
介紹 此Refcard提供了Apache Hadoop,這是最流行的軟體框架,可使用簡單的高級編程模型實現大型數據集的分散式存儲和處理。我們將介紹Hadoop最重要的概念,描述其架構,指導您如何開始使用它以及在Hadoop上編寫和執行各種應用程式。 簡而言之,Hadoop是Apache Softwa ...
介紹
此Refcard提供了Apache Hadoop,這是最流行的軟體框架,可使用簡單的高級編程模型實現大型數據集的分散式存儲和處理。我們將介紹Hadoop最重要的概念,描述其架構,指導您如何開始使用它以及在Hadoop上編寫和執行各種應用程式。
簡而言之,Hadoop是Apache Software Foundation的一個開源項目,可以安裝在伺服器集群上,以便這些伺服器可以通信並協同工作來存儲和處理大型數據集。Hadoop近年來因其有效處理大數據的能力而變得非常成功。它允許公司將所有數據存儲在一個系統中,並對這些數據進行分析,否則傳統解決方案不可能或非常昂貴。
圍繞Hadoop構建的許多配套工具提供了各種各樣的處理技術。與輔助系統和實用程式的集成非常出色,使Hadoop的實際工作更輕鬆,更高效。這些工具共同構成了Hadoop生態系統。
您可以將Hadoop視為大數據操作系統,從而可以在所有龐大的數據集上運行不同類型的工作負載。其範圍從離線批處理到機器學習再到實時流處理。
熱門提示:訪問http://hadoop.apache.org以獲取有關項目的更多信息並訪問詳細文檔。
要安裝Hadoop,您可以從http://hadoop.apache.org獲取代碼或(更推薦)使用其中一個Hadoop發行版。三種最廣泛使用的來自Cloudera(CDH),Hortonworks(HDP)和MapR。Hadoop發佈是Hadoop生態系統捆綁在一起的一組工具,由相應的供應商保證,可以很好地協同工作。此外,每個供應商都提供工具(開源或專有)來配置,管理和監控整個平臺。
設計理念
為瞭解決處理和存儲大型數據集的挑戰,Hadoop是根據以下核心特征構建的:
-
分發 - 存儲和處理不是構建一臺大型超級電腦,而是分佈在一組通信和協同工作的小型機器上。
-
橫向可擴展性 - 只需添加新電腦即可輕鬆擴展Hadoop集群。每台新機器都會按比例增加Hadoop集群的總存儲和處理能力。
-
容錯 - 即使少數硬體或軟體組件無法正常工作,Hadoop仍可繼續運行。
-
成本優化 - Hadoop不需要昂貴的高端伺服器,無需商業許可即可正常工作。
-
編程抽象 - Hadoop負責處理與分散式計算相關的所有混亂細節。藉助高級API,用戶可以專註於實現解決現實問題的業務邏輯。
-
數據位置 - Hadoop不會將大型數據集移動到運行應用程式的位置,而是運行數據已經存在的應用程式。
Hadoop組件
Hadoop分為兩個核心組件:
-
HDFS - 分散式文件系統。
-
YARN - 集群資源管理技術。
熱門提示:許多執行框架在YARN之上運行,每個框架都針對特定用例進行了調整。最重要的內容將在下麵的“YARN Applications”中討論。
讓我們仔細看看他們的架構並描述他們如何合作。
HDFS
HDFS是一個Hadoop分散式文件系統。它可以在您需要的任意數量的伺服器上運行 - HDFS可以輕鬆擴展到數千個節點和數PB的數據。
HDFS設置越大,某些磁碟,伺服器或網路交換機出現故障的概率就越大。HDFS通過在多個伺服器上複製數據來幸免於這些類型的故障。HDFS自動檢測給定組件是否已發生故障,並採取對用戶透明的必要恢復操作。
HDFS設計用於存儲數百兆位元組或千兆位元組的大型文件,併為它們提供高吞吐量的流數據訪問。最後但同樣重要的是,HDFS支持一次寫入多次讀取模型。對於這個用例,HDFS就像一個魅力。但是,如果您需要存儲大量具有隨機讀寫訪問許可權的小文件,那麼其他系統(如RDBMS和Apache HBase)可以做得更好。
