
所有阻塞信號由task_struct的blocked成員定義,所使用的sigset_t數據類型是一個位掩碼,所包含的比特位數目必須(至少)與所支持的信號數目相同,其數據結構為:
1 typedef struct { 2 unsigned long sig[_NSIG_WORDS]; 3 } sigset_t;
pending是task_struct中與信號處理相關的最後一個成員。它建立了一個鏈表,包含所有已經引發、仍然有待內核處理的信號。它們使用了下列數據結構:
1 struct sigpending { 2 struct list_head list; //通過雙鏈表管理所有待決信號 3 sigset_t signal; //位掩碼,指定了仍然有待處理的所有信號的編號 4 };
圖7為各結構體之間的關係。
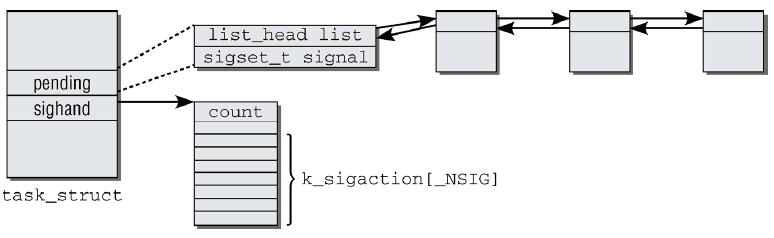
圖7 信號管理結構體之間關係
(3)實現信號處理
內核用於實現信號處理的最重要的系統調用有kill(向進程組的所有進程發送一個信號)、tkill(向單個進程發送一個信號)、sigpending(檢查是否有待決信號)、sigprocmask(操作阻塞信號的位掩碼)、sigsuspend(進入睡眠,直至接收某特定信號)。
對於發送信號,不論名稱如何,實際上kill和tkill基本相同,以sys_tkill為例,其代碼流程圖如圖8所示。
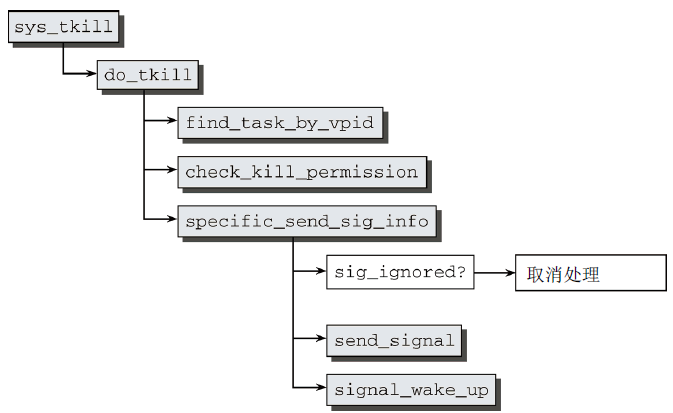
圖8 sys_tkill代碼流程圖
在find_task_by_vpid找到目標進程的task_struct之後,內核將檢查進程是否有發送該信號所需許可權的工作委托給check_kill_permission,該函數檢查許可權。剩餘的信號處理工作則傳遞給specific_send_sig_info進行,如果信號被阻塞(可以用sig_ignored檢查),則立即放棄處理;否則由send_signal產生一個新的sigqueue實例(使用sigqueue_cachep緩存),其中填充了信號數據,並添加到目標進程的sigpending鏈表;若發送陳宮,則可以使用signal_wake_up喚醒進程。
對於信號隊列的處理,每次由核心態切換到用戶狀態時,內核都會完成此工作。處理的發起獨立於特定的體繫結構,此後,最終的效果就是調用do_signal函數(此處不詳述)。
從時序上看,信號處理的過程如圖9所示。
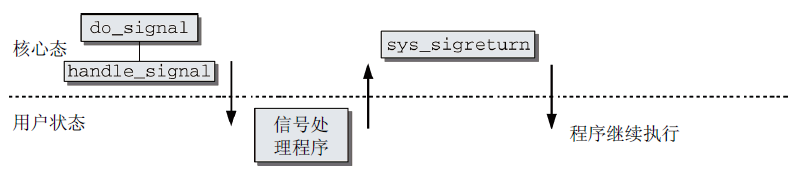
圖9 信號處理的執行
2、管道和套接字
管道和套接字是流行的進程間通信機制。管道使用了虛擬文件系統對象,套接字使用了各種網路函數以及虛擬文件系統。
管道是用於交換數據的連接。一個進程向管道的一端供給數據,另一個在管道另一端取出數據,供進一步處理。幾個進程可以通過一系列管道連接起來。
管道是進程地址空間中的數據對象,在用fork或clone複製進程時同樣會被覆制。使用管道通信的程式就利用了這種特征。在exec系統調用用另一個程式替換子進程之後,兩個不同的應用程式之間就建立了一條通信鏈路(必須把管道描述符重定向到標準輸入和輸出,或者調用dup系統調用,確保exec調用時不會關閉文件描述符)。
套接字對象在內核中初始化時也返回一個文件描述符,因此可以像普通文件一樣處理,與管道不同之處在於它可以雙向使用,還可以用於通過網路連接的遠程系統通信。從用戶的角度來看,同一系統上兩個本地進程之間