註意:HDFS不允許您修改文件的內容。只支持在文件末尾附加數據。但是,Hadoop設計的HDFS是眾多可插拔存儲選項之一 - 例如,使用專有文件系統MapR-F,文件完全可讀寫。其他HDFS替代品包括Amazon S3,Google Cloud Storage和IBM GPFS。
HDFS的體繫結構
HDFS由在選定群集節點上安裝和運行的以下守護程式組成:
-
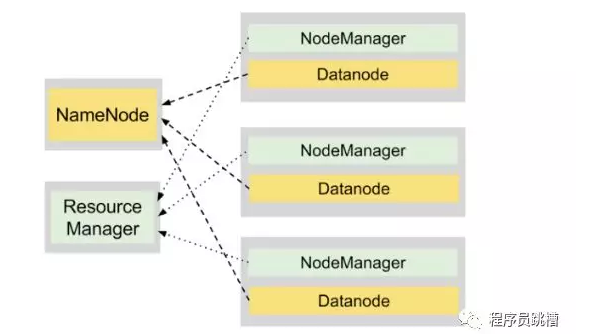
NameNode - 負責管理文件系統命名空間(文件名,許可權和所有權,最後修改日期等)以及控制對存儲在HDFS中的數據的訪問的主進程。如果NameNode已關閉,則無法訪問您的數據。幸運的是,您可以配置多個NameNode,以確保此關鍵HDFS進程的高可用性。
-
DataNodes - 安裝在集群中每個工作節點上的從屬進程,負責存儲和提供數據。
圖1說明瞭在4節點集群上安裝HDFS。其中一個節點托管NameNode守護程式,而其他三個運行DataNode守護程式。
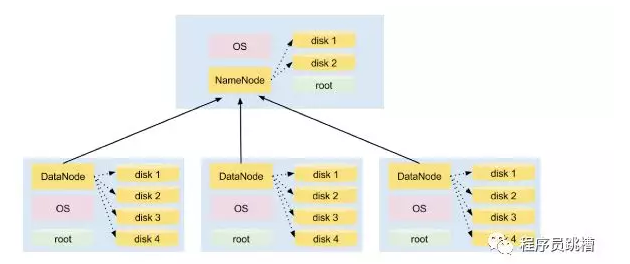
註意:NameNode和DataNode是在Linux發行版之上運行的Java進程,例如RedHat,Centos,Ubuntu等。他們使用本地磁碟存儲HDFS數據。
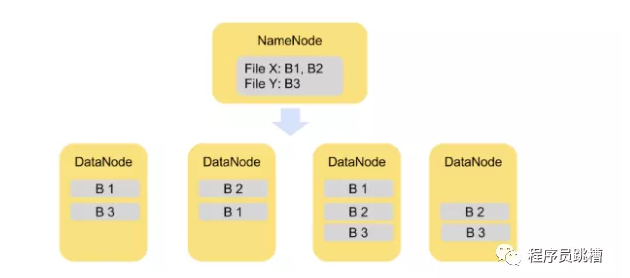
HDFS將每個文件拆分為一系列較小但仍然較大的塊(預設塊大小等於128MB - 較大的塊意味著更少的磁碟搜索操作,從而導致更大的吞吐量)。每個塊都冗餘地存儲在三個DataNode上以實現容錯(每個文件的副本數量是可配置的)。
圖2說明瞭將文件拆分為塊的概念。文件X被分成塊B1和B2,文件Y僅包括一個塊B3。所有塊都在群集中複製兩次。
與HDFS交互
HDFS提供了一個簡單的POSIX類介面來處理數據。您使用hdfs dfs命令執行文件系統操作。
熱門提示:要開始使用Hadoop,您不必完成設置整個群集的過程。Hadoop可以在一臺機器上以所謂的偽分散式模式運行。您可以下載已安裝所有HDFS組件的沙盒虛擬機,並立即開始使用Hadoop!只需按照以下鏈接之一:
http://www.mapr.com/products/mapr-sandbox-hadoop
http://hortonworks.com/products/hortonworks-sandbox/#install
https://www.cloudera.com/downloads/quickstart_vms/5-12.html
以下步驟說明瞭HDFS用戶可以執行的典型操作:
列出主目錄的內容:
$ hdfs dfs -ls /user/adam
將文件從本地文件系統上傳到HDFS:
$ hdfs dfs -put songs.txt /user/adam
從HDFS讀取文件的內容:
$ hdfs dfs -cat /user/adam/songs.txt
更改文件的許可權:
$ hdfs dfs -chmod 700 /user/adam/songs.txt
將文件的複製因數設置為4:
$ hdfs dfs -setrep -w 4 /user/adam/songs.txt
檢查文件的大小:
`$ hdfs dfs -du -h /user/adam/songs.txt
在主目錄中創建一個子目錄。請註意,相對路徑始終引用執行命令的用戶的主目錄。HDFS上沒有“當前”目錄的概念(換句話說,沒有相當於“cd”命令):
$ hdfs dfs -mkdir songs
將文件移動到新創建的子目錄:
$ hdfs dfs -mv songs.txt songs/
從HDFS中刪除目錄:
$ hdfs dfs -rm -r songs
註意:已刪除的文件和目錄將移至回收站(HDFS上主目錄中的.Trash)並保留一天,直到它們被永久刪除。您只需將它們從.Trash複製或移動到原始位置即可恢復它們。
熱門提示:您可以在不使用任何參數的情況下鍵入hdfs dfs,以獲取可用命令的完整列表。
如果您更喜歡使用圖形界面與HDFS交互,您可以查看免費和開源的HUE(Hadoop用戶體驗)。它包含一個方便的“文件瀏覽器”組件,允許您瀏覽HDFS文件和目錄並執行基本操作。
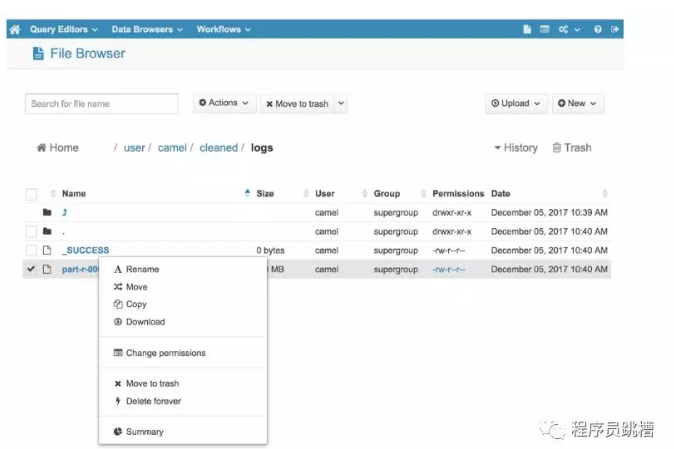
您還可以使用HUE通過“上傳”按鈕直接從電腦將文件上傳到HDFS。
YARN(Yet Another Resource Negotiator)負責管理Hadoop集群上的資源,並支持運行處理存儲在HDFS上的數據的各種分散式應用程式。
與HDFS類似,YARN遵循主從設計,ResourceManager進程充當主設備,多個NodeManager充當工作者。他們有以下責任:
的ResourceManager
-
跟蹤實時NodeManagers以及群集中每台伺服器上的可用計算資源量。
-
為應用程式分配可用資源。
-
監視Hadoop集群上所有應用程式的執行情況。
節點管理器
-
管理Hadoop集群中單個節點上的計算資源(RAM和CPU)。
-
運行各種應用程式的任務,並強制它們在指定的計算資源的限制範圍內。
YARN以資源容器的形式將集群資源分配給各種應用程式,資源容器表示RAM量和CPU核心數量的組合。
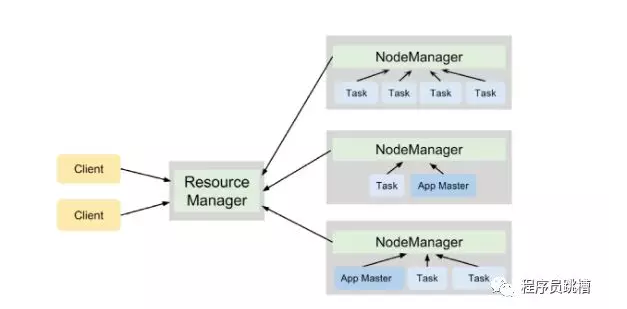
在YARN群集上執行的每個應用程式都有自己的ApplicationMaster進程。在群集上調度應用程式並協調此應用程式中所有任務的執行時,此過程開始。
圖3說明瞭YARN守護程式在運行兩個應用程式的4節點集群上的合作,這些應用程式總共產生了7個任務。
Hadoop = HDFS + YARN
在同一群集上運行的HDFS和YARN守護程式為我們提供了一個用於存儲和處理大型數據集的強大平臺。
DataNode和NodeManager進程在同一節點上並置以啟用數據位置。這種設計使得能夠在存儲數據的機器上執行計算,從而最小化通過網路發送大塊數據的必要性,這導致更快的執行時間。
YARN應用程式
YARN只是一個資源管理器,它知道如何將分散式計算資源分配給在Hadoop集群上運行的各種應用程式。換句話說,YARN本身不提供任何可以分析HDFS中數據的處理邏輯。因此,必須將各種處理框架與YARN集成(通過提供ApplicationMaster的特定實現)以在Hadoop集群上運行並處理來自HDFS的數據。
下麵列出了最流行的分散式計算框架的簡短描述,這些框架可以在由YARN支持的Hadoop集群上運行。
-
MapReduce - Hadoop的傳統和最古老的處理框架,將計算表示為一系列map和reduce任務。它目前正被Spark或Flink等更快的引擎所取代。
-
Apache Spark - 一種用於大規模數據處理的快速通用引擎,可通過在記憶體中緩存數據來優化計算(後面部分將詳細介紹)。
-
Apache Flink - 高吞吐量,低延遲的批處理和流處理引擎。它以其強大的實時處理大數據流的能力而著稱。您可以在這篇全面的文章中找到Spark和Flink之間的差異:https://dzone.com/articles/apache-hadoop-vs-apache-spark
-
Apache Tez - 一個旨在加快Hive執行SQL查詢的引擎。它可以在Hortonworks數據平臺上獲得,它將MapReduce替換為Hive的執行引擎。
監控YARN應用程式
可以使用ResourceManager WebUI跟蹤在Hadoop集群上運行的所有應用程式的執行,預設情況下,該管理程式在埠8088上公開。
對於每個應用程式,您都可以閱讀一些重要信息。
如果單擊“ID”列中的條目,您將獲得有關所選應用程式執行的更詳細的指標和統計信息。
熱門提示:使用ResourceManager WebUI,您可以檢查可用於處理的RAM總量和CPU核心數以及當前的Hadoop集群負載。查看頁面頂部的“群集指標”。
————————————————————
推薦閱讀:

